はじめに
こんにちは、積立お兄さんです。
大企業新卒3年目のAlteryx初心者です。
ひょんなことから「365日後にPredictive Masterになる!」という目標を掲げて、公式のWeekly Challengeにコツコツ挑戦しています。
この記事では、Alteryx歴3か月の平社員が、実務で生かせそうなノーコード分析力をどうやって身につけていくかを記録&共有していきます。
- 目標:ETLツールを自在に使いこなせるようになる
- 対象読者:Alteryxを始めたばかりの方/Weekly Challengeの解説が欲しい方
今回のチャレンジ:Weekly Challenge #006
- タイトル:[Weekly Challenge #001:4月のクリプトアナリティクス] LINK
- レベル感:中級者向け
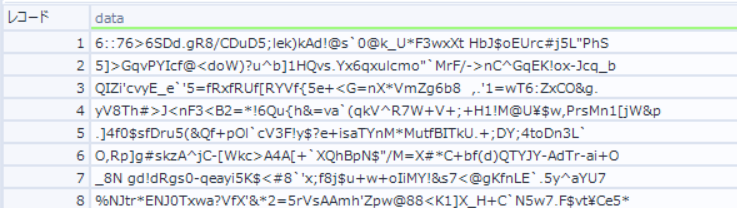
- ゴール:入力データの暗号?を解読する。
- 入力
解いた流れと使用ツール
ワークフロー全体
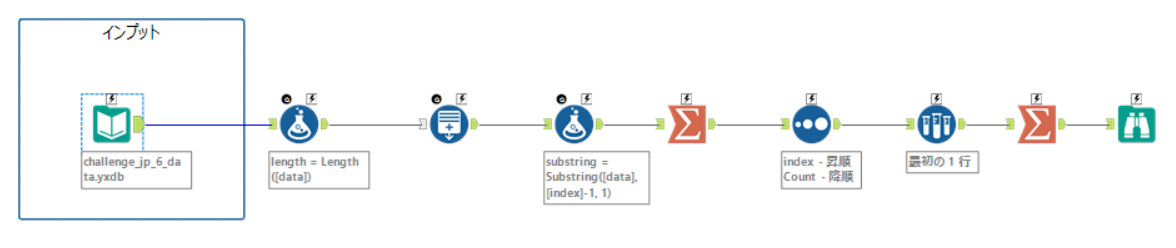
処理の手順と解説
data列の各値は同じ文字数であり、n文字目の文字を見て最頻の文字を採用していくことで、あるメッセージが浮かぶようになっている。それを解読するために以下の手順でフローを構築した。
-
フォーミュラツール :各行の文字数をカウントする(後の処理で使用する)
-
行生成ツール :data列の各文字列に対して、文字数分の行を作成する。index列を作成することで、data列の各値に対して、indexのn番目ごとに最頻がどれかを確認するための準備を行った。(日本語下手)
-
フォーミュラツール :substring()を使用して、data列の各値に対して一文字ずつ抽出を行う。
substring(対象の文字列, 開始位置, 長さ)
対象文字列:[data]
開始位置:[index]-1
長さ:1
対象文字列はいわずもがな。開始位置は0対象文字列の0番目から指定する。今回の場合は、indexが1からスタートしているので、[index]-1とすることで1文字目から順番に1文字ずつ抽出するようにしている。

-
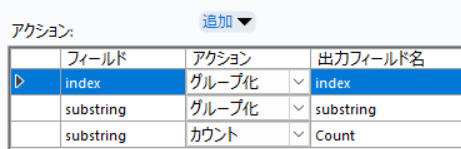
集計ツール :indexとsubstringでグループ化し、substringでカウントを行う。
各indexごとに最頻の文字を選択するため、各indexごとに各文字数をカウントする。
-
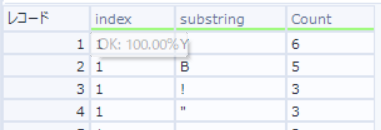
ソートツール :indexで昇順、Countで降順ソート。
-
サンプリングツール :indexでグループ化し、最初の1行目のみをサンプリングする。こうすることで、各indexの最頻の文字を抽出することができる。
-
集計ツール :substring列を連結させる。
詰まったポイントとその解決
-
問題1:ある文字列から1文字ずつ抽出する方法がわからない
→ フォーミュラツールのsubstring()を使用することで、1文字ずつ抽出することができる。 -
問題2:最頻の文字を抽出する方法がわからない
→ 初め、集計ツールを使用して、その中の最頻モードを使おうとしたが、それだと1文字ずつ設定する必要があり、汎用性が無かった。
→ カウントしてソートし、その1番上の行を抽出するようにしたことで、シンプルで簡単になった。
結果と出力確認

→正しい出力フォーマットで、指定要件を満たしていました!
今日の学び・振り返り
- 新しく覚えたツール:フォーミュラツールのSubstring関数
- 工夫ポイント:最頻の抽出方法(↑で解説済み)
- 実務への応用:正直実務で使用するかはわからないです。ただ、文字を抽出する方法を知れた。
次回予告
次は【Weekly Challenge #007】に挑戦予定!
さらっと進めましたが、実は005をスキップしております。問題の意味が頭の悪い私にはわかりませんでした...
タグ
Alteryx weekly Challenge データ分析 Predictive Master 365日チャレンジ ノーコード