記事概要
Transformerを使用した物体検出向けの論文調査メモ。誤りもあると思われるので随時修正&更新していく。
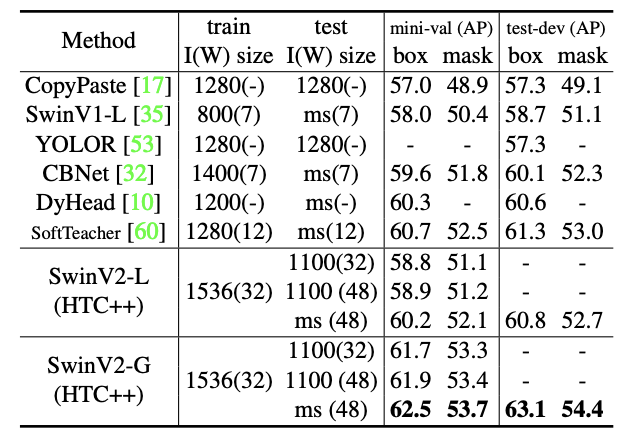
MSCOCOでの比較
学習時計算量多すぎる、と思いきやHTCだから多いみたい。SwinTransformer自体はそこまで学習時計算量を増やさず、CNN系バックボーンに比べると微増、Vision Transformerよりは少ない計算量である[Liu2021]。SwinTransformer V2はV1と計算量はほぼ同じ。
| Backbone | Detector | mAP | params | FLOPS |
|---|---|---|---|---|
| DarkNet(P6) | YOLOv4 | 54.9% | 128M | 718G |
| DarkNet(P6) | YOLOR | 55.4% | 37M | 326G |
| DarkNet(D6) | YOLOR | 57.3% | 152M | 937G |
| ViT | YOLOv4 | |||
| SwinV1-L | HTC++ | 58.7% | 284M | 1470G |
| Dual-SwinV1-L | HTC | 60.1% | 453M | 2162G |
| SwinV2-L | HTC++ | 60.8% | 284M | |
| SwinV2-G | HTC++ | 63.1% | 30B |
ViT-YOLO:Transformer-Based YOLO for Object Detection [Zhang2021] ICCV2021
Zhang, Zixiao, et al. "ViT-YOLO: Transformer-Based YOLO for Object Detection." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
概要
[課題]:ドローンの空撮映像は同一カテゴリ物体でも映っている大きさはまちまちであり、視点変化も大きい。
[従来]:YOLOv4等で使用されているCNN系バックボーンは深いレイヤほど解像度が落ちるため、大きい物体は正確な位置検出ができず、小さい物体は検出そのものが難しい。
[提案]:Vision Transformerの機構を取り入れたMHSA-Darknetバックボーンを提案
[効果]:VisDrone-DET 2021にてYOLOv4-P7を超えてSOTA、VisDrone2019ではYOLOv4-P7を5Pt以上改善し、mAP41%となった。
手法詳細
MHSA-Darknetは P7アーキテクチャのP7ブロックをTransformerを使用したMHSA-Dark Blockに入れ替えている。Transformerは画像サイズn、チャネル数dに対してO(n^2*d)の計算量であるため、P7の箇所のみ適用している。Vision Transformerに関してはこの記事が詳しい。
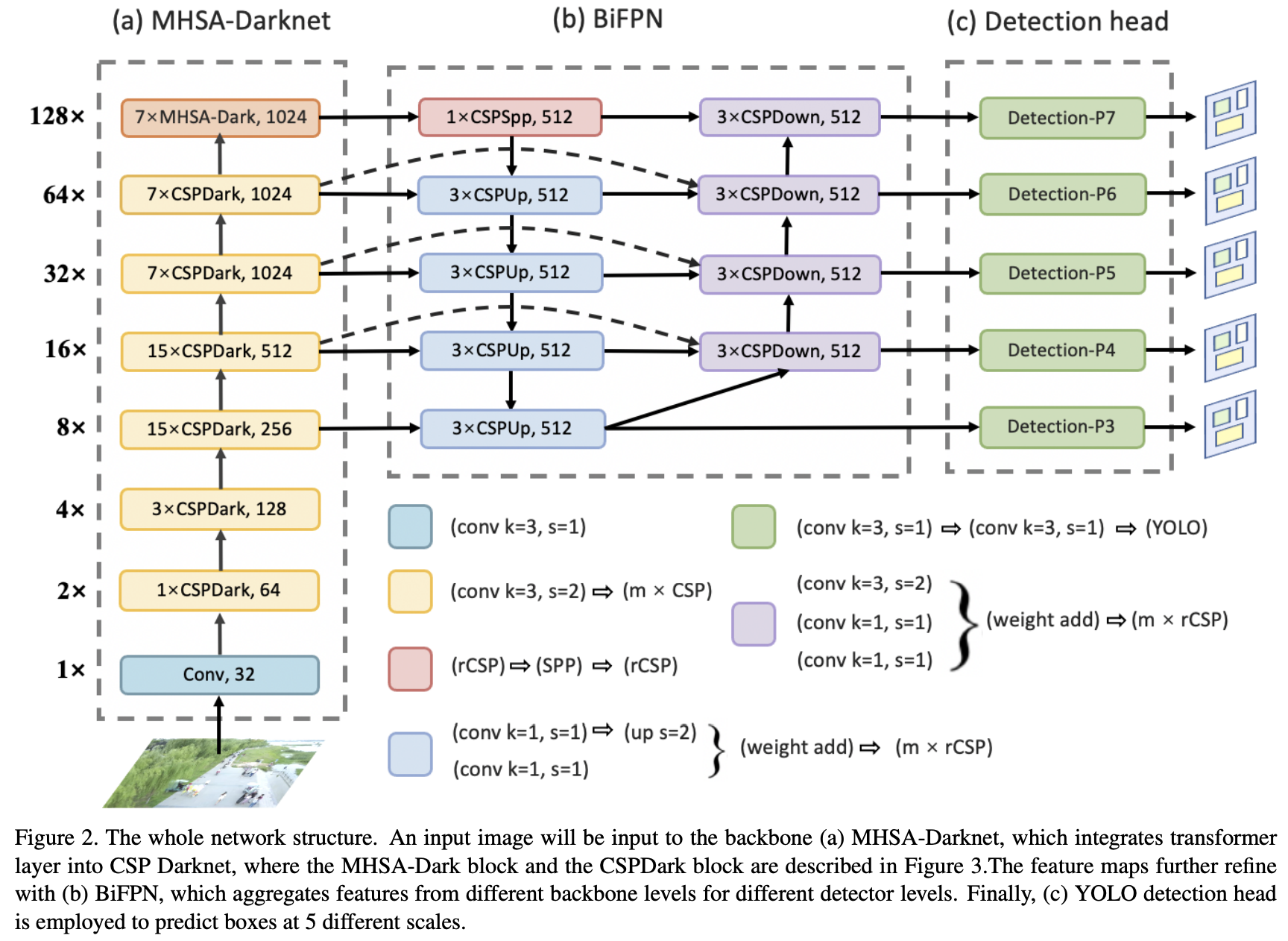
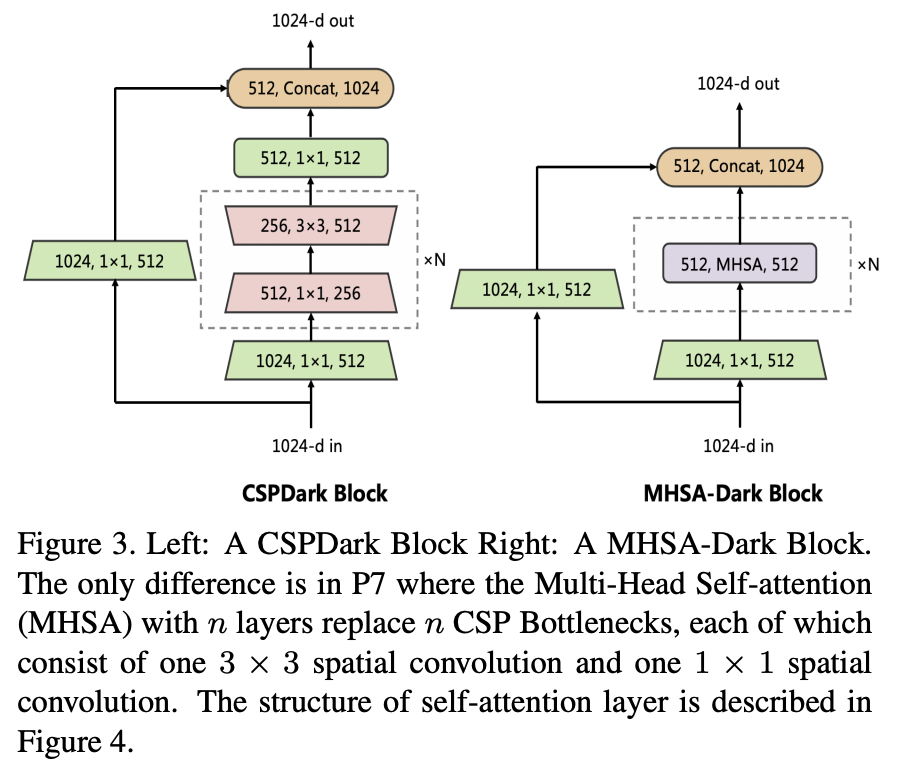
P7は7つの CSP bottleneck blocks 内に 1 × 1 convolution と 3 × 3 convolutionのペアを持つが、ここの部分はTransformer機構を持つ MHSA-Dark blockに入れ替わっている。
実験・考察
YOLOv4-P7をベースラインとし、バックボーンをDarknet->MHSA-Darknet、ネック部をFPN->BiFPNに変更し、さらにTTA+WBF[Solovyev2021]による推論時アンサンブルによって改善を得られた。バックボーンのTransformer化による改善が一番大きい。
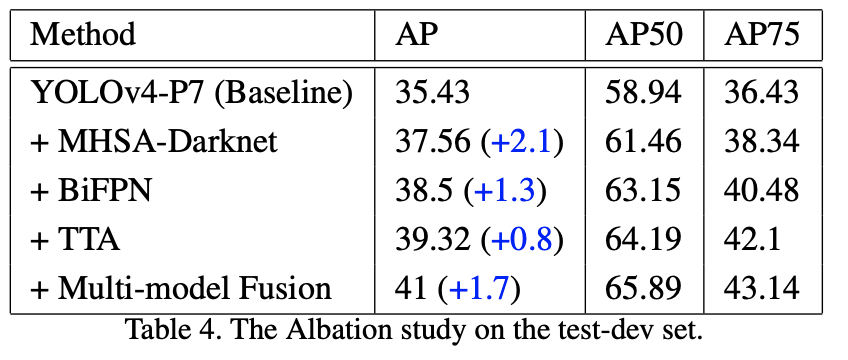
- 小さい物体検出に強い
CNNベースのバックボーンは深いレイヤほど解像度が落ちるため、大きい物体は正確な位置検出ができず、小さい物体は検出そのものが難しい。小さい物体は周辺物体との共起性の傾向が強く、広い範囲でのコンテキスト情報を学習できるTransformer系のバックボーンは小さい物体の検出に強いと言える。
- 視点変化(viewpoint variation)に強い
これは Vision Transformer の特性である。CNN系バックボーンよりもドメイン変化、オクルージョン、摂動に強い傾向があることが報告されている[Naseer2021]。
Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows [Liu2021] ICCV2021
Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." arXiv preprint arXiv:2103.14030 (2021).
MSRAの研究、SwinTransformer V1は以下の資料の説明が詳しいのでそちらに任せる
- [DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 「Swin Transformer」の概要を理解する
Swin Transformer V2: Scaling Up Capacity and Resolution [Liu2021]
[Liu2021] Liu, Ze, et al. "Swin Transformer V2: Scaling Up Capacity and Resolution." arXiv preprint arXiv:2111.09883 (2021).
https://arxiv.org/abs/2111.09883
MSRAの研究、SwinTransformer V1はICCV2021採択
(調査中)
実験・考察
CMT: Convolutional Neural Networks Meet Vision Transformers [Guo2021]
Guo, Jianyuan, et al. "Cmt: Convolutional neural networks meet vision transformers." arXiv preprint arXiv:2107.06263 (2021).