はじめに
本記事では PySpark でデータ分析をされている初心者の方向けに window 関数の仕組みを解説し、簡単なデータを例に window 関数を使ってみたいと思います。
window 関数はデータの集計をする際に使用され、データ分析において必須といっていいほど重要な関数になります。
PySpark で window 関数を使いこなせれば強力な武器になることは間違いないのですが、初学者にとって概念の理解や慣れない PySpark での作業に難しさを少し感じる方も多いのではないでしょうか。
SQL では window 関数に関する文献はわりと多いのですが、PySpark で解説されている日本語の文献はあまり見かけないので今回記事にしてみました。
本記事のゴール
- window 関数とは何かを理解する
- window 関数を理解した上で PySpark 上で簡単なデータを元に利用できる
window 関数とは
window 関数はデータを集計して計算する際に、計算する範囲を区切ることができる関数です。
例えば平均気温を求めたいとなったとき、すべての地域をまとめた平均気温を求めるのではなく、地域ごとに平均を求めたいときなどに window 関数は使用されます。
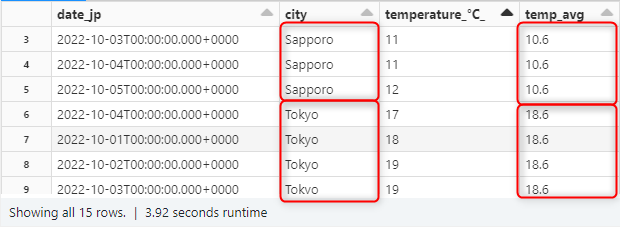
ここで group by と同じではないかと思われた方もいらっしゃるのではないのでしょうか。
確かに考え方は非常に似ているのですが、決定的に異なる点があります。
それは window 関数は区切られた範囲の中で1行ずつすべてに計算結果を出力してくれる点です。
対して、group by を使用した場合、グルーピングされた数の行のみ、つまり各拠点の行の分しか集計結果は出力されません。
つまり window 関数には各行に対して集計した値の情報を持たせることができ、さらなるデータの加工や機械学習分野における特徴量にも応用できるようになるのです。
これからの章で実際に window 関数を使用してみましょう。
作業環境
・Databricks を使用
・バージョン: Apache Spark 3.2.1
window 関数を使用してみる
まず、必要なモジュールのインポートを行います。
window関数 はインポートして呼び出す必要があります。
from pyspark.sql.functions import *
from pyspark.sql.window import Window
次に簡単なデータを用意しましょう。
日付ごとに日本の3拠点で気温が記録されたデータを作成します。
※データはダミーであり、実際に記録されたものではありません。
data = [
('2022-10-1 00:00:00','Tokyo',18),
('2022-10-1 00:00:00','Sapporo',10),
('2022-10-1 00:00:00','Naha',25),
('2022-10-2 00:00:00','Tokyo',19),
('2022-10-2 00:00:00','Sapporo',9),
('2022-10-2 00:00:00','Naha',26),
('2022-10-3 00:00:00','Tokyo',19),
('2022-10-3 00:00:00','Sapporo',11),
('2022-10-3 00:00:00','Naha',26),
('2022-10-4 00:00:00','Tokyo',17),
('2022-10-4 00:00:00','Sapporo',11),
('2022-10-4 00:00:00','Naha',24),
('2022-10-5 00:00:00',"Tokyo",20),
('2022-10-5 00:00:00','Sapporo',12),
('2022-10-5 00:00:00','Naha',26)
]
# データフレーム作成
df = spark.createDataFrame(data, ["date_jp","city","temperature_°C_"])
df = df.withColumn("date_jp",to_timestamp(col("date_jp")))
display(df)
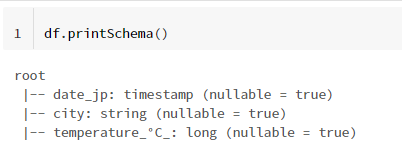
データ型も確認しておきます。
時系列を timestamp 、 地名を文字、気温を数値として扱っています。
実際に window 関数を使用していきます。
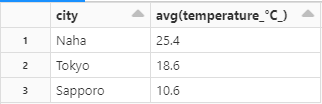
まずは、各拠点ごとに平均気温を出してみましょう。
まず window 関数で計算する範囲の定義を行います。
window を定義する際の構成は基本的に以下の3つです。
・partititonBy
partition の役割は group by にあたる部分ととほぼ同じです。引数に指定するカラムによって集計する範囲を区切ります。
・orderBy
orderBy の役割は引数に指定するカラムでデータを並び替えることができます。集計方法によってはデータの順番が重要になることがあります。
・rowsBetween
rowsBetween は partitionBy で区切った範囲からさらに行単位で計算する範囲を絞ることができます。
第一引数と第二引数で partition 内のさらに計算する範囲を指定します。
今回は全日付における平均気温を求めますので、rowsBetween の範囲は partition の全範囲(sys.maxsize が実質行の最大の範囲を表す)で指定しております。
w1 = Window.partitionBy(col("city")).orderBy("date_jp").rowsBetween(-sys.maxsize,sys.maxsize)
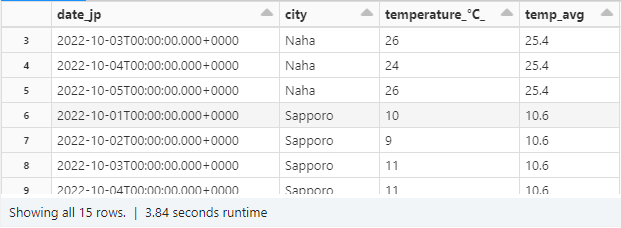
実際に定義した window で平均を求めていきます。
平均を求める際に avg 関数を使用し、引数には気温が記録されているカラムを選択します。
そして定義した window の範囲で計算を行うには window を over の引数に指定すれば OK です。
これで計算した平均を withColumn で新しいカラムを作成して格納すれば完了です。
# 平均
avg_val = avg(col("temperature_°C_")).over(w1)
df_avg = df.withColumn("temp_avg",avg_val)
display(df_avg)
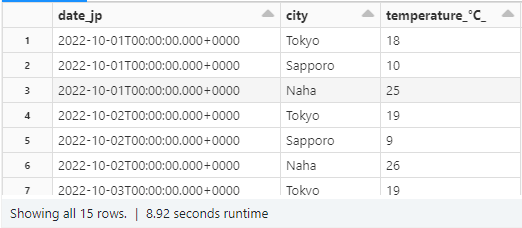
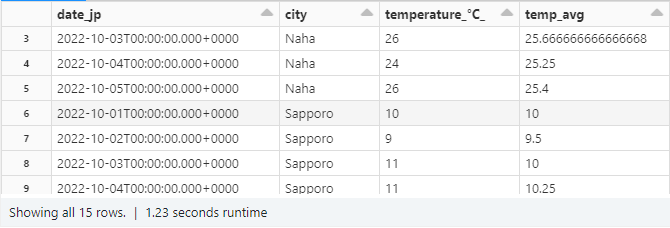
ちなみにですが rowsBetween(-sys.mazsize,0) のように指定すればデータの始めから現在行(0が現在点となる)までの平均を求めることも可能です。
この場合だと先ほどの平均算出とは異なり、同じ partition 内であっても平均を計算する範囲が毎行変化するので、1行ごとにそれぞれ異なる計算結果が出力されることがわかりますね。 group by にはないような操作になります。
# 平均2
w2 = Window.partitionBy(col("city")).orderBy("date_jp").rowsBetween(-sys.maxsize,0)
avg_val2 = avg(col("temperature_°C_")).over(w2)
df_avg2 = df.withColumn("temp_avg",avg_val2)
display(df_avg2)
まとめ
今回 window 関数とは何かを解説し、window 関数を利用して簡単なデータを例に平均を算出しました。
集計方法は平均だけではありません。
最大値や合計などの親しみのある関数はもちろん、lag や rowNumber といった window 特有の関数も使用することができます。
window 特有の関数に関する情報は SQL の方が圧倒的に多いので、まずはそちらから情報収集される方が効率的かと思います。
文法的な部分は PySpark と SQL で異なりますが、機能的な部分は一緒のはずです。
文法的な面は本記事でご紹介した平均を算出する方法と基本的な形は変わらないので、別の関数の応用にも参考にしていただければと思います。