はじめに
- 前回、基礎となる「Transformer」の概要を(大雑把にだけど)理解したので、本命である「Swin Transformer」を見ていきたいと思う。
- 「Transformer」をComputer Visionの幅広い課題に適用させることに成功したMicrosoftの論文である。
論文情報
- タイトル:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- 著者 :Ze Liu(Microsoft Research Asia) et al.
- 発表 :ICCV 2021(Best paper)
Abstruct
- TransformerをComputer Visionに適用するためには、(検出対象)物体のスケールが大きく変化すること、テキストと比較して入力画像の解像度が高いことの2つの課題に対応する必要がある。
- これらの課題に対応するため、本論文では、Shifted windowsで計算される階層的Transformerを提案する。
- このアーキテクチャは、画像サイズに対して線形の計算量を持ち、さらに画像分類・物体検出・セマンティックセグメンテーションなどのタスクで既存のSoTAを大きく上回った。
Introduction
- 既存のVision Transformerを含め、TransformerをCVに適用するには以下の課題があった。
- 画像を特定サイズのパッチに切り出して入力情報としており、多様な解像度や物体スケールの変化に対応しきれない。
- 入力データが大きい(おおよそ画像サイズの二乗)ため、計算量が大きすぎる。
- これらに対応するため、Swin Transformerでは、以下の工夫を行っている。
- Patch Mergingという、Poolingのようにデータの縦横サイズを小さくする機構を導入。
- Shifted windowsを用いて、局所的なAttentionを計算する。
ネットワークアーキテクチャ

- 1stage目
- 入力データを、パッチ分割モジュールで分割(重なりのないパッチに分割される)。
- 各パッチをトークンとして扱い、RGB値をconcatしたものを特徴量とする。
- 今回の実装では、パッチサイズは4 × 4。各パッチの特徴量の次元は、4 × 4 × 3 = 48。
- 最初のステージでは、この入力にlinear embedding layerでC次元に圧縮をかける
- 次元圧縮?実装は??と思ったが、公式コードでは1.と併せて、kernel_size=stride=パッチサイズのconv2dを使用。
- (図では省略されているが)Layer Normalizationを適用
- 「Swin Transformer Block」を2層適用
- Transformerのencoder(の1block分)がベース
- Multi head self-attantionが、「Shift Window-based Multi head self-attantion」に改良
- このポイントはキーアイデアなので、詳細は次項へ。
- 入力データを、パッチ分割モジュールで分割(重なりのないパッチに分割される)。
- 2stage目以降
- Patch Margingと呼ばれる、入力のH、Wサイズを1/2に縮小し、チャネル方向に拡張する処理を行う。
- 実装は、以下の通りcatで[1/2W, 1/2H, 4C] → Layer Normalization → Linearで[1/2W, 1/2H, 2C]のように処理している。

- 1stage目と同様に「Swin Transformer Block」を2層適用
- 1-2を4stageまでstackする
- Patch Margingと呼ばれる、入力のH、Wサイズを1/2に縮小し、チャネル方向に拡張する処理を行う。
Swin Transformer Block
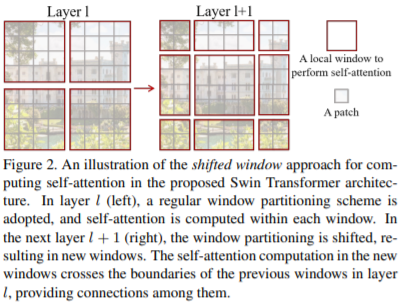
- キーアイデアはシンプルで、self-attentionを適用する範囲をlayerlの図のようにwindowで区切る。
- windowを適用することで、通常のself-attentionでは対応が難しい大きい入力データに対しても、スケーラブルにself-attentionを適用できる。
- さらに、1回おきにLayerl+1の図のようにshiftする。
- これにより、隣接したwindow間でのconnectionが生まれ、image classification, object detection, semantic segmentationの課題で有効な結果が得られた。
- 実装時において、layerl+1の例にあるような見切れている小さい窓にも(仮想的に)同じWindow sizeを適用して計算し、不要な部分をmaskする方法を取ると、計算量が大きくなってしまう。
- そこで、cyclicにshiftさせることで、Window数を増やさずに(layerl+1の場合も、layerlの場合と同じ計算量で)効率的に処理する実装方法を提案する。

Relative position bias
- self-attentionにおいて相対位置を考慮するため、以下の式でattentionを算出する。

- 実装では、レイヤのinit時に全w*hの組合せの相対位置を格納したrelative position bias tableを作成しておき、使う時に参照している。
その他、個人的に気になる所
-
stochastic depthという、ノードではなくレイヤ数をDropOutさせる手法を適用。Object Detectionでは0.2。
-
Object Detectionの実験結果。
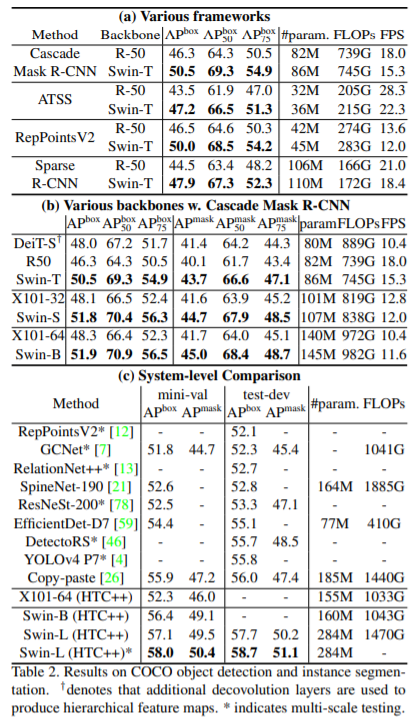
- メモリ使用量と計算量を勘案すると、現時点ではEfficientDetやYOLOの方が実用的な気がしてしまう。
-
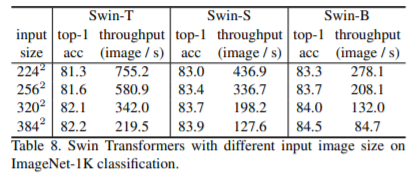
気になる入力サイズごとのスループット。
- Swin-TがResNet50, Swin-SがResNet101相当。
- この表には載ってないが、おそらくGPUはTesla v100を使用。