はじめに
機械学習は大前提として、学習データとテストデータの分布が同じである必要があります。
練習時の的が、テスト時には違うところにおいてあっては的に当てることはできません。
そこで Adversarial Validation を利用しデータ分布が異なる特徴量を炙り出すことで上記の的の位置を揃えることができます。
今回はそんな特徴量選択しての Adversarial Validation を紹介します。
Adversarial Validation
Adversarial Validation について説明します。
手順
- 学習データに0、テストデータに1とそれぞれ適当なラベルをつけ、一つのデータに連結
- 上記データセットを学習
- 学習済みモデルから重要度を算出
- 重要度の高い特徴量を削除
このとき、重要度が高い変数とは
学習とテストを分けることができるデータ
→ 学習とテストで分布が明らかに違うデータとしてみなすことができます。
このような変数を取り除くことで学習データとテストデータの分布を寄せようという特徴量選択方法になります。
実験
今回はタイタニックデータに人口的な分布の異なる特徴量を加えて効果を実験していきたいと思います。
https://www.kaggle.com/c/titanic/overview
前処理は以下を参照しました。
https://www.kaggle.com/arthurtok/introduction-to-ensembling-stacking-in-python
人口データの作成
今回は特に学習データとテストデータの分布が異なる特徴量 feature_1 を作成しました。
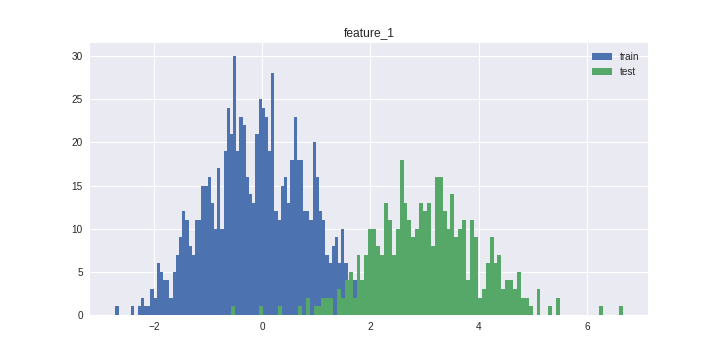
Adversarial Validation
以下は人口的な特徴量の作成とテストスプリットになります。
今回は簡易的に hold-out でスプリットしますが、データ分布に強く依存するため,K-Fold cross validation をした方がより正確な評価が出ると思います.
# 人口データ作成
train['feature_1'] = np.random.normal(loc=0, scale=1, size=len(train))
test['feature_1'] = np.random.normal(loc=3, scale=1, size=len(test))
# ラベル作成
train['test'] = 0
test['test'] = 1
# シャッフル
df = pd.concat([train, test]).drop(['Survived'], axis=1)
df = df.sample(frac=1, random_state=9).reset_index(drop=True)
# テストスプリット
split = int(len(df)* 9/10)
train = df.iloc[:split]
test = df.iloc[split:]
このデータを LightGBM で学習させます.
roc_auc : 0.9643574297188755
と,かなりの精度で学習データとテストデータが判別できてしまっています.
ここで gain による重要度をみてみましょう
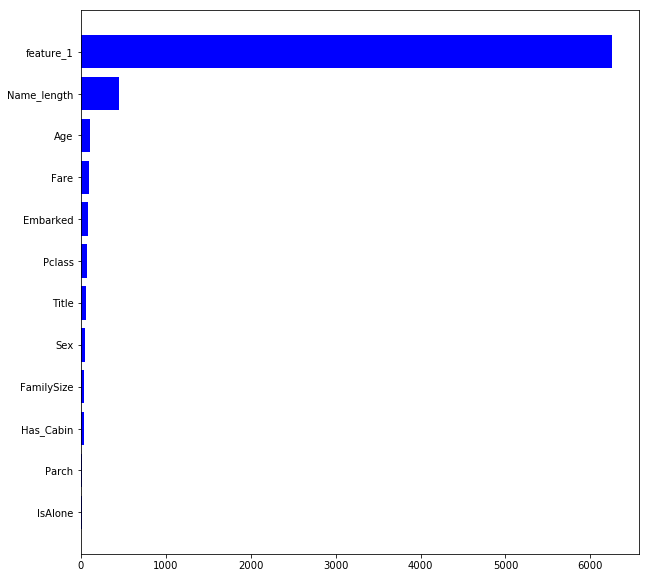
学習データとテストデータでは上記のように feature_1 を見れば大まかに予測できてしまっているようです.
このように, Adversarial Validation では,学習データとテストデータの分布が大きく異なる特徴量をあぶり出すことができます.
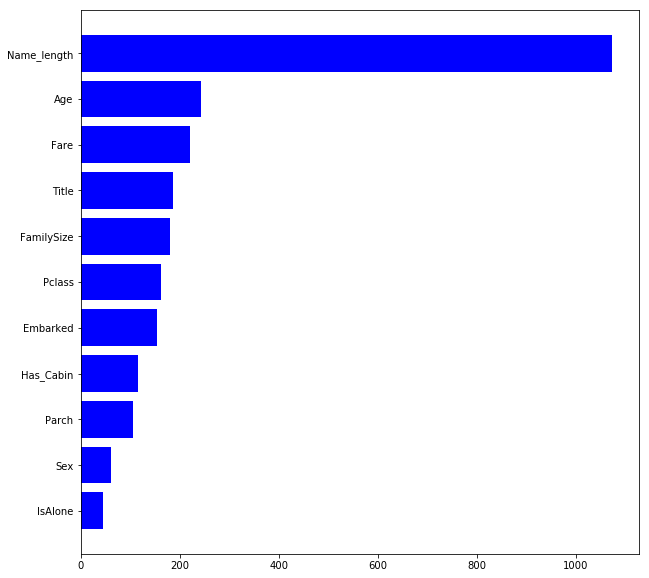
この feature_1 を除いてもう一度,学習データとテストデータを分類してみます.
roc_auc : 0.5670180722891566
このようにテストデータと学習データが十分に割り振れていないため,学習データとテストデータの分布が同じ事がわかります.
gain 重要度
おわりに
今回は Adversarial Validation を用いた特徴量削減を行いました.
注意点としては以下です.
- 重要度にバイアスがかかる場合がある https://aotamasaki.hatenablog.com/entry/bias_in_feature_importances
- 時系列データでは値が削除されすぎてしまう
頭がいい特徴量削減だなと思いました.
参照