🔷 scikit-learn とは?
Pythonで機械学習を行うための最も有名なライブラリです。
✔ 特徴
• 機械学習アルゴリズムがひと通りそろっている
• コードがシンプルで初心者でも使いやすい
• 高速(NumPy / SciPy を利用)
• データ前処理も充実
• 無料で使える
🔷 scikit-learn でできること
① 教師あり学習(supervised learning)
正解ラベル付きのデータから予測するタスク。
② 教師なし学習(unsupervised learning)
ラベルなしデータからパターンを見つけるタスク。
③ モデル評価
「予測の精度がどれくらい良いか?」を定量的に評価できます。
④ 前処理
機械学習に入れる前にデータを整えることです。
💡 線形回帰 (Linear Regression) とは?
線形回帰は、機械学習における最も基本的な回帰(数値を予測するタスク)モデルです。
1. 基本的な考え方
線形回帰の目的は、「**入力データ(特徴量)と予測したい出力(目的変数)の間に、直線的な関係がある」と仮定し、その関係を最もよく表す一本の直線(または超平面)**を見つけ出すことです。
単回帰(特徴量が1つ):
$x$(入力)が変化すると、傾き a に従って y(出力)が直線的に変化する、という関係を見つけます。
重回帰(特徴量が複数):
特徴量 x が複数ある場合($x_1$: 年齢、$x_2$: BMI、...)は、この式を使って、各特徴量の重要度を示す係数($a_1, a_2, \dots$)を決定します。
2. 「学習」は何をしているのか?
モデルが学習するとは、「最もデータにフィットする直線(係数)を見つける」ということです。具体的には、学習用データを使って以下のことを行います。
残差の計算
モデルが予測した値と実際の正解値との差(誤差)を計算します。
最小二乗法
この誤差の二乗の合計(残差平方和)が最も小さくなるように、直線の係数 a(傾き)と切片 bを数学的に求めます。これが「最小二乗法」と呼ばれる手法です。このプロセスにより、モデルは新しいデータが与えられたときでも、過去のデータから学んだ最も確からしい直線的な関係に基づいて数値を予測できるようになります。
コード
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 1. 人工データ(学習用データ)の作成
# x: 特徴量(入力)
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
# y: 目的変数(正解。Xの約2倍の値+ノイズ)
y = np.array([2.1, 4.2, 5.8, 8.1, 10.3, 12.0, 14.5, 16.2, 17.9, 20.0])
# 2. 線形回帰モデルの作成と学習
model = LinearRegression()
# Xとyの関係(直線の傾きと切片)を学習させる
model.fit(X, y)
# 3. 予測
# 元のXの値に対してモデルで予測を行う
y_pred = model.predict(X)
# 4. 結果の表示
print("--- 学習結果 ---")
# 傾き (係数 a)
print(f"傾き (Coefficient): {model.coef_[0]:.2f}")
# 切片 (b)
print(f"切片 (Intercept): {model.intercept_:.2f}")
# 5. グラフによる可視化
plt.figure(figsize=(8, 5))
# 元のデータ点をプロット
plt.scatter(X, y, color='blue', label='実際のデータ点')
# 学習した直線(予測結果)をプロット
plt.plot(X, y_pred, color='red', label='回帰直線 (モデルの予測)')
plt.title('単回帰分析の可視化')
plt.xlabel('特徴量 X (入力)')
plt.ylabel('目的変数 y (出力)')
plt.legend()
plt.grid(True)
plt.show()
実行結果
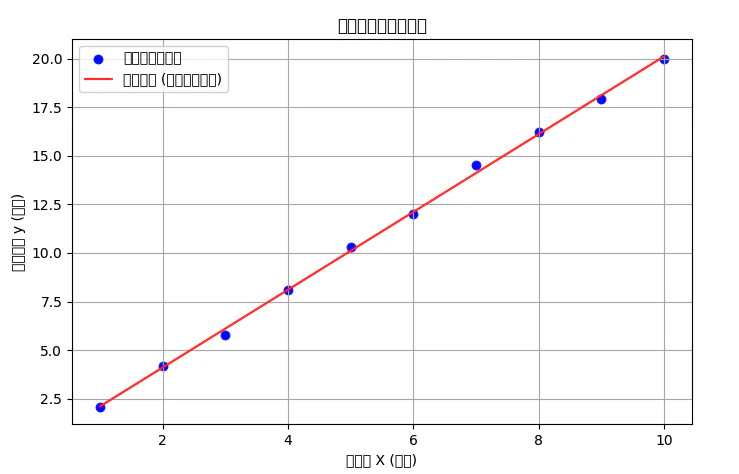
🔑 コードが示す線形回帰の核心
このコードを実行すると、以下の結果とグラフが得られます。
・データ点(青い点)が散らばってプロットされます。
・回帰直線(赤い直線)が、その青い点の間を最も通り抜けるように引かれます。
この赤い直線こそが、線形回帰モデルが学習によって見つけ出した「Xとyの関係」です。
📊 出力される係数の意味
コードの実行結果として表示される傾きと切片は、以下の直線の方程式の $a$ と $b$ に対応します。
$$\text{予測値} = a \times X + b$$
・傾き (Coefficient, $a$): $X$ が 1 増加したときに、予測値がどれだけ変化するか(直線の急さ)。
・切片 (Intercept, $b$): $X$ が 0 のときの予測値(直線が $y$ 軸と交わる点)。
線形回帰モデルの学習とは、この $a$ と $b$ を、データ全体の誤差(残差)が最小になるように決定することに他なりません
感想
線形回帰とは、各データの誤差を最小化し直線化して、将来のデータを予測するための理論だと思いました。