
こんにちは、トイロジック3年目プログラマーのS.Hです。本記事では、プライベートで行った深層学習を用いたオセロAIの実装とAIをより強くするための調整方法について振り返りとともに解説をしたいと思います。
筆者も深層学習を用いた実装は今回が初めてで難しい実装は行っていませんので、深層学習について詳しくない方でも気軽に読んでいただければと思います。
開発環境
開発環境は以下の通りになります。- Unreal Engine 4.21.2 (UE)
- Python 3.6.2
- UnrealEnginePython
- Unreal Engineのランタイム上でPythonの実行を可能にするプラグイン
- TensorFlow 2.6.0
- 機械学習ライブラリ
- CUDA 11.2
- GPUで並列実行するためのプラットフォーム
- CUDA Deep Neural Network 8.1 (cuDNN)
- 深層学習を高速化するためのGPGPUライブラリ
- Tensor Board
- 機械学習のデータを可視化するツール
今回はライブラリやフレームワークが充実しているという観点から深層学習の処理はPythonで実行することにしました。また、これらのソフトウェアはバージョン間の互換性問題があるため注意が必要です。
深層学習とは
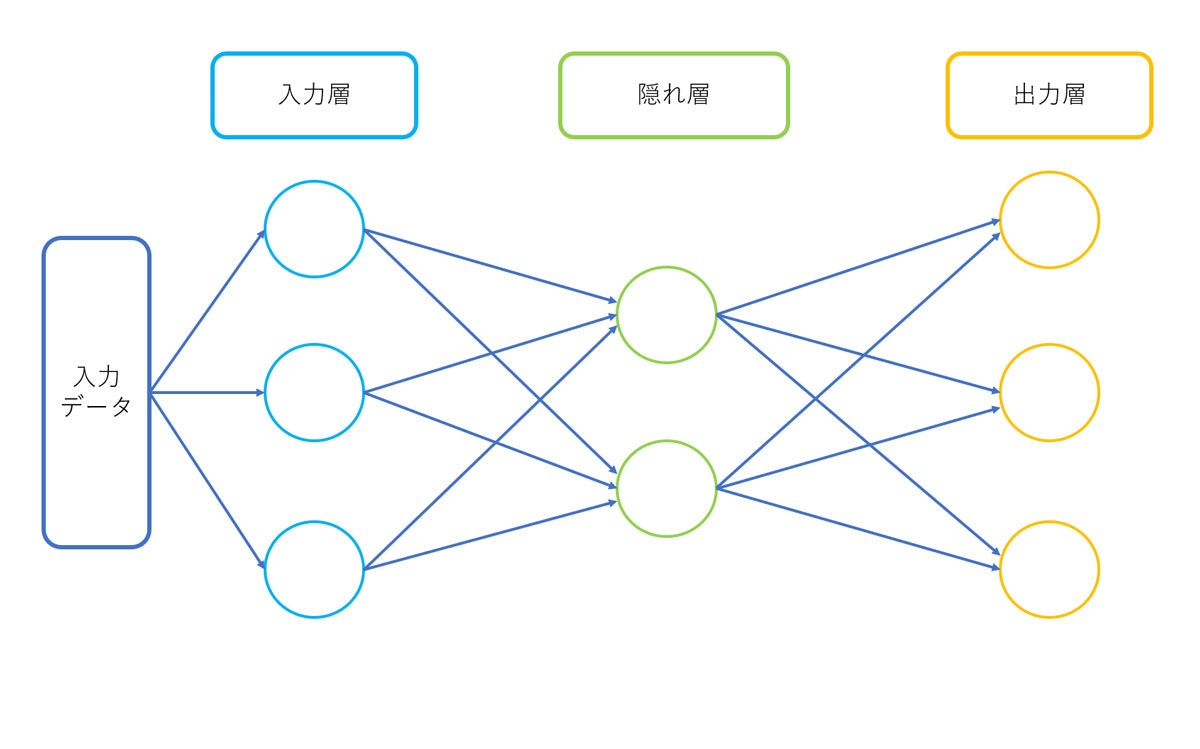
深層学習とは機械学習の手法の一つで、人間の神経細胞のニューロンの仕組みを再現したニューラルネットワークを用いて学習を行います。ニューラルネットワークは下の図のように複数の層によって構成されており、入力されたデータを処理して次の層へと受け渡していきます。これを各層で行うことでデータの特徴やパターンを学習し最適な値を求めることができます。
深層学習AIを作成する流れは以下のようになります。
- AIに学習させるデータを用意・作成する。
- AIのモデルを作成する。
- AIに学習データを学習させる。
- それでは実際にAIの作成をしていこうと思います。
学習データの作成
まずはAIに学習させるためのデータを用意します。今回AIにやってほしいことはオセロゲームで現在の盤面において勝利するためにどのマスに置くのが強いかを求めることです。そのため学習データはオセロの盤面の情報とその盤面で置くべきマスの位置とします。
学習データ用の盤面と置く位置はオセロ連盟が公開している棋譜データベースWTHORに保存されているデータを使わせていただきました。WTHORのデータはバイナリ形式で保存されているため読み取りやすい形式に変換する必要があります。WTHORのデータをCSVに変換するプログラムを公開してくれている方がいたのでそちらを使わせていただきました。
オセロの棋譜データベースWTHORの読み込み方
CSVに変換すると1試合分の記録が以下のようなアルファベットと数字で表現されています。
f5d6c3d3c4f4f6f3e6e7d7b3e3d2g3h3d1c5f2e2e1f7f8g5h6h5g6g4c2c1e8c8d8g8b6f1b4a4h4b5g2h7c6a7a5a6a3a2b7h2h1g1h8g7b2b1a1a8b8c7
この文字列は石を置いた位置を羅列したものであり2文字で1手を表しています。アルファベットが列、数字が行に対応しています。例えば先頭のf5だと左から6列目の上から5行目をさしています。
まずはCSVデータから試合内容を読み込む処理を作成していきます。
# CSVから試合内容を読み込む
def load_match_info(self):
# csv読み込み
csv_data = pd.read_csv("wthor.csv")
# 1行目はヘッダになっているため削除する
# 試合内容はtranscriptの列
csv_data = csv_data.drop(index= csv_data[csv_data["transcript"].str.contains("transcript")].index)
# 正規表現を使って2文字ずつ切り出す
extract_one_hand = csv_data["transcript"].str.extractall('(..)')
# Indexを再構成して、1行1手の表にする
# 試合の切り替わり判定のためtournamentIdも残しておく
one_hand_df = extract_one_hand.reset_index().rename(columns={"level_0":"tournamentId" , "match":"move_no", 0:"move_str"})
# アルファベットを数字に変換するテーブル
conv_table = {"a" : 1, "b" : 2, "c" : 3, "d" : 4, "e" : 5, "f" : 6, "g" : 7, "h" : 8}
one_hand_df["move"] = one_hand_df.apply(lambda x: self.convert_move(x["move_str"], conv_table), axis=1)
return transcripts_df
1手を数値に変換する
def convert_move(self, v, conv_table):
l = conv_table[v[:1]] # 列の値を変換する
r = int(v[1:]) # 行の値を変換する
return np.array([l - 1, r - 1], dtype='int8')
これで試合内容を読み込むことができましたが、データには石を置いたマスの情報しか含まれていません。そのため現在の盤面情報ついては実際にオセロの試合を進めていき自前で作成する必要があります。パスがあることも忘れずに実装する必要があるので注意してください。
また、盤面情報をそのまま配列に変換するのではなく白色の石の配置情報と黒色の配置情報を別々の配列に分けて2つあわせて現在の盤面情報とします。そうすることで1つの盤面情報で白色と黒色が反転した時の配置にも対応できます。
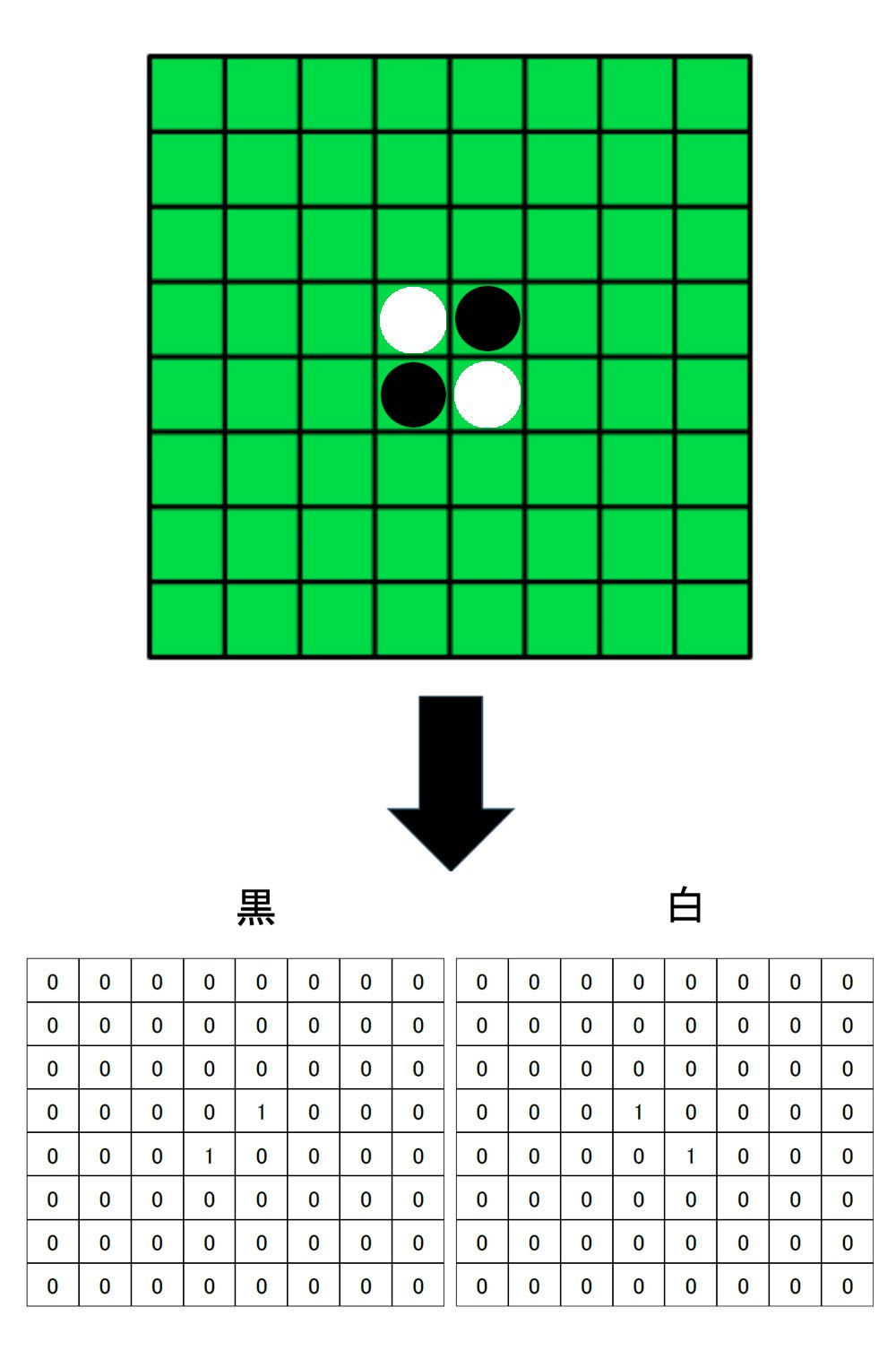
CSVから読み込んだデータから盤面情報を求める処理は以下のようになります。(オセロの盤面の処理がしやすいように外側に1マス追加して全部で100マスにしています)
def process_tournament(self, df):
# 試合が切り替わる盤面リセット
if df["tournamentId"] != self.now_tournament_id:
self.table_info = [0] * 100
self.table_info[44] = 2
self.table_info[45] = 1
self.table_info[54] = 1
self.table_info[55] = 2
self.turn_color = 1
self.now_tournament_id = df["tournamentId"]
else:
self.turn_color = 1 if self.turn_color == 2 else 2
# 置ける箇所がなければパスする
if len(reversi.GetCanPutPos(self.turn_color, self.table_info)) == 0:
self.turn_color = 1 if self.turn_color == 2 else 2
// 配置場所
put_pos = df["move"]
# 訓練用データ追加
self.record_training_data(put_pos)
# 盤面更新
put_index = put_pos[0] + 1 + (put_pos[1] + 1) * 10
reversi.PutStone(put_index, self.turn_color, self.table_info)
def record_training_data(self, put_pos):
# ボード情報を自分と敵のものに分ける
my_board_info = np.zeros(shape=(8,8), dtype="int8")
enemy_board_info = np.zeros(shape=(8,8), dtype="int8")
for i in range(len(self.table_info)):
# 盤面処理のための余分なマスは無視する
if i >= 0 and i <= 9:
continue
if i / 10 == 0:
continue
if i / 9 == 0:
continue
if i >= 90 and i <= 99:
continue
if self.table_info[i] == 1:
my_board_info[int(i/10) - 1][int(i%10) - 1] = 1
elif self.table_info[i] == 2:
enemy_board_info[int(i/10) - 1][int(i%10) - 1] = 1
move_one_hot = np.zeros(shape=(8,8), dtype='int8')
move_one_hot[put_pos[1]][put_pos[0]] = 1
if self.turn_color == 1:
self.my_board_infos.append(np.array([my_board_info.copy(), enemy_board_info.copy()], dtype="int8"))
self.my_put_pos.append(move_one_hot)
else:
self.enemy_board_infos.append(np.array([enemy_board_info.copy(), my_board_info.copy()], dtype="int8"))
self.enemy_put_pos.append(move_one_hot)
モデルの作成
次にオセロAIのモデルを作成していきます。モデルとは機械学習の入力から出力までの構造のことを指しており、今回はTensorFlowライブラリに用意されているSequentialというモデルを使用します。Sequentialは各層に1つの入力と1つの出力のみをもつ単純な構造になっています。
モデルを作成したら各層で実行する活性化関数を指定していきます。活性化関数とは入力された数値を特定の方法で変換し、その結果を出力する関数のことです。活性化関数はいくつかの種類があり組み合わせや並び順も学習結果に影響します。今回のオセロAIのモデルにはReLU関数を12層と出力層にSoftmax関数を採用しました。
モデル作成のコードは以下になります。
def create_model(self):
class Bias(keras.layers.Layer):
def __init__(self, input_shape):
super(Bias, self).__init__()
self.W = tf.Variable(initial_value=tf.zeros(input_shape[1:]), trainable=True)
def call(self, inputs):
return inputs + self.W
model = keras.Sequential()
model.add(layers.Permute((2,3,1), input_shape=(2,8,8)))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'))
model.add(layers.Conv2D(1, kernel_size=1,use_bias=False))
model.add(layers.Flatten())
model.add(Bias((1, 64)))
model.add(layers.Activation('softmax'))
model.compile(keras.optimizers.SGD(learning_rate=0.01, momentum=0.0, nesterov=False), 'categorical_crossentropy', metrics=['accuracy'])
return model
モデルの学習
これで学習データのモデルの準備ができたので、モデルの学習を行えます。コードは以下のようになります。
def training(self):
x_train = np.concatenate([self.my_board_infos, self.enemy_board_infos])
y_train_tmp = np.concatenate([self.my_put_pos, self.enemy_put_pos])
# 教師データをサイズ64の1次元配列に変換
y_train = y_train_tmp.reshape(-1, 64)
try:
# 学習を開始
model.fit(x_train, y_train, epochs=1000, batch_size=32, validation_split=0.2)
except KeyboardInterrupt:
# 学習中に途中で中断された場合に途中結果を出力
model.save('saved_model_reversi/my_model_interrupt')
print('Output saved')
return
# 学習が終了したら指定パスに結果を出力
model.save('saved_model_reversi/my_model')
print('complete')
x_trainに現在の盤面情報、y_trainに現在の盤面で置くべきマスの位置を入れてmodelに渡しています。
model.fit()の引数の意味は以下になります。
- epochs=エポック数(学習データを何週繰り返し学習させるかを表す)
- batch_size=学習データをグループに分けて処理するときのグループ数
- validation_split=学習最後にモデルをテストする際に使うテスト用データとして採用される割合
model.save()で学習データを外部に出力することができます。コードにあるように例外が発生したときに途中結果を保存することもできます。
AIテスト
これでオセロAIの準備は出来たので実際に試合をさせてみます。筆者が対戦相手になってもよかったのですが、残念ながらオセロはあまり自信がないため代わりにルールベースで動くAIを作成して対戦相手にしました。
今回はモンテカルロ法という手法を使ったオセロAIをテスト用に作成しました。モンテカルロ法とは乱数を使ってシミュレーションを行い最適な解を求めるという手法です。モンテカルロ法を使ったオセロAIの実装について詳しくはこちらを参照ください。手始めにモンテカルロ法の試行回数10回のAIと深層学習AIで対戦させてみました。対戦結果はテキストファイルで出力し、見やすいようにスプレッドシートで読み込んでいます。
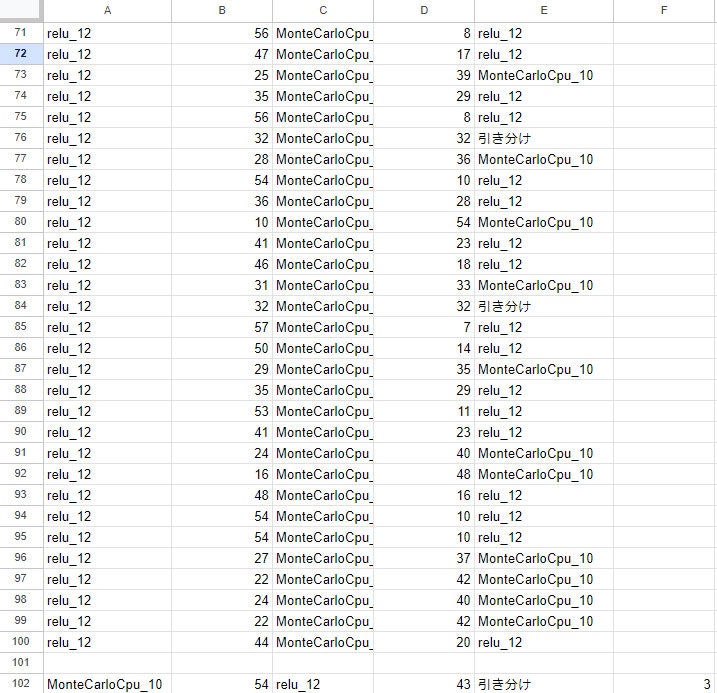
何ということでしょう。
深層学習AIが43勝54敗3引き分けと負け越してしまいました。
コードにミスがあるのではないかと見直してみますが特に問題は見つかりません。では何が問題になっているのでしょうか。そんなときに参考になるのがaccuracy(学習率)とloss(損失)の値です。accuracyはAIが正しく予測できた割合を表し、lossは正解と予測とのずれの大きさを表しています。accuracyとlossの値はモデルの学習中にコマンドプロンプト上に表示されます。
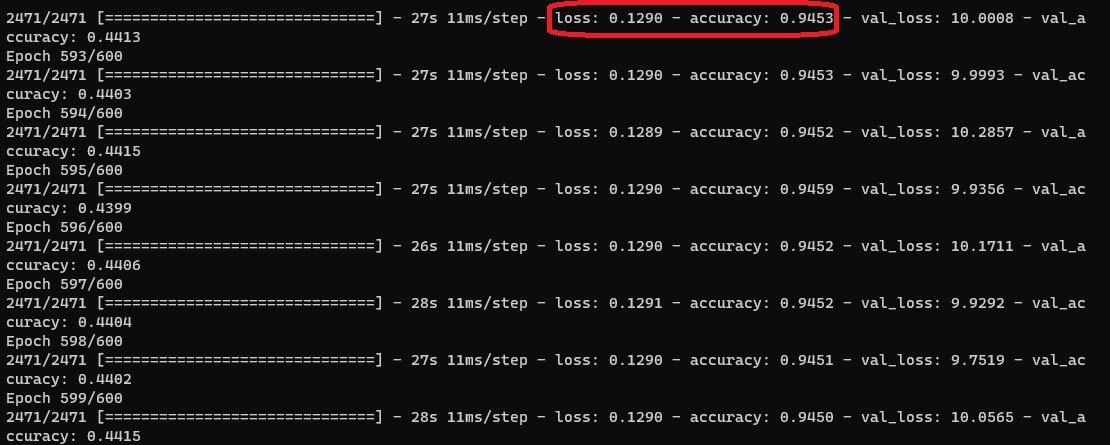
ただコマンドプロンプト上の数字では、学習中にどんな感じで遷移していったか読み取りづらいです。そこで使うのがTensor Boardです。
Tensor Boardの利用
Tensor Boardとは開発環境紹介でも説明しましたが、機械学習のデータを可視化するツールになります。機械学習のデータとは具体的に言うとaccuracyやlossの値のことになります。Tensor Boardを利用するためにはmodel.fit()関数にコールバックを設定する必要があります。
# Tensor Boardコールバック
tb_cb = keras.callbacks.TensorBoard(log_dir='model_log/relu_12', histogram_freq=1, write_graph=True)
# 引数callbackにtb_cbを設定
model.fit(x_train, y_train, epochs=1000, batch_size=32, validation_split=0.2, callback=[tb_cb])
tensorboard --logdir logpath
http://localhost:6006/にアクセスするとグラフが確認できます。今回の学習のデータは以下のようになっていました。
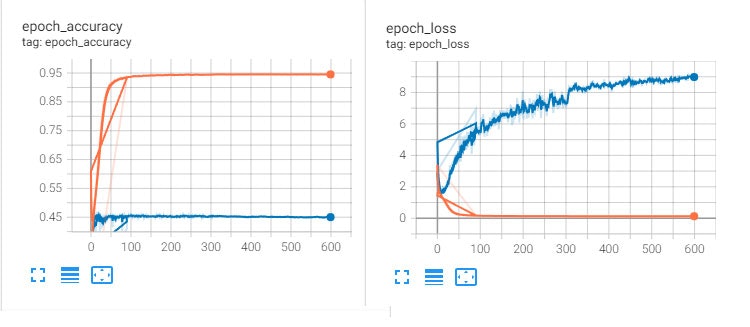
それぞれのグラフでオレンジ色の線と青色の線があると思います。オレンジの線は学習中に計測した値の平均値を表し、青色の線は1エポック終了時に学習データから抽出したデータで計測した値を表しています。
この結果から読み取れることは、オレンジ色のグラフはaccuracyは上昇し、lossは減少しているため問題なさそうです。青色のグラフのほうはaccuracyが45%程で停滞しlossのほうは上昇してしまっています。
これらのことからこの深層学習AIは過学習を引き起こしてしまっていると判断できます。過学習とは学習データと過剰に適合しすぎてしまい未知のデータが来た時に正しい予測ができなくなっている状態のことです。問題が特定できたので対策を行っていきます。
過学習対策
過学習の対策に有効な方法は主に以下の5つの方法が挙げられます。
- 学習データの拡張
- モデルの単純化
- 早期打ち切り(Early Stopping)
- ドロップアウト
- 正則化
今回は「学習データの拡張「モデルの単純化」「早期打ち切り」「ドロップアウト」の4つを試してみました。
学習データの拡張
まず学習データの拡張ですがこれは過学習に対してとても有効な対策で可能であれば行うべきです。もともと1651試合のデータだったところを6133試合まで増やしました。モデルの単純化
次にモデルの単純化です。モデルの単純化とはモデルの層を少なくすることでパラメータを減らし過剰に適合するのを防ぎます。ReLU12層をReLU8層に変更しました。早期打ち切り
次に早期打ち切りについてです。早期打ち切りはモデルの学習状況が悪化し始めたところで学習を途中で終了してこれ以上悪化するのを防ぐ手法です。監視するデータを設定することが可能で今回はlossの値を監視することにします。ドロップアウト
最後にドロップアウトです。ドロップアウトは各エポックごとに各層で異なるニューロンをランダムに除去することで特定のニューロンに依存し過ぎないようにして過学習を防ぐ仕組みです。再学習の結果
以上の対策をしたうえで再度学習を行い結果を確認してみます。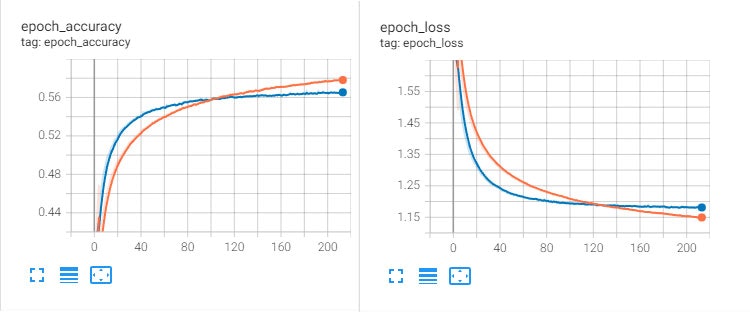
グラフを見てみるとaccuracyは上昇しlossは減少するようになっていることが分かります。これで再度モンテカルロ法AIと対戦させてみましょう。
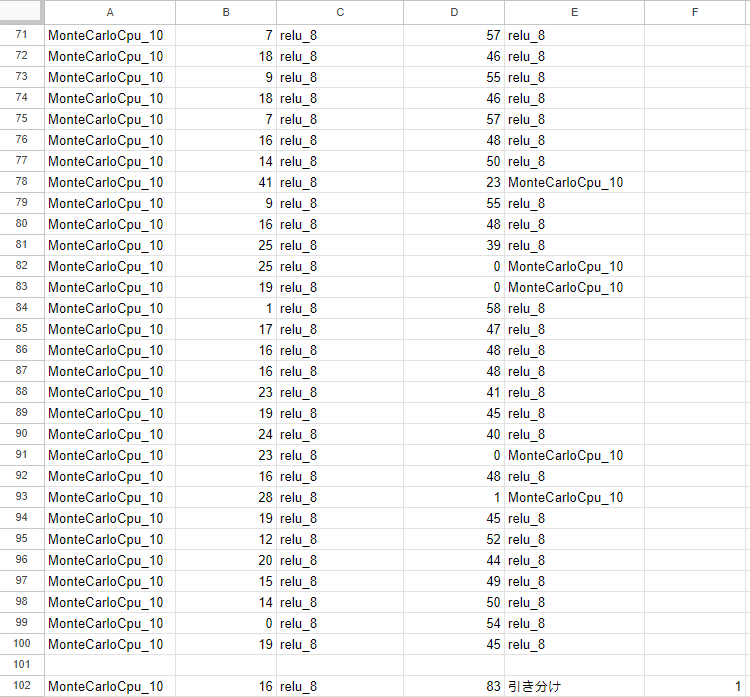
深層学習AIが83勝16敗1引き分けで勝ち越すことができるようになりました。
最後に
今回は深層学習を使ったオセロAIの実装とその調整について紹介させていただきました。記事に書いたことは深層学習の基礎的な部分で今回作成したAIもまだまだ改良の余地があります。ぜひより強いAIの作成に挑戦してみてください。最近では色々な分野で活用されている機械学習ですが、ゲーム開発においてもデバッグやパラメータ調整等活用される事例が増えています。今後もゲーム開発と機械学習は深く結びついていくと思いますのでこれを機会に機械学習に触れてみてください。