こんな困りごとを解決します
![]() 「京都」で検索!
「京都」で検索!

![]()
![]()
![]() かぎ括弧の中身だけを正規表現
かぎ括弧の中身だけを正規表現 「.* 」 で抽出!

![]()
![]()
![]()
1. はじめに - 正規表現における2つの「否定」
「正規表現 否定」で検索してここへ来た方へ。 おそらくあなたが想定しているような「正規表現で否定を表すシンプルな表現」はないです。 でもご安心を。おそらくあなたがやろうとしている事は、正規表現を使ってできます!「正規表現 否定」という理解レベルから、一歩上を目指してみましょう。
この記事では正規表現における「否定」のうち、否定文字クラス と 否定後読み・否定先読み という機能を解説します1。 手っ取り早く使えるようになってもらうために、説明の後に例と練習問題を載せました。また、私含めた正規表現勉強中の方へ向け、基本的な正規表現機能の説明を適宜加えました。一方である程度知っている方はサクサク読めるように、補足や細かい内容は折りたたみ部に入れました。
否定後読み・否定先読みに類似する機能に、肯定後読み・肯定先読み があります。せっかくなので、これも今回解説します。
凡例・注
正規表現は [\d,]+(?=円) のようにコードとしてハイライトしてあります。ただし▷の小見出し内ではハイライトが使えなかったので、普通に記載しています。
正規表現がどの文字列のどの部分にマッチするかの例文は、「[\d,]+(?=円) のテスト例文」のような見出しをつけてあります。また、テスト文字列のうちマッチする箇所のみに背景色をつけてあります(下記の例参照)。
2. 否定文字クラス
否定文字クラスとは、簡単に言うと「ある文字を除く任意の文字にマッチする」正規表現のことです。書式は [^除外したい文字] のように書きます。
否定文字クラスの前に、文字クラスについておさらいしたい方へ
文字クラスという用語は知らないけれど、 [0-9]+ の意味はわかるよ、という方はいるかもしれません。ここでいう [0-9] の部分は、0から9までの文字、すなわちアラビア数字という文字種2を表します。このように文字種を表すための正規表現を文字クラスといいます。ちなみに + の部分は、1文字以上という意味です。
文字クラスを表すための基本的な表現として、 [0123456789abcdef] のようにマッチしてほしい文字をすべて列挙する方法、 [a-f] のように範囲で指定する方法、 [0-9a-f] のようにそれらを組み合わせる方法(この場合は0から9の数字か、aからfのアルファベットいずれかにマッチする)があります。
そのほかに、 \d で0から9の数字3、 \s でタブやスペースや改行といった空白文字、のように、バックスペース+アルファベット で文字クラスを略記することがあります。
否定文字クラスの例
基本的な例
[^0-9] で、数字以外の任意の文字を表します。
[^0-9] のテスト例文

補足: 文字クラス内のハイフン
文字クラス・否定文字クラス内でハイフンを文字通り使いたいときは、 [^-0-9] のように先頭に書けばOKです。
少し洗練させた例
上記例を少し洗練させて、 [^0-9,.] とすれば、数字の間に挟まっているカンマやピリオドも除外することができますね。こうすれば、たとえば値段が一覧になっているファイルの中に、数字・カンマ・小数点以外の余計なものが含まれていないかどうかのチェックに使えます4。
[^0-9,.] のテスト例文

補足: 文字クラス内のピリオド
ピリオドは文字クラス内ではエスケープ不要です。文字クラスの中と外では、ルールがまったく別と考えた方が良いでしょう。「対になるカッコにマッチしない」問題を解決
よくある「対になるカッコにマッチさせたいのに、近くに別のカッコがあるせいで狙ったところにマッチさせられない」問題は、否定文字クラスを活用して「[^」]*」 と表現すれば解決することが可能です5。
「[^」]*」 の分解
-
「かぎ括弧開きにマッチ -
[^」]*かぎ括弧閉じ以外の文字 が任意の数マッチ6。 -
」かぎ括弧閉じ にマッチ

もっと詳しい解説
正規表現特有の「記号ばっかりで頭おかしくなりそう!」という気持ちはよくわかります。次のようにステップに分けて、落ち着いて考えれば大丈夫。
原型は、かぎ括弧で囲まれた部分を表す次の正規表現です。
「」
その中に、任意の文字が任意の数だけマッチするようにした正規表現 .* を入れて、
「.*」
とします。
この状態でもある程度機能しますが、先ほど述べた「対になるカッコにマッチさせたいのに、近くに別のカッコがあるせいで狙ったところにマッチさせられない」という問題が発生してしまうわけです(Regex Testerでテストしてみましょう)。
「.*」 のテスト

そして、それを解消するためのアイデアが先ほどの正規表現 「[^」]*」 だったのでした。かぎ括弧の中身が .* から [^」]* になっています。かぎ括弧の中身はなんでもいい、としてしまうと、かぎ括弧閉じ 」 も含めてなんでもいい、と解釈されてしまい、最も長い部分にマッチしてしまいます。そこで、「[^」]*」 とすることで、
-
「かぎ括弧開きにマッチ -
[^」]*かぎ括弧閉じ以外の文字 が任意の数マッチ -
」かぎ括弧閉じ にマッチ
のすべてを満たした部分のみにマッチするので、結果的にかぎ括弧の開始から終了までが狙ったとおりにマッチします。
否定文字クラスを使った練習問題
次の文字列の中から、 色をつけた部分のみにマッチする正規表現を考えましょう。
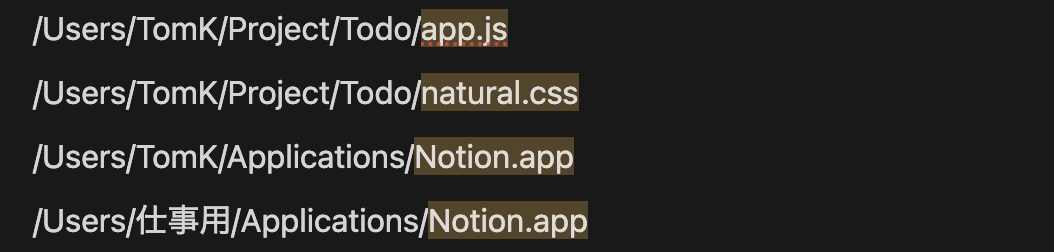
コピペ用
/Users/TomK/Project/Todo/app.js
/Users/TomK/Project/Todo/natural.css
/Users/TomK/Applications/Notion.app
/Users/仕事用/Applications/Notion.app
解答
[^\/]*$
解説
行末付近のみを抜き出したいので、 $ を使います。
ファイル名部分にはスラッシュを使えないので、「行末付近にある、スラッシュ以外の文字列の並び」を考えればよいです。従って解答は [^\/]*$ 。
-
[^\/]*スラッシュ以外の文字列、任意の数 にマッチ -
$行末位置 にマッチ -
\/.*?$ではダメ?: マッチは先頭から順に試されるので、最小量指定子.*?を使ったとしてもこの例ではうまくいかない。
3. 否定後読み・否定先読み
否定後読みとは、一言で言うと「左側に特定のマッチがないような位置 にマッチする」正規表現です。
書式は (?<!左側に来てはいけないパターン) のように書きます。
否定先読みとは、一言で言うと「右側に特定のマッチがないような位置 にマッチする」正規表現です。
書式は (?!右側に来てはいけないパターン) のように書きます。
一言で説明されても難しいと思うので、例で説明します。
先読みと後読みが逆では!?
感覚としては左から右に向かって文を読むので、自分が右を向いている状態。前方=先が右、後方が左、という説明でいかがでしょうか?自分的にはしっくり来てます。
否定後読みの例
(?<!東)京都 のテスト例文

テスト例文の中から色をつけた部分だけにマッチさせたいとします。「京都」にマッチさせたいので正規表現パターンを 京都 とすると、東京都立大学や東京都市大学にもマッチしてしまいます。
そこで、「左側に 東 がなくて、かつ 京都 にマッチしたい」と考えます。これはまさに否定後読みがぴったりはまる利用場面です。 (?<!東)京都 という正規表現を使えば、上記の色をつけた部分にのみマッチします。
否定先読みの例
.+\.(?!md).+ のテスト例文
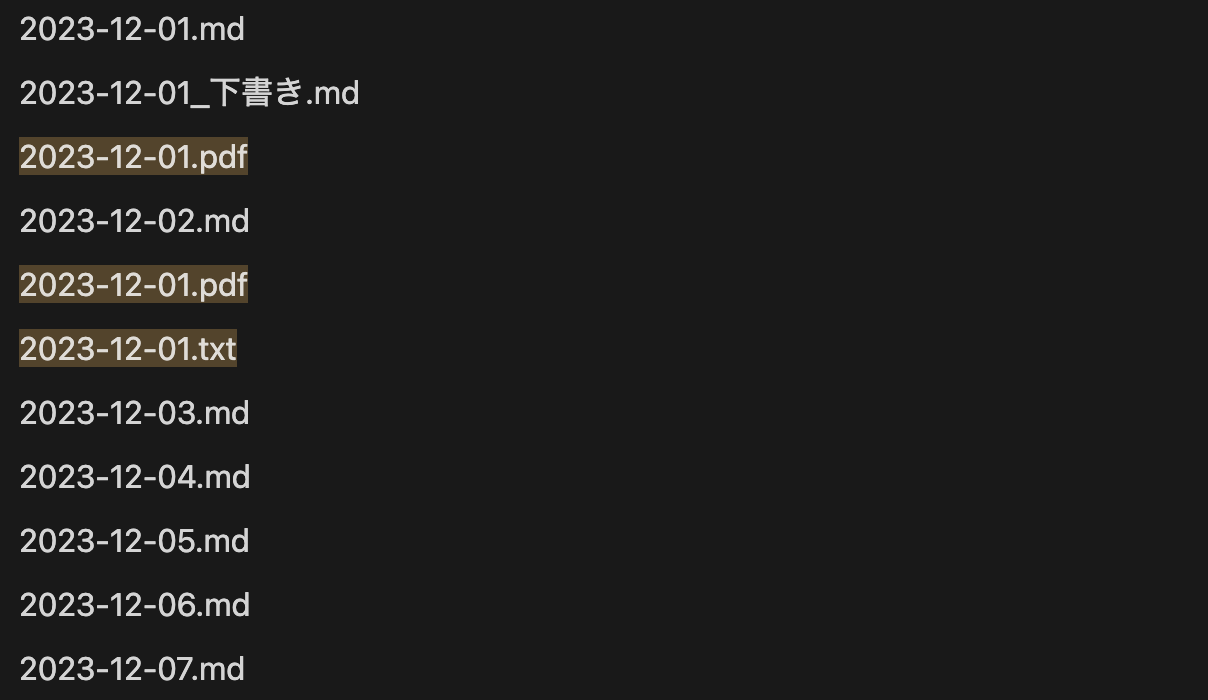
テスト例文のようなファイル名の一覧から.mdファイル以外を効率的に発見するために、否定先読みを活用できます。.+\.(?!md).+ という正規表現を考えてみました。
.+\.(?!md).+ の分解
-
.+任意の文字が1つ以上: ファイル名のうち拡張子の前部分を想定 -
\.ピリオド -
(?!md)mdという文字列が右側に来なければOK -
.+任意の文字が1つ以上: ファイル名のうち拡張子の部分を想定
もっと詳しい解説(やや長いです)
文字列
2023-12-01.pdf
が正規表現 .+\.(?!md).+ にマッチする手順を説明します8。正規表現.+\.(?!md).+ を構成する要素を順番にみていきましょう。
-
.+任意の文字が1つ以上: ファイル名のうち拡張子の前部分を想定 -
\.ピリオド -
(?!md)mdという文字列が右側に来なければOK -
.+任意の文字が1つ以上: ファイル名のうち拡張子の部分を想定
.+ 任意の文字が1つ以上: ファイル名のうち拡張子の前部分を想定
最大量指定子 + があるので、行けるところまで行きます。
マッチの候補:

\. ピリオド(リテラル)
正規表現の次の要素はピリオド(リテラル)なので、「行けるところまで」行ったマッチの候補のうち、次がピリオドになっている部分以外は捨てられます。
マッチの候補:

(?!md) mdという文字列が右側に来なければOK
正規表現の次の要素は否定先読みなので、右側に md がこなければOKです。右側に特定のパターンがこないかどうかチェックだけして、カーソル(マッチの候補を精査する箇所)は先へ進めません。(この考え方を「マッチを消費しない」と言ったりします。詳しくは第5節参照。) 今回は唯一残っている候補は、mdという文字列が今の位置(ピリオド)の右側にないのでOKですね。
マッチの候補:
.+ 任意の文字が1つ以上: ファイル名のうち拡張子の部分を想定
正規表現の最後の要素はまた「行けるところまで行く」タイプなので、行末まで行きます。
マッチの候補:

これで正規表現は最後まで到達しました。最後に残っていた3つの候補
のうち、最も長くマッチしている物(最大量指定子 + を使っているため)が選ばれます。
結果、
2023-12-01.pdf
にはマッチします。
この例は後でより洗練されたものを提示します。
否定先読みと置換を組み合わせた応用例: Markdownで目次作成
^(?!#{1,3} ).*\n を無に置換すれば、h1, h2, h3見出しだけを取り出せます。
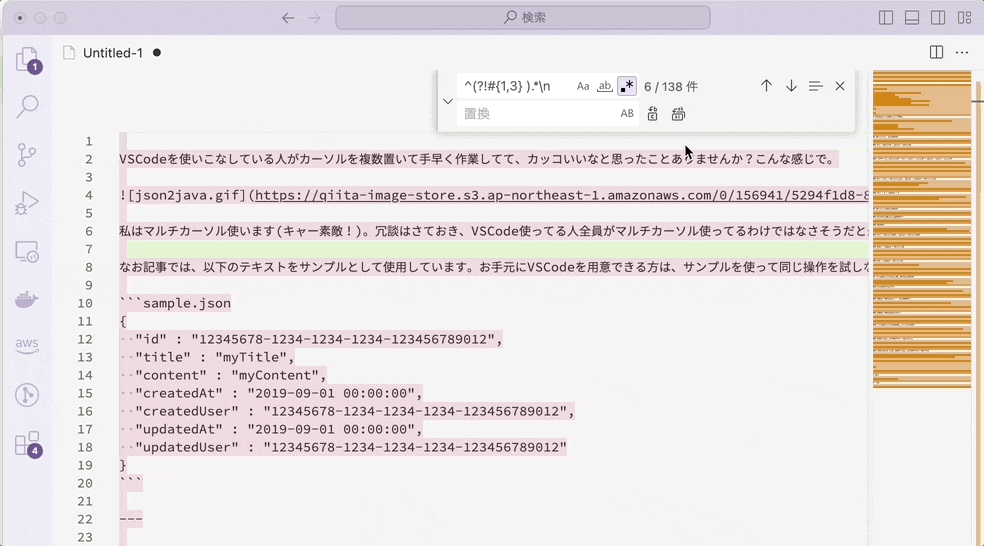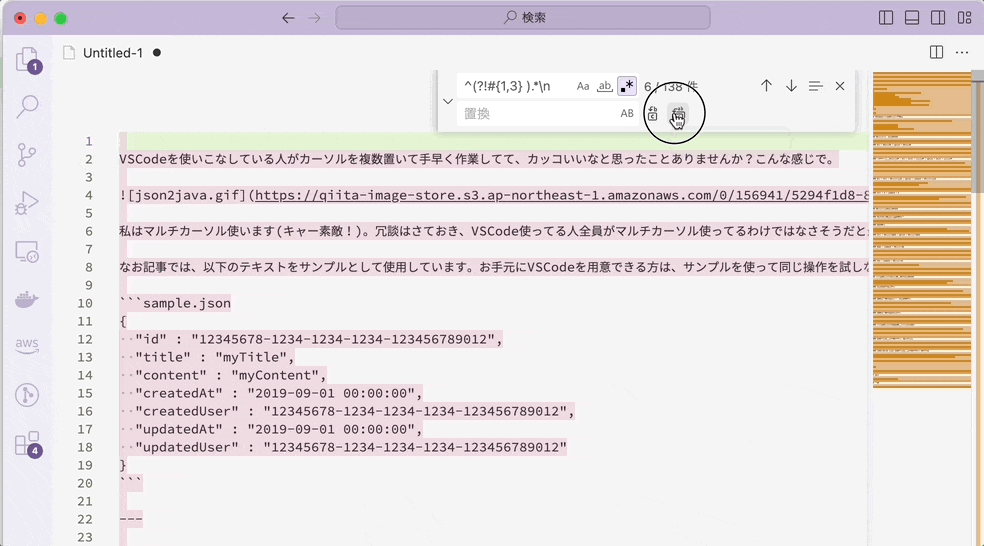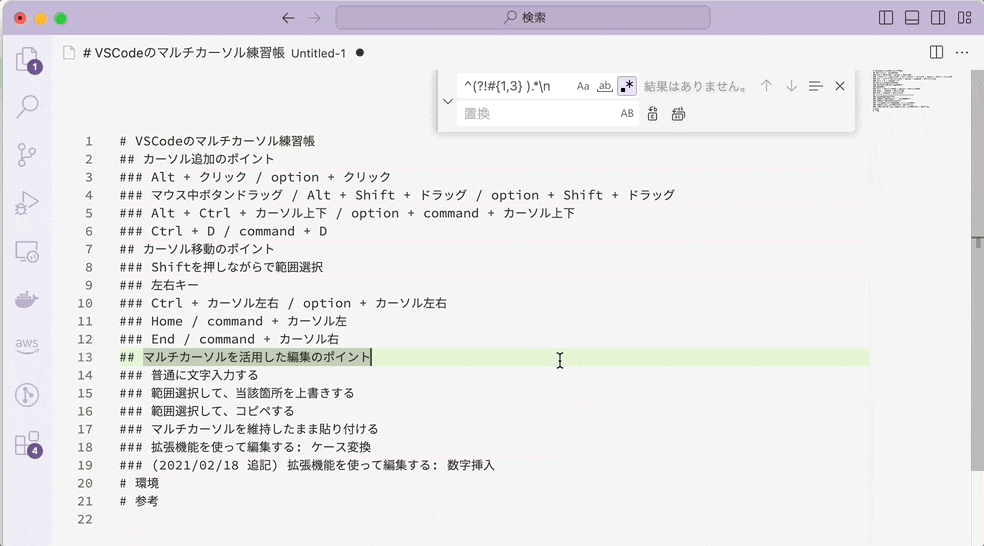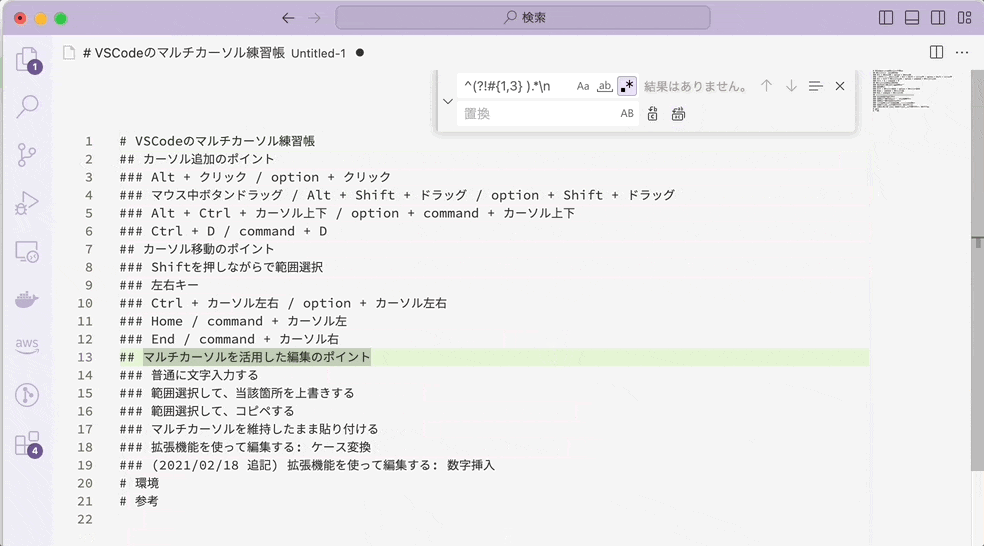
h1, h2, h3見出し行以外の行をすべて葬れば、見出し行のみが残るというわけです。(実際に使うかはわかりませんが) 目次を作るのに使えそうですね。
^(?!#{1,3} ).*\n の分解
-
^行頭にマッチします。 -
(?!#{1,3} )否定先読み。#{1,3}は#が1つから3つある場合にマッチします。今回はそれを否定先読みの中に入れているので、右側がMarkdownのh1, h2, h3見出し(( #または##または###から始まる行。最後の#と見出し文字列の間にはスペースを1つ入れる ))以外であればマッチします。 -
.*\n任意の文字列が行末までマッチします。改行も含めて無に置換したいので、\nをパターンに含めています。
否定後読み・否定先読みを使った練習問題
次の文字列の中から、色をつけた部分のみにマッチする正規表現を考えましょう。
(ハイフン区切りのない電話番号で、ちょうど10桁のものにのみマッチする。携帯電話の11桁電話番号にはマッチしないようにしたい)

コピペ用
電話番号: 0312345678
0450000000までお問い合わせください。
お問い合わせ先:09000001111(直通)
解答
(?<!\d)\d{10}(?!\d)
先頭のゼロを活用するなら
0\d{9}(?!\d)
解説
10桁の数字なので、と簡易に
\d{10}
としてしまうと、携帯電話の番号11桁の先頭10桁にマッチしてしまいます。

これが嫌なので、10桁の数字の後にはこれ以上数字がこないようにしたいですね。つまり、否定先読みを使って、右側に数字が来るパターンを除外します。
\d{10}(?!\d)
これでうまく行ったでしょうか?これだと

のようになってしまい、狙っていないところにマッチしてしまいます(9からマッチを開始すると、ちょうど10桁の数字がある&その次は数字ではないので)。
10桁の数字の前にも数字がないことが保証できれば、「ちょうど10桁の数字」を表現できますね。なので、否定後読みを使って、左側に数字が来るパターンを除外します。
(?<!\d)\d{10}(?!\d)
あるいは、電話番号の先頭が0であることを利用するならば、もう少し簡略化して
0\d{9}(?!\d)
とすることもできます9。
4. 肯定後読み・肯定先読み
「否定」の説明はこれで終わりですが、せっかくなので肯定後読み・肯定先読みについても覚えてしまいましょう。否定後読み・否定先読みの反対です。もうなんとなく想像つくと思います!
肯定後読みとは、一言で言うと「左側に特定のマッチがあるような位置 にマッチする」正規表現です。書式は (?<=左側に来てほしいパターン) のように書きます。
肯定先読みとは、一言で言うと「右側に特定のマッチがあるような位置 にマッチする」正規表現です。書式は (?=右側に来てほしいパターン) のように書きます。
肯定後読みの例
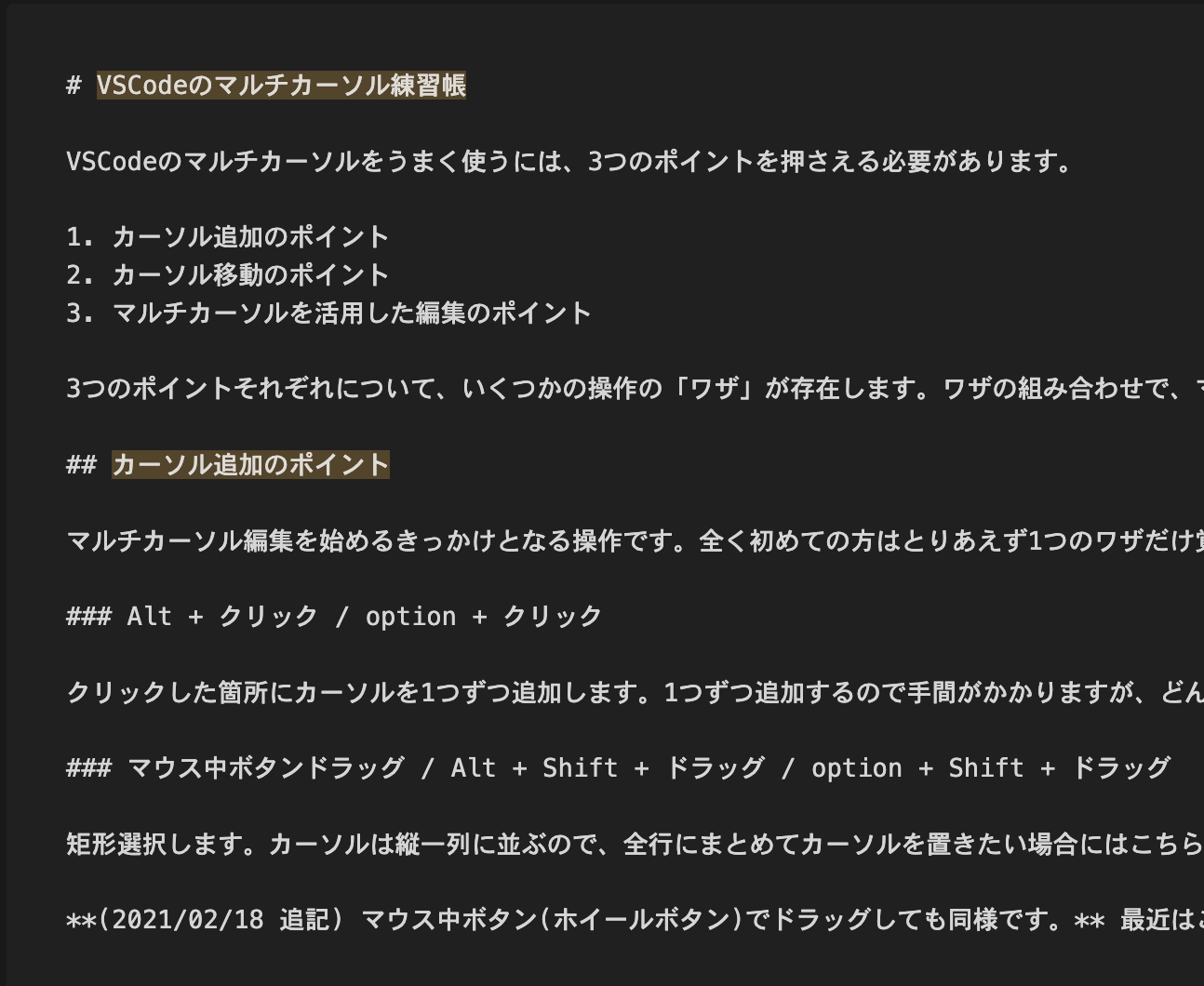
Markdownでh1(#)とh2(##)の見出し文字部分にのみマッチする (?<=^#{1,2} ).* という正規表現を作ってみました10。
(?<=^#{1,2} ).* のテスト
肯定先読みの例
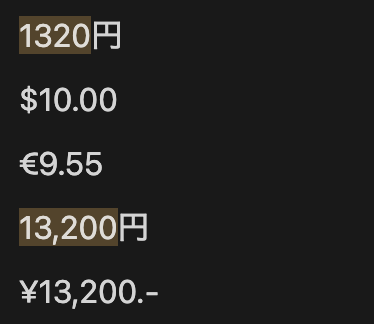
右側に「円」が来る数字(あるいはカンマ)の列にマッチする正規表現を
[\d,]+(?=円) のように作ってみました。
[\d,]+(?=円) のテスト

[\d,]+(?=円) の分解
-
[\d,]「数字またはカンマ」を表す文字クラス。+をつけているので1文字以上の並びにマッチします。 -
(?=円)後ろに「円」が来ればマッチします。
[\d,]+円 との違いは?
[\d,]+円 だと、最後の「円」まで含めてマッチします。 [\d,]+(?=円) だと、最後の「円」は含まずにマッチします。
肯定後読み・肯定先読みを使った練習問題
次の文字列の中から、色をつけた部分のみにマッチする正規表現を考えましょう。
(JSONのうち、値がUUIDの形式になっている部分のキーのみにマッチする。)
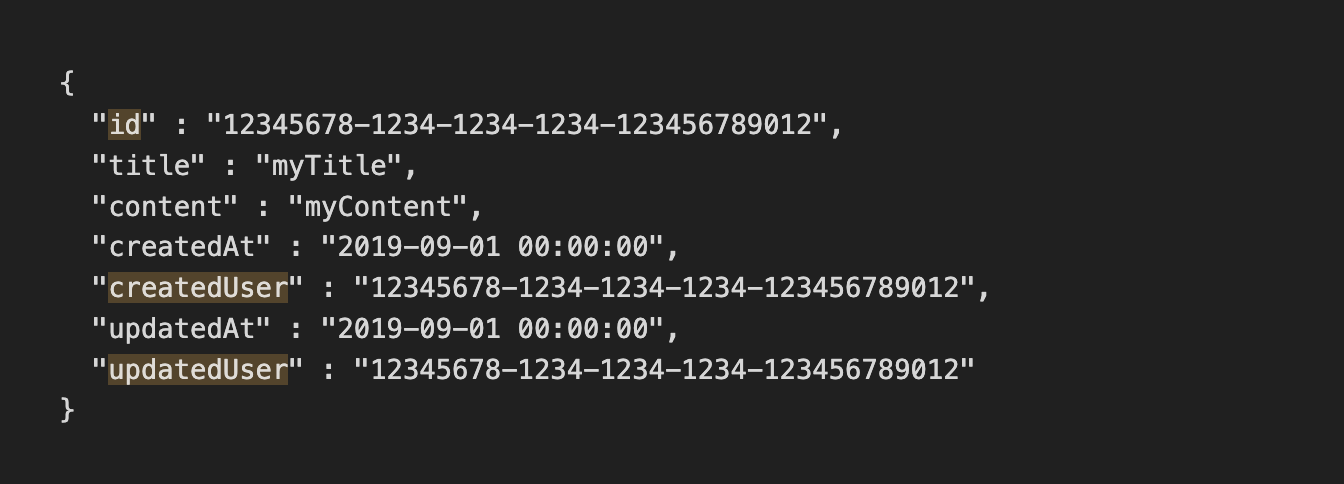
コピペ用
{
"id" : "12345678-1234-1234-1234-123456789012",
"title" : "myTitle",
"content" : "myContent",
"createdAt" : "2019-09-01 00:00:00",
"createdUser" : "12345678-1234-1234-1234-123456789012",
"updatedAt" : "2019-09-01 00:00:00",
"updatedUser" : "12345678-1234-1234-1234-123456789012"
}
補足: UUIDの書式
f12555ea-3532-4114-867a-e463dadc5052
のように、
- 8桁-4桁-4桁-4桁-12桁
- 各桁は16進数[0123456789abcdef]
- 厳密にはバージョンとかルールとかあるけど例によって今回はこだわらなくていいです。
解答
[^"]+(?=" ?: ?"[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}")
解説
長いけど要素ごとにみればシンプルです!
-
[^”]+ダブルクォーテーション以外の文字列 1文字以上 -
(?=" ?: ?"肯定先読み" : "つまりキーと値の間の部分にマッチ。コロン前後のスペースはあってもなくてもいいので?をつけました。((もっとこだわりたければ\s*にしてもよいし、例題にはスペース1つが必ず入っていたので?なしでもよい)) -
[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}UUID本体部分。 -
")値部分のダブルクォーテーション閉じと、肯定先読みの終わり。
5. 先読み・後読みをもっと理解する
これらは細かい挙動ですが、先読み・後読みをより深く理解し、使いこなすのに役立つはずです。
5-1. 「マッチを消費しない」という考え方
例: the 以外の3文字の英単語
\b(?![Tt]he)[a-zA-Z]{3}\b
\b(?![Tt]he)[a-zA-Z]{3}\b のテスト例文

(?![Tt]he) で、右側にtheやTheが来ないことをチェックします。この際、カーソル(現在注目している文字)は動かさないままです。このことを「マッチを消費しない」と言います((ちゃんとした用語じゃないかも。「詳説 正規表現」では頻繁に登場した言葉。) 。個人的には、「右側をチラ見する」感覚だと思っています。先読み・後読みでない通常のマッチでは、チラ見でなくどんどん読み進めていく感じ。
\b(?![Tt]he)[a-zA-Z]{3}\b の分解
-
\bは単語境界にマッチします。 -
(?![Tt]he)肯定先読み。右側をチラ見して、theやTheがないことをチェックします。 -
[a-zA-Z]{3}で、アルファベット3文字にマッチします。繰り返しになりますが、(?![Tt]he)はマッチを消費していないので、\bつまり単語境界の直後の[a-zA-Z]{3}にマッチします。 - 最後に、
\bが単語境界にマッチします。これにより3文字の英単語のみにマッチします。
あるいは、同じ事を後読みを使って表現することもできます。
\b[a-zA-Z]{3}(?<![Tt]he)\b
\b[a-zA-Z]{3}(?<![Tt]he)\b の分解
-
\bが単語境界にマッチします。 -
[a-zA-Z]{3}で、アルファベット3文字にマッチします。この時点では、Theやtheも含めてマッチします。 -
(?<![Tt]he)で、左側にtheやTheが来ないことをチェックします。1つ前のステップでアルファベット3文字を読んだ後、左側をチラ見して、既に通ってきた部分がtheやTheでなければクリア!という感覚です。 - 最後に、
\bが単語境界にマッチします。これにより3文字の英単語のみにマッチします。
例: ファイル名の末尾が.mdで終わらない
※新しい情報はないです。これまで学んだことの復習です
後読みは「既に読んだ部分を振り返る」ことができるのでした。これを使って、ちょっと前に登場した「ファイル名の末尾が.mdになっていないもののみを抜き出す」例をより洗練させることができます。
.*(?<!\.md)$
.*(?<!\.md)$ のテスト例文
.*(?<!\.md)$ の分解
-
.*任意の文字、任意の文字数にマッチします。 -
(?<!\.md)左側に.mdが来ないことを、既に読んだ左側をチラ見してチェックします。 -
$行末にマッチします。
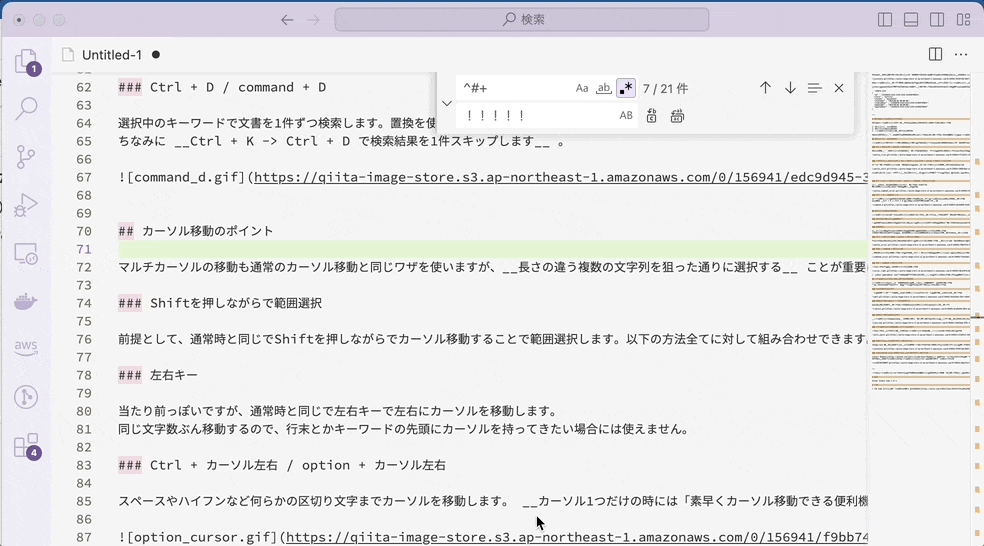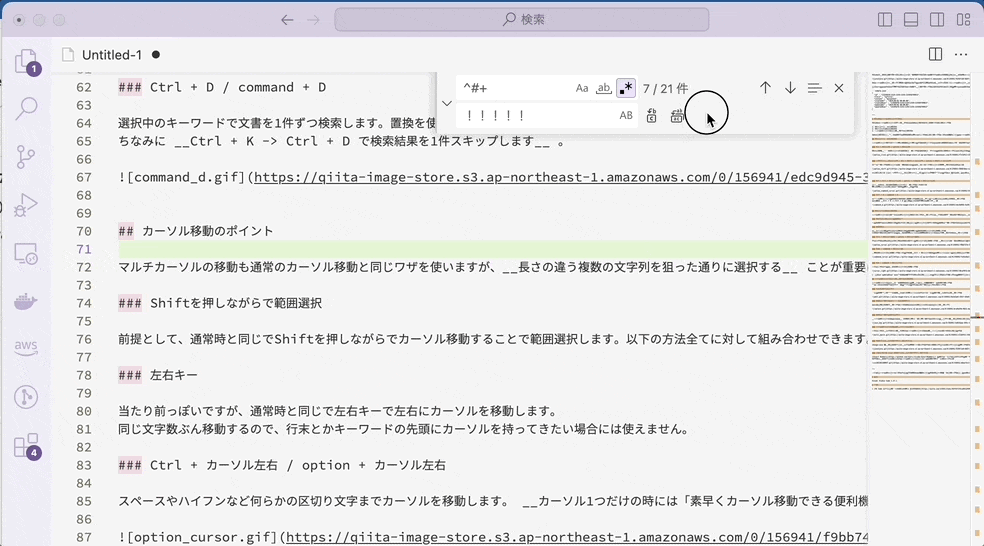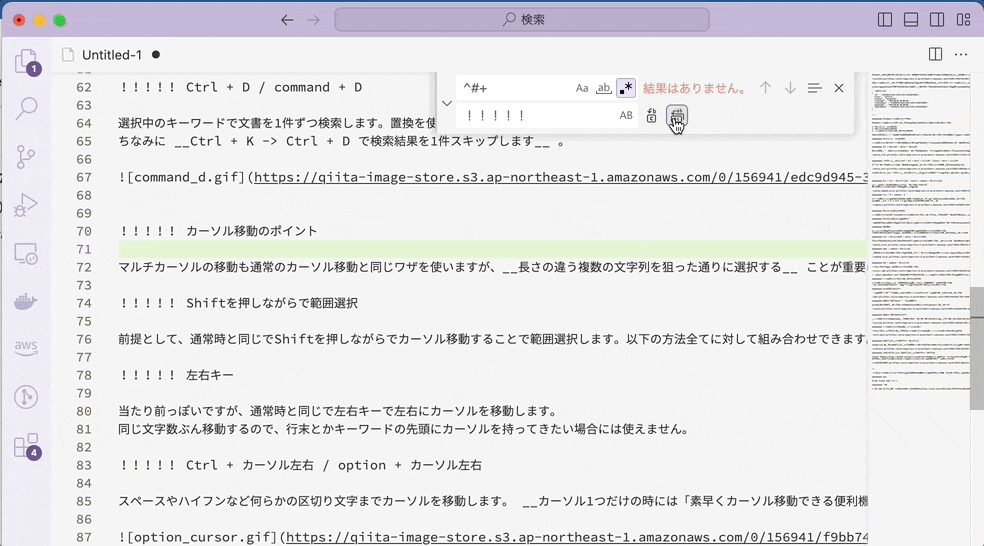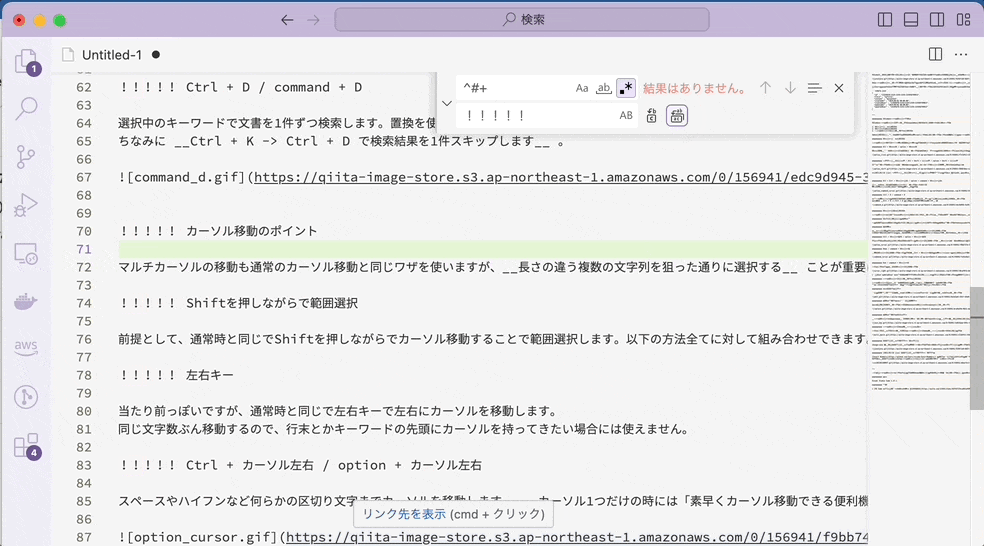
5-2. 先読み・後読みは文字(列)ではなく、位置にマッチする
先読み・後読みは文字列自体にマッチするわけではなく、位置にマッチします。たとえば、肯定先読み (?=#+) なら、「右側に#がいくつか来るような位置」にマッチします。
といってもわかりにくいですね。置換を組み合わせつつ、通常文字列の場合と比較してみましょう。
通常文字列×置換
先読み×置換
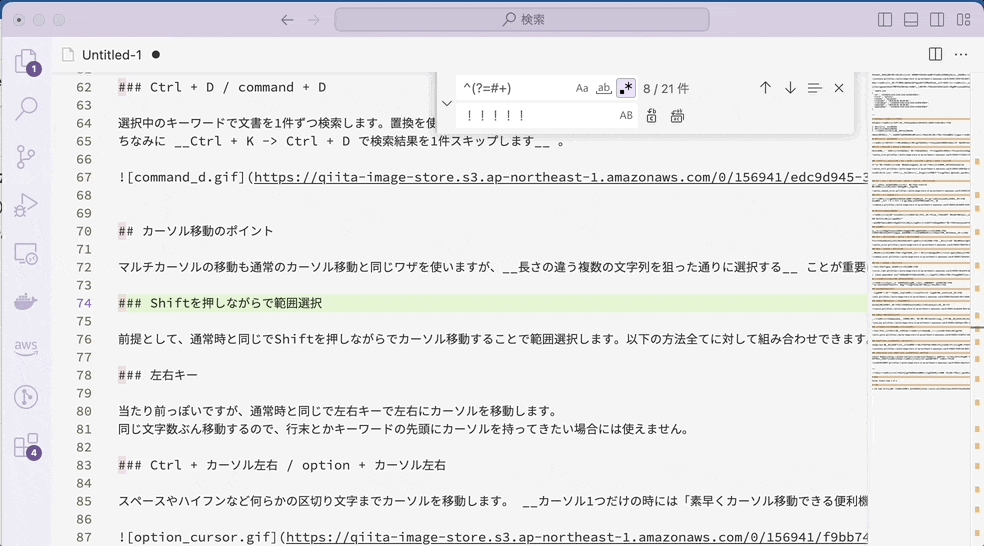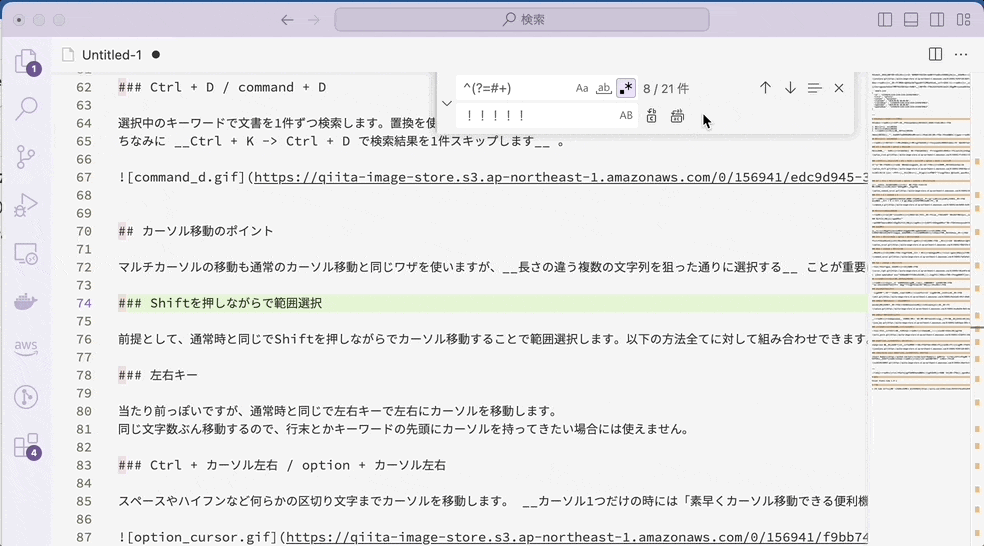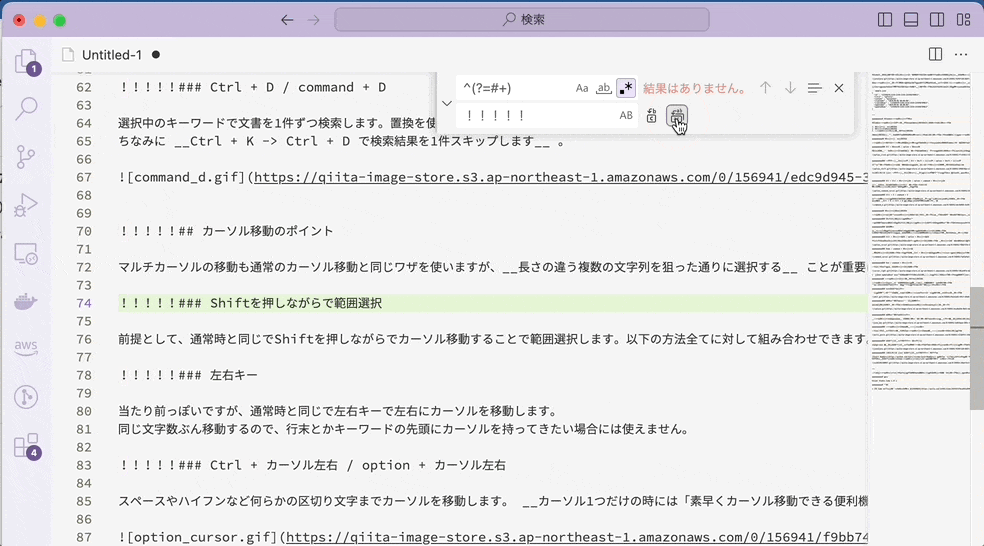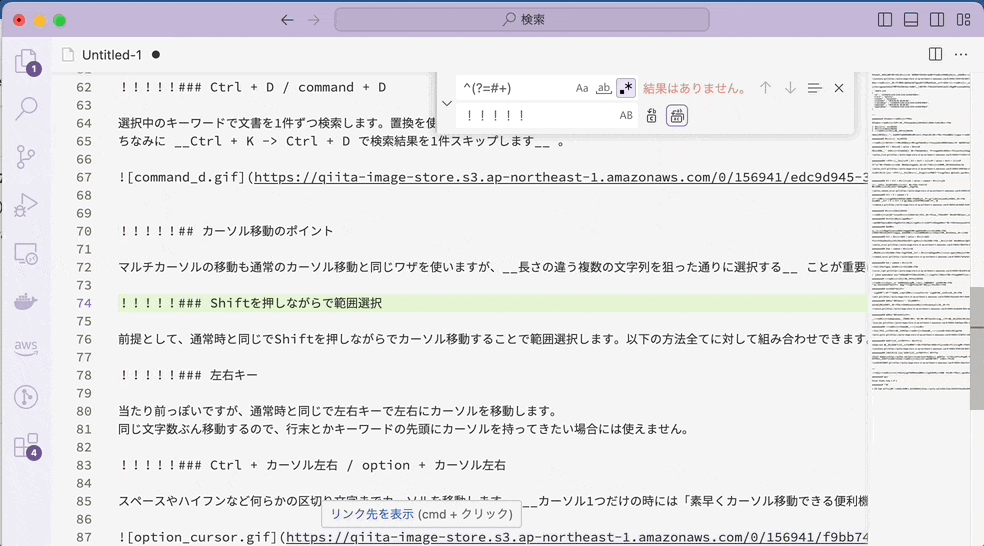
通常文字列の場合には、マッチした 「###」の部分が「!!!!!」に置き換えられています。それに対して、先読みの場合には「###」自体にマッチするのではなく「右側に###が来るような位置」にマッチするので、無を「!!!!!」に置き換えます。つまり、「!!!!!」を挿入したような結果になるのです。
6. おさらい
本記事では正規表現における2種類の否定として、否定文字クラスと否定後読み・否定先読みを紹介しました。また、後読み・先読み関連で、肯定後読み・肯定先読みについても紹介しました。
書式を改めて掲載します。
| 機能 | 書式 | 例 |
|---|---|---|
| 否定文字クラス | [^除外したい文字] | [^0-9,.] |
| 否定後読み | (?<!左側に来てはいけないパターン) | (?<!東)京都 |
| 否定先読み | (?!右側に来てはいけないパターン) | .+.(?!md).+ |
| 肯定後読み | (?<=左側に来てほしいパターン) | (?<=^#{1,2} ).* |
| 肯定先読み | (?=右側に来てほしいパターン) | [\d,]+(?=円) |
覚え方
後読み・先読みは、規則的な書式になっているので覚えてしまいましょう。
| 否定 | 肯定 | 特徴 | |
|---|---|---|---|
| 後読み | (?<!) | (?<=) | < がある |
| 先読み | (?!) | (?=) | < がない |
| 特徴 | ! がある | = がある |
7. 参考文献
Jeffery E. F. Friedl 著、株式会社ロングテール/長尾高弘 訳「詳説 正規表現 第3版」2008年、オライリー・ジャパン
アドカレなのにキャッチーなこと書けなくてすみません、、骨太本を読んで(まだ途中ですが)刺激を受けたので、シェアしたくて書いてみました。最新技術も楽しいですがこういった基礎的なことをしっかり固めるのも大事かなと思います。
-
他にも「否定」を正規表現で表す方法があるのかどうかは調べませんでした。ですがこの2つを使えるようになれば、「否定」関連でやりたいことはだいたい表現できるようになりそう。 ↩
-
「文字種」という言葉が正規表現や文字コード界隈で特別な意味を持つ可能性がよぎりましたが、時間がなかったので調べていません。不正確な言葉遣いだったらごめんなさい。 ↩
-
一部のUnicode対応ツールでは、すべてのUnicode数字にマッチする。「詳説正規表現 第3版 p.116より」 ↩
-
行頭と行末の通貨記号は除外したい、漢数字も許容したい、など使う場面に応じて対応ライン=許容ライン=妥協ラインは異なりますね。自分でちょっと「楽する」ために正規表現を便利に使うなら、どの程度で妥協するかは大事です。 ↩
-
最小量指定子
*?,+?などを使うことでも解決可能です。こっちの方がスマートかも ↩ -
*は直前の要素が任意の数(0でもいいし、たくさんあってもいい)マッチすることを表します。 ↩ -
夏目漱石「こころ」四十二 https://www.aozora.gr.jp/cards/000148/files/773_14560.html より。 ↩
-
ここでは正規表現主導型=NFA型の正規表現エンジンを使っている場合を想定しています。正直、私が個人的に使っているツールはほとんどこの(従来型)NFA型正規表現エンジンを使っているように見えました。テキスト主導型=DFA型の正規表現エンジンを使っている場合には異なるマッチ手順をしています。詳しくは参考文献欄の「詳説 正規表現」を参照。 ↩
-
ただし 製造LOT=AA00000000000000123456 のようなものにもマッチしてしまいますが。繰り返しになりますが、どこまで正規表現を洗練させるか?どこまでを考慮に入れ、どこからは諦めるか?は重要です。 ↩
-
エラーがでる場合もあります。正規表現の「方言」によるものと思われます。たとえば https://regex101.com で試せるPCRE2モードでは、先読み・後読みの中で可変長の表現
{1,2}を使うことができません。このように正規表現にはいくつかのバリエーションがあるので注意しましょう。 ↩