私の仕事では、とても kusto クエリが重要です。華麗にカッコいいクエリが書ける人はおそらくモテメンになるのは間違いありません。少なくとも一部の地域で。
さて、私は「なんとなく」kusto クエリを使ってきたので、ここらでちゃんと理解して、凝ったクエリーを一撃で書けるようになりたいので、ブログに少しづつ書き溜めることにしました。
参考資料はこちらです。
内容的には、上記のチュートリアルが非常によくできていますので、自分用に解説を加えていきます。あと、多少自分の経験した、「どうやったらええんやろ的なものは踏み込んでみたいと思います)
Kusto クエリとは
Kusto クエリは、読み込み専用のリクエストで、データを処理して結果を返すものです。リクエストは、スキーマは、クラスタ、データベース、テーブル、そしてカラムといった形式で構造化されています。クエリは、複数のクエリからなりたっています。;でデリミタされています。 tabular expression statementという形式で記述されています。
source1 | operator 1 | operator2 | renderInstruction
という形式になっています。データソース、つまりテーブルを最初に書いて、そのデータのオペレーションをパイプでつないでいくことで、さまざまなデータ処理をすることができます。最後の renderInstruction は結果をどのようにレンダリングするかのオプションです。
次の例を見てみましょう。最初の StormEvents がテーブルです。そのテーブルを、where 句でクエリーをして、該当する日時のデータのみにフィルタしています。最後に、State つまり州がフロリダのもののみ抽出して、件数をカウントする関数である count を使って件数数えています。
StormEvents
| where StartTime >= datetime(2007-11-01) and StartTime < datetime(2007-12-01)
| where State == "FLORIDA"
| count
これから様々なクエリの文法を見ていきましょう。
Kusto クエリの文法
検索範囲の設定と、表示列の設定 where と project
where オペレータは検索の範囲を狭めるためのものです。where 句で使える論理演算としては、Query best practicesなどを参考にされると良いでしょう。ほかにも Samplesが充実しています。projectオペレータは、最後表示する列を限定することができます。カラムが多いテーブルだとたくさんカラムが出てくるとうっとおしいことが多いので、project で数を制限すると見やすくなります。
StormEvents
| where StartTime > datetime(2007-02-01) and StartTime < datetime(2007-03-01)
| where EventType == 'Flood' and State == 'CALIFORNIA'
| project StartTime, EndTime , State , EventType , EpisodeNarrative

取得レコードの制限 take
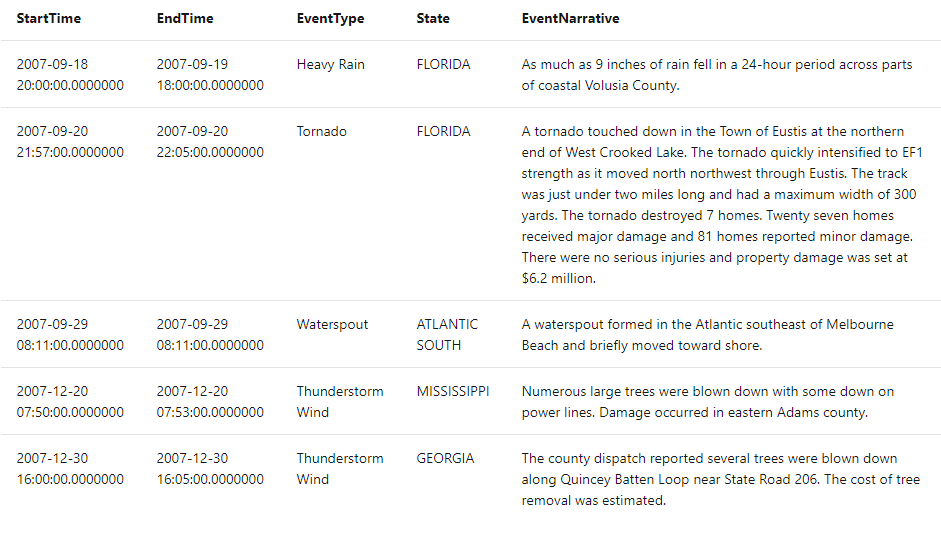
takeは limit のシノニムで、取得する件数を制限します。件数が多すぎるとどうせ見れないので、通常take を使って 1000 件程度に制限します。
StormEvents
| take 5
| project StartTime, EndTime, EventType, State, EventNarrative
ソート top, asc, desc
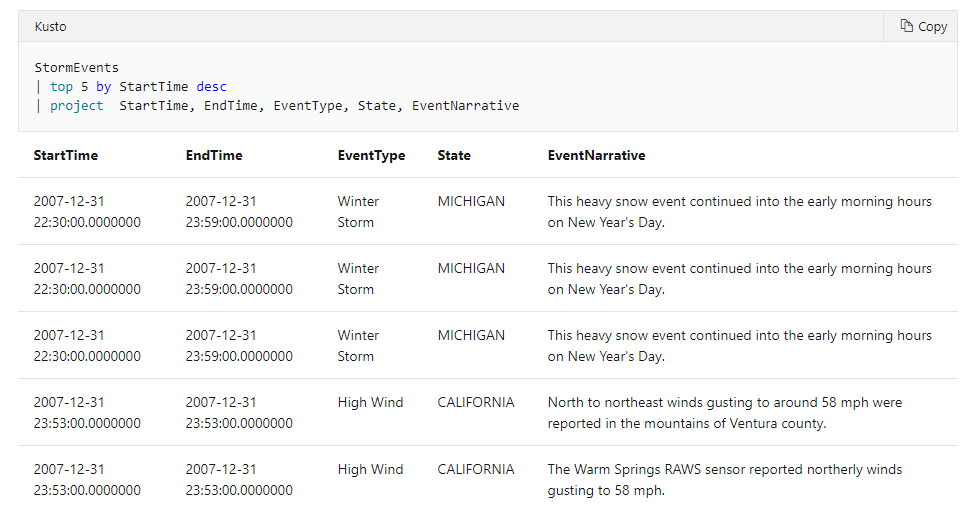
top 最初のNレコードを返却します。desc で降順、asc で昇順です。by 句によって、どのカラムに対してソートをかけるのかを指定します。ほかに null first, null last というオプションを最後につけても構いません。null の順番の指定です。
StormEvents
| top 5 by StartTime desc
| project StartTime, EndTime, EventType, State, EventNarrative
カスタムの列 extend
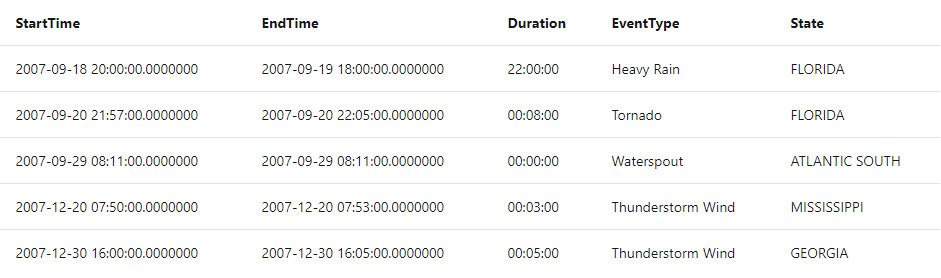
カスタムの列を作りたいときは extend を使います。これ以降、通常の列同じ扱いになります。この例では、Duration という列を終了時間 - 開始時間で計算して作成しています。
StormEvents
| limit 5
| extend Duration = EndTime - StartTime
| project StartTime, EndTime, Duration, EventType, State
件数を数える count
count() は集合関数です。集計で使うようにできているのでそのように呼ばれます。by で指定された列の項目ごとに件数をカウントします。summarize オペレータは集合関数、つまり複数の行にわたっての操作を定義します。カウントも複数の行を扱って件数をカウントするので、summarize を使って、集合関数を適用した結果が event_count という変数に格納されています。
StormEvents
| summarize event_count = count() by State
distinct count
重複がない形の count が dcount です。
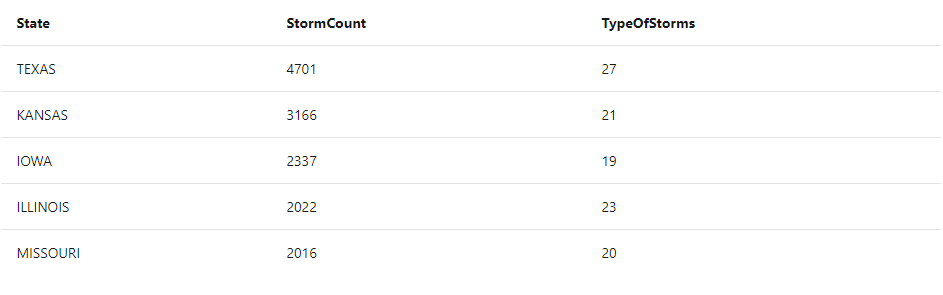
StormEvents
| summarize StormCount = count(), TypeOfStorms = dcount(EventType) by State
| top 5 by StormCount desc
一定の時間ごとに集合関数を適用する bin
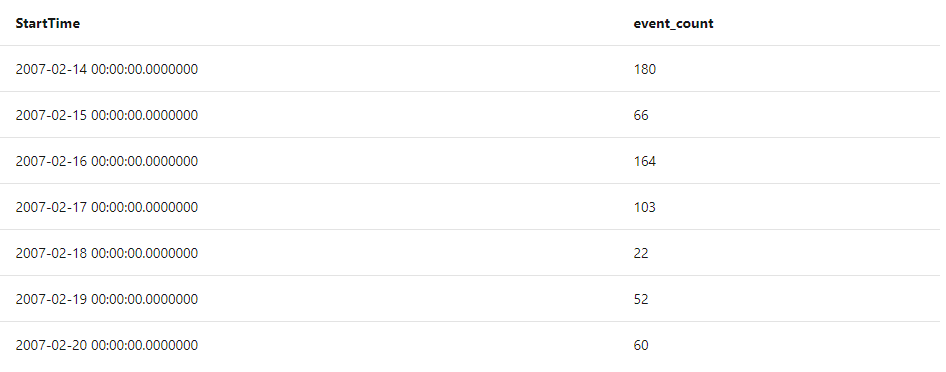
bin関数は、一定の期間ごとのサマリを作ってくれる関数です。ここではStartTime を1日単位でカウントしてくれています。結果を見ると一日毎にカウントがまとめられているのがわかります。
StormEvents
| where StartTime > datetime(2007-02-14) and StartTime < datetime(2007-02-21)
| summarize event_count = count() by bin(StartTime, 1d)
グラフを出力する render
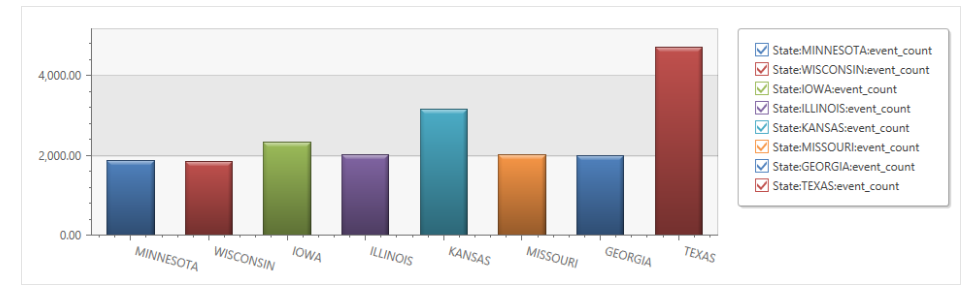
renderによって、グラフを出力することができます。使えるチャートの種類は renderのページで確認できます。簡単にグラフ出力できて最高!
StormEvents
| summarize event_count=count(), mid = avg(BeginLat) by State
| sort by mid
| where event_count > 1800
| project State, event_count
| render columnchart
複数の列でサマリーする
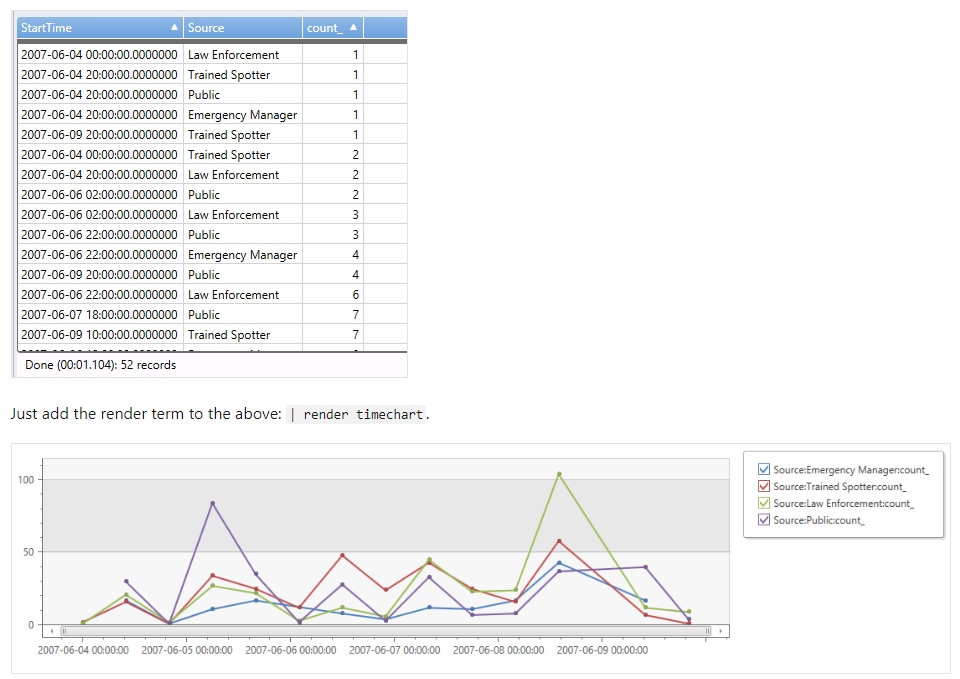
in 句は、特定の列が選択したデータを持ってるもののみを抽出するオペレータです。この例では、サマリを、10h 毎という軸だけではなく、Source つまり、ここで、選択された、Source, Public, Emergency Manager... 等のソースごとに集計をしています。カンマで区切るだけなので簡単ですね。
StormEvents
| where StartTime > datetime(2007-06-04) and StartTime < datetime(2007-06-10)
| where Source in ("Source","Public","Emergency Manager","Trained Spotter","Law Enforcement")
| summarize count() by bin(StartTime, 10h), Source
周期の分析 bin/floor
ここでは、bin のシノニムの floor を使っていますが、ポイントは、% 1d の部分です。1時間ごとで集計するだけではなく、ここでは、% 1d によって、一日のあまりと表現することで、1日のどの時間単に、どれだけの件数があったかを、1日という時間単位で見ることができます。
StormEvents
| extend hour = floor(StartTime % 1d , 1h)
| summarize event_count=count() by hour
| sort by hour asc
| render timechart
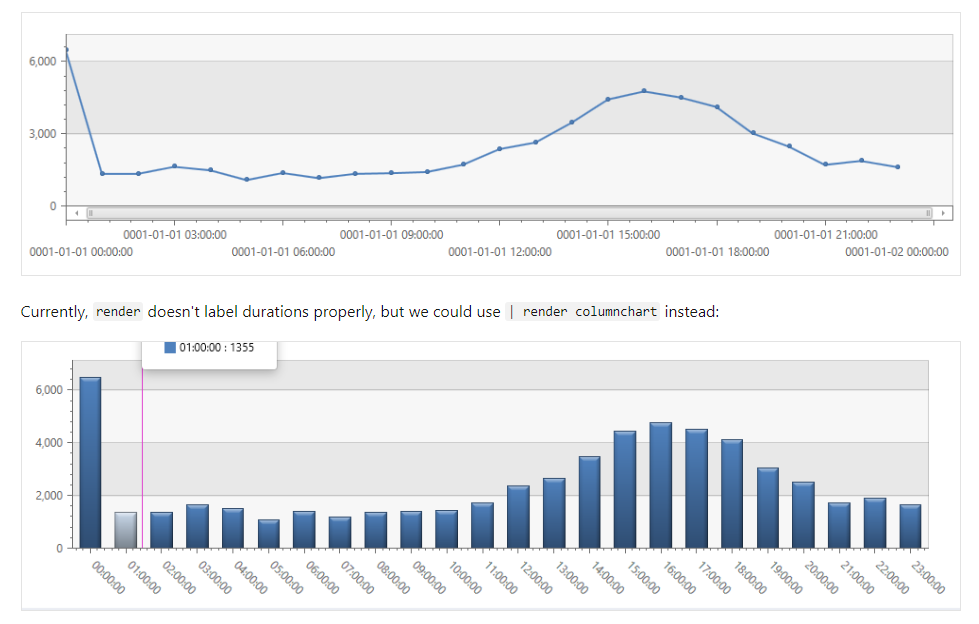
複数軸で、1日の周期的傾向を見る
上記は、時間軸のみでしたが、時間と、州といった2軸で傾向を見ることもできます。カンマで区切るだけです。
StormEvents
| extend hour= floor( StartTime % 1d , 1h)
| where State in ("GULF OF MEXICO","MAINE","VIRGINIA","WISCONSIN","NORTH DAKOTA","NEW JERSEY","OREGON")
| summarize event_count=count() by hour, State
| render timechart
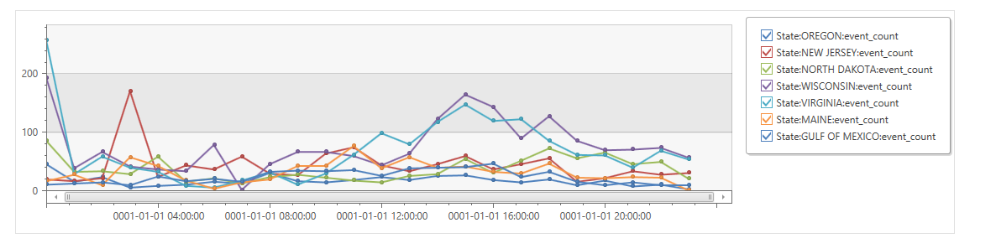
複数のデータの結合 join
雷と雪崩の両方起きた州を見つけたいときはどうしたらいいでしょうか? distict で重複をなくすのはいいとして、join を使うと、両方の条件に一致する州のみをピックアップしてくれます。
StormEvents
| where EventType == "Lightning"
| join (
StormEvents
| where EventType == "Avalanche"
) on State
| distinct State
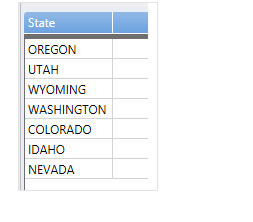
セッションIdが同一の開始時間と終了時間のペアのデータを処理する join
これも join の例ですが、よくありがちな例として、開始時間を持つイベント、終了時間をもつイベントがあって、そのレイテンシを測定したり、観察したいというケースがよくあります。普通は目 grep になりそうですが、join を使うことで、クレバーに表現することができます。session_id が同一であるものという絞り込みをしているのがポイントです。
Events
| where eventName == "session_started"
| project start_time = timestamp, stop_time, country, session_id
| join ( Events
| where eventName == "session_ended"
| project stop_time = timestamp, session_id
) on session_id
| extend duration = stop_time - start_time
| project start_time, stop_time, country, duration
| take 10
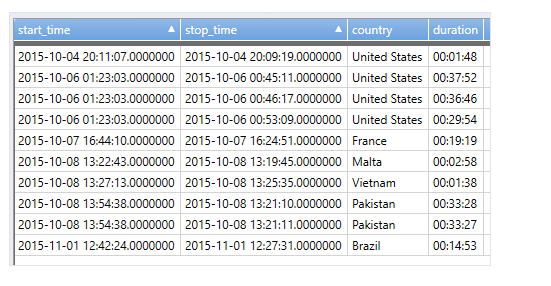
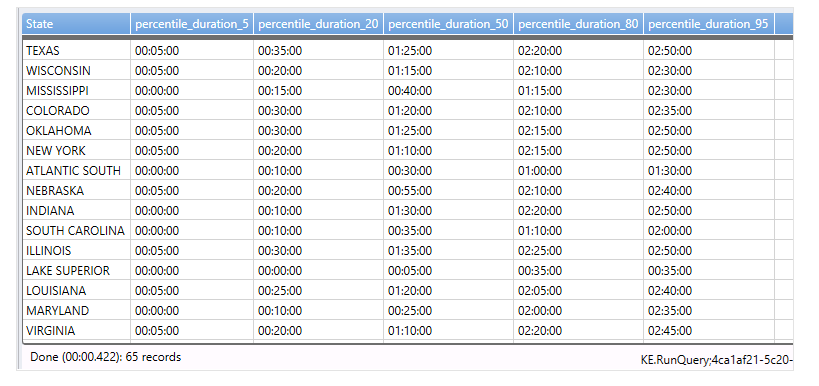
パーセンタイル percentiles
これは、集合の傾向を見たいときによく使われるパーセンタイル形式での集計をサポートしています。パーセンタイルは図の通りで、全体の5%のデータであれば、平均はこれだけ、20%であれば、平均はこれだけ、、、と、集合のパーセンテージ毎の平均値を出したりすることができるものです。
StormEvents
| extend duration = EndTime - StartTime
| where duration > 0s
| where duration < 3h
| summarize event_count = count()
by bin(duration, 5m), State
| sort by duration asc
| summarize percentiles(duration, 5, 20, 50, 80, 95) by State

変数の定義 let
変数の定義も可能です。Kustoクエリーイケメンがよくこれを使っていました。
let LightningStorms =
StormEvents
| where EventType == "Lightning";
let AvalancheStorms =
StormEvents
| where EventType == "Avalanche";
LightningStorms
| join (AvalancheStorms) on State
| distinct State
複数のクラスタ、デーベースにわたった検索 cluster, database and union
複数のクラスタやデータベースにわたった検索をしたいケースがあります。unionオペレータで検索するデータを結合することができて、cluster や database の特殊関数を使うことで別のクラスタや、データベースの表を対象にすることができます。最後の例は複数のテクニックを組み合わせた例になります。
FunctionsLogs
| union cluster('clusterA').database('databaseA').FunctionsLogs, cluster('clusterB').database('databaseB').Logs
| where TIMESTAMP >= datetime(2020-09-24 17:30:00) and TIMESTAMP <= datetime(2020-09-24 18:55:00)
このクエリーのサンプルでは、Summary に詳細な説明がテキストで書いてあって、ある特別な列だけ HttpTrigger Completed .... Duration=22ms とか書いてあります。この22 のみを抽出して、新たな列を作りたいと考えました。そこで正規表現を使います。extract でそれが可能になります。Duration=に続く数値をマッチさせています。1 は最初にマッチしたものを指します。ここで、テキストから取得した、Duration の型は残念ながら string なので、 toint関数で、数値型に変換しています。サマライズの軸を、5秒刻み、Duration(レイテンシ)の平均値、サイト名の結果で、サマリをしたものをタイムチャートにレンダリングしています。
| extend Duration = toint(extract("Duration=([0-9.]+)", 1, Summary))
| order by TIMESTAMP asc
| project TIMESTAMP, EventName, RuntimeSiteName, Summary, Duration
| summarize avg_duration=avg(Duration) by bin(TIMESTAMP, 5s), RutimeSiteName
| render timechart
さいごに
今回は Kusto の基本関数を学びましたが、これだけでも相当レベルアップしている感があります。今後は実業務の中でやりたくなったことを記録していこうと思っています。最後にとても便利なリンクをまとめておきました。kusto は様々なものにつかわれていますので、一度慣れておくと応用がきいて便利ですね!