BigQueryの機能の一つRANGE_BUCKETについてお話しします。この関数は、データソースの差異を効率的に検証し、値の分布を簡単に可視化できるものです。
Mathematical functions | BigQuery | Google Cloud
RANGE_BUCKETを使うのに必要な引数
- 値:バケットを見つけたい対象
- 配列:値をグループ化するためのバケット間隔
上記の引数を受け取り、データをカテゴリ化します。
RANGE_BUCKETとCASE WHEN文のそれぞれのメリット
RANGE_BUCKET
- コードが簡潔で読みやすい
- バケットの範囲を配列で簡単に変更可能
- 大量のバケットを扱う際に効率的
CASE WHEN
- 条件をより細かく制御可能
- 各バケットに対して異なる処理を適用しやすい
- 複雑な条件分岐を表現しやすい
CASE WHENの方が私は馴染み深いのでCASE WHENを使いますがカテゴリが多く分類をたくさんする必要がある場合には活用しようかなと思いました。
RANGE_BUCKET vs CASE WHEN
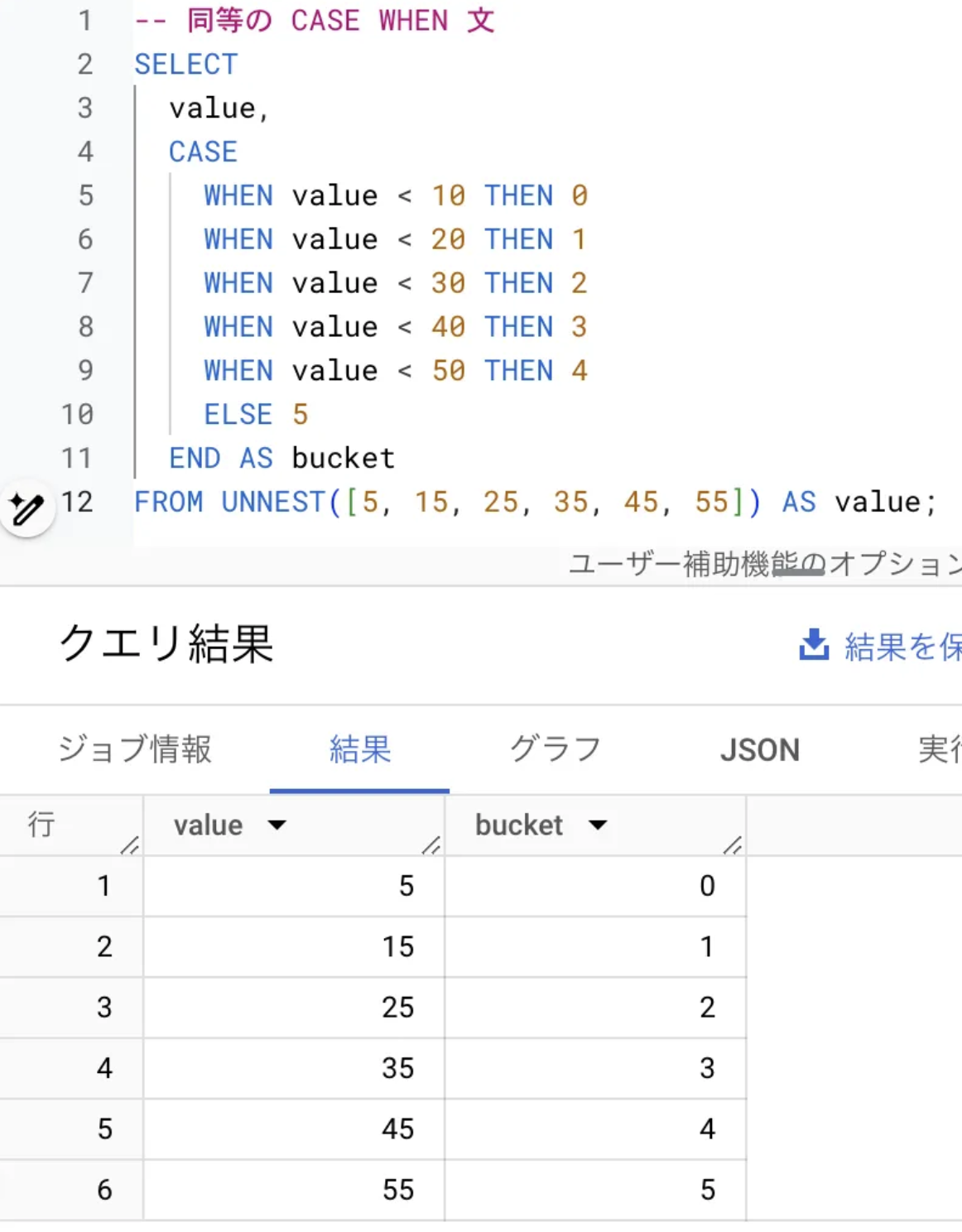
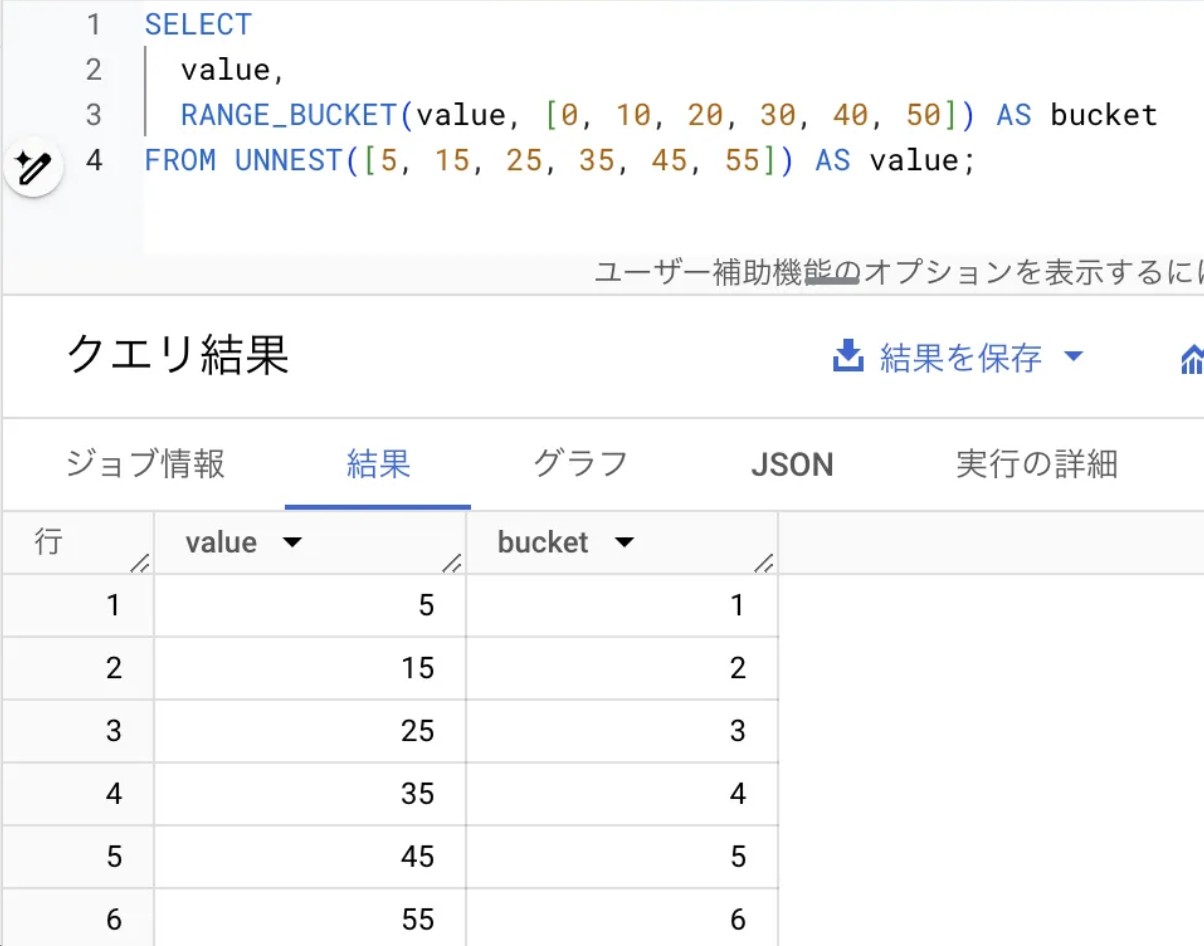
以下は、RANGE_BUCKETとCASE WHEN文を比較する簡単な例です:
-- RANGE_BUCKET を使用した例
SELECT
value,
RANGE_BUCKET(value, [0, 10, 20, 30, 40, 50]) AS bucket
FROM UNNEST([5, 15, 25, 35, 45, 55]) AS value;
-- 同等の CASE WHEN 文
SELECT
value,
CASE
WHEN value < 10 THEN 0
WHEN value < 20 THEN 1
WHEN value < 30 THEN 2
WHEN value < 40 THEN 3
WHEN value < 50 THEN 4
ELSE 5
END AS bucket
FROM UNNEST([5, 15, 25, 35, 45, 55]) AS value;
結果
range_bucket
case when文