はじめに
恥ずかしながらいまさらSwinTransfomerをしり論文を読み面白かったため論文中の主なアイデアをまとめました.
概要
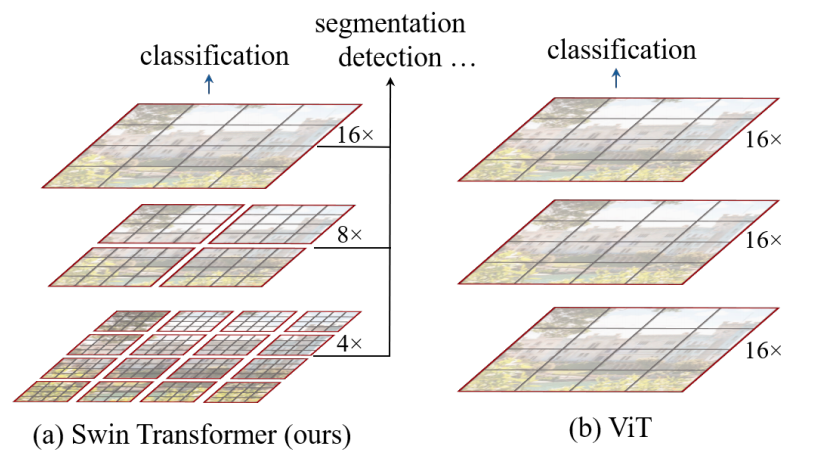
- SwinTransfomer は ViTでは考慮できない階層的な特徴量を学習するモデル
- 主なアイデア
- PatchMerging : 階層が深くなるにつれて特徴量マップが小さくなるように設計し階層的な特徴量を取得
- W-MSA と SW-MSA の二つの Attention : windowサイズを不均一にすることでwindow間のインタラクションを考慮
- Object Detection, Semantic Segmentation分野で当時のSoTA
背景
現在,CV分野で人気のViTですが,以下の問題があります.
- パッチサイズが固定になってしまうため,階層的な特徴量が取得できずに物体検出などのタスクに向いていない
- 高解像度の画像では画像サイズの二乗で計算量が増えるため計算時間の削減が必要である
SwinTrasnfomer では上記の問題を解決するために提案されたモデルであり, Object Detection, Semantic Segmentation でSoTAを達成したモデルとなります.
主なアイデア
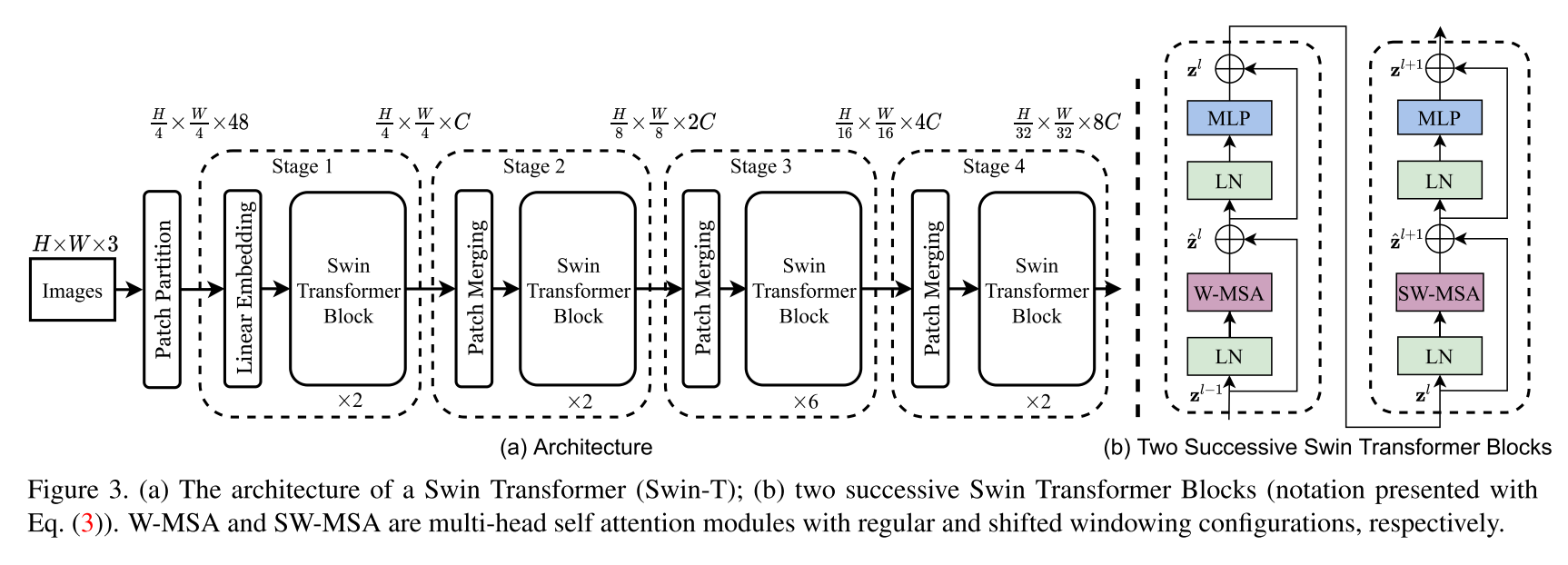
PatchMerging
まず,層が深くなるにつれて特徴量マップが小さくなる機構「PatchMergin」について説明します.
これは近傍の 22C のデータを一列に並べ線形変換して W/2 * H/2 * 2C へとデータを縮小します.
これにより,Pooling層のように層が深くなるにつれて階層的に特徴量を抽出できます.
W-MSA と SW-MSA
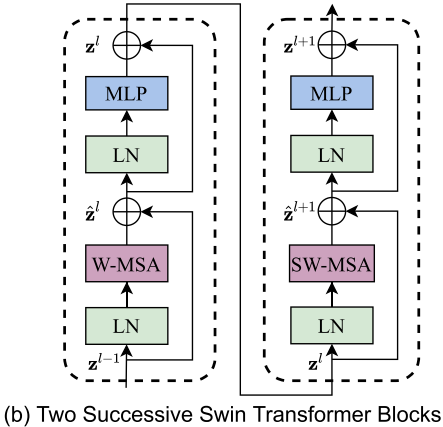
W-MSA(Window based Multihead Self Attention)
SwinTransfomerには二つのAttentionが含まれています.その一つが W-MSA になります.
これはパッチをWindowという単位にまとめてwindow内のパッチ間にAttentionをにかけることで高解像の画像でも効率的に学習を行うことができます.従来の MSA では 4hwC^2+2(hw)^2C の計算量が必要なのに対して, W-MSA では 4hwC^2+2M^2(hw)C で計算が可能となります.従来の手法では画像サイズの二乗に比例するのに対して,提案手法ではWindowサイズの二乗で計算ができるため,高解像度画像でも効率的に学習ができます.
SW-MSA(Shifted Window based Multihead Self Attention)
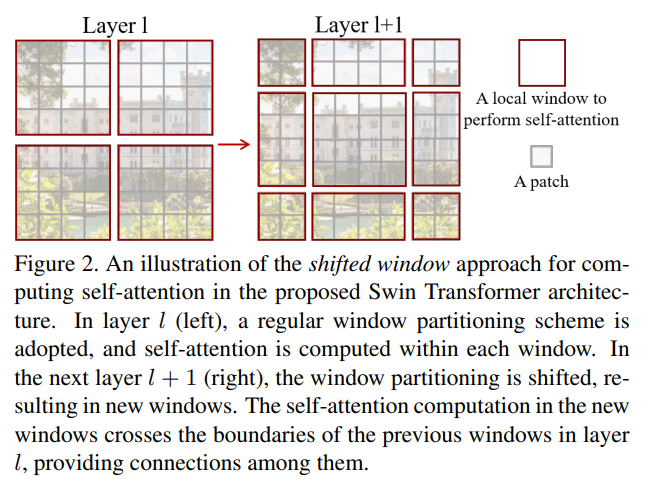
次に SW-MSA について説明します.
これは偶数番目のWindowサイズを半分にすることでパッチ間のインタラクションを考慮した学習が可能になります.
上記二つのAttentionを利用して効率的に学習が可能となるのがSwinTransfomerが優れている点になります.
結果
Swin-T : C=96, 層数 = {2, 2, 6, 2}
Swin-S : C=96, 層数 = {2, 2, 18, 2}
Swin-B : C=128, 層数 = {2, 2, 18, 2}
Swin-L : C=192, 層数 = {2, 2, 18, 2}
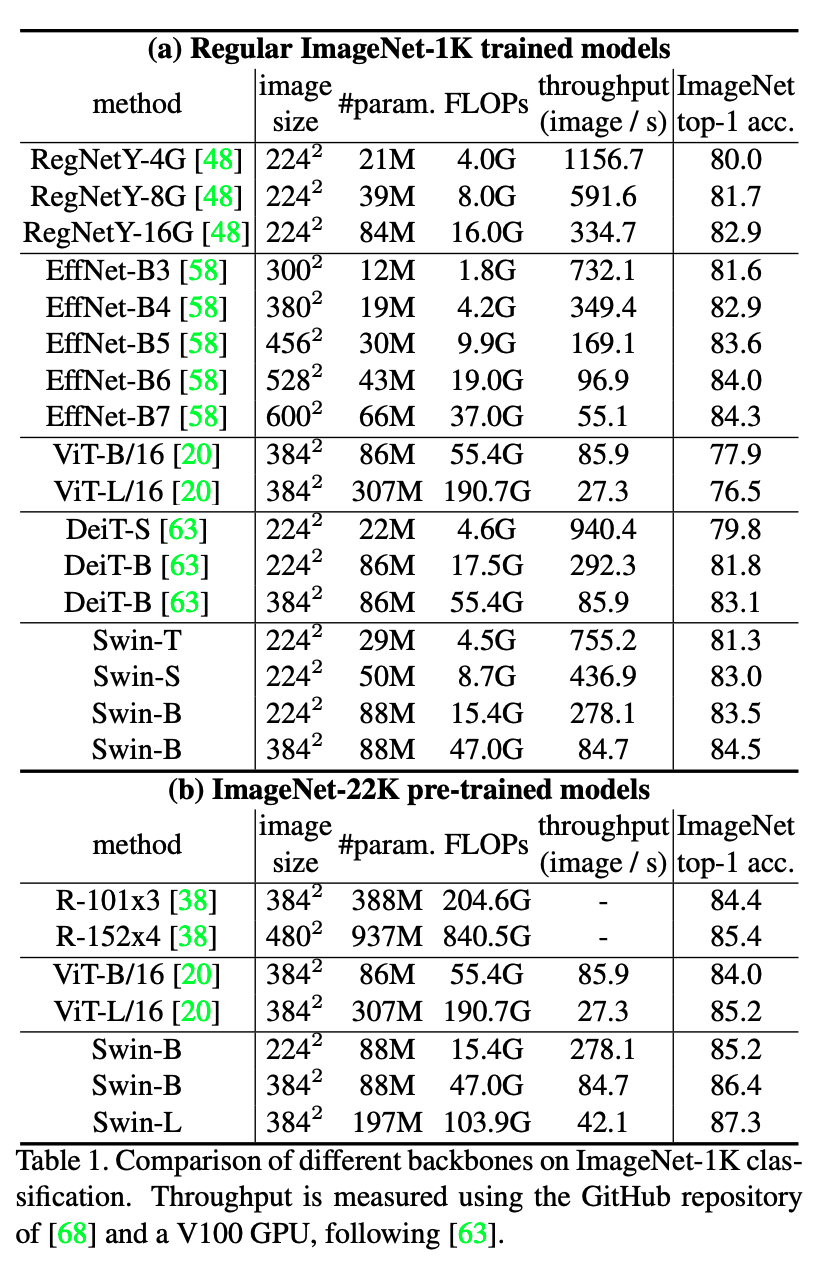
ImageNetの分類においても高い精度を記録していることがわかります.
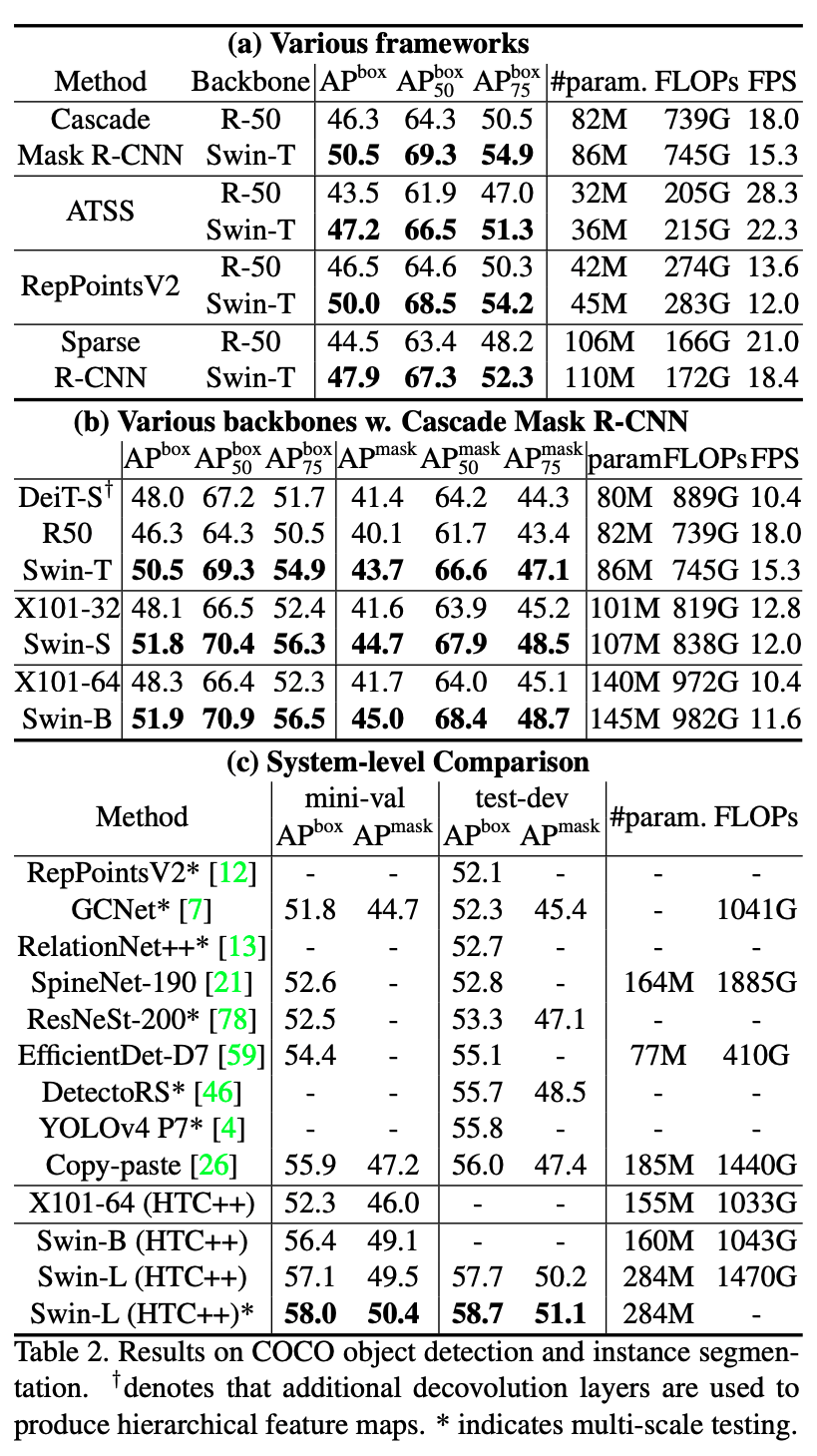
COCOデータセットの物体検出でも他のどのモデルよりも高い性能を示していることがわかります.
詳しい条件や詳細などは本論文をご覧ください.
まとめ
まとめると…
- SwinTransfomerは階層的なアーキテクチャとウィンドウ間のインタラクションを考慮して学習が可能
- 従来の学習よりも高解像度の画像でも効率的な学習が可能
- Object Detection と Semantic Segmentation の分野で高い性能を誇る
非常に勉強になりました.面白かったです.