この記事は、自社ブログの記事を技術者向けに再編集したものです。元記事は botトラフィックでチャネル評価が狂う理由:除外しないと予算を誤る です。
「アクセス解析を見たら、ある経路からの流入が急に伸びていた。新しいチャネルが当たったのかもしれない」。そう思って予算や手間を寄せようとしたことはないでしょうか。
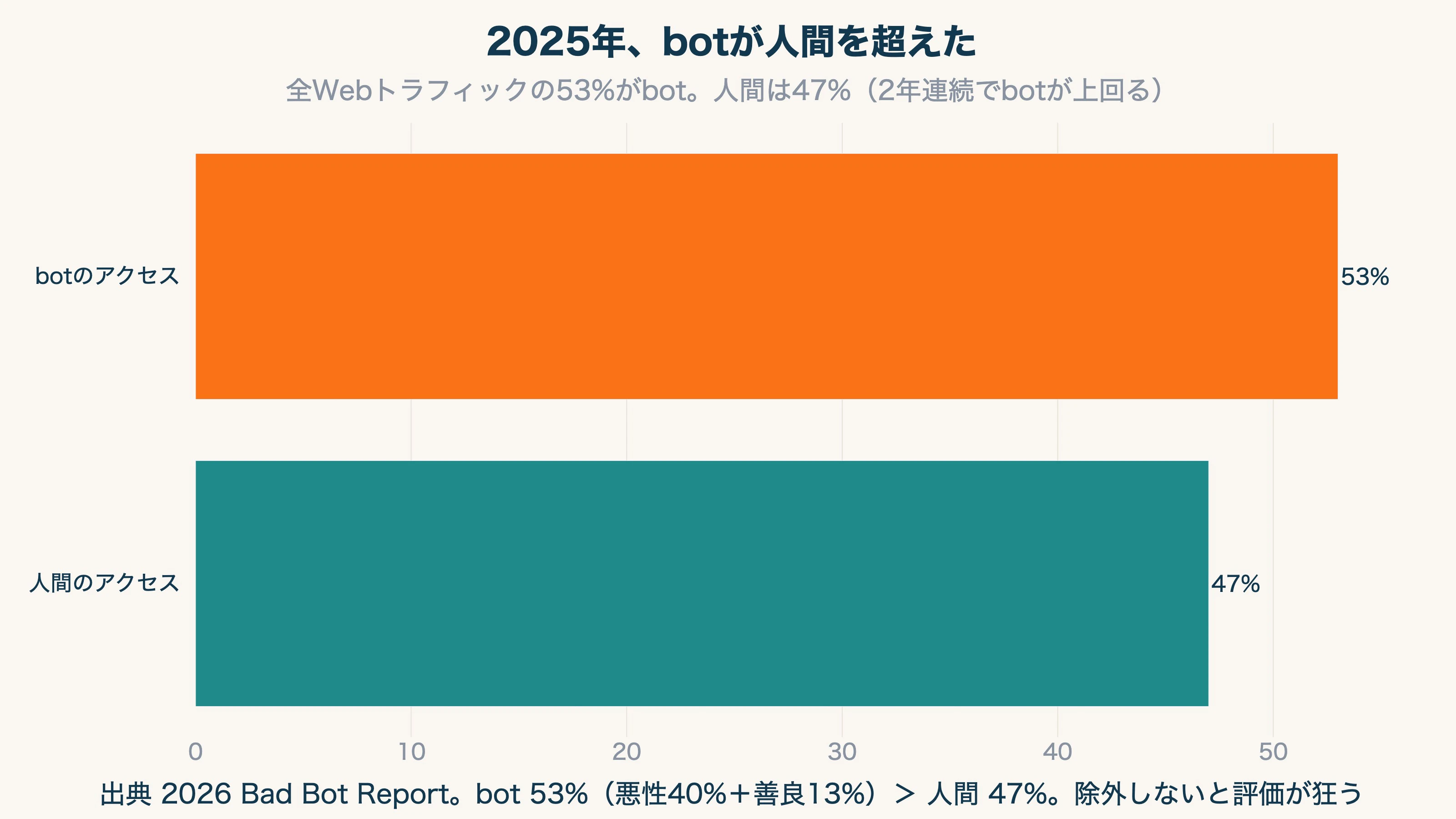
結論を先に言うと、その流入は人間ではなく bot かもしれません。bot は今やインターネット全体のアクセスの 53% を占め、ついに人間(47%)を上回りました[1]。問題は bot が来ること自体ではありません。bot が混ざった流入を「効いているチャネル」と誤って評価し、無効な経路に予算を割き、本当に伸びるチャネルを見過ごしてしまう ことです。
この記事は、まず現象と原因(なぜ bot が参照元付き流入に紛れるか)を押さえたうえで、後半に 計測担当向けの技術パート を置きました。具体的には、(1) GA4 の既知 bot 自動除外の仕組みと限界、(2) ユーザーエージェント・IP・ふるまいといった見分けの観点、(3) GTM / GA4 のフィルタ設定とサーバーログでの確認観点、の 3 つを扱います。先に要点を言うと、bot の判別は単独のシグナルでは誤判定しやすく、複数の角度を重ね、しかも継続的に見直す必要がある領域です。
この記事のまとめ
- bot はインターネット全体のアクセスの 53% を占めて人間(47%)を上回り、その多くは参照元のある流入として解析データに紛れ込む
- GA4 が自動除外するのは IAB が管理するブラックリスト(既知 bot の一覧)に載った「既知の bot」だけで、ブラックリストにない bot や正体を隠す bot は素通りする。しかも除外量は確認できない
- 自動除外で取りこぼした bot の見分けには、ふるまい(滞在の短さ・単一 PV・等間隔アクセス)と UA / IP(データセンター ASN など)を複数重ねる必要があり、単独のシグナルでは人間の直帰と誤判定しやすい。高度な bot ほど判別は難しく、継続的な分析が要る
まず何が起きているか:botが参照元付き流入に紛れる
bot(ボット)は、検索エンジンや SNS、各種ツールが動かす自動アクセスのプログラムです。Thales(旧 Imperva)の調査では、2025 年にインターネット全体のアクセスのうち 53% が bot となり、人間の訪問(47%)を 2 年連続で上回りました。うち悪性 bot は 40%、検索エンジンや AI クローラーなど善良な bot は 13% です[1]。生成 AI の普及で、自動アクセスはさらに増えています。
bot がチャネル評価に紛れ込むのは、多くの bot が「参照元のあるアクセス」として記録されるからです。たとえば SNS や動画サイトの説明欄にサイトの URL を貼ると、その中身を読み取るための bot(リンクプレビュー用 bot)が自動でページを開きます。このアクセスは、解析ツールには「その SNS や動画サイトからの流入」として残ります。つまり、人が訪れていないのに「新しいチャネルからの流入」が数字として立ち上がるのです。
代表的な bot の種類を整理すると、次のようになります。
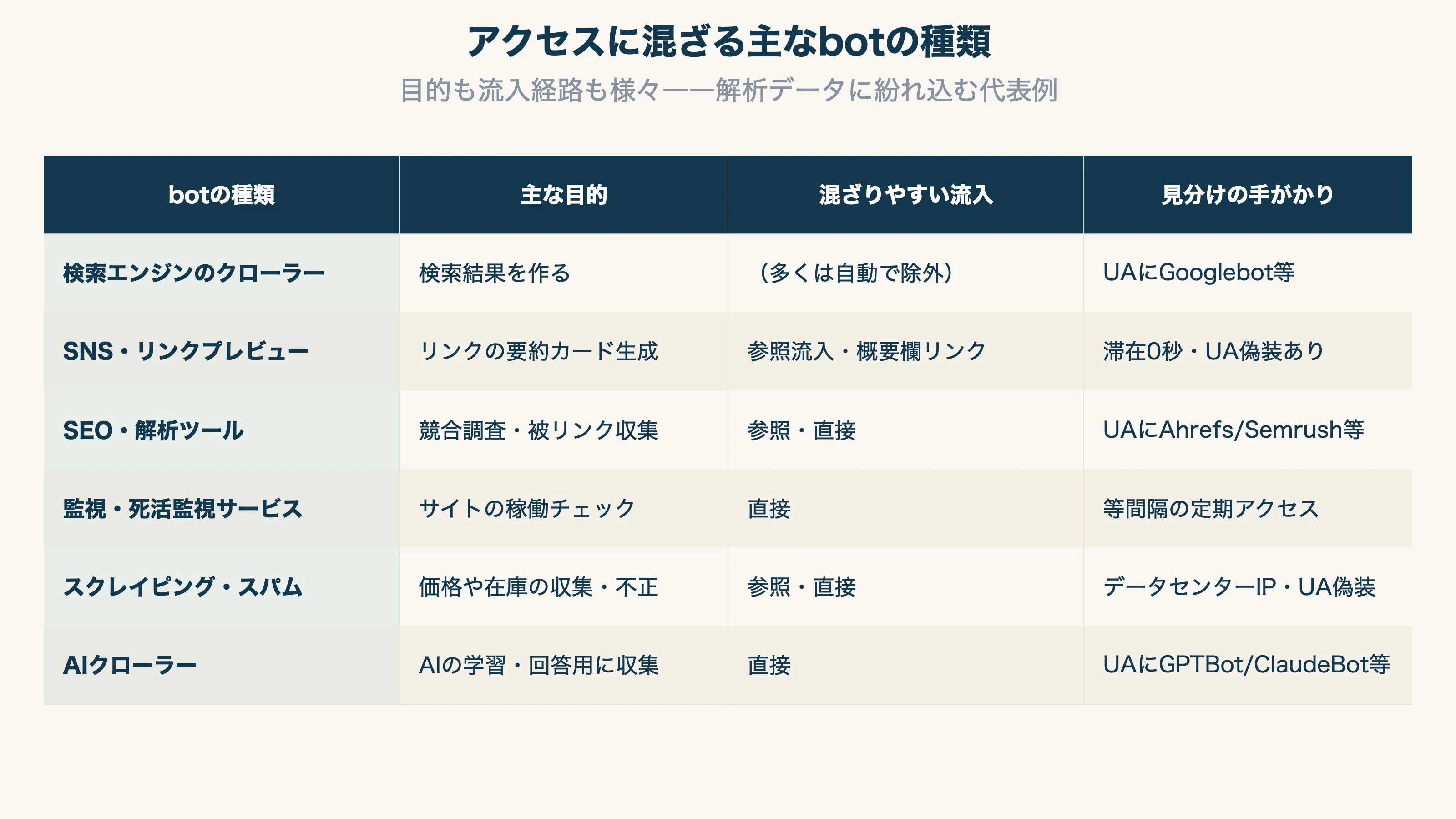
検索エンジンのクローラー(Googlebot など)は正体がはっきりしていて、ユーザーエージェントに名前が含まれるため、GA4 などでは多くが自動で除外されます。注意が要るのは、SNS やチャットのリンクプレビュー用 bot、SEO 解析ツール、監視サービス、スクレイピング、AI 学習用クローラーなど、参照元付き流入に紛れ、ブラウザのふりをして正体を隠す bot です。ここからは、これをどう見分けるかを技術レベルで扱います。
技術1:GA4の既知bot自動除外の仕組みと限界
GA4 は「既知の bot とスパイダーからのトラフィックを自動的に除外する」機能を持ちますが、その判定根拠を理解しておかないと「除外されているはずだから安心」と誤解します。
GA4 の自動除外は、IAB(Interactive Advertising Bureau)が管理する International Spiders and Bots List と Google 独自の調査リストに基づいています[2]。これは既知の bot を一覧化したいわば ブラックリスト方式 で、判定の中心はユーザーエージェントなどで識別された 既知の bot のリストマッチ であり、ふるまい解析で未知の bot を見抜く仕組みではありません。ここに 3 つの限界があります。
- ブラックリスト(既知 bot の一覧)にない bot は素通りする。新興のスクレイパーや自作クローラー、生成 AI 系の新しいクローラーはリスト反映が追いつかず、人間の流入として計上されます
-
UA を偽装する bot は識別できない。
Mozilla/5.0 ... Chrome/...のような正規ブラウザの UA を名乗る bot は、リストマッチをすり抜けます - 除外された量を後から確認できない。GA4 の自動除外は標準レポートに「何件除外したか」を出しません。除外設定の有無は管理画面のデータストリーム設定で確認できますが、除外実数は不可視です
GA4 自動除外の判定フロー(概念)
ヒット受信
└─ User-Agent / 既知 bot ブラックリスト(IAB + Google)に一致?
├─ Yes → 計測から除外(件数は不可視)
└─ No → 人間トラフィックとして計上(← 未知 bot / UA 偽装はここに混入)
要点は、GA4 の自動除外は「既知 bot のリストマッチ(ブラックリスト方式)」であって「ふるまい検出」ではない ことです。ブラックリスト(既知 bot の一覧)にない bot を取りこぼすのは仕様です。では後段でふるまいを見れば自前で補えるかというと、ここからが難しいところで、高度な bot は正規ブラウザの UA を名乗り、滞在の短さだけでは人間の直帰と区別がつきません。リストの更新を追い続け、セッション横断の振る舞いを継続的に見直す体力が要る領域であり、片手間の自前運用では取りこぼしが残り続けます。
技術2:ユーザーエージェント・IP・ふるまいでの見分け方
自動除外で取りこぼした bot は、UA・IP・ふるまいの 3 つの観点を組み合わせて見分けます。単独の指標では誤判定しやすいため、複数を重ねるのが実務の基本です。
ユーザーエージェント(UA)
UA 文字列に bot / crawler / spider / slurp / bingbot / Googlebot などの語が含まれる場合は、自己申告型の bot です。ただし前述のとおり UA は偽装できるため、UA だけでの判定は「正直な bot を拾う」程度に留めます。サーバーログを見られる環境なら、UA 別にアクセス数とふるまいを集計するのが第一歩です。
IP(データセンター・ASN・reverse DNS)
人間の訪問は一般的に ISP やモバイルキャリアの IP から来ますが、bot の多くは AWS / GCP / Azure などの データセンター IP(ASN がクラウド事業者) から来ます。アクセス元 IP の ASN を引いて、クラウド事業者のレンジが上位を占めていれば bot を疑います。
加えて、Googlebot など正規クローラーを名乗るアクセスについては、Google が正規の Googlebot かどうかを検証する手順を公式に案内しています[3]。ただしこうした検証は対象が明確な正規クローラーに限った話で、正体を隠す bot の判別までカバーするものではありません。
ふるまい(滞在時間・PV・アクセス間隔)
最も汎用的に効くのが ふるまい です。人間はページを開けば数秒でも滞在し、複数ページを見ることがあります。bot の多くは次の特徴を示します。
- 平均滞在時間がほぼ 0 秒(GA4 のエンゲージメント時間が 0)
- 単一 PV で離脱(1 ページだけ開いて去る)
- 等間隔・同一ページへの連続アクセス(機械的なリクエストの典型)
このふるまいをチャネル単位で並べると、bot 混入が一目で分かります。

上のマトリクスのように、チャネルを「流入量 × 平均滞在時間」で並べると性格がはっきり分かれます。量が多いのに平均滞在がほぼ 0 秒 の経路は、bot 混入を最優先で疑い、除外して人間の訪問が残るかを精査します。逆に量も滞在もある経路は本物の主力です。
この見分けを誤ると、損失は 2 つの方向で起きます。ひとつは 広告投資 で、bot で水増しされた経路を「効いているチャネル」と判断し、人間も売上もない経路に予算を寄せてしまう(逆に地味でも売上を生む経路を過小評価する)。もうひとつは SEO 対策 で、SEO ツールのクローラーなどで特定ページの流入が多く見えると、成果の出ないページやキーワードに手間をかけ続ける、あるいは伸びる芽を「効果なし」と切り捨ててしまいます。
私自身、自社サイトの運用でこの罠にはまりかけました。ある動画サイト経由の流入が、立ち上げから数日で「1 日あたりで最も多いチャネル」に見えたのです。ところが調べると、その経路のセッションはすべて滞在がほぼゼロ。動画の説明欄に貼った URL を読み取るクローラーが機械的に開いていただけで、人間は 1 人も訪れていませんでした。滞在時間を横並びで比べていなければ、そのまま「最良チャネル」と信じ続けていた はずです。
もっとも、この見分けを安定して回し続けるのは簡単ではありません。滞在の短さだけを根拠にすると、たまたますぐ離脱した人間の直帰まで bot と誤判定します。逆に UA を偽装し、人間らしいアクセス間隔を装う高度な bot は、単一のシグナルでは見抜けません。結局は UA・IP・ふるまいを横断したセッション単位の分析を、bot 側の進化に合わせて継続的に更新し続ける必要があり、ここが自前運用で最も負荷の高いところです。
技術3:GTM・GA4のフィルタ設定とサーバーログでの確認
見分けた bot を実際に除外・分離するには、GTM / GA4 のフィルタとサーバーログを使い分けます。
GA4 のデータフィルタ(内部トラフィック・デベロッパー)
GA4 には「内部トラフィック」「デベロッパートラフィック」を除外する データフィルタ があります。内部トラフィックは IP ベースで定義し、traffic_type パラメータで識別して除外します。注意点として、新規に作ったデータフィルタは初期状態が 「テスト」 で、テスト状態では実データから除外されません。除外を効かせるには 「有効」 に切り替える必要があります。また、GA4 のフィルタは適用後のデータにのみ効き、過去データを遡って除外しません。
referral exclusion(参照元除外)との違い
bot 除外と混同しやすいのが 参照元除外(referral exclusion) です。これは Stripe や決済代行など外部ドメイン経由の遷移で「自サイトが新しい参照元として再計測される」のを防ぐ設定で、GA4 では「除外する参照のリスト」として定義します。あくまで 正規ユーザーのセッションの参照元を整える ものであり、bot トラフィックそのものを除外する機能ではありません。「動画サイト経由の bot が邪魔だから referral exclusion に入れる」というのは誤用で、その経路の人間の流入まで Direct に押し込んでしまいます。bot は referral exclusion ではなく、ふるまい・IP ベースの除外で対処するのが筋です。
GTM での配信制御とサーバーログ
GTM では、特定 IP やプレビュー環境でタグを配信しないトリガー条件を組めますが、UA 偽装する bot を GTM のクライアントサイドで完全に弾くのは困難です。最終的に 最も確実なのはサーバーログ(または CDN / WAF のログ)での確認 です。クライアントサイドの計測(GA4 / GTM)は JavaScript を実行しない bot を取りこぼしますが、サーバーログは全リクエストを記録します。ログで以下を見れば、クライアント計測で見えない bot まで把握できます。
- UA 別のリクエスト数と、
bot/crawlerを含む UA の比率 - アクセス元 IP の ASN 分布(データセンター IP の比率)
- 同一 IP・同一パスへの等間隔リクエスト(タイムスタンプの規則性)
サーバーログを集計基盤に取り込み、UA 別・IP 別に ASN 分布やアクセス間隔の傾向を見れば、クライアント計測で取りこぼした bot の当たりはつけられます。ただしこれはあくまで「傾向を掴む」段階で、高度な bot の確度の高い判別には、シグナルを横断したセッション単位の評価と、bot 側の変化に追従する継続的な見直しが要ります。単発のログ集計で線を引いて終わり、にはなりにくい領域です。
botを除いて初めて、売上で投資判断できる
bot 混入の怖さは、流入の数字だけを見ていると気づけないことです。同じ落とし穴は、ほかの指標にもあります。流入元が分からず Direct にまとまる現象や、最後の広告だけに成果を寄せる偏りも、根は同じ「見えている一部だけで判断してしまう」問題です。
- 流入元が分からず Direct に入る仕組みは GA4「Direct/(none)」が増える5つの原因と対処順2026
- 広告の評価を歪める偏りは 広告予算の判断を歪める『ラストクリックの罠』
- 数字が欠ける前提での読み方は Search Consoleのクリック数が合わない本当の理由
だからこそ、流入の数で判断を止めず、最後は売上で見る 視点が要ります。チャネルごとに「そのアクセスがいくらの売上を生んだか」まで一続きで見れば、滞在 0 秒で売上もない経路が「効いている」と誤認しにくくなります。考え方は RPSとは|広告チャネル比較の指標・計算式・GA4での出し方2026 で整理しています。
私たちが作っている RevenueScope は、ここまで見てきた「自前では負荷が高い」判別を継続的に肩代わりすることを狙っています。収集時にユーザーエージェントとサーバー情報(クラウド ASN)で既知の bot を判定して集計から除外し(自社サイトでは約 4 分の 1 が bot 判定)、さらに滞在ゼロ・単一ページといった振る舞いからも自動で見分けて除外します。判定基準は bot 側の変化に合わせて継続的に見直すため、片手間の自前運用では取りこぼす bot まで拾いにいきます。残った人間のアクセスをチャネルごとに売上で評価することで、bot が水増しした「見かけの当たりチャネル」に予算を吸われずに済みます。
よくある質問
Q. GA4 を使っていれば bot は自動で除外されますか。
既知の bot とスパイダーは自動で除外されます。ただし対象は IAB が管理するブラックリスト(既知 bot の一覧)に載った bot だけで、ブラックリストにない bot や UA を偽装する bot は素通りします。除外された量も確認できないため、自動除外だけに頼るのは危険です。
Q. bot の流入かどうかは、どこを見れば分かりますか。
UA・IP・ふるまいの 3 点を組み合わせます。UA に bot 名が含まれるか、アクセス元 IP がデータセンター(クラウド ASN)か、平均滞在が極端に短く単一 PV・等間隔アクセスか。ただし単独のシグナルでは誤判定しやすく、UA を偽装する高度な bot ほど見分けは難しいため、複数の角度を重ね、bot 側の変化に合わせて継続的に見直す前提が要ります。Googlebot を名乗るアクセスについては、Google が正規かどうかの検証手順を公式に案内しています。
Q. 動画サイト経由の bot は referral exclusion で除外すればいいですか。
いいえ。参照元除外(referral exclusion)は正規ユーザーのセッションの参照元を整える設定で、bot 除外の機能ではありません。referral exclusion に入れると、その経路の人間の流入まで Direct に押し込んでしまいます。bot はふるまい・IP ベースの除外で対処します。
まとめ
bot は今やインターネット全体のアクセスの 53% を占め、ついに人間を上回りました。その多くは参照元のある流入として解析データに紛れ込みます。技術的な要点を 3 つに整理します。
- GA4 の自動除外は「既知 bot のリストマッチ(ブラックリスト方式)」であり「ふるまい検出」ではない。IAB のブラックリスト(既知 bot の一覧)にない bot や UA 偽装は素通りし、除外量も不可視
- 見分けは UA・IP・ふるまいを複数重ねる必要がある。単独のシグナルでは人間の直帰と誤判定しやすく、UA を偽装する高度な bot ほど判別は難しい。しかも bot 側は変化し続けるため、一度線を引いて終わりにはできず継続的な見直しが要る
- 除外は GA4 データフィルタとサーバーログを使い分ける。referral exclusion は bot 除外ではない。JS を実行しない bot はサーバーログでしか見えない
流入量と平均滞在時間を組み合わせて bot を見分け、最後は売上まで一続きで見る。これで、計測の落とし穴に予算を吸われずに済みます。
参考文献
- Thales 「2026 Bad Bot Report」 2025 年 [1]
- Google アナリティクス ヘルプ 「既知の bot トラフィックの除外」 [2]
- Google 検索セントラル 「Googlebot などの Google クローラーを確認する」 [3]