この記事の目的
Dataikuを利用すると、ノーコードでRAGアプリケーションを開発できます。一方で、回答精度や安定性を高めるためには、開発時の工夫やコードを利用した拡張が必要な場合もあります。
そこで、この記事では、RAGアプリケーション構築において「Dataikuの標準ビジュアル機能で、どこまでできるのか」「拡張が必要な場合、どのように対応すれば良いのか」について説明します。
前提知識・前提情報について
「Dataikuを利用してノーコードでRAGアプリケーションを開発する手順」については、以下のブログやドキュメント等を参考にしていただけます。当記事では、読者の方がこのような内容を実際に試したことがある、もしくは理解していることを前提に、もう一歩踏み込んだ情報を提供します。
Dataikuを使って完全ノーコードで、1時間でRAG作成→AIチャットボットを作ってみた
(中村 祐樹さん Qiita記事)
https://qiita.com/yukinaka_data/items/8270e1a559e8fc3c047d
Dataiku LLMメッシュをつかってRAGをつくってみた
(K.Hさん keywalkerブログ記事)
https://www.keywalker.co.jp/blog/dataiku-llm-mesh-rag.html
Use the RAG approach for question-answering
(Dataiku Tutorial:※英語)
https://knowledge.dataiku.com/latest/ml-analytics/gen-ai/tutorial-question-answering-using-rag-approach.html
はじめに(RAGシステムの全体像)
RAGシステムの全体像は以下の図のようになります。この記事では、以下の図の流れに沿って、説明を進めていきます(吹き出しの中の数字は、当記事の章番号に対応しています)。
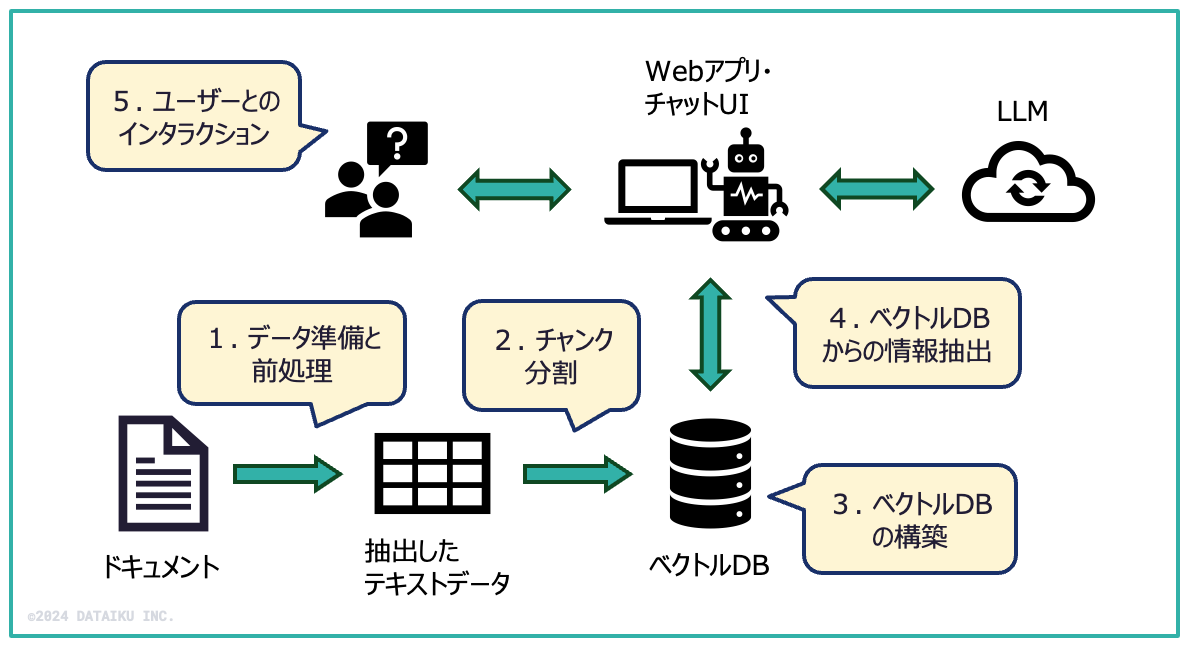
1. データ準備と前処理
まず始めに、RAG対象のドキュメントからテキストを抽出し、必要に応じてテキストのクレンジング・修正を行います。
1) Dataikuにおける対応方法:
ビジュアルレシピ、プラグイン、コードレシピなどを利用して、ドキュメントからのデータ抽出とテキストの前処理を行います。
2) 実装の考え方:
-
PDFファイル、Webサイト(HTMLドキュメント)等からのテキスト抽出は、プラグイン、もしくはコードレシピ(Python/R)を利用して行います。
Dataikuプラグイン「Text extraction and OCR」
https://www.dataiku.com/product/plugins/tesseract-ocr/
参考:プラグインを利用したテキスト抽出の実装例:
Dataiku Gallery: 「LLM Starter Kit」
https://gallery.dataiku.com/projects/EX_LLM_STARTER_KIT/flow/?zoneId=nS8CTF4

-
テキストを抽出した後は、必要に応じて不適切な改行コード、HTMLタグなどをテキストから除去します。(ビジュアルレシピ、コードレシピなどを利用します。)
参考:コードレシピを利用した前処理の実装例:
Dataiku Gallery: 「Advanced RAG」
https://gallery.dataiku.com/projects/EX_ADVANCED_RAG/flow/?zoneId=5bdEBbj
-
関連文章が複数レコードに分割されてしまっている場合など、必要に応じてレコードのマージや統合を検討します。その場合、基本的にはコードレシピを利用した対応になります。
また、次項で説明する「チャンク分割」を意識して、文章構造やセマンティクスを反映させたレコードを作成し、データセットに格納する案も考えられます。
2. チャンク分割
次に、テキストを適切なチャンクに分割し、ベクトルDBに格納します。
1) Dataikuのビジュアル機能(準備レシピ)を利用した対応方法:
準備レシピのステップで「Split into chunks」プロセッサーを利用することで、チャンクサイズ、オーバーラップ、セパレーターを指定してチャンク分割可能です(セパレーターは、正規表現による指定も可能)。
Dataikuドキュメント:「プロセッサーリファレンス - Split into chunks」
https://doc.dataiku.com/dss/latest/preparation/processors/split-into-chunks.html
2) Dataikuのビジュアル機能(Embedレシピ)を利用した対応方法:
Embed(埋め込み)レシピを利用すると、Inputデータセットのレコード単位でチャンクが生成されます。その際、「Document splitting method」の設定でチャンクをさらに分割できます。
Dataikuドキュメント:「Embedレシピ(埋め込みレシピ)の設定」
https://knowledge.dataiku.com/latest/ml-analytics/gen-ai/concept-rag.html#embed-recipe-settings
「Document splitting method」の設定方針:
- すでに適切な粒度・サイズでレコードを作成済みの場合、Embedレシピの「Document splitting method」は「Do not split」を選択する。
- そうでない場合は、「Character count」を選択し、適切な「Chunk size」「Chunk overlap」を設定する。
※適切なチャンクサイズは、データの特性、データサイズ、利用するLLMモデル等の要素によって異なるため、個別の状況に合わせた検討が必要です。もし不明な場合、デフォルト設定のままで進める形でも良いと思います。
3) コードを利用した拡張:
前述のように、データの前処理工程ですでにチャンク分割済みの場合、Embedレシピの「Document splitting method」で「Do not split」を指定すれば良いです。もしくは、Embedレシピの設定で「Character count」を選択して、「Chunk size」「Chunk overlap」に基づきチャンク分割することもできます(LangChainのCharacterTextSplitterと同様の挙動)。
しかし、精度を上げる等の目的で、コンテンツの構造・セマンティクスなどを考慮してチャンク分割を行いたい場合、コードレシピによる対応が必要です。実装例として、以下URLのサンプルを提供しています。(1つ目のレシピでチャンク分割とエンベッド処理、2つ目のレシピで情報抽出を行なっています。)
参考:コードレシピを利用した、チャンク分割、ベクトルDBへの情報格納・情報抽出の実装例
Dataiku Gallery: Advanced RAG
https://gallery.dataiku.com/projects/EX_ADVANCED_RAG/flow/?zoneId=LMMCK3R
注1:上記のサンプルでは、チャンク分割だけではなく、ベクトルDBへの情報格納・情報抽出もすべてコードで対応しています。そのような場合、Dataikuのナレッジバンク(次項参照)は生成されないため、ノーコード(プロンプトスタジオやAnswersプラグイン)でRAGを利用することはできません。このため、ベクトルDBへの情報格納、ベクトルDBからの情報抽出、Webアプリ開発はすべてコードで実装することになります。
用途によっては、チャンク分割のみコードレシピで行い、後続のベクトルDB構築はビジュアルレシピ(Embedレシピ)を利用する方が良いかもしれません。
注2:チャンキングには様々な手法が存在するため、具体的な手法・利用ライブラリー等は、別途検討が必要です(「RAG チャンキング」などのキーワードで検索すると、色々確認できます)。対応方法としては、LlamaIndexやLangchainが提供するSplitterやRetrieverの利用が考えられますが、日本語にはまだ完全対応していないライブラリーも多いようですので、その点も含めて個別の検討・検証が必要となります。
3. ベクトルDBの構築
Embedレシピを定義する際、ナレッジバンク(ベクトルDB)の情報を指定します。
ナレッジバンク(Knowledge Bank)とは?
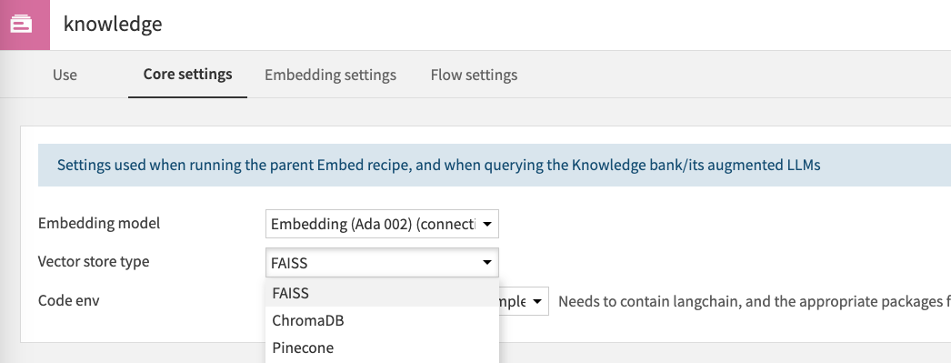
DataikuはベクトルDBを「ナレッジバンク(以下KB)」として抽象化しています。通常、ベクトルDBの実装は「FAISS」を選択すればOKですが、それ以外にも、以下ドキュメント記載のベクトルDB(FAISS、ChromaDB、Pinecone)をサポートしています。
Dataikuドキュメント:「Retrieval-Augmented Generation」
https://doc.dataiku.com/dss/latest/generative-ai/rag.html#vector-store-types
KBの作成方法:
-
Embedレシピを定義する際、「Knowledge bank settings」の「Core Setting」タブで、利用対象のベクトルDBとEmbeddingモデルを指定します。(この時点では、空のKBアイコンが作成されます。)
-
その後、Embedレシピを実行することで、KBの実体が生成されます。
KBの利用方法:
KBから情報を取得する具体的な方法は、次項で説明しますが、コードレシピやWebアプリからは、API経由でKBを操作・利用することもできます。
Dataiku ディベロッパーガイド:「Programmatic RAG with Dataiku's LLM Mesh and Langchain」
https://developer.dataiku.com/latest/tutorials/genai/nlp/llm-mesh-rag/index.html#storing-embeddings-in-a-vector-database
4. ベクトルDBからの情報抽出
ユーザーからの問い合わせ(クエリ)に対する関連ドキュメントをベクトルDBから取得します。
1) Dataikuのビジュアル機能を利用した対応方法:
KB設定の「Use」タブで、情報の取得方法を指定します(「Retrieval-augmented LLMs」)。プロンプトスタジオからRAGを呼び出す場合、この設定が利用されます(PythonプログラムやAnswersアプリから情報を抽出する場合、別の仕組みで取得方法を指定するため、この設定は不要です)。「Use」タグの定義内容については、以下のドキュメントをご参照ください。
Dataikuドキュメント:「Knowledge Bank settings」
https://knowledge.dataiku.com/latest/ml-analytics/gen-ai/concept-rag.html#knowledge-bank-settings
「Improve diversity of documents」設定について
ここで、上記のドキュメントではあまり触れられていない「Improve diversity of documents」について補足します。
「Improve diversity of documents」をチェックしない場合、類似度スコアのみに基づいて、チャンクを取得します。しかし、同じような内容が複数のチャンクに記載されているようなケースでは、同様な情報ばかり取得してしまい、本来有用な別の情報を取得できない可能性があります。そのようなケースでは、「Improve diversity of documents」をチェックすることで、異なった内容のチャンクを取得して、LLMのコンテキストに渡すことができます。
「Improve diversity of documents」の「Diversity factor」設定は、「同じような意味を持つチャンクをどれくらい捨てるか」を制御するパラメータです。以下ドキュメントの「lambda_mult (float)」に該当しますが、この値が0に近いほど、チャンクの多様性を重視する(=クエリとチャンクの類似度には関わらず、すでに取得済みのチャンクと同じような類似度のチャンクは捨てる)ことになります。
LangChain API:「langchain_chroma.vectorstores.maximal_marginal_relevance」
https://api.python.langchain.com/en/latest/vectorstores/langchain_chroma.vectorstores.maximal_marginal_relevance.html
2) コードを利用した拡張:
上記のKB設定では「Maximal Marginal Relevance」に基づいて情報を取得しますが、精度を上げたいなどの目的で、別の手法や各種Retrieverを利用したい場合、コードレシピによる対応となります。
ベクトルDBからの情報取得方法としては、クエリ変換、リランキング、ハイブリッドサーチなど様々なRetrieval手法がありますので、どのような手法が最適かは、やはり個別の検討が必要です。ハイブリッドサーチを利用した情報抽出の例として、DataikuのGalleryでは以下のサンプルを提供しています。
参考:ハイブリッドサーチを利用した情報抽出の実装例:
Dataiku Gallery: 「Advanced RAG」
https://gallery.dataiku.com/projects/EX_ADVANCED_RAG/flow/?zoneId=T6tPm60
また、クエリの動的生成・複数ベクトルDBからの情報抽出・エージェント/ファンクションの利用など、RAGパイプラインを拡張する方法も日々進化しています。このようなエージェント実装も現時点ではコードを記述して対応することになります。
5. ユーザーとのインタラクション
ユーザーからの質問に対して、RAGアプリケーションから回答を行います。ユーザーとのインタラクションに関しては、以下の3つの方法が存在します。
1) Dataikuのビジュアル機能を利用した対応方法(プロンプトスタジオ):
Dataikuのプロンプトスタジオを利用して、LLMにRAGのコンテキスト情報を追加したプロンプトを投げることができます。質問はプロンプトスタジオ上で入力することもできますし、データセットから複数読み込むことも可能です。(具体的な手順は、冒頭のK.HさんブログやDataikuチュートリアルをご参照ください。)
2) Dataikuのビジュアル機能を利用した対応方法(Answersアプリ):
Dataiku Answersというチャットアプリのテンプレートを利用して、UIを利用する方法です。Embedレシピを利用してKBを作成しておくと、ノーコードでRAGアプリケーションを作成できます。(具体的な手順は、冒頭の中村 祐樹さんブログをご参照ください。)
参考:Dataiku Answers
https://www.dataiku.com/ja/製品/の主要機能/dataiku-answers/
※このAnswers機能は、プレビュー版の位置付けであり、製品本体の機能としてはまだ一般提供されておりません。利用されたい場合は、個別にお問合せいただく必要がございますので、その点はご了承ください。
3) コードを利用した拡張(Webアプリ開発):
Dataiku上でWebアプリ(Python、HTML、JavaScriptなどを利用)を開発して、Dataiku
APIと連携したチャットアプリを開発することも可能です。その場合、前述のように任意のRetrieverやエージェントを利用したRAGアプリ実装も可能となります。
参考:Dataiku LLM Mesh関連API
https://developer.dataiku.com/12/concepts-and-examples/llm-mesh.html
Webアプリの実装例については、以下のレポジトリからプロジェクトをダウンロードして、ご自身の環境にインポートして内容を確認することもできます。
Dataikuサンプルレポジトリ:「LLM_STARTER_KIT」
https://downloads.dataiku.com/public/dss-samples/EX_LLM_STARTER_KIT/
※上記サンプルをインポートする際は、以下のドキュメントを参考にして、事前にCode Envのセットアップが必要です。
Dataiku Gallery: 「LLM Starter Kit - Wikiドキュメント」
https://gallery.dataiku.com/projects/EX_LLM_STARTER_KIT/wiki/2/Appendix:%20py_310_sample_llm%20code%20environment
6. 回答精度の評価・LLMOps・自動化
ここまでのプロセスで、RAGを利用したWebアプリを開発できました。一方で、アプリケーションの位置付けや用途によっては、有害な回答・ハルシネーションが発生していないかどうか、回答精度はどれくらい出ているのかなど定量的なテストが必要になるケースが多いと思います。
LLMを利用したアプリケーションのテスト手法、評価指標については、オープンソース系でもRAGAS、TruLensなどいくつかの選択肢があり、今後、Dataikuもそのようなライブラリーや評価指標を組み込んでいく可能性がありますが、現状ではコードレシピを利用してチェックを行う対応となります。
精度評価の具体的な手法は、公開されている情報などを参考にしていただければと思いますが、いったん検証結果・メトリクスをデータセットに格納した後は、Dataikuのダッシュボードで結果を可視化したり、MLOps機能を利用して精度の変化を時系列でチェックすることができます。
Dataikuブログ:「スケッチから成功へ: 高度な RAG システムの構築と評価の戦略」
https://qiita.com/Dataiku/items/4a306ec4f77582ab8724
また、RAGが生成した回答を正解データと比較したり、回答をLLM自身にチェックにさせたりという方法に加えて、Dataikuのラベリングレシピを利用して人が採点するなどの対応も考えられます。
参考:ラベリングレシピを利用した人によるスコアリングの実装例:
Dataiku Gallery: 「Advanced RAG - Human Evaluation」
https://gallery.dataiku.com/projects/EX_ADVANCED_RAG/flow/?zoneId=h2AbQmP
LLM評価 機能について
Dataiku Version 13.3にて、「Evaluate LLM(LLM評価)レシピ」が追加されました。この機能を利用すると、ROUGEやBLEUのような指標やLLMモデルを利用して、回答の精度を評価できます。
この機能を利用するためには、Advanced LLM Meshオプションが必要ですが、生成された回答の精度を評価・可視化・時系列チェックする上では便利です。機能の内容は、以下のドキュメントや動画をご参照ください。
Dataikuドキュメント:「チュートリアル:LLM評価」
https://knowledge.dataiku.com/latest/ml-analytics/gen-ai/tutorial-llm-evaluation.html
動画:「Dtaikuを利用したLLMの評価」
https://youtu.be/nR6NsQt_Izs?si=F0u7dGFBSI6Q4jzB
LLMOps・運用自動化について
実際にRAGアプリケーションの運用が始まると、以下のような課題が出てくると思います。
- 新情報の追加に合わせて、ベクトルDBへのインデックス追加が必要である。
- 回答内容・精度を定期的に評価・テストする必要がある。
- プロンプト・実装内容の改善、テスト、本番環境へのデプロイのサイクルを安全かつ効率的に実施する必要がある。
上記のようなLLMOps・自動化は重要なトピックですが、こちらの内容については、あらためて別記事として扱いたいと思います。
おわりに
当記事で説明したように、RAGシステムの回答精度を上げたり、複雑な業務システムを作っていく上では、コード対応が必要な部分はどうしても発生します。
そのような場合でも、Dataikuには以下のようなメリットがありますので、アナリティクス・機械学習だけではなく、LLMアプリ開発にもDataikuを積極的にご活用いただければと思います。
- 複数のプロンプト、データ変換、エージェントが関連する複雑なデータパイプラインにおいて、データパイプラインの全体像を可視化し、システムのブラックボックス化を避けることができる。
- 生成コンテンツ・回答精度にガードレールをかけて、アプリケーションのセキュリティ・信頼性を高めることができる。
- コードを記述してRAGワークフローを開発するだけではなく、プロンプトスタジオやLLMレシピを利用して、ビジュアル環境でアドホックにデータ抽出やタグ付けを行う選択も可能である。
- 開発者だけではなく、受け入れ側の業務部門も共通画面でリアルタイムに回答精度やプロジェクトの内容をチェックできる。