自己紹介から
初投稿になります!
データ分析コンサルティング業務を長く担当し、現在では生体デバイスの会社においてデータサイエンティストとして業務に携わっています。主としてPythonを使った分析・コーディングを行っています。職場の調べ物でかなりQiitaにお世話になることが多く、私も自分の知見をフィードバックできればという思いから、Qiitaに参戦することにしました。
概要
ICLR2018においてPosterで登場したDAGMMという異常検出アルゴリズムを試しに実装してみましたので報告してみます(Python, TensorFlowを利用する前提)githubにて公開してみたのですが、Google検索にも引っかからず、かなり寂しい思いをしたので、思い切って Qiita 初投稿で宣伝してみます。
- 対象文献 : Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection [Bo Zong et al (2018)]
- 実装したコード : https://github.com/tnakae/DAGMM/
あまり TensorFlow 経験もそこまでないのですが、練習課題と思って実装してみました。使いづらいところがあれば、Issue 追加していただければ幸いです。日本語の説明も書きましたので、簡易に始める場合はそちらを参照してください。
恐らくこの手のモデルが有効に働くのは、アカデミアの課題よりも、産業界(特にセンサー系のデータが集まる業界、IoT系など)での有効活用が考えられるかなと思っており、その手の方々の業務に参考になれば幸いです。
異常検知手法のおさらい
異常値検出手法には様々な前提がありますが、対象データが多次元の数値であり、時系列性を考慮しない手法としては、Deepの文脈を外すと次の2つのアルゴリズムが有力かなとみています。
-
One-Class SVM
- 外れ値検出の目的で使われる特殊なSVM。
- 特に、カーネル関数がRBFなどの非線形カーネルを使う場合に強力な異常値検出が可能。
- Pythonの場合sklearn.svm.OneClassSVMなどの実装が有力です。
- 但し、カーネル計算が必要となるため、データ数の2乗のオーダーでの
計算時間が必要となり、データが多い場合には非常に不利になります。
-
混合正規分布モデル (Gaussian Mixture Model ; GMM)
- 多次元の正規分布の複数個(有限個)の重ね合わせで表現すると考える統計モデル
- 連続値で性質のよく似たセンサー(複数の場所に設置した温度センサーなど)のデータ
でよく整合します。 - データの性質上、データは正規分布の重ね合わせで表現できることが前提。
(そうでないデータに対しても意外と無理くり現場で使ったりする) - Python では sklearn.mixture.GaussianMixture などの実装があります。
Rでは、mclust というかなり強力な実装があります。
これらの手法の説明は井出剛さんの書籍「機械学習による異常検知」あたりに詳しく記載されています。その他、LOF (Locally Outlier Filter) や Isolation Forest なども利用されることがあります。それぞれの手法をsklearn で適用した結果などの図などもあります。
これ以外にDeep系のモデルでやる発想としては、AutoEncoderを使う発想があります。これは、AutoEncoderで元のベクトルに戻らない戻らなさ加減を異常度として表現するものです。ただしこの場合、AutoEncoderの表現能力が高ければいくらでももとに戻ってしまうため、この点の表現力との裏返しの関係になってしまいます。私も以前業務で使えないか実験したことがありますが、なかなか難しいところでした。同じ発想で、GANを使う手法も最近では多々あります。
DAGMMについて
DAGMM とは Deep AutoEncoder Gaussian Mixture Model の略称です。このモデルも、多次元データに対して異常値検出を行う手法で、これまで割と使われてきた異常値検出の定番である混合正規分布モデル(GMM)と、AutoEncoderをうまくつなぎ合わせた発想のモデルです。
論文から図を拝借して、このモデルの概要を説明してみます。
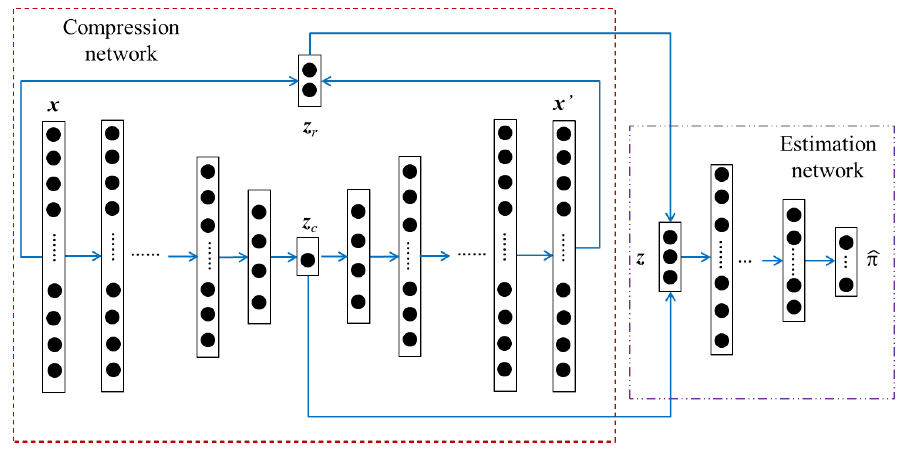
モデルの構成は次の3つの部分からなります。
- 圧縮モデル (Compression Network) : AutoEncoder の圧縮表現に誤差(2種類)をconcatしたものを生成するモデル
- クラス推定モデル (Estimation Network) : GMMの混合正規分布のどのクラスに入るかを予測するモデル
- 混合正規モデル (GMM) <図には表現されていない>
詳細は論文そのものに譲るとして、このDAGMMのユニークなところが2点あります。
-
圧縮モデル (Compression model) で異常検出に圧縮した表現のみを使わないところ
通常の発想では、AutoEncoderの圧縮表現だけを使うところですが、これだと、AutoEncoderでどこまで圧縮すればいいのかの加減が分からなくなってしまいます。DAGMMでは、低次元表現($z_c$)に加えてここに誤差ベクトル($z_r$)を加える(concatする)ことで、同じ表現となった場合でも、うまく元に戻ったのかどうかをそのデータの特徴として説明に用いることができるというところです。 -
GMMのクラス推定で Softmax のモデルを1つつけたところ
GMMの通常の実装では、対象データがどの正規分布に属するかの所属率を、EMなどのアルゴリズムを用いるところですが、GMMの手前にどのクラスに含まれるのかを推定するモデル(Estimation Network) を用意しています。これにより、GMMのパラメータ推定でEnd-To-Endの学習を可能にしています。この発想によりモデルをそれぞれのパーツで分解することなく、TensorFlowなどのフレームワークを用いて一斉に学習することを可能にしています
(ここは変分モデルの発想と近いところで、論文でも同様の指摘があり、実際に変分モデルと比較した結果も論文で言及されています)
DAGMMの利用
元論文の著者は "TensorFlowで実装した!" と宣言しているのですが、コードが公開されていません(私が見落としているだけかもしれない。ご存知の方がおられましたら教えてください...)
試験的に実装したコードを https://github.com/tnakae/DAGMM/ に公開しました。なお詳細は github の README_ja.md をご覧ください。動作例を Jupyter Notebook でも作った(Example_DAGMM_ja.ipynb)ので、こちらも参照してください。Python3環境で TensorFlow, Numpy, sklearn があれば動作するので、Anaconda に TensorFlow さえ入っていれば動作します。
READMEにも記述しましたが、次のように比較的簡単に利用可能です:
import tensorflow as tf
from dagmm import DAGMM
# 初期化
model = DAGMM(
comp_hiddens=[32,16,2], comp_activation=tf.nn.tanh,
est_hiddens=[16.8], est_activation=tf.nn.tanh,
est_dropout_ratio=0.25
)
# 学習データを当てはめる
model.fit(x_train)
# エネルギーの算出
# (エネルギーが高いほど異常)
energy = model.predict(x_test)
# 学習済みモデルをディレクトリに保存する
model.save("./fitted_model")
# 学習済みモデルをディレクトリから読み込む
model.restore("./fitted_model")
利用するには、"Download Zip" のリンク先からZIPファイルを手元にダウンロードし、dagmmディレクトリを動作させたい.pyファイル、ないし.ipynbファイルと同階層にコピーして import してください。
(6/10注)いくつか数値実験を行い、実装を手直ししました。またKDDCup99データに対する検証Notebookを動かし、確かにかなり高い精度での異常値検知ができることを確認しました。ただ、データの前処理・構築するネットワークの構造にかなり影響を受けるようであり、この点の調整が必須に見えました。
補足
DAGMMは比較的簡単な構造なので、Deep系の実装に慣れた人であれば割と簡単に実装できると思います。Google で "github DAGMM" と検索すると多数出てくるのは多分そういうことでしょう。異常検知でデータが大量すぎる、次元が多すぎて困っているなど壁にぶつかっている人は、ぜひ論文の一読をお勧めします。
なおこの事情を反映して github上でも多数の実装が上がっています。
- pytorch を利用した実装
- tensorflow を利用し、入力として画像を利用した例(Compression Model にCNNを採用)
なかなか時間が取れないので、文章もなかなか書けないのですが.. 今後時間があるときに、実装上気づいた点などの補足記事など書く予定です。