検索拡張生成(RAG)は、ドメイン固有の知識を大規模言語モデル(LLM)に統合し、高度にカスタマイズされ、文脈に関連した応答の生成を可能にします。たとえば、RAGを活用することで、製品ドキュメントやチュートリアルを用い、チャットボットは特定のツールや主題について洞察力に富んだ正確なサポートをユーザーに提供できるようになります。
ドキュメントデータベースから基本的なRAGシステムの初期セットアップを行うのは簡単そうに見えますし、満足のいく結果が得られるかもしれません。しかし、実際のところ、難しいのはこれらの初期結果を評価して改善することです。
この記事では、ベースラインのRAGパイプラインの限界に焦点を当て、これらの課題を克服するための方法を紹介します。さらに、RAGシステムの構築と強化をガイドする系統的なアプローチをご紹介します。実際にアプリケーションで利用する際に参考にしてください。
1. ベースラインRAGの限界とは
RAGの基礎: 基本知識を理解する
RAGパイプラインがどのようなものかを知るために、具体的な例を掘り下げご案内しましょう。この例ではDataikuユーザー向けに、ユーザーサポートチャットボットを作成しました。以下に示すように、パイプラインには3つの主要なコンポーネントが含まれています。
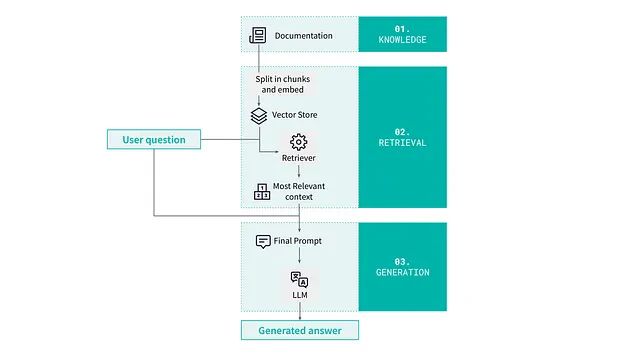
RAGビルディングブロック
まず初めのシステムのコンポーネントは、ユーザーの問い合わせに対応するためのすべての関連情報を含まれているナレッジのコーパスです。この例の場合、関連情報とは、一般的な製品ドキュメントやユーザーチュートリアルとなります。
ユーザーが質問すると、検索コンポーネントが機能します。その役割は、ユーザーのクエリーに対して、知識コーパスの最も適切なセグメントを識別することです。今回採用する、コーパスをいくつかのかたまりに分割して検索するという方法は、このプロセスの品質を確保する上で極めて重要です。
最後に、生成コンポーネントは、ユーザーのクエリーと以前に取得したかたまりに基づいて、最終的な回答を提供します。このステップはLLMに依存します。
RAGの弱点:よくある失敗タイプ
以下の3つのコンポーネントのどれかに欠陥があると、ユーザーに対する応答が不十分になる可能性があります。
- まず、ユーザーのクエリーに指定された関連情報がコーパス内に見つからない場合、モデルは必然的に失敗します。
- 次に、関連情報がコーパス内に存在していても効果的に取得されなかった場合、結果は同じままになります。
- さらに、コーパスから関連する要素にアクセスできるにもかかわらず、重要な情報が、取得されたコンテキスト内の無関係で詳細な情報に埋もれ隠れている場合 、生成ステップが失敗する可能性があります。
これらそれぞれの失敗タイプを示す例を以下の表に示します。
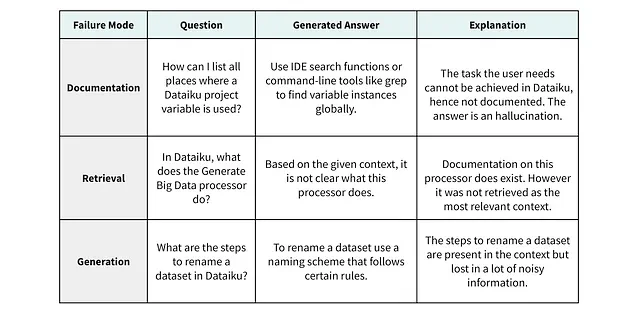
ベースラインRAGの失敗タイプ
2. RAG システムを次のレベルに引き上げます
これらの問題に対処するには、RAGパイプラインの3つのコンポーネントのそれぞれを強化する実用的な方法を採用します。以下では、これらの方法のいくつかを取り上げます。
ナレッジコーパスの課題への対処
特定の質問に関連するファクトがナレッジコーパスにない場合は、追加の情報源を含めたり、既存の情報源からテキストだけでなく表や図も利用するようにします。
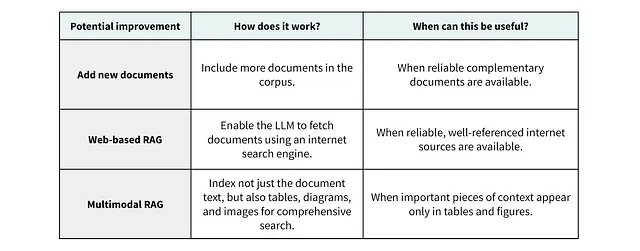
ナレッジ コーパスの課題に対処するアプローチの例
取得パフォーマンスの最適化
よくある状況は、関連するファクトが知識コーパスに含まれているにもかかわらず、検索ステップでそれらを特定できない場合です。この場合、個々のかたまりの関連性を高めて自己完結型にすること、検索クエリーを変更すること、または別の検索方法を使用することを試します。
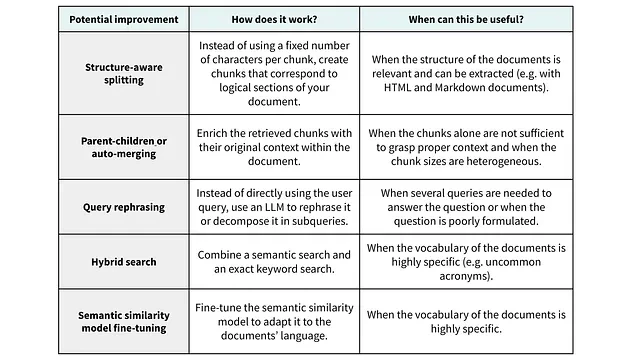
取得パフォーマンスを最適化するためのアプローチの例
生成品質の向上
コンテキストの正しい部分が取得されてプロンプトに含まれている場合でも、LLMが適切な応答を生成できない可能性があります。この場合、迅速なエンジニアリング技術またはより強力なモデルを使用します。
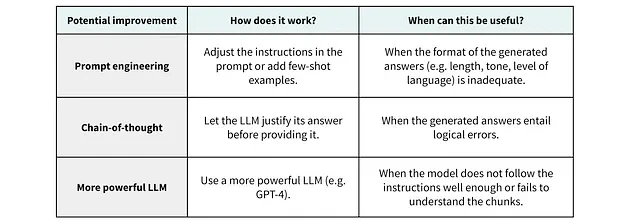
生成品質を高めるためのアプローチ例
3. ゼロから1へ: 理想的なRAGモデルを構築するための方法論的探求
継続的な改善によるベースラインレベルのモデルの最適化
RAGパイプラインの3つのコンポーネントのそれぞれを改善する方法は無数にあります。利用可能なオプションを体系的に探索して選択するには、反復的なアプローチが必要です。以下の図に示す方法論を採用することをお勧めします。
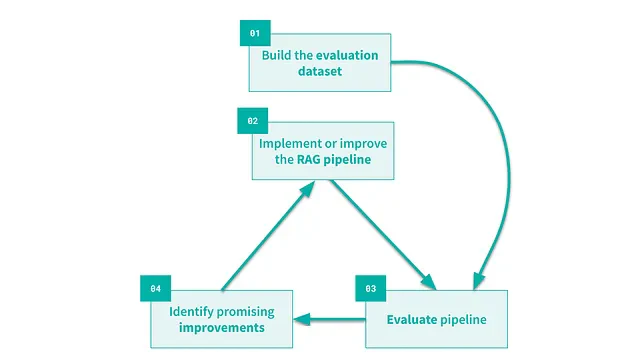
ベースラインRAGモデルを改良するための反復プロセス
- まず、評価データセットを構築します。質問とそれに対応する参考回答を含める必要があります。このデータセットは手動でキュレーションすることも、LLMを使用して自動生成することもできます。自動化されたアプローチを選択する場合は、生成されたクエリーの関連性を確認することが重要です。
- RAGパイプラインを構築または改善します。
- このパイプラインを評価データセットで実行し、モデルのパフォーマンスを評価します。これには、次のセクションで説明する特定の指標の計算と、誤った回答の定性分析の両方が必要となります。
- ステップ3で実行した分析に基づき、考えられるパフォーマンスのボトルネックを特定します。これは、最も有望で可能性のある改善策を決定するのに役立ちます。このような改善を実装するには、ステップ2に戻ります。
この一般的なアプローチは単純そうに見えますが、RAGの領域では、とくに評価指標の定義が困難です。この課題にどのように対処できるかを検討してみましょう。
成功の定量化: RAGシステムのメトリクス
従来の機械学習シナリオでは、モデルの答えと参照の答えを比較することが一般的です。この方法は、期待される応答にできるだけ近い応答を生成することが目的であるRAGアプリケーションにも当てはまります。これを説明するために、次の例を考えてみましょう。

上記のシナリオでは、生成された回答は正しいですが、参照回答の文言と正確には一致しません。この場合、回答の正しさを評価するには、評価指標は、言語の微妙な点をきちんと評価できるものでなくてはなりません。この目的のために、いくつかの評価アプローチが存在します。
- 最初は、人間のレビュー担当者が手動で結果を検査し、フィードバックを提供します。この定性的評価はパターンを明らかにするのに役立ちますが、規模を拡大するのが難しく、人間の偏見の影響を受けやすいものでもあります。
- 代わりに、BERTスコアのような統計的手法を用い、候補と参照回答の間の類似性を測定します。
- 最後は、RAGAS、Trulens、Deepevalなどのモジュールで、「LLM-as-a-judge」 フレームワークを使用して評価を自動化する方法です。この方法では、LLMに質問、参照回答、および生成された回答が提供され、生成された回答を採点するように求めます。このアプローチには拡張性がありますが、コストや透明性の欠如などの欠点があります。とくに、LLMは偏った評価者であると認識されており、これらの偏りを軽減する方法の発見に焦点を当てた研究が進行中です。
ただし、精度の指標だけに依存するだけでは不十分ですね。別のシナリオを考えてみましょう。

この場合、生成された回答は明らかに間違っており、さらなる調査が必要と示唆されます。取得したコンテキストに答えが存在するかどうか、またはモデルがドキュメントに基づいていない応答を提供したかどうかなどの質問が表示されます。これらの問い合わせは、以下の図にまとめられているように、RAGに合わせた特定の指標の重要性を強調しています。
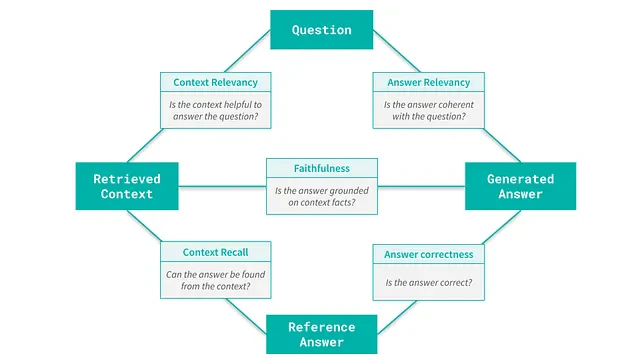
RAGパイプラインを評価するための5つの主要な指標
回答の正しさに関して前述したように、これらの指標の評価は手動で行うことも、「LLM-as-a-judge」 アプローチを通じて行うこともできます。唯一異なるのは、指標へのインプットとして何を使うかということです。
たとえば、忠実度の指標は、生成された回答が取得されたコンテキストと適切に一致しているかどうかを評価します。この指標に対するパフォーマンスが低いということは、モデルが提供されたコンテキストから切り離された応答を生成していることを示唆しています。
結論
堅牢な反復手法と、ガイドとなる一連の指標を用い、ニーズに合ったRAGシステムを作成および改善することができます。以下の重要なポイントを覚えておいてください。
- RAGパイプラインには、拡張のための多数の手段があります。わずかな調整でも大幅な改善が得られる場合があります。幸いなことに、LangChainやLlamaIndexなどのオープンソースパッケージにより、高度なRAGテクニックを実装するためのアクセス可能な手段を利用できます。
- RAGソリューションは、万能ではありません。最適なアプローチは特定の使用例によって異なり、本格的なベンチマークが必要です。
- RAGのこのようなベンチマークを確立するには、主に生成モデルの複雑な性質と不透明さにより、特有の課題が生じます。包括的な評価フレームワークを採用することが不可欠です。
- 自動化された指標は、人間の評価基準と一致していることを確認するための徹底的な検証を行った上で、慎重に使用する必要があります。 RAGをうまく利用するには、正確さだけが重要ではないことを認識することも重要です。レイテンシ、コスト、保守性などの要因が、全体的な効率に重要な役割を果たします。
すでにDataikuをご利用の場合は、この記事全体で紹介している再利用可能なDataikuデモを使用して、RAGプロジェクトをすぐに開始できます。Dataikuを使用することで、かたまりの作成、埋め込み、カスタマイズ可能なチャットボットインターフェースの作成ができるノーコードツールを使用して、包括的なベースラインRAGパイプラインを迅速に開発できます。高度なユーザーの方は、コーディング機能を活用してベースラインのアプローチを調整し、さらなるカスタマイズも可能です。
LLMに関する技術的なコンテンツをご希望ですか?
Dataikuの高度な機械学習の研究者とデータ専門家による専用のMediumページである「Data From the Trenches」(英語)ご覧ください。最近の記事には、マルチモーダルLLM、LLMの量子化、自由形式の質問に答えるためのWebの活用などのトピックが含まれています。
原文:From Sketch to Success: Strategies for Building & Evaluating an Advanced RAG System