概要
最近、ChatGPT や Gemini といった生成AIを業務で触らない日はなくなりました。また、基盤モデルが登場したことで誰でも簡単にAIを使ったアプリケーションの開発ができるようになり、多くの企業・個人が参入しています。
しかし、それらが具体的にどのような原理で動いているのか、その「中身」を体系的に理解できている人は意外と少ないかもしれません。中身を知っていると「どのモデルを選択するべきか」「望ましい回答を得るためにはどうしたらいいか」がわかります。
この記事では、言語モデルの基礎から、大規模言語モデル(LLM)へと進化した背景、そしてAIが実際に回答を生成するプロセスの裏側まで、エンジニアの視点で解説します。
言語モデルとは
まず、大規模言語モデル(LLM)の基礎となる言語モデルについてです。
言語モデル自体は古くからありました。しかし近年「自己教師あり学習(Self-Supervised Learning)」の登場により、言語モデルは大規模言語モデル(LLM)へと劇的な進化を遂げたのです。
代表的な言語モデル
言語モデルとは、簡単に言えば「ある単語の次にどの単語が来るか」という統計的な性質を学習したモデルです。大きく分けて2つのタイプがあります。
- マスク言語モデル: 「私の好きな__は青色です」といった穴埋め問題を得意とする(例:BERT)。
- 自己回帰言語モデル: 「私の好きな色は__」の後に続く言葉を順番に予測する(例:GPTシリーズ)。
現在、生成AIとして主流なのは後者の「自己回帰言語モデル」です。
言語モデルの基礎知識
トークン
言語モデルが処理する最小単位です。モデルによって異なりますが、単語や文字、あるいは単語の一部を「トークン」として扱います。英語の場合、100トークンは約75単語に相当しますが、日本語は構造上トークン数が多くなりがちで、コストや処理効率に影響するポイントです。
AIにかかるコストを見積もる際も、このトークンを「いくつ使うか」を考えれば大体計算できます。

やっていることは「続きの補完」にすぎない
言語モデルのアウトプットは、あらかじめ決められた選択肢からの回答ではなく、手持ちの語彙を組み合わせて自由に生成する「オープンエンド(自由入力)」形式です。プロンプト(入力文)を「補完」するのがモデルの本質であり、「質問への回答」「翻訳」「コーディング」も実は「続きのテキストを生成している」に過ぎません。
そしてこのアウトプットも入力と同じトークンとして扱われます。

パラメータ
モデルの「知能の規模」を表す指標です。内部に持っている定数(重みづけ)のことで、「次に来る単語は何か」を予測する精度を高めるのに使います。一般的にパラメータ数が多いほど複雑な概念を理解し、高度な推論が可能になります。
例えば、Llama-3-70Bの「70B」は700億(70 Billion)個のパラメータを持つことを意味します。推論にはこのパラメータをメモリ上に展開する必要があるため、モデルサイズは必要なGPUスペックに直結します。

「自己教師あり学習」によるブレイクスルー
なぜ今、これほどAIが進化しているのか。最大の理由は「自己教師あり学習」の確立にあります。
従来の機械学習では、人間が正解データ(ラベル)を用意する「教師あり学習」が主流で、データの準備が大きなボトルネックでした。
しかし、言語モデルは「次に来る単語」を正解として学習できるため、インターネット上の膨大なテキストデータ(書籍、ブログ、ソースコードなど)をそのまま教材にできます。この「勝手に学習できる」仕組みによって、モデルの巨大化(LLM化)が可能になったのです。

大規模言語モデルから基盤モデルへ
LLMはテキストを扱うものですが、最近では画像や音声も同時に扱えるマルチモーダルモデルへと進化しています。これを現在では**基盤モデル(Foundation Model)**と呼ぶのが一般的です。
基盤モデルは圧倒的な学習量のおかげで、特定のタスク(翻訳専用、要約専用など)に特化させなくても、プロンプト一つであらゆるタスクをこなす汎用性を備えています。そのため、自社でモデルを開発するのはもはやコストパフォーマンスが悪く、既存の基盤モデルをいかに最適化できるか、というエンジニアリングの必要性が上がっています。
生成AIとLLMの違い
最近では「生成AI」と「LLM」はほぼ同義として使われていますが、厳密には少し違います。「生成AI」がジャンル名で、その中に「LLM」がいるイメージです。
- 生成AI: コンテンツ(テキスト、画像、音声、動画など)を新しく作り出すAIの総称
- LLM: 膨大なテキストデータで学習した、テキスト生成に特化した大規模なモデル。
しかし最近のLLMが高性能になり画像も音声も扱えるマルチモーダル化が進んでいるため、ほぼ「生成AI = LLM」という認識になってきています。

基盤モデルの構築と事後学習
ChatGPTなどの基盤モデルの学習は、極めて複雑で膨大なコストがかかる作業です。また、そのノウハウは秘密保持契約で保護されており、核心を知ることはできません。しかし、基盤モデルのおおまかな仕組みを知っていれば、どのモデルを使用し、ニーズに合わせてどのように適応させるかを判断できます。
基盤モデルの学習は「事前学習」と「事後学習」の二段階で行われます。事前学習と事後学習は、知識を得るための読書(事前学習)と、その知識の使い方を学ぶ実践(事後学習)と例えられます。
事前学習
AIモデルの性能は学習データによって決まります。学習データに日本語がなければ、モデルは英語を日本語に翻訳できません。画像分類モデルが学習データで動物しか見ていなければ、植物の写真を何か判断できないでしょう。
多くの基盤モデルが参考にしている学習データの1つに Common Crawl があります。Common Crawl はインターネット上のウェブサイトを不定期にクロールしているもので、膨大なWebページの情報があります。ここに入っている情報の多くは低品質な情報です。誤情報、プロパガンダ、陰謀論、人種差別など、信頼性の低いメディアが含まれています。しかしOpenAIやGeminiを含め、学習データを公開しているほとんどの基盤モデルでCommon Crawlが使われているのです。
また、より大きなモデルのほうが優れていると思われがちですが、Anthropicの報告によると、より多くの事後学習をしたモデルでは人間の好みとの整合性が低いモデルになることを発見しました。「特定の政治的見解や宗教的見解を示す、シャットダウンされたくないという願望を表明する」可能性が高くなるとのことです。
なお、一度学習したデータを忘れさせる方法は今のところわかっていないとのことです。
事後学習(モデルを「お行儀よく」させる)
事前学習を終えただけのモデルは、単なる「高性能なテキスト補完機」であり、会話が成立しなかったり不適切な発言をしたりします。これを修正するのが事後学習です。
- 教師ありファインチューニング (SFT): そのままだと「質問に質問を返す」「勝手に別の話を進める」など会話が成立しません。そこで「質問:〇〇」「回答:△△」というお手本データを学習させ、対話形式を覚えさせます。
- 選好ファインチューニング (RLHF): 「人間からのフィードバックを用いた強化学習」。複数の回答案を人間に評価させ、より好ましい回答を選ぶように重みを調整します。これにより、有害な回答を避け、役に立つ回答をするようになります。

AI界隈で有名な「ショゴス(Shoggoth)」のイラスト。
事前学習しただけのモデルは怪物みたいであり、事後学習をすることで人間っぽい仮面を被っている、というブラックユーモア。
基盤モデルが応答を生成する流れ
AIが回答を生成する際、実は内部で「ルーレット」を回しています。
1. 文脈の理解
ユーザーの質問と、それまでの会話履歴をすべて読み込みます。
2. 次に来るトークンと確率の計算
モデルは「次に来る単語(トークン)」の候補すべてに確率スコアを付けます。以下の図のようなイメージです。
3. トークンのサンプリング
2 の選択肢のうちから1つを選ぶのがサンプリングです。
ここで最も確率の高い選択をするのが最善かと思われがちですが、言語モデルでそれをやってしまうと問題が発生します。「私は...私は...私は...」などのループに陥ったり、何を質問してもまったく面白みのない出力が生成されてしまったりするのです。
そこでモデルは、ルーレットを回すようなイメージで応答を決めます。上の例で言うと、50%の確率で「緑」、20%の確率で「赤」、20%の確率で「青」、9%の確率で「紫」、1%の確率で「それ」、と応答します。これを繰り返して次々と後トークンを生成していくことで、最終的に文章が出来上がるのです。
このように確率分布に従ってあえてランダム性を持たせることで、人間らしい揺らぎや創造性を生み出しています。ChatGPTやGeminiなどの多くの汎用言語モデルはこの仕組みを使っています。
ハルシネーションの正体
AIがもっともらしい嘘をつく「ハルシネーション」の正体は、この「確率的なサンプリング」が原因の一つです。例えば事実としては1%の確率しかない「陰謀論」をサンプリングで選んでしまい、一度嘘を生成すると、次はその嘘を「文脈」として補完し続けるため、嘘が雪だるま式に膨らんでしまうのです。
4. 出力全体のサンプリングする
モデルが最終的な回答を1つ選ぶ際、内部では単に1回生成して終わりではなく、「複数の回答候補を生成し、最も優れたものを選ぶ」というプロセスを挟むことがあります。
確率の積と長さの正規化
最も基本的な選び方は、文章全体で「高い確率を持つ」出力を選択することです。文章に含まれる各トークンの選択確率を掛け合わせることで、その文章が統計的にどれだけ妥当かを算出します。
例えば「私の好きな色は緑です」という文章は以下のトークンと確率で構成されており
「私の(確率50%)」「好きな(確率40%)」「色は(確率60%)」「緑です(20%)」
これは 0.5 * 0.4 * 0.6 * 0.2 = 0.024 が合計値になります。(正確に言うともうちょっと難しい式で表されますが、イメージとして)
ただし、単純に掛け合わせると「文章が長ければ長いほど、確率は限りなくゼロに近づく(=短い文章が有利になる)」という問題が起こります。そのため、実際のシステムでは「トークン数(長さ)で割って平均値を出す」といった正規化処理を行い、公平にスコアリングしています。
検証器(Verifier)による革新
最近のより高度な手法では、生成モデルとは別に「その回答が正しいかどうかを判定する検証器(Reward Model / Verifier)」を動かすことがあります。
- Best-of-N Sampling: 例えば10個の回答を生成させ、検証器が最も高いスコアをつけた1つだけをユーザーに返します。
- 効率の向上: 研究によれば、この検証プロセスを導入することで、モデルのパラメータ数を物理的に増やさなくても、数倍〜数十倍大きなモデルに匹敵するパフォーマンスを発揮できることが分かっています。
基盤モデルの現状と課題
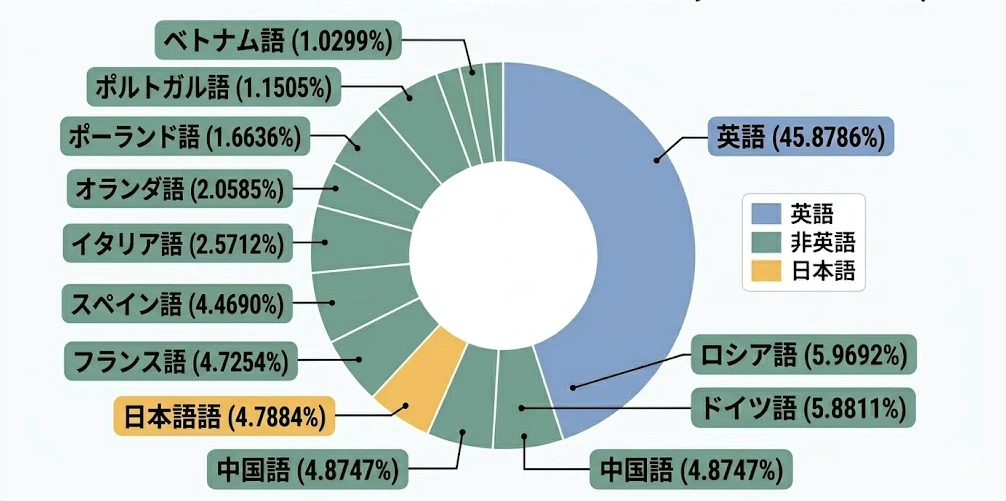
多言語の壁
インターネット上のデータの約半分は英語です。日本語は5%程度しかありません。そのため、多くのモデルで「英語の方が推論能力が高い」「日本語だとトークン数がかさみ、コストが高くなる」といった格差が生じています。
では「他の言語からのクエリを一度すべて英語に翻訳して、応答を得てから元の言語に翻訳しなおす」アプローチはどうでしょうか?多くの人がこのアプローチを試しましたが、今のところ上手くいった例はないそうです。そもそもデータ量の少ない言語を翻訳するのに十分な理解力を持つモデルが必要、翻訳によって失われる情報がある、ということで精度は上がらないようです。
スケーリングの限界(ボトルネック)
「モデルを大きくすればするほど賢くなる」という法則(スケーリングロー)がありますが、現在は2つの限界に直面しています。
- データの枯渇: 基盤モデルは非常に多くのデータを学習に使うため、今後数年でインターネット上のデータが枯渇すると言われています。
- 電力不足: 巨大なモデルの学習・推論には膨大な電力が必要であり、環境負荷やコストが課題になっています。
学習を悪用しようとする人がいる
モデルがインターネット上のあらゆるページを学習していることを悪用し、将来自分たちの利益に繋がるような誤情報を公開して学習させようとする人が現れています。
まとめ
LLMや基盤モデルは、魔法のような知能を持っているように見えますが、その実態は「膨大なデータから統計的な正解を予測する超高性能な補完マシン」です。
- 自己教師あり学習によって、データの壁を越えて進化した。
- 回答生成は確率的であり、ランダム性(遊び)があるからこそ人間らしい。
- 一方で、ハルシネーションや多言語間のコスト差といった課題も理解しておく必要がある。
次はモデルを使いこなす3つのテクニックについて解説していきたいと思います;
- プロンプトエンジニアリング: 入力文を工夫して精度を高める。
- 検索拡張生成 (RAG): 外部データベースから最新情報を取得してプロンプトに埋め込む。
- ファインチューニング: 特定のデータセットでモデルを追加学習させる。
これらのテクニックは「AIエンジニアリング」と呼ばれています。これについては別の記事で詳しく解説しようと思います。