はじめに
本記事ではPolarsデータフレームを使う文脈ではcsvやjsonよりもParquetが最強だ(過激派)という主張をさせていただきます。
polarsを標榜していますが、pandasや他のデータ処理ライブラリでも使える話かとおもいます。
私の失敗談
Polarsの型推論が失敗してデータが消えうせた
とあるタスクのために、クラウド上のデータをpolarsに読み込んで処理する必要がありました。
図のように、Amazon Athenaでデータをクエリして、その結果をS3にUnloadし、最後にPolarsでデータを読み込む簡単な処理です。
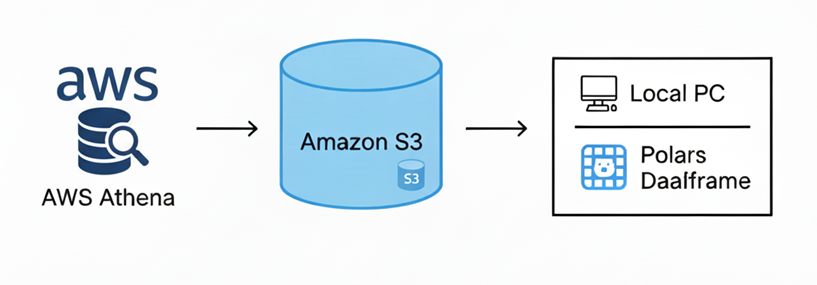
毎月このようなプログラムを回して、データを取得・データフローに格納、結果を確認、、、のようなことをしていたのですが、ある月に突然データが0件になってしまいました!
polarsはエラーを吐かず、さも正常のように動作していたので、気づくのが遅れ大変な目にあいました(思い出したくない)。
なぜこんなことに?
結果からいうと、polarsの型推論が問題でした。
polarsではデータを読み込む際、特に何も指定しなければ自動で型推論が行われます。
例えばCSVデータをpolarsで読み込む際には、最初の100行をチェックして型を推定します。なので、運悪く最初の100行だけを見ても型が決まらない(すべてNullなど)ような場合や、101行目以降に文字列が含まれる場合など、誤った型付けがなされてしまう可能性があります。
私が当たったのはこの問題で、数か月問題なく動いてきたプログラムがいきなり動かなくなったわけです。
(polarsの仕様で0件になったのではなく、型が数値⇒文字列になってしまったため、その後のデータ処理で全行全て無視されていました)
どう対応するか?
一番確実で安定な方法があり、それはSchemaを指定することです。
以下のようにschemaを完全に指定すれば、それに反するカラムは完全に無視されます。
import polars as pl
# 全列の型を辞書で定義
my_schema = {
"timestamp": pl.Datetime,
"user_id": pl.String,
"event_type": pl.String,
"value": pl.Int64
}
# 全列定義して読み込む
# ※CSVに定義外の列があるとエラーになるか無視される設定も可能
df = pl.read_csv(
"s3://my-bucket/events.csv",
schema=my_schema,
has_header=True
)
print(df.head())
ただ、柔軟さが売りのPythonで毎回カラムを指定し続けるのは個人的には好きではありません。
もっと気軽にデータを呼び出しつつ、かつ型情報のミスマッチもなくなるような方法はないかと考えたところで、polars + Parquet に行きついたのでした。
最強のファイル形式Parquet
Parquetとは
ビッグデータを扱うのに最適なデータ形式です。
Parquetを扱う上で特に重要なのは以下の2点です。
- 「列」ごとにデータを保存する(列指向)
- CSVが1行ずつデータを並べるのに対し、Parquetは「列(カラム)」ごとにデータをまとめて保存する。そのため、ビッグデータで重要な集計処理と相性が良い
- 「型情報」をファイル自体が持っている
- CSVはただのテキストですが、Parquetは「この列は数値」「この列は日付」という情報をデータと一緒に保存している
その他にも、
- データが強力に圧縮される
- 同じ列には同じ種類のデータ(数値なら数値、文字列なら文字列)が並ぶため、効率よく圧縮できる
- 「メタデータ」を内蔵している
- ファイルの中に「この列の最大値・最小値はいくつか」といった統計情報(メタデータ)を持っている
といったメリットもあります。
- ファイルの中に「この列の最大値・最小値はいくつか」といった統計情報(メタデータ)を持っている
逆にデメリットとしては、ファイルがバイナリ形式なので、デバッグ用にファイルをダウンロードしても人間は直接読めない形式である点が挙げられます。
一応Parquet Viewerはアプリで存在しますが、専用アプリを使わないと生データを確認できないのは不便な点かなと感じます。
polars + Parquetが最強のワケ
前項で記述しましたが、Parquetは「内部に型情報を保持している」のです。
つまりそれは、Athenaなどデータ生成側が意図した型情報を、そのままPythonで受け取れるというわけです!
さらにpolarsにはread_parquetという関数があり、これを使うとParquetが持つ型情報をそのままpolarsデータフレームに格納できるのです!
import polars as pl
# 全列定義して読み込む
df = pl.read_parquet("s3://my-bucket/event.parquet")
print(df.head())
これだけなのです!
今まで型情報を確定させるのに、不確定な要素があったり、スキーマによる型指定が面倒だったりしたのですが、1行書けばフルオートで型情報を確約してくれるので、とても便利ではないでしょうか?
(pandasでも同じ関数が使えます)
Parquetは人間が読めないという欠点がありましたが、Polarsで読み込む前提ならそのデメリットも気にしなくて良いでしょう。
実装例
最後に、実際に私が使っている、Athenaからのクエリ結果をそのままpolarsに読み込む関数を紹介します。
Parquetへの変換を内在しているので、気軽にAthenaからのクエリ結果をpolarsに型情報付きで読み込めます。
import time
import random
from math import floor
import boto3
import polars as pl
DEFAULT_OUTPUT_LOCATION = "s3://your-athena-result-bucket"
class AthenaQueryService:
def __init__(
self, database: str, output_location: str, region_name: str = "ap-northeast-1"
):
self.athena_client = boto3.client("athena", region_name=region_name)
self.s3_client = boto3.client("s3", region_name=region_name)
self.database = database
self.output_location = output_location
def _execute_query(self, query: str) -> str:
"""Athenaでクエリを実行し、クエリIDを返す"""
response = self.athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={"Database": self.database},
ResultConfiguration={"OutputLocation": self.output_location},
)
return response["QueryExecutionId"]
def _get_query_status(self, query_execution_id: str) -> str:
"""クエリの実行状態を取得"""
response = self.athena_client.get_query_execution(QueryExecutionId=query_execution_id)
return response["QueryExecution"]["Status"]["State"]
def _list_objects(self, bucket: str, prefix: str) -> list[str]:
"""S3 に指定した prefix のオブジェクトをリストで取得"""
continuation_token= None
files = []
while True:
list_kwargs = {
'Bucket': bucket,
'Prefix': prefix,
'MaxKeys': 500
}
# 続きがあれば続きから取得
if continuation_token:
list_kwargs['ContinuationToken'] = continuation_token
response = self.s3_client.list_objects_v2(**list_kwargs)
for content in response.get('Contents', []):
files.append(content["Key"])
if 'NextContinuationToken' in response:
continuation_token = response['NextContinuationToken']
else:
break
return files
def _wait_for_query(self, query_execution_id: str, wait_time: int = 2) -> str:
"""クエリが完了するまで待機"""
while True:
status = self._get_query_status(query_execution_id)
if status in ["SUCCEEDED", "FAILED", "CANCELLED"]:
return status
time.sleep(wait_time)
def run_query_and_extract_as_df_through_parquet(self, query: str) -> pl.DataFrame:
random_suffix = str(floor(time.time()*1000)) + "_" + str(random.randint(1000, 9999)).zfill(4)
unload_s3_path = f"{self.output_location}/temp/{random_suffix}/"
"""クエリを実行し、完了後に結果をParquet経由でDataFrameで取得"""
query_with_unload = f"""
UNLOAD (
{query}
)
TO '{unload_s3_path}'
WITH (format = 'PARQUET', compression = 'SNAPPY')
"""
query_execution_id = self._execute_query(query_with_unload)
status = self._wait_for_query(query_execution_id)
if status == "SUCCEEDED":
self.athena_client.get_query_execution(QueryExecutionId=query_execution_id)
# ファイルが無い(初回の場合)
file_list = self._list_objects(
bucket=unload_s3_path.replace("s3://", "").split("/")[0],
prefix="/".join(unload_s3_path.replace("s3://", "").split("/")[1:])
)
if len(file_list) == 0:
print("【WARNING】No data found in the query result!!")
return pl.DataFrame()
df = pl.read_parquet(
f"{unload_s3_path}*"
)
return df
else:
raise Exception(f"Query failed with status: {status}")
まとめ
今回は polars + Parquet が最強であるとの主張をさせていただきました(もっといい方法は世の中に転がっているかもしれませんが!)。
特に伝えたいことを、最後にもう一度まとめます。
- polarsを使用する際に、型推論を使うと意図せぬエラーになるかもしれない
- Parquet形式を使うことで、型情報を内部に埋め込み、polars側で型指定をしなくても間違いない型を付与できる
- S3からParquetを読み込むのは、1行でできる
メリットが多すぎるので、是非 polars + Parquetを使ってみてください!