1.導入
「ChatGPTすごく話題だけど,技術的にはどうなっているの?」
と思っているそこのあなた!
私と同じですね。
今回はそのようなきっかけで,Chat-GPTに繋がる初代GPTの論文「Improving Language Understanding by Generative Pre-Training(2018)」について調べましたので解説します.
OpenAIの言語モデルは,GPT → GPT-2 → GPT-3 → InstructGPT → ChatGPTと至るわけですが,基本的なモデルはGPTのものから変わらないので,GPTのモデルを理解することがChatGPT理解の第一歩と言えると思います.
こんな方の役に立つと嬉しい
・GPTの技術的な面も知りたい方
・論文をダウンロードしてみたけどなかなか読む時間がない方
・論文を読んでみたけど,論文の中で触れられている周辺技術のことについてもさらっと理解してみたい方
2.要旨
2-1.従来手法の課題
・手作業でラベル付けしたデータがたくさん必要.
・「自然言語推論」や「テキスト分類」などのタスクに対して,タスク毎に大幅なモデルの修正が必要なことが多い.
2-2.解決策
教師無し事前学習
↓
教師ありファインチューニング
の仕組みで,ラベル付けしたデータの必要数の削減と,大幅なモデル修正を要しない汎化モデルを両立.
2-3.結果
12個のデータセットの内,9個のデータセットでSoTAを達成.
2-4.新規性
従前の手法
・LSTMを用いた手法では,短距離依存関係しか捉えることができていなかった.
・ELMo1などのfeature-based transfer2では,タスクに応じて大幅にモデルを修正する必要があり,多くの時間を要した.
GPTモデル
・Transformer3を用いたモデルで,連続した長いテキストを含む多様なデータで事前学習を行うことで,複雑な長距離依存関係を処理することができた.
・事前学習による広範な知識と,タスクに応じた簡易な入力変換により,モデルに大幅な修正を加えることなく多様なタスクに対応することができた.
概略を理解したら,いよいよモデルの内部について順を追って見ていきましょう!
3.モデル
本論文で提案されたモデルは,先述のとおり,
教師無し事前学習(Unsupervised pre-training)
↓
教師ありファインチューニング(Supervised fine-tuning)
と二段階になっています.
基本的なモデルについて論文では以下のように示されています.
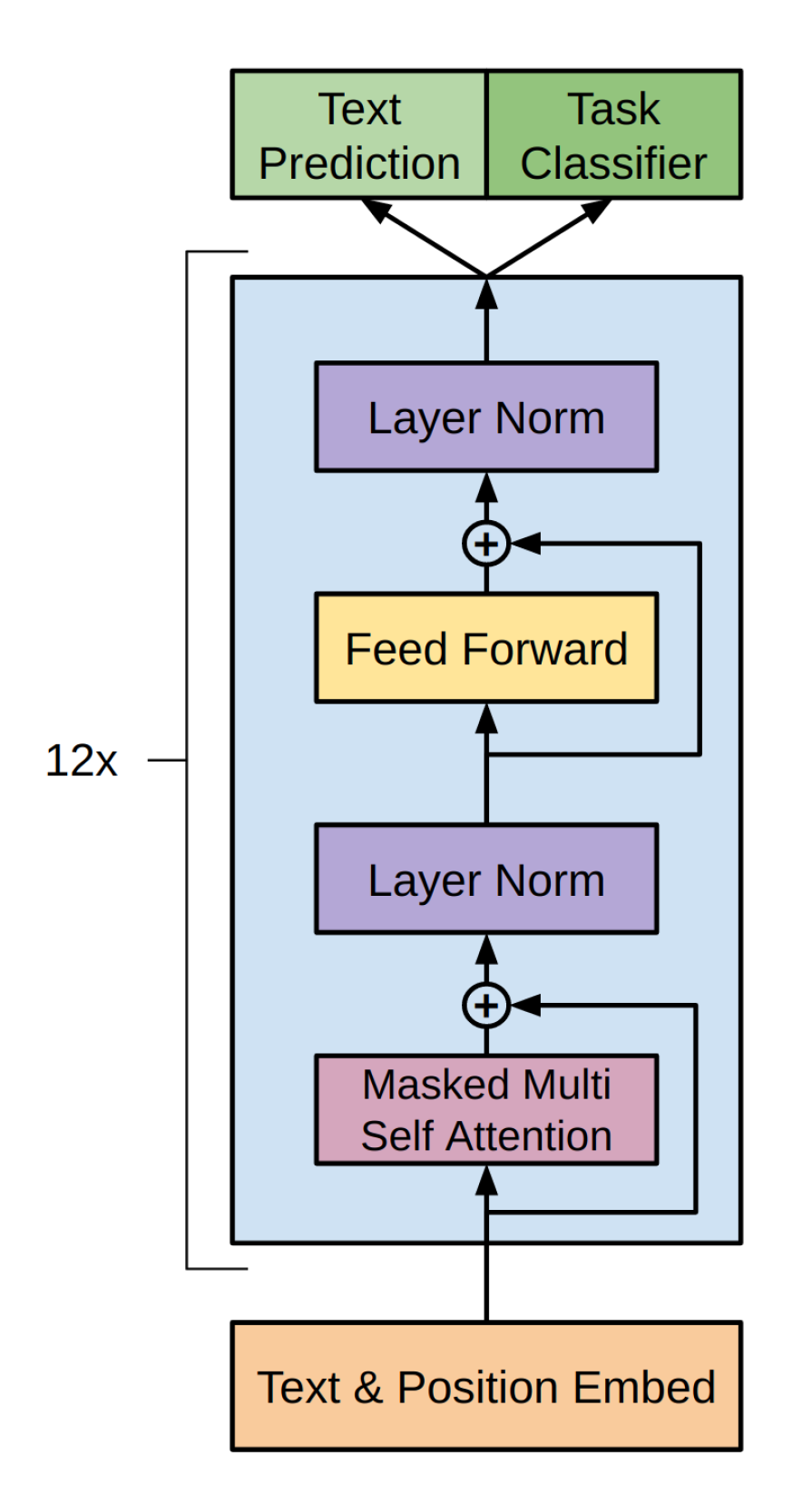
[出典:Improving Language Understanding by Generative Pre-Training(2018)]
3-1.Unsupervised pre-training
まずは,事前学習の工程です.
この論文の肝となる部分であり,内容が長くなりますが,順番に説明しますので,じっくり進めていきましょう.
事前学習工程の概略は以下のとおりです.
論文では,トークン化されたデータを $\mathcal{U} = \{u_{1}, ..., u_{n}\}$と置き,以下の対数尤度を最大化するように学習しています.
L_{1}(\mathcal{U}) = \sum_{i} \log P(u_{i} | u_{i-k}, ..., u_{i-1};\Theta)\\
($\Theta$:学習モデルのパラメーター)
3-1-1.入力
まずは学習する元データについて.
BookCorpus datasetが使用されています.BookCorpus datasetでは,7,000を超える様々なジャンルの未出版本が収録されています.
また,1B Word Benchmarkというデータセットも使用されています.
自然言語のデータをそのまま利用することはできないので,トークン化(例:「000:あ」,「010:ああ」,「011:あい(愛)」)を行うことになります.
ただし,対象とする文字列や単語が多ければ多いほどモデルの計算量も増えてしまうので,全ての単語を対象とすることはできません.
そこで,本モデルでは,「Neural machine translation of rare words with subword units(2015)」で提案されたByte Pair Encodingの手法を使って,全体のトークン数を
基本文字478("a", "b", "-", "\n", "<unk>4"など)
+
文字組み合わせ40,000("and</w>5", "cur", "embarrassing"など)
= 40,478
に押さえ込んでいます.
Byte Pair Encodingについて詳しく・・・
Byte Pair Encodingのアイディアは,登場頻度の低い単語(例:一般常識)について直接対象とするのではなく,より頻度の高い「一般」と「常識」さえ対象にしてしまえば,「一般」+「常識」の連続と認識してもさほど問題ないのではないかということです.そこで,文字列と文字列の合成(merge)に関して,回数の上限を設定し,それより後の合成語については,その構成要素の連続として認識することを提案しています.
<例>
・「あ」 + 「い」 → 「愛」
は登場回数が多いから,合成して1単語として扱おう!
・「一般」 + 「常識」 → 「一般常識」
は登場回数が少ないから,合成せずに「一般」と「常識」の連続として扱おう!
Byte Pair Encodingの学習アルゴリズムを噛み砕くと以下のとおりです.
- 0. 語彙list,pair-listを作成し,hyper-parameterであるmerge回数を設定する.
- 本モデルでは,merge回数は40,000
- ※語彙list,pair-listは一般的な用語ではなく,説明用の便宜的な用語
- 1. 基礎文字を用意し,語彙listに追加する.
- 本モデルでは,"a", "b", "-", "\n", "\unk"などの478文字
- (Unicodeで表現された特殊文字や,文字と語末マーカーとの組み合わせを含む.)
- 2. dataset内の単語の出現回数を計上し,単語と出現回数の辞書データを作成する.
- 例:{("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)}
- 3. 辞書データの単語を基礎文字に分解する(基礎文字に存在しない場合は"\unk"とする).
- 例:{("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)}
- 4. 最も多いpair(""で囲われる単位2つの組み合わせ)を抽出する.
- 例:"h"&"u":15, "u"&"g":20 ... → "u"&"g"を抽出
- 5. 抽出したpairをmergeする.
- 例:{("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)}
- 6. 抽出したpairを抽出順とともにpair-listに追加する.(抽出順は実際にencodeするときに使用します.)
- 例:{"ug", 1}をpair-listに追加
- 7. merge回数が目標数に達しているか確認する.
- ↪︎目標数に達していない → 「4.」に戻る.
- 8.語彙listに基礎文字以外のmergeされた語彙を追加する.(語彙listの完成)
- 例:"ug"を追加する.
- 1. データを基礎文字に分解する.
- 2. pair-listの抽出順の若いpairから順番に,pair-listの最後まで順番にmergeする.
- 3. merge後のデータの語彙を,語彙listのindexでencodeする.
3-1-2.Embedding Layer
埋込層では,以下のとおり語彙情報の埋め込みと,位置情報の埋め込み(position embedding)を行なっています.
h_{0} = UW_{e} + W_{p}\\
$U=(u_{-k}, ..., u_{-1})$:予測したいトークンが$u_{i}$であるとすると,その$k$個前までのトークンまでのことで,このデータを元に$u_{i}$を予測します.
$W_{e}$:埋込行列($W_{e} \in \mathbb{R}^{40,478\times768}$(40,478=全体のトークン数))
$W_{p}$:position embedding用の行列($W_{p} \in \mathbb{R}^{512\times768}$(512=入力データ長))
語彙情報の埋め込みについて詳しく・・・
Byte Pair EncodingでEncodeされた各語彙(トークン)のそれ自体は,本モデル上のindex以上の情報を持っていません.本来,各語彙(トークン)には固有の意味があるので,その意味を捉えたベクトル表現を学習することとなります. 今回のモデルでは,$W_{e}$の各行がそれぞれのトークンのベクトル表現に対応しています. 実際にそのベクトル表現を使用するときには,以下のコードで入力データ内のトークンのindexを用いて,対応するベクトル表現を$W_{e}$から参照しています.def embed(X, we):
we = convert_gradient_to_tensor(we)
e = tf.gather(we, X)
h = tf.reduce_sum(e, 2)
return h
また,以下のコードのとおり初期値を正規分布で与えて,ベクトル表現自体もモデル内で学習しています.
we = tf.get_variable("we", [n_vocab+n_special+n_ctx, n_embd], initializer=tf.random_normal_initializer(stddev=0.02))
位置情報の埋め込みって何・・・
position embeddingが必要であることは,GPTでその派生系が利用されているTransformerの仕組みに起因しています.Transformerが登場するまでは,自然言語処理の分野ではLSTMをベースとしたものが主流でした.LSTMはトークンを文章の順番通りに逐次的に処理しながら,時系列データを保持することで文脈の理解を高めることができました.
[LSTMの構造概略]
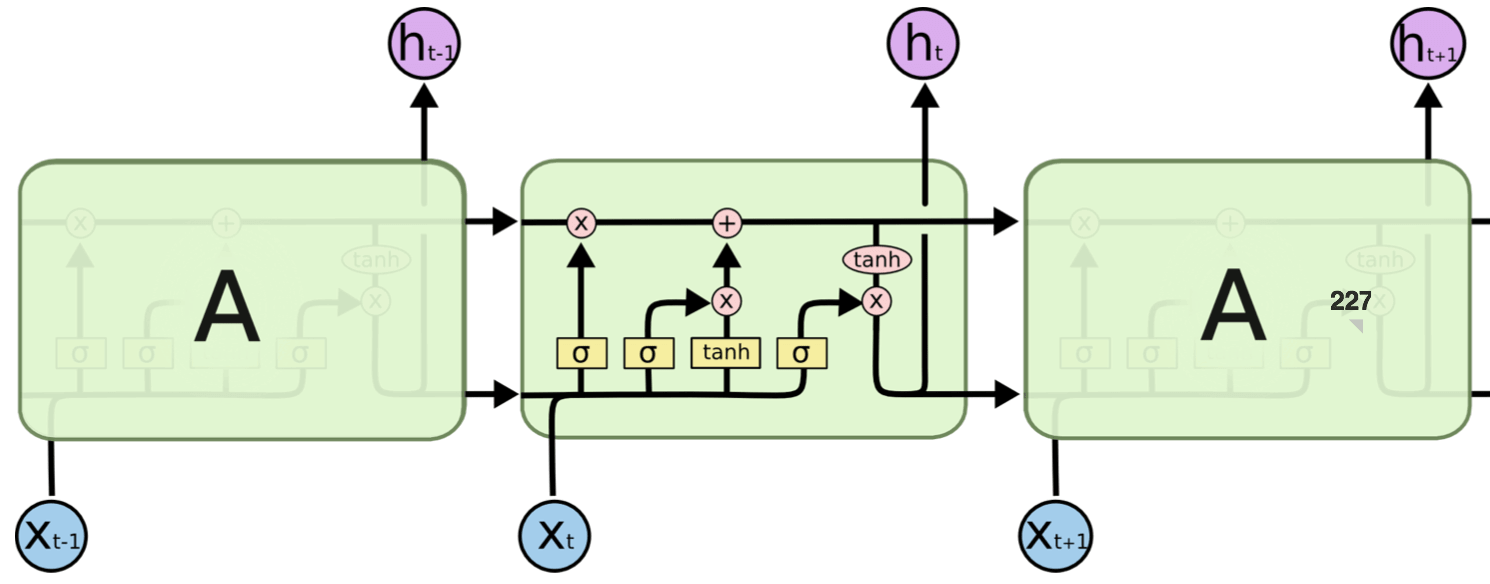)
出典:自然言語処理に使われるLSTMとは?RNNとの違いや特徴を紹介 [https://aismiley.co.jp/ai_news/lstm/]
一方で,逐次的な処理が必要であるため,並列的に処理することができず計算時間が長くなってしまうという欠点がありました.
そこで現れたのがTransformerであり,その最大の強みは,並列処理ができることでした.ただし,Transfomerの論文でも示されているとおり,時系列データを保持していないので,そのトークンが文章上どの位置(position)にあるかをembeddingする必要があります.それがposition embeddingです.
3-1-3.Transformer Block
論文では,簡単に次のように示されています.
\begin{align}
h_{l} &= \mathrm{transformer\_block}(h_{l-1}) \forall i \in [1,n]\\
P(u) &= \mathrm{softmax}(h_nW^T_e)
\end{align}
この最終的な出力である$P(u)$がモデルによる予測になります.
ここでは,Transformerの派生系であるTransformer Decoderを採用しています.
Transformer Decoderは,「GENERATING WIKIPEDIA BY SUMMARIZING LONG SEQUENCES(2018)」で提案された手法です.
encoderとdecoderの両方が存在するオリジナルのTransformerとは異なり,Transformer Decoderではその名のとおりdecoderのみを利用します.
Tranformer Decoderについて詳しく・・・
Q.なぜDecoderのみを利用するのか?A.Hyper-parametersを約半数にまで削減でき,より長い文章にも対応することができるから.
<詳細>
論文(GENERATING WIKIPEDIA BY SUMMARIZING LONG SEQUENCES(2018))では,Wikipedia内のReferenceにあるページや,一般的な関連するWebページを要約する事で,Wikipediaにより近い記事を生成することを目標としています.
そのため,必然的にインプットとなる文章が長くなり,Hyper-parametersを削減する動機ができた訳です.
また,この論文の著者は,monolingualのtext-to-textタスクにおいては,EncoderとDecoderの両方で冗長的に言語に関する情報を再学習してしまっているのではないかと気づきました.
そこで,以下のようなサンプルデータの変換を用いることで,TransformerのEncoder部分を省略することを提案しました.
入力データ : $m^1,...,m^n$
正解データ : $y^1,...,y^\eta$
セパレータ : $\delta$
変換後の入力 : $w^1,...,w^{n+\eta} = m^1,...,m^n,\delta,y^1,...,y^\eta$
実際に,精度を大幅に落とすことなく,より長い文章に対応できています.
さらにTransformer Decoderは,
・Masked Multi Self Attention層
・Feed Forward層
・Layer Norm層
で構成されています.
また,順番に見ていきましょう!
・Masked Multi Self Attention層
オリジナルのTransformer(Attention is all you need(2017))で提案されたモジュールであり,現段階において入力データのどこに注目すべきかを判定し,そのトークンの情報を取り入れています.

[出典:Attention is all you need(2017)]
Multi-Head(本論文では12Heads)にすることで,それぞれのHeadが異なる特徴を持ち,より複雑な表現ができるとされています.
Input全体からどこに注目すべきか参照するため,何も工夫をしなければ,予測すべき次のトークンの情報も含めた全ての内容から注目すべき情報を取ってしまいます.
つまり,カンニングしながら予測するようなものです.
ですので,次のトークン以降は参照できないようにmaskされています.
このmaskされたmulti-headのself-Attenntion機構がその名のとおり,Masked Multi Self-Attentionです.
・Feed Forward層
埋込層で抽出した特徴量の次元($\mathbb{R}^{768}$)よりも大きな特徴空間($\mathbb{R}^{3072}$)に投影するために,より大きな次元の中間層を持ったFeed Forward層を想定します.
それを1次元のCNNで実現しており,Kernel数を4倍の3,072にしています.
具体的には以下のとおりです.
活性化関数で利用されているGELU(Gaussian Error Linear Units)は以下のWEBページの解説が非常にわかりやすいので紹介させていただきます.
「活性化関数GELUを理解する」
・Layer Norm層
レイヤー毎(Transformer Block層,Feed Forward層)に,そのレイヤーのインプットとアウトプットの和に対して正規化をしています.
それぞれのレイヤーの$i$番目のインプットが$x^{(i)}=[x_{1}^{(i)}, ... ,x_{768}^{(i)}]$,$i$番目のアウトプットが$y^{(i)}=[y_{1}^{(i)}, ... ,y_{768}^{(i)}]$であるとすると,正規化後のLayer Norm層の出力は以下の$\overline{a^{(i)}}$となります.
\begin{align}
a_{j}^{(i)} &= x_{j}^{(i)} + y_{j}^{(i)}\\
\mu^{(i)} &= \frac{1}{H} \sum^{H}_{j=1} a_{j}^{(i)}\\
\sigma^{(i)} &= \sqrt{\frac{1}{H} \sum^{H}_{j=1} (a_{j}^{(i)}-\mu^{(i)})^2}\\
\overline{a_{j}^{(i)}} &= \frac{g_{j}^{(i)}}{\sigma^{(i)}}(a_{j}^{(i)}-\mu^{(i)})+b_{j}^{(i)}\\
\overline{a^{(i)}}&=[\overline{a_{1}^{(i)}}, .., \overline{a_{j}^{(i)}},...,\overline{a_{768}^{(i)}}]
\end{align}
*$g_{j}^{(i)},b_{j}^{(i)}$はそれぞれ1と0で初期化されるハイパーパラメーター
Layer Normalizationについて詳しく・・・
そもそもバッチ毎や,レイヤー毎で行う正規化(Normalization)は,膨大となってしまうDeep Neural Networkの学習にかかる時間を減らすために,パラメーターの正規化を行うものです.Layer Normalizationは,「Layer Normalization(2016)」で提案された手法であり,従来の手法であるBatch Normalizationの以下の欠点を克服した手法となっています.
・効果がバッチサイズに依存していること.特に小さいバッチサイズでは不安定になってしまう.
・RNNの入力シーケンスの長さは変化することが多いため,RNNにバッチ正規化を適用すると,バッチ毎に異なる母数で計算しなければならなくなる.
そこで,Layer Normalizationでは正規化の単位を
Batch Normalization:バッチデータ全体で
↓
Layer Normalization:サンプル毎にレイヤーのアウトプット全体で
に修正しています.
※GPTの論文では,インプットとアウトプットの和をそのレイヤーのアウトプットとする残差結合が利用されているため,サンプル毎にインプットとアウトプットの和全体で正規化しています.
3-1-4. 最適化手法について
最適化アルゴリズムはADAMを利用しています.最適化アルゴリズムについては,以下の記事がすごくわかりやすいので,紹介させていただきます.
「【決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法-」
正則化は,「DECOUPLED WEIGHT DECAY REGULARIZATION(2019)」で提案されたDecoupled Wight Decayを採用しています.
Decoupled Wight Decayについて詳しく・・・
まずは,本論文の肝となるL2-normalizationと,Weight Decayの元来の手法は以下のとおりです.・L2-normalization
損失関数$f_t(\theta)$に正則化項$\frac{\lambda^{\prime}}{2}||\theta||^2_2$を加算するもの.
f^{reg}_t(\theta) = f_t(\theta)+ \frac{\lambda^{\prime}}{2}||\theta||^2_2
\\
\theta_{t+1} = \theta_{t}-\alpha\nabla f^{reg}_t(\theta_t)
・Weight Decay
パラメーター更新時に,現在の値に$(1-\lambda)$を乗じるもの.
\theta_{t+1} = (1-\lambda)\theta_{t}-\alpha\nabla f_t(\theta_t)
この2つの正則化手法は,最適化アルゴリズムとしてSGDを採用した場合は,同一視することができます.
\begin{align}
f^{reg}_t(\theta) &= f_t(\theta)+ \frac{\lambda^{\prime}}{2}||\theta||^2_2\quad(\mathrm{=L2-norm})
\\
\Leftrightarrow \theta_{t+1} &= \theta_{t}-\alpha\nabla f^{reg}_t(\theta_t)
\\
\Leftrightarrow \theta_{t+1} &= \theta_{t}-\alpha(\nabla f_t(\theta_t)+\lambda^{\prime}\theta)
\\
\Leftrightarrow \theta_{t+1} &= (1-\lambda)\theta_{t}-\alpha\nabla f_t(\theta_t)\quad(\mathrm{=Weight Decay})
\\
(\lambda&=\alpha\lambda^{\prime})
\end{align}
そのため,この論文が発表された当時は,L2-normとweight decayは同一視されることが多く,一般的なDeep LearningのライブラリではL2-normを実行するのみになっており,最適化アルゴリズムはL2-normと相性の良いSGDの派生系が主流でした.
この論文の指摘は,L2-normとweight decayがADAMなどの適応的勾配アルゴリズムを採用した場合には全く異なるものになるということです.
また,ADAMなどの適応的勾配アルゴリズムが主流でなかったのは,誤ってL2-normとweight decayが同一視されることでADAMなどと相性の悪い最適化手法であるL2-normと組み合わされていたことが原因としています.
そこで,本論文では,本来のweight decayの効果を再現するためにLearning Rateの設定などから独立したDecopled weight Decayを導入し,ADAMなどの適応的勾配アルゴリズムに対する効果的な正則化手法を提案することで,ADAMなどの利用価値を高めました.
論文で提案されているDecoupled Wight Decayを導入したアルゴリズムは以下のとおりです.

[出典:DECOUPLED WEIGHT DECAY REGULARIZATION(2019)]
3-2. Supervised fine-tuning
ファインチューニングの工程では,基本的に事前学習で用いたモデルをそのまま利用し,タスクに合わせてパラメーターを調整します.
ファインチューニング用のデータセットを$\mathcal{C}$,
データの各トークンを$x^1,...,x^m$,
そのラベルを$y$とすると,最大化したい尤度関数は以下のとおりです.
L_{2}(\mathcal{C}) = \sum_{x,y} \log P(y | x^1, ..., x^m)
モデルによる予測は,最後のTransformer Blockの出力を$h^m_l$,出力層の重み行列を$W_y$とすると以下のようになります.
P(y | x^1, ..., x^m) = \mathrm{softmax}(h^m_lW_y)
Supervised fine-tuningで最適化する目的関数は以下のとおりです.
L_3(\mathcal{C}) = L_2(\mathcal{C})+\lambda*L_1(\mathcal{C})
これは,タスクに合わせたファインチューニングを行いながら,言語モデル自体の学習も並行して実行するものであり,汎化性能の向上と,収束の高速化を実現できるとされています.
また,基本的にタスク毎に入力の形式は異なります.
例えば,テキスト間推論(Textual Entailment)は,1つのテキスト(前提:premise)が別のテキスト(仮説:hypothesis)を論理的に導出するかどうかに関して推論するものであり,入力は前提と仮説の2つが必要となります.
そのような変動に対し,以下の図で示すように,Startトークン,Extractトークンに加えて,Delimiterトークンを用いて,事前学習したモデルに適用できるようにしています.

[出典:Improving Language Understanding by Generative Pre-Training(2018)]
4.結果
・Natural Language Inference
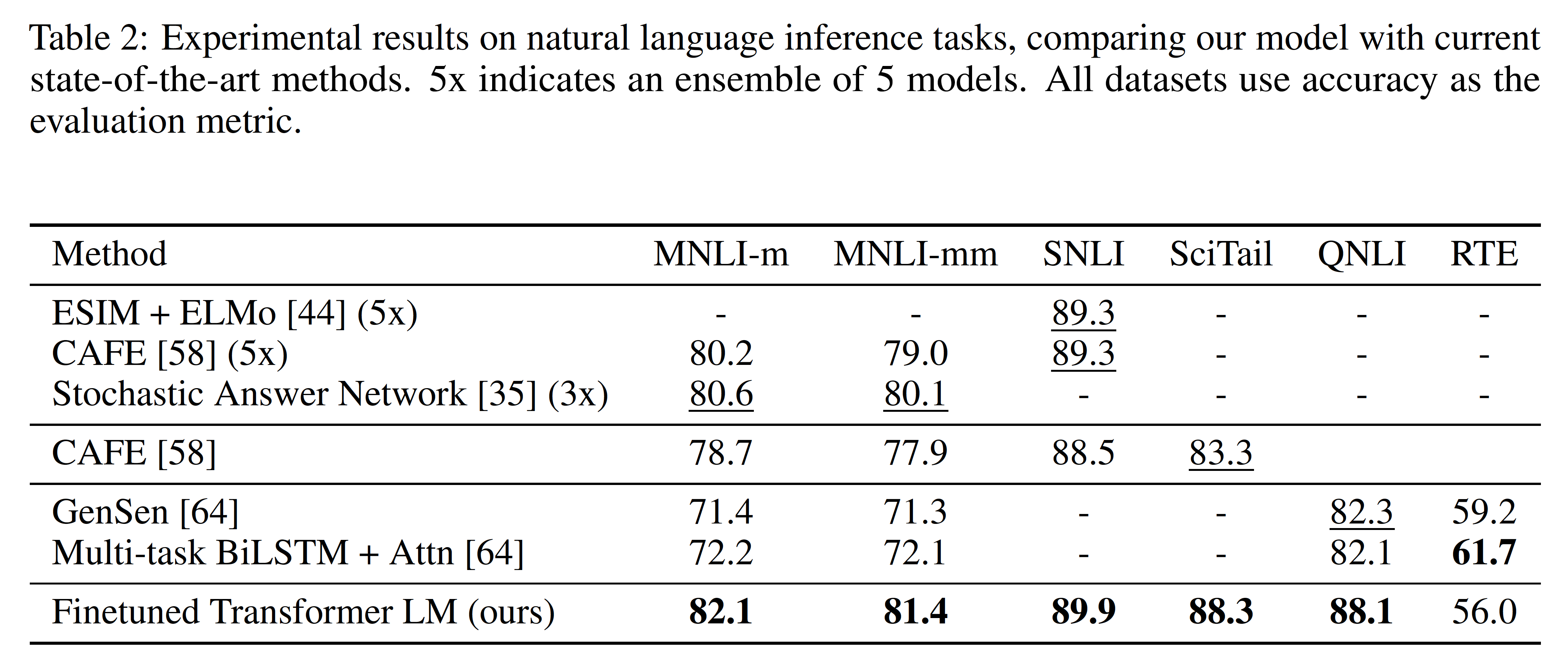
[出典:Improving Language Understanding by Generative Pre-Training(2018)]
自然言語推論(Natural Language Inference)は,テキスト間の関係を判断するタスクであり,文のペアを読み,それらの間の関係を含意,矛盾,または中立のいずれかを判断するものです.
5つのデータセットのうち4つでベースラインを上回っています.ただ,最も小さいデータセットであるRTEでは,改善が見られていません.
・Question answering and commonsense reasoning

[出典:Improving Language Understanding by Generative Pre-Training(2018)]
Question answering(質問応答)は,言葉どおり質問に対して適切な回答を選択するタスクです.ここでは,中学校と高校の試験からの英語の文章と関連する質問から構成されるRACEデータセットを使用しています.
Commonsense reasoning(常識的推論)について,ここでは,Story Cloze Testデータセットを用いて,2つの選択肢からマルチセンテンスのストーリーに適切な結末を選ぶタスクを行なっています.
Question answering and commonsense reasoningでは,全てのデータセットでベースラインを上回っています.
・Classification and Semantic similarity

[出典:Improving Language Understanding by Generative Pre-Training(2018)]
Classification(分類)は,2つの異なるテキスト分類タスクで評価を行っています.Corpus of Linguistic Acceptability(CoLA)では,文が文法的かどうかを分類します.一方,Stanford Sentiment Treebank(SST2)は,標準的な2値分類タスクです.CoLAで45.4のスコアを獲得し,大幅な向上を示しています.また,SST-2では91.3%の精度を達成し,最先端の結果に競合する性能を持っています.
Semantic similarity(意味の類似性)は,2つの文が意味的に等しいかどうかを予測します.類似性タスクのうち2つでSoTAを達成しています.
5.分析
・Impact of number of layers transferred and Zero-shot Behaviors

[出典:Improving Language Understanding by Generative Pre-Training(2018)]
Impact of number of layers transferred(転送される層の数の影響)については,上の図の左側で示されているとおり,タスクに対する学習・推論を行う際に事前学習した層を多く活用するほど良い結果となっているので,事前学習における各層が有用な情報を保持していることが示されています.
Zero-shot Behaviorsについて,上の図の右側で,全てのタスクにおいて訓練が進むにつれて着実にパフォーマンスが向上していることがわかります.これは事前学習が幅広いタスク関連の機能を学習するのを支えていることを示しています.また,TransformerはLSTMよりも安定したパフォーマンスとなっています.これは,Attention機構によって複雑な依存関係を捉えていることが寄与していると考えられます.
Zero-shotって何?
ここでの"shot"は,個別のタスクに対する学習データのことです.Zero-shot learningの目標は,訓練中に見たことのないカテゴリに対しても,モデルが適切に分類できるようにすることです. 例えば,ある画像分類器が「犬」「猫」「馬」の画像で訓練されていたとします.
この分類器に対してZero-shot learningを適用すると,訓練中に見たことのない「象」の画像を適切に識別する能力を持つようになることを目指すようなものです.
・Ablation studies

[出典:Improving Language Understanding by Generative Pre-Training(2018)]
ここでは,「The auxiliary LM objective during fine-tuningの有無」,「Tranformer or LSTM」,「事前学習の有無」の3項目でパフォーマンスの比較をしています.
・The auxiliary LM objective during fine-tuningの有無
The auxiliary LM objective(補助的な言語モデル目標)は,Supervised fine-tuningの時に出てきた
L_3(\mathcal{C}) = L_2(\mathcal{C})+\lambda*L_1(\mathcal{C})
の"$ + \lambda*L_1(\mathcal{C})$"の部分のことであり,単純にタスクの目的関数のみを用いるのではなく,補助的に言語モデル自体の目的関数を同時に学習することで,汎化性能の向上と,収束の高速化ができるというものでした.
この補助的目標は,大きなデータセットでは効果が出ているのに対し,小さなデータセットでは,パフォーマンス向上に寄与していないことがわかります.
・Tranformer or LSTM
Transformerの代わりに,LSTMを活用することで,1つのデータセットを除く全てのデータセットでパフォーマンスが下がることがわかります.
・事前学習の有無
今回のモデルに対し,事前学習無しのモデルは全てのデータセットで大きくパフォーマンスが低下していることがわかります.
6.参考にした情報
この記事は以下の情報を参考にして執筆しました.
- Improving Language Understanding by Generative Pre-Training(2018)
- Deep contextualized word representations(2018)
- Attention is all you need(2017)
- Neural machine translation of rare words with subword units(2015)
- GENERATING WIKIPEDIA BY SUMMARIZING LONG SEQUENCES(2018)
- Layer Normalization(2016)
- DECOUPLED WEIGHT DECAY REGULARIZATION(2019)
- Byte-Pair Encoding tokenization
- 自然言語処理に使われるLSTMとは?RNNとの違いや特徴を紹介
- 活性化関数GELUを理解する
- 【決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法-
- 【論文解説】OpenAI 「GPT」を理解する
-
ELMo:「Deep contextualized word representations(2018)」で提案されたUnsupervised pre-trainingを用いたモデルの一種であり,feature-based transferを採用しています. ↩
-
feature-based transfer:転移学習(transfer)の手法の一種であり,事前学習した単語の埋込表現を,タスクごとのモデルで使用するもの.GPTやBERTのような事前学習したモデルをそのまま転用し,fine-tuningするfine-tuning-based transferと異なり,タスク毎に大幅なモデル修正が必要となります. ↩
-
Transfomer:「Attention is all you need(2017)」で提案された革命的な手法.LSTMのような時系列処理を廃し,Attention機構のみで高度な自然言語処理を達成しています. ↩
-
"<unk>"は対象外の文字列であることを示すマーカーのことです. ↩
-
"</w>"は語末示すマーカーのことです. ↩