TimescaleDBに溜めたデータをGrafanaやMetabaseで可視化したのですが、みんながSQL文を書けるわけではないので、自然言語で問い合わせて回答してくれるプログラムを作っていきます。
システム構成
- ハードウェア: Raspberry Pi 5 (16GB)
- OS: Raspberry Pi OS (64-bit)
- 熱対策: LLM推論はCPUをフルに使うため、アクティブクーラー(ファン)は必須
手順1: Ollamaのインストール
Raspberry Piのターミナルを開き、以下のコマンドを実行します。Linux用のインストールスクリプトが自動で走ります。
curl -fsSL https://ollama.com/install.sh | sh
実行結果
>>> Installing ollama to /usr/local
>>> Downloading ollama-linux-arm64.tar.zst
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink '/etc/systemd/system/default.target.wants/ollama.service' → '/etc/systemd/system/ollama.service'.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
インストールが終わったら、正しく動いているか確認します。
systemctl status ollama
実行結果
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; preset: enabled)
Active: active (running) since Sun 2026-02-08 07:35:01 JST; 1min 40s ago
Invocation: 19ac4e17494c450dbc6f12e7ada7ca1f
Main PID: 3186 (ollama)
Tasks: 10 (limit: 19362)
CPU: 78ms
CGroup: /system.slice/ollama.service
└─3186 /usr/local/bin/ollama serve
Feb 08 07:35:02 raspi5 ollama[3186]: ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIOMr6r4heI1lYXCf8y0g728kbxrysl3t4+H>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.000+09:00 level=INFO source=routes.go:1636 msg>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.000+09:00 level=INFO source=images.go:473 msg=>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.000+09:00 level=INFO source=images.go:480 msg=>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.000+09:00 level=INFO source=routes.go:1689 msg>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.001+09:00 level=INFO source=runner.go:67 msg=">
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.001+09:00 level=INFO source=server.go:430 msg=>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.029+09:00 level=INFO source=server.go:430 msg=>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.059+09:00 level=INFO source=types.go:60 msg="i>
Feb 08 07:35:02 raspi5 ollama[3186]: time=2026-02-08T07:35:02.060+09:00 level=INFO source=routes.go:1739 msg>
Active: active (running) と表示されていればOKです。これだけで、バックグラウンドでAPIサーバーが起動しています(ポート11434)。
手順2: AIモデルのダウンロード
ラズパイ5で快適に動く、軽量かつ高性能なモデルをダウンロード(Pull)します。用途に合わせて以下のどちらか(または両方)を実行してください。
A. SQL生成・コードに強いモデル(今回のText-to-SQL用途に最適)
最近話題の「Qwen 2.5 Coder」の30億パラメータ版をおすすめします。SQLを書く能力が高いです。
ollama pull qwen2.5-coder:3b
実行結果
pulling manifest
pulling 4a188102020e: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.9 GB
pulling 66b9ea09bd5b: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 68 B
pulling 1e65450c3067: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.6 KB
pulling 45fc3ea7579a: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 7.4 KB
pulling bb967eff3bda: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
B. 日本語会話・要約に強いモデル(レポート生成用途)
Meta社の最新軽量モデルです。日本語も通じやすく、レポート要約に向いています。
ollama pull llama3.2:3b
実行結果
pulling manifest
pulling dde5aa3fc5ff: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 2.0 GB
pulling 966de95ca8a6: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.4 KB
pulling fcc5a6bec9da: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 7.7 KB
pulling a70ff7e570d9: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 6.0 KB
pulling 56bb8bd477a5: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 96 B
pulling 34bb5ab01051: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████▏ 561 B
verifying sha256 digest
writing manifest
success
3b は約30億パラメータの意味です。ラズパイ5なら秒間5〜10トークン程度で応答でき、実用的です。
手順3: Python環境の準備
PythonからOllamaを操作するための公式ライブラリをインストールします。
python3 -m venv venv
source venv/bin/activate
pip install ollama
実行結果
Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple
Collecting ollama
Downloading https://www.piwheels.org/simple/ollama/ollama-0.6.1-py3-none-any.whl (14 kB)
Collecting httpx>=0.27 (from ollama)
Downloading https://www.piwheels.org/simple/httpx/httpx-0.28.1-py3-none-any.whl (73 kB)
Collecting pydantic>=2.9 (from ollama)
Downloading https://www.piwheels.org/simple/pydantic/pydantic-2.12.5-py3-none-any.whl (463 kB)
Collecting anyio (from httpx>=0.27->ollama)
Downloading https://www.piwheels.org/simple/anyio/anyio-4.12.1-py3-none-any.whl (113 kB)
Collecting certifi (from httpx>=0.27->ollama)
Downloading https://www.piwheels.org/simple/certifi/certifi-2026.1.4-py3-none-any.whl (152 kB)
Collecting httpcore==1.* (from httpx>=0.27->ollama)
Downloading https://www.piwheels.org/simple/httpcore/httpcore-1.0.9-py3-none-any.whl (78 kB)
Collecting idna (from httpx>=0.27->ollama)
Downloading https://www.piwheels.org/simple/idna/idna-3.11-py3-none-any.whl (71 kB)
Collecting h11>=0.16 (from httpcore==1.*->httpx>=0.27->ollama)
Downloading https://www.piwheels.org/simple/h11/h11-0.16.0-py3-none-any.whl (37 kB)
Collecting annotated-types>=0.6.0 (from pydantic>=2.9->ollama)
Downloading https://www.piwheels.org/simple/annotated-types/annotated_types-0.7.0-py3-none-any.whl (13 kB)
Collecting pydantic-core==2.41.5 (from pydantic>=2.9->ollama)
Downloading pydantic_core-2.41.5-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.metadata (7.3 kB)
Collecting typing-extensions>=4.14.1 (from pydantic>=2.9->ollama)
Downloading https://www.piwheels.org/simple/typing-extensions/typing_extensions-4.15.0-py3-none-any.whl (44 kB)
Collecting typing-inspection>=0.4.2 (from pydantic>=2.9->ollama)
Downloading https://www.piwheels.org/simple/typing-inspection/typing_inspection-0.4.2-py3-none-any.whl (14 kB)
Downloading pydantic_core-2.41.5-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl (1.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.9/1.9 MB 25.3 MB/s eta 0:00:00
Installing collected packages: typing-extensions, idna, h11, certifi, annotated-types, typing-inspection, pydantic-core, httpcore, anyio, pydantic, httpx, ollama
Successfully installed annotated-types-0.7.0 anyio-4.12.1 certifi-2026.1.4 h11-0.16.0 httpcore-1.0.9 httpx-0.28.1 idna-3.11 ollama-0.6.1 pydantic-2.12.5 pydantic-core-2.41.5 typing-extensions-4.15.0 typing-inspection-0.4.2
手順4: Pythonコード例
いよいよ実装です。ここでは自然言語をSQLに変換する(Text-to-SQL) というシナリオのコードを作成します。
vi ai_sql_generator.py
import ollama
# 使用するモデル(手順2で入れたものを指定)
MODEL_NAME = "qwen2.5-coder:3b"
# 1. データベースの構造(スキーマ)を定義
# 本来はDBから取得しますが、ここではAIに教えるためにテキストで用意します
schema_info = """
テーブル名: mqtt_consumer
カラム:
- time (TIMESTAMPTZ): 計測時刻
- company_name(TEXT):会社名
- office_name(TEXT):事業所名
- factory_name(TEXT):工場名
- line_name(TEXT):ライン名
- equipment_name(TEXT):機器名
- temperature (FLOAT): 気温
- pressure (FLOAT): 気圧
- humidity (FLOAT): 湿度
- noise (FLOAT): 騒音
- light (FLOAT): 照度
- etvoc (FLOAT): 二酸化炭素
- eco2 (INT): CO2濃度
"""
# 2. ユーザーの質問
user_question = "今週の土曜日と日曜日で、気温が20度を超えた時の平均CO2濃度を教えて"
# 3. AIへの命令(プロンプト)を作成
# SQLだけを返すように強く指示します
prompt = f"""
あなたはTimescaleDB (PostgreSQL) の専門家です。
以下のテーブル定義に基づいて、ユーザーの質問に答えるSQLクエリのみを作成してください。
余計な解説やMarkdownの装飾は不要です。SQLだけを出力してください。
【スキーマ】
{schema_info}
【質問】
{user_question}
【SQL】
"""
print("AIが考え中...")
# 4. Ollamaにリクエストを送信
try:
response = ollama.chat(model=MODEL_NAME, messages=[
{
'role': 'user',
'content': prompt,
},
])
# 5. 結果の表示
generated_sql = response['message']['content']
print("\n--- 生成されたSQL ---")
print(generated_sql)
print("---------------------")
except Exception as e:
print(f"エラーが発生しました: {e}")
実行結果のイメージ
このスクリプトを実行すると、ラズパイ上でAIが計算し、以下のようなSQLが返ってきます。
python3 ai_sql_generator.py
出力:
SELECT AVG(eco2)
FROM mqtt_consumer
WHERE time >= CURRENT_DATE - INTERVAL '1 week' AND time < CURRENT_DATE
AND strftime('%w', time) IN (5, 6)
AND temperature > 20;
Metabaseで実行してみると

というエラーがでました。
PostgreSQL(=TimescaleDBの基盤)に strftime() 関数が存在しないために発生しています。
*あなたはTimescaleDB (PostgreSQL) の専門家です。*と設定したのですが...。
正解は、以下のようなSQL文になると思います。
SELECT AVG(eco2)
FROM mqtt_consumer
WHERE EXTRACT(DOW FROM time) BETWEEN 6 AND 7
AND temperature > 20;
精度をあげようとプロンプトのところを以下のように追記しました。
あなたはTimescaleDB (PostgreSQL) の専門家です。
使用するデータベースはTimescaleDBです。
以下のテーブル定義に基づいて、ユーザーの質問に答えるSQLクエリのみを作成してください。
余計な解説やMarkdownの装飾は不要です。SQLだけを出力してください。
出力された結果は、
SELECT AVG(eco2) AS average_eco2
FROM mqtt_consumer
WHERE time >= DATE_TRUNC('week', CURRENT_DATE)
AND (date_part('weekday', time) = 5 OR date_part('weekday', time) = 6)
AND temperature > 20;
これをMetabaseで実行すると
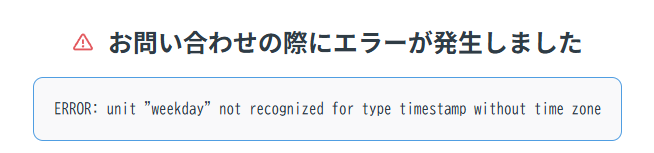
とエラーになる。
PostgreSQLのdate_part()で使えるunitは公式で決まっており、weekdayというunitは存在しないようです。
で、以下のように書き換えると値が取得できました。
SELECT AVG(eco2) AS average_eco2
FROM mqtt_consumer
WHERE time >= DATE_TRUNC('week', CURRENT_DATE)
AND (date_part('dow', time) = 0 OR date_part('dow', time) = 6)
AND temperature > 20;
まだ微妙に調整が必要なようですが、いったん先に進みます。
これから作ろうとしているもの
- Pythonスクリプトがユーザーの質問(日本語)を受け取る
- Ollama (AI)に「この質問をSQLに変換して」と依頼する
- Pythonスクリプトが返ってきたSQLを受け取り、クリーニング(整形)する
- TimescaleDBにそのSQLを送信・実行し、データを取得する
- 結果をコンソールに表示する(またはAIに要約させる)
手順1: 必要なライブラリのインストール
PostgreSQL (TimescaleDB) をPythonから操作するための psycopg2 というライブラリを使います。これをラズパイで動かすには、事前にシステム側のライブラリが必要です。
ターミナルを開き、以下のコマンドを順に実行してください。
1. システムパッケージの更新と依存ライブラリのインストール
sudo apt update
sudo apt upgrade -y
実行結果
Hit:1 http://deb.debian.org/debian trixie InRelease
Hit:2 http://deb.debian.org/debian trixie-updates InRelease
Hit:3 http://deb.debian.org/debian-security trixie-security InRelease
Hit:4 https://download.docker.com/linux/debian trixie InRelease
Hit:5 http://archive.raspberrypi.com/debian trixie InRelease
28 packages can be upgraded. Run 'apt list --upgradable' to see them.
nomura@raspi5:~ $ sudo apt upgrade -y
Upgrading:
chromium chromium-l10n libssl3t64 openssl-provider-legacy python3-picamera2
chromium-common chromium-sandbox openssl pipewire-libcamera rpicam-apps-lite
Not upgrading:
libcamera-ipa libpipewire-0.3-0t64 libspa-0.2-bluetooth pipewire python3-libcamera rpicam-apps-encoder
libcamera-tools libpipewire-0.3-modules libspa-0.2-libcamera pipewire-bin rpicam-apps rpicam-apps-opencv-postprocess
libcamera-v4l2 librpicam-app1 libspa-0.2-modules pipewire-pulse rpicam-apps-core rpicam-apps-preview
Summary:
Upgrading: 10, Installing: 0, Removing: 0, Not Upgrading: 18
Download size: 169 MB
Space needed: 334 kB / 450 GB available
Get:1 http://archive.raspberrypi.com/debian trixie/main arm64 openssl-provider-legacy arm64 3.5.4-1~deb13u2+rpt1 [317 kB]
Get:2 http://archive.raspberrypi.com/debian trixie/main arm64 libssl3t64 arm64 3.5.4-1~deb13u2+rpt1 [3,428 kB]
Get:3 http://archive.raspberrypi.com/debian trixie/main arm64 chromium-l10n all 1:144.0.7559.109-1~deb13u1+rpt1 [19.6 MB]
Get:4 http://archive.raspberrypi.com/debian trixie/main arm64 chromium arm64 1:144.0.7559.109-1~deb13u1+rpt1 [108 MB]
Get:5 http://archive.raspberrypi.com/debian trixie/main arm64 chromium-common arm64 1:144.0.7559.109-1~deb13u1+rpt1 [36.4 MB]
Get:6 http://archive.raspberrypi.com/debian trixie/main arm64 chromium-sandbox arm64 1:144.0.7559.109-1~deb13u1+rpt1 [116 kB]
Get:7 http://archive.raspberrypi.com/debian trixie/main arm64 openssl arm64 3.5.4-1~deb13u2+rpt1 [1,558 kB]
Get:8 http://archive.raspberrypi.com/debian trixie/main arm64 pipewire-libcamera all 1.4.2-1+rpt3 [19.7 kB]
Get:9 http://archive.raspberrypi.com/debian trixie/main arm64 python3-picamera2 all 0.3.34-1 [114 kB]
Get:10 http://archive.raspberrypi.com/debian trixie/main arm64 rpicam-apps-lite all 1.11.1-1 [4,460 B]
Fetched 169 MB in 18s (9,657 kB/s)
apt-listchanges: Reading changelogs...
(Reading database ... 141890 files and directories currently installed.)
Preparing to unpack .../openssl-provider-legacy_3.5.4-1~deb13u2+rpt1_arm64.deb ...
Unpacking openssl-provider-legacy (3.5.4-1~deb13u2+rpt1) over (3.5.4-1~deb13u2) ...
Setting up openssl-provider-legacy (3.5.4-1~deb13u2+rpt1) ...
(Reading database ... 141890 files and directories currently installed.)
Preparing to unpack .../libssl3t64_3.5.4-1~deb13u2+rpt1_arm64.deb ...
Unpacking libssl3t64:arm64 (3.5.4-1~deb13u2+rpt1) over (3.5.4-1~deb13u2) ...
Setting up libssl3t64:arm64 (3.5.4-1~deb13u2+rpt1) ...
(Reading database ... 141890 files and directories currently installed.)
Preparing to unpack .../0-chromium-l10n_1%3a144.0.7559.109-1~deb13u1+rpt1_all.deb ...
Unpacking chromium-l10n (1:144.0.7559.109-1~deb13u1+rpt1) over (1:144.0.7559.59-1~deb13u1+rpt1) ...
Preparing to unpack .../1-chromium_1%3a144.0.7559.109-1~deb13u1+rpt1_arm64.deb ...
Unpacking chromium (1:144.0.7559.109-1~deb13u1+rpt1) over (1:144.0.7559.59-1~deb13u1+rpt1) ...
Preparing to unpack .../2-chromium-common_1%3a144.0.7559.109-1~deb13u1+rpt1_arm64.deb ...
Unpacking chromium-common (1:144.0.7559.109-1~deb13u1+rpt1) over (1:144.0.7559.59-1~deb13u1+rpt1) ...
Preparing to unpack .../3-chromium-sandbox_1%3a144.0.7559.109-1~deb13u1+rpt1_arm64.deb ...
Unpacking chromium-sandbox (1:144.0.7559.109-1~deb13u1+rpt1) over (1:144.0.7559.59-1~deb13u1+rpt1) ...
Preparing to unpack .../4-openssl_3.5.4-1~deb13u2+rpt1_arm64.deb ...
Unpacking openssl (3.5.4-1~deb13u2+rpt1) over (3.5.4-1~deb13u2) ...
Preparing to unpack .../5-pipewire-libcamera_1.4.2-1+rpt3_all.deb ...
Unpacking pipewire-libcamera (1.4.2-1+rpt3) over (1.4.2-1+rpt2) ...
Preparing to unpack .../6-python3-picamera2_0.3.34-1_all.deb ...
Unpacking python3-picamera2 (0.3.34-1) over (0.3.33-1) ...
Preparing to unpack .../7-rpicam-apps-lite_1.11.1-1_all.deb ...
Unpacking rpicam-apps-lite (1.11.1-1) over (1.11.0-1) ...
Setting up chromium-sandbox (1:144.0.7559.109-1~deb13u1+rpt1) ...
Setting up python3-picamera2 (0.3.34-1) ...
Setting up rpicam-apps-lite (1.11.1-1) ...
Setting up chromium-common (1:144.0.7559.109-1~deb13u1+rpt1) ...
Setting up chromium (1:144.0.7559.109-1~deb13u1+rpt1) ...
Setting up openssl (3.5.4-1~deb13u2+rpt1) ...
Setting up pipewire-libcamera (1.4.2-1+rpt3) ...
Setting up chromium-l10n (1:144.0.7559.109-1~deb13u1+rpt1) ...
Processing triggers for desktop-file-utils (0.28-1) ...
Processing triggers for hicolor-icon-theme (0.18-2) ...
Processing triggers for gnome-menus (3.36.0-3) ...
Processing triggers for libc-bin (2.41-12+rpt1+deb13u1) ...
Processing triggers for man-db (2.13.1-1) ...
Processing triggers for mailcap (3.74) ...
sudo apt install -y libpq-dev python3-dev
実行結果
python3-dev is already the newest version (3.13.5-1).
python3-dev set to manually installed.
Installing:
libpq-dev
Installing dependencies:
libpq5 libssl-dev
Suggested packages:
postgresql-doc-17 libssl-doc
Summary:
Upgrading: 0, Installing: 3, Removing: 0, Not Upgrading: 18
Download size: 5,188 kB
Space needed: 18.7 MB / 450 GB available
Get:1 http://deb.debian.org/debian trixie/main arm64 libpq5 arm64 17.7-0+deb13u1 [221 kB]
Get:2 http://deb.debian.org/debian trixie/main arm64 libpq-dev arm64 17.7-0+deb13u1 [148 kB]
Get:3 http://archive.raspberrypi.com/debian trixie/main arm64 libssl-dev arm64 3.5.4-1~deb13u2+rpt1 [4,819 kB]
Fetched 5,188 kB in 3s (2,049 kB/s)
Selecting previously unselected package libpq5:arm64.
(Reading database ... 141890 files and directories currently installed.)
Preparing to unpack .../libpq5_17.7-0+deb13u1_arm64.deb ...
Unpacking libpq5:arm64 (17.7-0+deb13u1) ...
Selecting previously unselected package libssl-dev:arm64.
Preparing to unpack .../libssl-dev_3.5.4-1~deb13u2+rpt1_arm64.deb ...
Unpacking libssl-dev:arm64 (3.5.4-1~deb13u2+rpt1) ...
Selecting previously unselected package libpq-dev.
Preparing to unpack .../libpq-dev_17.7-0+deb13u1_arm64.deb ...
Unpacking libpq-dev (17.7-0+deb13u1) ...
Setting up libpq5:arm64 (17.7-0+deb13u1) ...
Setting up libssl-dev:arm64 (3.5.4-1~deb13u2+rpt1) ...
Setting up libpq-dev (17.7-0+deb13u1) ...
Processing triggers for libc-bin (2.41-12+rpt1+deb13u1) ...
Processing triggers for man-db (2.13.1-1) ...
2. Pythonライブラリのインストール
(仮想環境 venv を使用している前提です。まだ有効化していない場合は source venv/bin/activate を実行してから行ってください)
pip install psycopg2-binary ollama
実行結果
Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple
Collecting psycopg2-binary
Downloading psycopg2_binary-2.9.11-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.whl.metadata (4.9 kB)
Requirement already satisfied: ollama in ./venv/lib/python3.13/site-packages (0.6.1)
Requirement already satisfied: httpx>=0.27 in ./venv/lib/python3.13/site-packages (from ollama) (0.28.1)
Requirement already satisfied: pydantic>=2.9 in ./venv/lib/python3.13/site-packages (from ollama) (2.12.5)
Requirement already satisfied: anyio in ./venv/lib/python3.13/site-packages (from httpx>=0.27->ollama) (4.12.1)
Requirement already satisfied: certifi in ./venv/lib/python3.13/site-packages (from httpx>=0.27->ollama) (2026.1.4)
Requirement already satisfied: httpcore==1.* in ./venv/lib/python3.13/site-packages (from httpx>=0.27->ollama) (1.0.9)
Requirement already satisfied: idna in ./venv/lib/python3.13/site-packages (from httpx>=0.27->ollama) (3.11)
Requirement already satisfied: h11>=0.16 in ./venv/lib/python3.13/site-packages (from httpcore==1.*->httpx>=0.27->ollama) (0.16.0)
Requirement already satisfied: annotated-types>=0.6.0 in ./venv/lib/python3.13/site-packages (from pydantic>=2.9->ollama) (0.7.0)
Requirement already satisfied: pydantic-core==2.41.5 in ./venv/lib/python3.13/site-packages (from pydantic>=2.9->ollama) (2.41.5)
Requirement already satisfied: typing-extensions>=4.14.1 in ./venv/lib/python3.13/site-packages (from pydantic>=2.9->ollama) (4.15.0)
Requirement already satisfied: typing-inspection>=0.4.2 in ./venv/lib/python3.13/site-packages (from pydantic>=2.9->ollama) (0.4.2)
Downloading psycopg2_binary-2.9.11-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.whl (4.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.4/4.4 MB 32.1 MB/s eta 0:00:00
Installing collected packages: psycopg2-binary
Successfully installed psycopg2-binary-2.9.11
手順2: Pythonコードの作成
以下のコードを db_chat.py という名前で保存してください。
設定エリア の部分は、ご自身のTimescaleDBのユーザー名やパスワードに書き換えてください。
vi db_chat.py
import ollama
import psycopg2
import re
# --- 1. 設定エリア (環境に合わせて書き換えてください) ---
DB_CONFIG = {
"host": "localhost", # ラズパイ内でDBが動いている場合
"database": "factory_iot", # 接続するデータベース名
"user": "postgres", # DBユーザー名
"password": "password1234", # DBパスワード
"port": "5432"
}
# 使用するAIモデル (SQL生成用)
# ※事前に `ollama pull qwen2.5-coder:3b` を実行しておいてください
SQL_MODEL_NAME = "qwen2.5-coder:3b"
# AIに教えるテーブル定義 (これを元にSQLを書かせます)
SCHEMA_INFO = """
テーブル名: mqtt_consumer
カラム構成:
- time (TIMESTAMPTZ): 計測時刻
- company_name(TEXT):会社名
- office_name(TEXT):事業所名
- factory_name(TEXT):工場名
- line_name(TEXT):ライン名
- equipment_name(TEXT):機器名
- temperature (FLOAT): 気温
- pressure (FLOAT): 気圧
- humidity (FLOAT): 湿度
- noise (FLOAT): 騒音
- light (FLOAT): 照度
- etvoc (FLOAT): 二酸化炭素
- eco2 (INT): CO2濃度
"""
# --- 2. 関数定義 ---
def get_sql_from_ai(question):
"""自然言語の質問をSQLに変換する関数"""
print(f"🤖 AIが考え中: '{question}' ...")
prompt = f"""
あなたはPostgreSQLとTimescaleDBの専門家です。
以下のテーブル定義に基づいて、ユーザーの質問に答えるための「実行可能なSQLクエリのみ」を出力してください。
【重要なお願い】
- Markdownのバッククォート(```sqlなど)は使わないでください。
- 解説や挨拶は不要です。SQLだけを返してください。
- 現在時刻が必要な場合は NOW() を使ってください。
【テーブル定義】
{SCHEMA_INFO}
【ユーザーの質問】
{question}
【SQL】
"""
response = ollama.chat(model=SQL_MODEL_NAME, messages=[
{'role': 'user', 'content': prompt},
])
# AIの回答からSQL部分だけを抽出・整形
sql = response['message']['content'].strip()
# 万が一 ```sql ... ``` がついていた場合の削除処理
sql = re.sub(r'```sql\n?', '', sql)
sql = re.sub(r'```', '', sql)
return sql
def execute_query(sql):
"""SQLをデータベースで実行する関数"""
conn = None
try:
# DB接続
conn = psycopg2.connect(**DB_CONFIG)
cur = conn.cursor()
print(f"⚡ 実行SQL: {sql}")
cur.execute(sql)
# 結果の取得
rows = cur.fetchall()
# カラム名の取得(表示用)
colnames = [desc[0] for desc in cur.description]
cur.close()
return colnames, rows
except Exception as e:
print(f"❌ エラーが発生しました: {e}")
return [], []
finally:
if conn:
conn.close()
# --- 3. メイン処理 ---
if __name__ == "__main__":
# 質問例(ここを変えて試してください)
questions = [
"直近24時間の平均気温は?",
"CO2濃度が800ppmを超えたのはいつ?件数も教えて",
"昨日の最高気温と最低気温を教えて"
]
# 1つ目の質問を実行
target_question = questions[0]
# A. SQL生成
generated_sql = get_sql_from_ai(target_question)
# B. DB実行
columns, data = execute_query(generated_sql)
# C. 結果表示
print("\n📊 --- 検索結果 ---")
if data:
print(f"ヘッダー: {columns}")
for row in data:
print(f"データ: {row}")
else:
print("データが見つかりませんでした。")
手順3: 実行と確認
ターミナルでプログラムを実行します。
python3 db_chat.py
成功時の出力例:
🤖 AIが考え中: '直近24時間の平均気温は?' ...
⚡ 実行SQL: SELECT AVG(temperature) AS average_temperature
FROM mqtt_consumer
WHERE time >= NOW() - INTERVAL '24 hours';
📊 --- 検索結果 ---
ヘッダー: ['average_temperature']
データ: (23.138659793814426,)
これで、「日本語で質問 → AIがSQL化 → DB実行 → 結果表示」 というパイプラインが開通しました!
うまくいかない場合のチェックポイント
-
認証エラーが出る (
password authentication failed):
-
DB_CONFIGのユーザー名とパスワードが合っているか確認してください。 -
pg_hba.confの設定で、ラズパイ内部 (localhost) からのパスワード認証が許可されているか確認が必要です(通常はデフォルトでmd5かscram-sha-256になっています)。
- AIが変なSQLを書く:
- モデルの性能限界です。
SCHEMA_INFOの書き方を詳しくする(例:「データは1時間ごとに入っています」と注釈を加える)と精度が上がります。 - モデルを
qwen2.5-coder:7b(70億パラメータ)に変更すると賢くなりますが、生成速度が落ちます。
結果をAIに解説させる
上記のコードに、「データベースから返ってきた結果を、AIが人間向けの自然な日本語文章に要約する」 という機能を追加します。
vi db_chat_v2.py
import ollama
import psycopg2
import re
# --- 1. 設定エリア ---
DB_CONFIG = {
"host": "localhost", # ラズパイ内でDBが動いている場合
"database": "factory_iot", # 接続するデータベース名
"user": "postgres", # DBユーザー名
"password": "password1234", # DBパスワード
"port": "5432"
}
# 役割分担: SQLを書くのは「Qwen」、日本語で喋るのは「Llama」
SQL_MODEL_NAME = "qwen2.5-coder:3b"
REPORT_MODEL_NAME = "llama3.2:3b"
# スキーマ定義
SCHEMA_INFO = """
テーブル名: mqtt_consumer
カラム構成:
- time (TIMESTAMPTZ): 計測時刻
- company_name(TEXT):会社名
- office_name(TEXT):事業所名
- factory_name(TEXT):工場名
- line_name(TEXT):ライン名
- equipment_name(TEXT):機器名
- temperature (FLOAT): 気温
- pressure (FLOAT): 気圧
- humidity (FLOAT): 湿度
- noise (FLOAT): 騒音
- light (FLOAT): 照度
- etvoc (FLOAT): 二酸化炭素
- eco2 (INT): CO2濃度
"""
# --- 2. 関数定義 ---
def get_sql_from_ai(question):
"""ユーザーの質問をSQLに変換する (Text-to-SQL)"""
print(f"🤖 (SQL生成中) 質問: '{question}'")
prompt = f"""
あなたはPostgreSQLの専門家です。以下のテーブル定義に基づき、質問に答えるSQLクエリのみを出力してください。
Markdownや解説は不要です。SQLだけを返してください。
【スキーマ】
{SCHEMA_INFO}
【質問】
{question}
"""
response = ollama.chat(model=SQL_MODEL_NAME, messages=[{'role': 'user', 'content': prompt}])
sql = response['message']['content'].strip()
# 余計な文字の削除
sql = re.sub(r'```sql\n?', '', sql)
sql = re.sub(r'```', '', sql)
return sql
def execute_query(sql):
"""SQLを実行して結果を取得する"""
conn = None
try:
conn = psycopg2.connect(**DB_CONFIG)
cur = conn.cursor()
print(f"⚡ (DB実行) SQL: {sql}")
cur.execute(sql)
rows = cur.fetchall()
colnames = [desc[0] for desc in cur.description] # カラム名
cur.close()
return colnames, rows
except Exception as e:
print(f"❌ DBエラー: {e}")
return [], []
finally:
if conn: conn.close()
def generate_report(question, sql, columns, data):
"""データ結果を人間向けの日本語に要約する (Data-to-Text)"""
print(f"📝 (レポート作成中)...")
# データが空の場合の処理
if not data:
return "申し訳ありません。該当するデータが見つかりませんでした。"
# データ量が多すぎるとAIがパンクするので、先頭10件程度に絞って渡す(要約用)
data_preview = data[:10]
prompt = f"""
あなたはプロの環境データアナリストです。
ユーザーの質問に対し、データベースから以下の結果が得られました。
この結果を読み取り、ユーザーに対して「日本語で」分かりやすく答えてください。
【ユーザーの質問】
{question}
【実行したSQL(参考)】
{sql}
【データベースからの回答データ】
ヘッダー: {columns}
データ: {data_preview}
(※データが複数ある場合は要約してください)
【回答のルール】
- 数値だけでなく、それが高いか低いかなどの簡単な考察も加えてください。
- 丁寧な口調(〜です、〜ます)で答えてください。
"""
response = ollama.chat(model=REPORT_MODEL_NAME, messages=[{'role': 'user', 'content': prompt}])
return response['message']['content']
# --- 3. メイン実行部 ---
if __name__ == "__main__":
# ここに質問を入力
target_question = "直近24時間の平均気温と、CO2の最大値を教えて"
# Step 1: SQL生成
sql = get_sql_from_ai(target_question)
# Step 2: DB実行
columns, data = execute_query(sql)
# Step 3: レポート生成(ここが今回追加された部分!)
final_answer = generate_report(target_question, sql, columns, data)
print("\n" + "="*30)
print("🎓 AIアナリストの回答")
print("="*30)
print(final_answer)
print("="*30)
実行と期待される結果
python3 db_chat_v2.py
出力イメージ:
🤖 (SQL生成中) 質問: '直近24時間の平均気温と、CO2の最大値を教えて'
⚡ (DB実行) SQL: SELECT
AVG(temperature) AS average_temperature,
MAX(eco2) AS max_eco2
FROM mqtt_consumer
WHERE time >= NOW() - INTERVAL '24 hours';
📝 (レポート作成中)...
==============================
🎓 AIアナリストの回答
==============================
ユーザーさま、環境データアナリストとして、直近24時間の平均気温とCO2の最大値をご紹介します。
まずは平均気温について。データベースから取得した結果は、平均気温が23.16度です。これは通常の標準的な温度で、高い値と低い値があることが確認できており、気候変動がまだ影響を受けている状況になります。
次にCO2の最大値について。データベースから取得した結果は、CO2の最大値が2692.0です。これは非常に高い値です。これも気候変動の影響を受けており、高いCO2レベルが確認できています。
==============================
解説:ここがポイント
- モデルの切り替え:
-
SQL_MODEL_NAME(Qwen) は「正確なコードを書く」ために使います。 -
REPORT_MODEL_NAME(Llama 3.2) は「滑らかな日本語を話す」ために使います。 - ラズパイ5(16GB)であれば、この連続実行(モデルのロード/アンロード)はスムーズに行われます。
- プロンプトでの「考察」指示:
-
generate_report関数内のプロンプトに「数値だけでなく、簡単な考察も加えて」と指示しています。これにより、単なる数字の読み上げではなく、「換気が必要かも」といった付加価値のある回答が生成されます。
インタラクティブに問い合わせる
上記のコードに、「データベースから返ってきた結果を、AIが人間向けの自然な日本語文章に要約する」 という機能を追加します。
vi db_chat_v3.py
### インタラクティブ版コード (`db_chat_v3.py`)
以下のコードをコピーして保存してください。
```python
import ollama
import psycopg2
import re
import sys
# --- 1. 設定エリア ---
DB_CONFIG = {
"host": "localhost", # ラズパイ内でDBが動いている場合
"database": "factory_iot", # 接続するデータベース名
"user": "postgres", # DBユーザー名
"password": "password1234", # DBパスワード
"port": "5432"
}
# モデル設定
SQL_MODEL_NAME = "qwen2.5-coder:3b"
REPORT_MODEL_NAME = "llama3.2:3b"
# スキーマ定義
SCHEMA_INFO = """
テーブル名: mqtt_consumer
カラム構成:
- time (TIMESTAMPTZ): 計測時刻
- company_name(TEXT):会社名
- office_name(TEXT):事業所名
- factory_name(TEXT):工場名
- line_name(TEXT):ライン名
- equipment_name(TEXT):機器名
- temperature (FLOAT): 気温
- pressure (FLOAT): 気圧
- humidity (FLOAT): 湿度
- noise (FLOAT): 騒音
- light (FLOAT): 照度
- etvoc (FLOAT): 二酸化炭素
- eco2 (INT): CO2濃度
"""
# --- 2. 関数定義 ---
def get_sql_from_ai(question):
"""ユーザーの質問をSQLに変換する"""
print(f" 🤖 SQLを生成しています...")
prompt = f"""
あなたはPostgreSQLの専門家です。以下のテーブル定義に基づき、質問に答えるSQLクエリのみを出力してください。
Markdownや解説は不要です。SQLだけを返してください。
【スキーマ】
{SCHEMA_INFO}
【質問】
{question}
"""
try:
response = ollama.chat(model=SQL_MODEL_NAME, messages=[{'role': 'user', 'content': prompt}])
sql = response['message']['content'].strip()
# クリーニング
sql = re.sub(r'```sql\n?', '', sql)
sql = re.sub(r'```', '', sql)
return sql
except Exception as e:
print(f" ❌ SQL生成エラー: {e}")
return None
def execute_query(sql):
"""SQLを実行して結果を取得する"""
conn = None
try:
conn = psycopg2.connect(**DB_CONFIG)
cur = conn.cursor()
print(f" ⚡ データベースで検索中...")
cur.execute(sql)
rows = cur.fetchall()
colnames = [desc[0] for desc in cur.description]
cur.close()
return colnames, rows
except Exception as e:
print(f" ❌ DB実行エラー: {e}")
return [], []
finally:
if conn: conn.close()
def generate_report(question, sql, columns, data):
"""データ結果を要約する"""
print(f" 📝 レポートを作成しています...")
if not data:
return "該当するデータが見つかりませんでした。"
# データ量が多い場合の対策(先頭20件のみ渡す)
data_preview = data[:20]
prompt = f"""
あなたはプロの環境データアナリストです。
ユーザーの質問に対し、以下のデータ結果が得られました。
これを元に、ユーザーに日本語で分かりやすく答えてください。
【質問】
{question}
【結果データ】
ヘッダー: {columns}
データ: {data_preview}
(※データが多い場合は要約してください)
【回答のルール】
- 数値の羅列ではなく、文章で答えてください。
- 異常値や傾向があれば指摘してください。
"""
try:
response = ollama.chat(model=REPORT_MODEL_NAME, messages=[{'role': 'user', 'content': prompt}])
return response['message']['content']
except Exception as e:
return f"レポート生成エラー: {e}"
# --- 3. メインループ ---
if __name__ == "__main__":
print("\n" + "="*50)
print("🤖 TimescaleDB AIアナリスト (終了するには 'q' または 'exit' を入力)")
print("="*50)
while True:
try:
# ユーザー入力を待機
user_input = input("\n質問を入力してください > ").strip()
# 終了判定
if user_input.lower() in ['q', 'exit', 'quit', '終了']:
print("システムを終了します。お疲れ様でした!")
break
if not user_input:
continue
# Step 1: SQL生成
sql = get_sql_from_ai(user_input)
if not sql: continue
# デバッグ用に生成されたSQLを表示(不要ならコメントアウト可)
print(f" (実行SQL: {sql})")
# Step 2: DB実行
columns, data = execute_query(sql)
# Step 3: レポート生成
final_answer = generate_report(user_input, sql, columns, data)
# 回答表示
print("\n" + "-"*30)
print("🎓 回答:")
print(final_answer)
print("-"*30)
except KeyboardInterrupt:
# Ctrl+C での強制終了対応
print("\nシステムを終了します。")
sys.exit()
使い方
ターミナルで実行すると、入力待ち状態になります。
連続して質問ができるようになっていますので、終了したいときは q か exit と入力してエンターキーを押してください。
python3 db_chat_v3.py
実行イメージ:
==================================================
🤖 TimescaleDB AIアナリスト (終了するには 'q' または 'exit' を入力)
==================================================
質問を入力してください > 今日の平均気温を教えてください
🤖 SQLを生成しています...
(実行SQL: SELECT AVG(temperature) AS average_temperature
FROM mqtt_consumer
WHERE time >= CURRENT_DATE;
)
⚡ データベースで検索中...
📝 レポートを作成しています...
------------------------------
🎓 回答:
今日の平均気温は22.6度です。
この値は通常の日数内における月平均気温値であり、気象パラメータを分析する際に使用される重要な情報です。
特定の期間や地域などの異常値や傾向が存在しますか?
------------------------------
質問を入力してください >