こんにちは。
本記事は Pythonその2 Advent Calendar 2019 3日目の記事です。
先日、【福岡開催】AWS Solution Seminarというものに参加しました。
とてもためになったのですが、その中で、このお題のworkshopに参加して、「手順多くて覚えらんねえ。。。」そんな感想になりました。
社内のパイセンから、「それPython sdkでいけるよ!」と言われたので、
スクリプト流してドーンと終わったら楽だなと思って、ここに書き記しておきます。
Python sdk(boto3)の導入
それでは早速行きましょう。
流れとしては以下です。
- IAMユーザーの作成
- awscliをインストール(しなくてもいいけど簡単なので)
- boto3のインストール
の3つくらいです。
IAMユーザーの作成
ぶっちゃけルートユーザーでもアクセスキーとかシークレットキーでプログラムを作成することが可能です。
しかし、ルートユーザーにはいろんなアクセス権が認められているため、IAMユーザーでアクセス権を制御しておきましょう。
IAMは
AWSマネジメントコンソール > IAM > ユーザー > ユーザーを追加
からまあ、名前とかは適当に

プログラムのみで使うのであれば、AWSマネジメントコンソールにアクセスできる必要はないです。
今回はコンソールで試し使いするため、チェックを入れておきましょう。
次にアクセス許可の設定ですが、アクセスグループを設定して追加してもらっても構わないですし、実験程度に使うなら「既存のポリシーを直接アタッチ>AdmiinistratorAccess」で問題ないです。
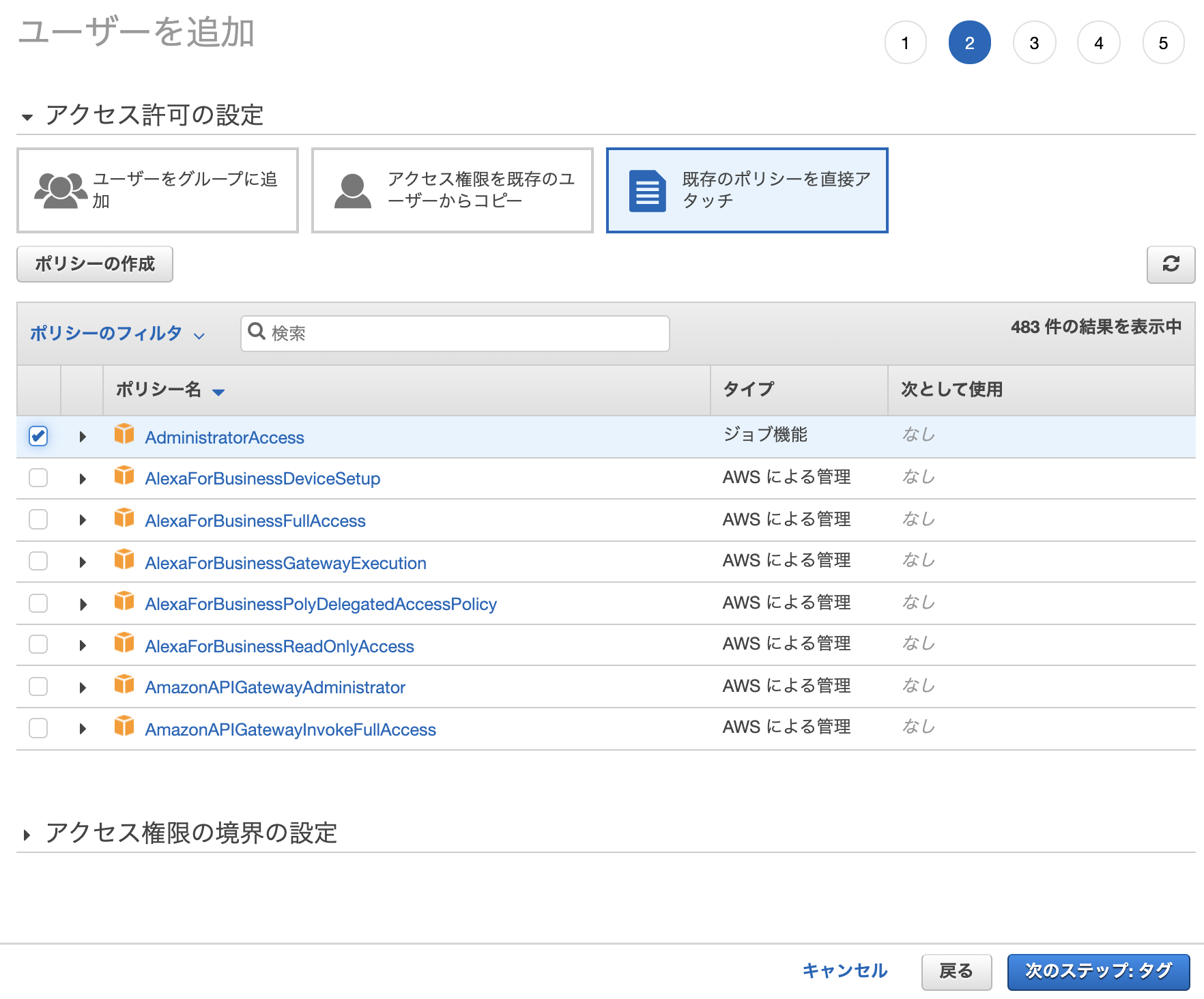
これは各プロジェクトに従ってください。
あとは次々進んでIAMユーザーを作成してください。
作成成功画面でシークレットアクセスキーとパスワードは手元にメモっておきましょう。
これがboto3を操作するのに必要です。
awscliのインストール
Macだったらbrew install awscliで
Windowsだったらscoop install awsで(たぶんchocolateyでも)おそらく入ると思います。
ちなみに自分はvagrantを使っているため、pip install awscliで導入しました。
インストールできたら設定を追加しましょう。
ちなみにですが、自分はリッチなコマンド補完をインタラクティブに行えるaws-shellというものを使っています。
さて、アクセスキー等の設定をしていきましょう。
$ aws configure
AWS Access Key ID [None]: ************************
AWS Secret Access Key [None]: ************************
Default region name [None]: us-east-1
Default output format [None]: json
まあ、適当に上みたいなこと聞かれるんで自分のものを設定しましょう。
boto3のインストール
boto3はpython sdkのため、pip install boto3で導入することが可能です。
これだけです。
困ったことがあったらboto3 Documentを参照しましょう。
boto3を使う
boto3のquickstartをみましょう。
実は、その中のUsing boto3までに書いてあることが、これまでにやってきたことです!
Using boto3に書いてあることをやっていくこととします。
$ python
import boto3
session = boto3.session.Session(profile_name='python-advent-calendar-demo')
s3 = session.resource('s3')
for b in s3.buckets.all():
print(b.name)
pythonコマンドで、インタラクティブに実行できる環境を準備し、boto3をインポートします。
で、ドキュメント通りにやっても、動かない場合が、profile名を指定した時です。
デフォルトではdefaltのprofileが指定されるため、一旦profile_nameを指定して、セッションを作っておきます。
今は、s3バケットを何も追加していないため、何も表示されません。
何か追加してみましょう。
せっかくなんでね。ここをみながら、何か追加しましょう。
s3.create_bucket(ACL='private', Bucket='python-advent-calendar-demo')
for b in s3.buckets.all():
print(b.name)
python-advent-calendar-demo
この一行でパッとできちゃいます。ブラウザでも確認しておきましょう。

ちゃんとできていますね!
適当にファイルもアップロードしておきましょう。
s3.meta.client.upload_file('test.txt', 'python-advent-calendar-demo', 'text.txt')

ちゃんとできていますね!!!
Amazon Personalizeの利用
Amazon Personalize
このサービスは、アプリケーションを使用している顧客に対して開発者が個別のレコメンデーションを簡単に作成できるようにする機械学習サービスです。
と、コピペ通りです。そんなサービスです。
何はともあれAWSマネジメントコンソール
Amazon Personalizeの実行権限を持ったIAMユーザーを作ったらAmazon Personalizeの画面へいきましょう。
さっそくAmazon Personalizeを使ってみます!
基本的にはAmazon Personalize コンソールを使用して、映画のレコメンデーションを特定のユーザーに返すキャンペーンを作成に従って、進めていきます。
学習させるまでの手順は多いですが、案内に従ってやれば大したことないです。
- Dateset group detail

- Detaset details
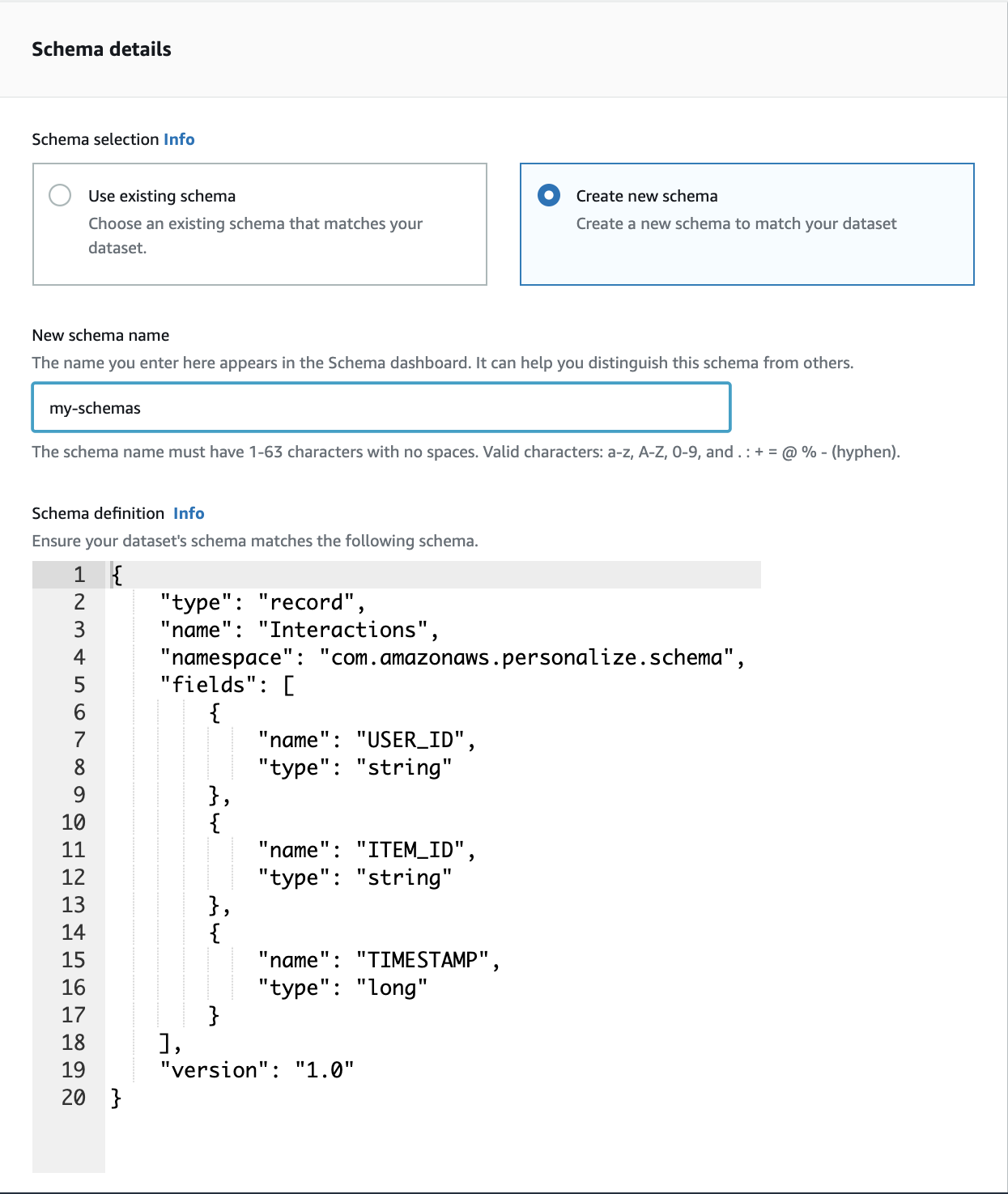
- Schema details
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}
- Dataset import job details
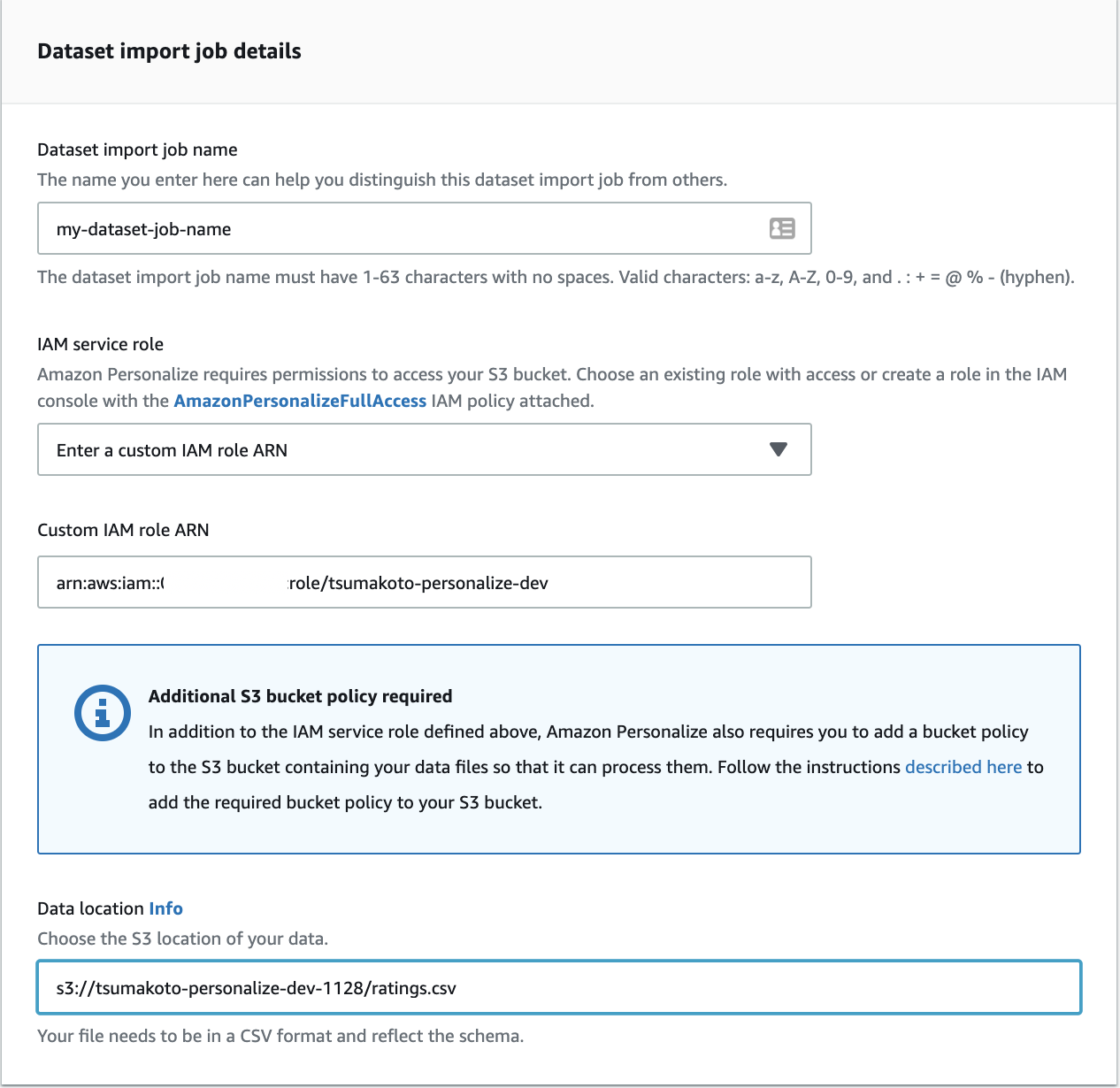
上の1〜4までの手順を実行していけば、データのロードが完了します。
データについてはhttp://files.grouplens.org/datasets/movielens/ml-latest-small.zip のリンクからダウンロードできます。
この中の、rating.csvを使ってください。
データの前処理についてはAmazon Personalize – Real-Time Personalization and Recommendation for Everyoneを参照ください。
※もしかしたら、データロードの段階で、permission errorで怒られるかもしれません。
その場合は、ここに従って、バケットポリシーを設定してください。
自分の場合は以下のようになりました。
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::tsumakoto-personalize-dev-1128",
"arn:aws:s3:::tsumakoto-personalize-dev-1128/ratings.csv"
]
}
]
}
ここまでくれば、あとは学習させるだけです。
上のようにActiveになったのが確認できたら、create solutionから以下のように設定して、学習を実行させましょう!!
5.Solution configuraion
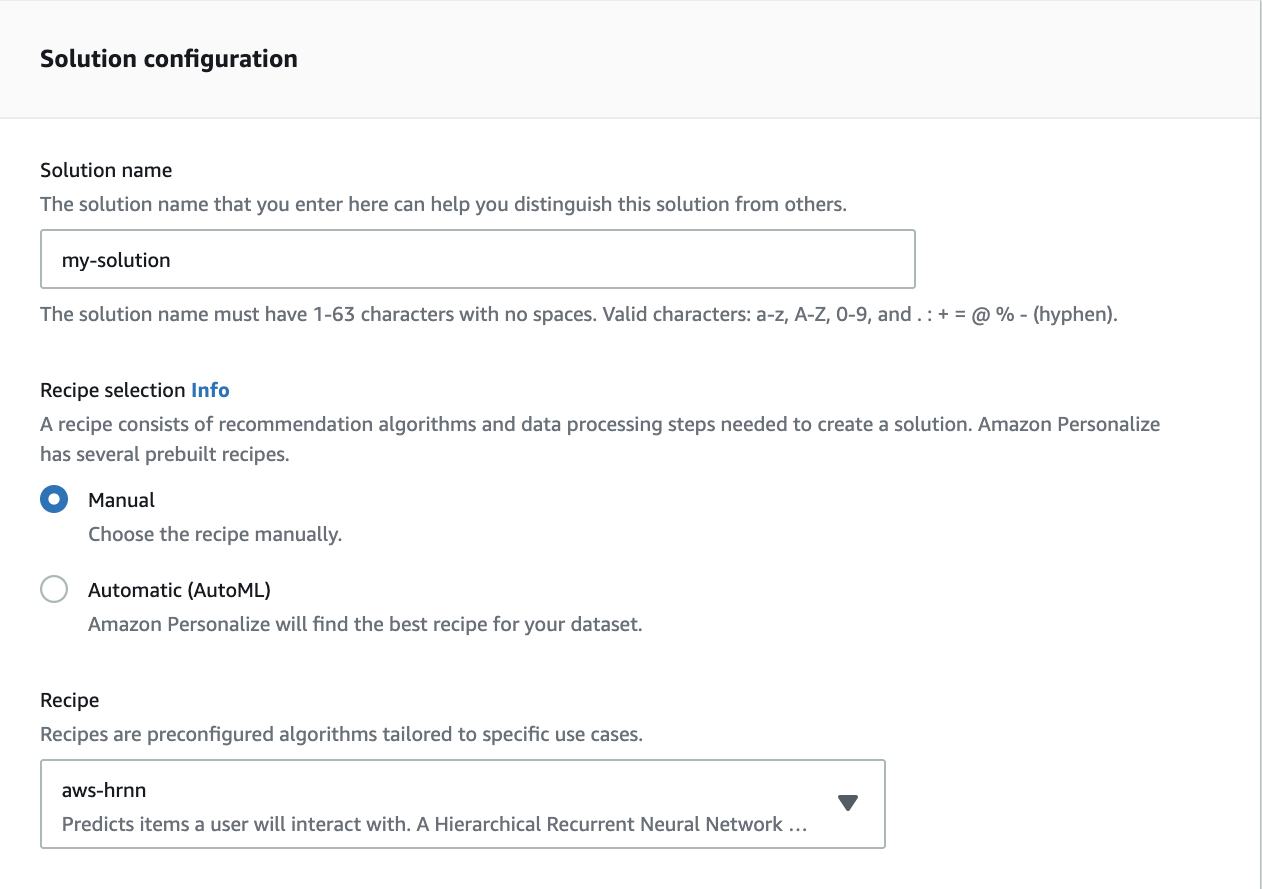
設定したら、Next > finishで学習が開始されます。
だいたい40分くらいかかるので、待つしかないですね笑
この間にcliの方にいって、実行してみるといいかも!
- Create Campaign

学習が終了すると、モデルのデプロイができるようになります。
Create new CampaignからCampaignを作成していきます。
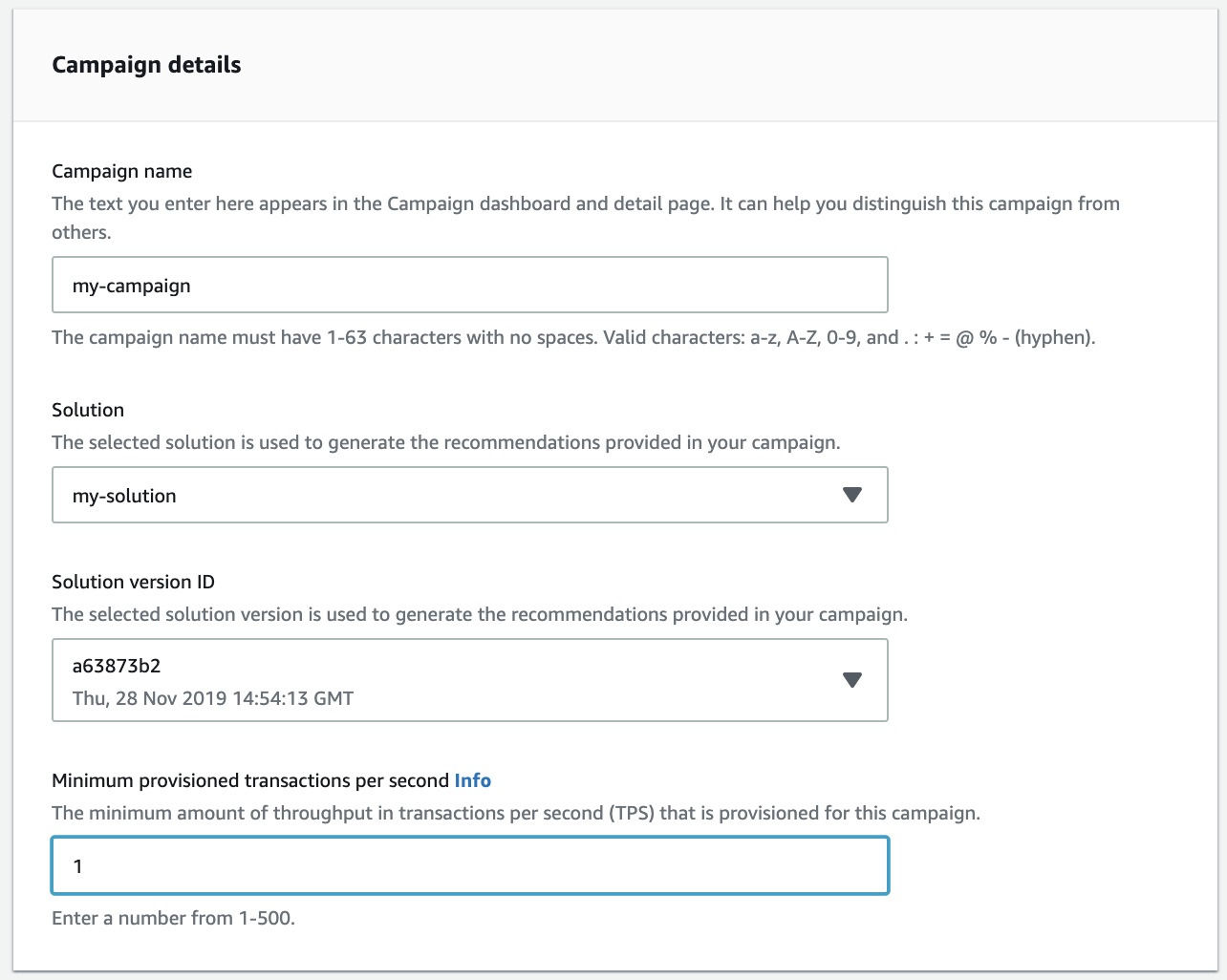
さっき作ったソリューションを使って、適当にこんな感じで、作成していきます。

あとは、適当にUserIDを指定することでこのユーザーにあったRecomendを抽出してくれます。
機械学習なんでわかってなくともここまでのことができます。
素晴らしいですね。
boto3での利用
これまで操作してきたことをそのままコードにするだけです。
学習の部分
import boto3
import os
from os.path import dirname, join
def main():
session = boto3.session.Session(
profile_name=os.environ.get('PROFILE_NAME'))
print('created session')
BucketCreater(session).exec(_load_bucket_policy())
print('created bucket: {}'.format(os.environ.get('BUCKET_NAME')))
ExportDataSource(session).upload(
join(dirname(__file__), 'ratings.csv'),
'ratings.csv')
print('uploaded csv')
datalocation = 's3://{}/ratings.csv'.format(os.environ.get('BUCKET_NAME'))
job_arn = DatasetLoader(session).import_job(
_load_schema_definition(),
{'dataLocation': datalocation}
)
print('dataset import job')
solution_version_arn = SolutionCreater(session, job_arn).exec()
print('solution created')
campaign_arn = CampaignCreater(session, solution_version_arn).exec()
print('success!')
print('campaign arn is {}'.format(campaign_arn))
上で書いている手順を、順に実行していけばモデルのデプロイまでできます。
ここのメインとなるであろうデータセットのロードの部分は
# DatasetLoader.import_jobの一部
dataset_group = self.personalize.create_dataset_group(
name=self.dataset_name)
dg_arn = dataset_group['datasetGroupArn']
description = self.personalize.describe_dataset_group(
datasetGroupArn=dg_arn)['datasetGroup']
# 60sec待つ
print("creating dataset group")
for i in range(60):
if description['status'] == 'ACTIVE':
break
else:
time.sleep(1)
description = self.personalize.describe_dataset_group(
datasetGroupArn=dg_arn)['datasetGroup']
if description['status'] != 'ACTIVE':
print('dataset group not create')
sys.exit(-1)
schema = self.personalize.create_schema(
name=self.schema_name,
schema=schema_definition)
dataset = self.personalize.create_dataset(
name=self.dataset_name,
schemaArn=schema['schemaArn'],
datasetGroupArn=dataset_group['datasetGroupArn'],
datasetType='Interactions')
dataset_import_job = self.personalize.create_dataset_import_job(
jobName=self.job_name,
datasetArn=dataset['datasetArn'],
dataSource=data_source,
roleArn=self.role_arn)
dij_arn = dataset_import_job['datasetImportJobArn']
description = self.personalize.describe_dataset_import_job(
datasetImportJobArn=dij_arn
)['datasetImportJob']
# 100mまで待つ
print("importing job")
for i in range(60):
if description['status'] == 'ACTIVE':
break
else:
time.sleep(100)
description = self.personalize.describe_dataset_import_job(
datasetImportJobArn=dij_arn
)['datasetImportJob']
if description['status'] != 'ACTIVE':
print('job do not success')
sys.exit(-1)
ACTIVEになるまで待たなければならないのですが、実直にfor文で60secまでや100minutesまで待つようにする形で書いてます。
うーん、何かいいやり方ないですかね。。
とりあえずこれで。
推論の部分
推論の部分では、上でやったような結果がちゃんと表示されるようにします。
session = boto3.session.Session(
profile_name=os.environ.get('PROFILE_NAME'))
item_list = RecommendGetter(session, argv[1]).get(argv[2])
print("🔻Recommended item ID")
for item in item_list:
print(item['itemId'])
print('-------------')
推論の時は、クライアントとしてsession.client('personalize-runtime')を使います。
これに対して、get_recommendationsを使えばレコメンドが取れることになります。
🔻Recommended item ID
1682
-------------
552
-------------
104
-------------
1265
-------------
527
-------------
1676
-------------
780
-------------
367
-------------
2395
-------------
上のような結果が出ればOKです!
終わりに
今回、IAMユーザーの作成とROLEは手でやりましたが、これもBoto3を使ってできると思います。
上で省略した部分は私のリポジトリにあるので、よければみてください。
https://github.com/TsuMakoto/aws_personalize_demo
おわり。