不純な動機
私は、データを分析して仮説を立てて実験していくのが好きなんですが、一次データって取得するの難しいなって思いまして、そんな時にSNSって簡単にデータが取れるのはって気づいたので、Twitterを戦略的にバズらせたいなと思いました。
技術的なproblem
API取ってみたんですが、pythonで使えるTweepyっていうライブラリがめちゃくちゃ使いにくくてびっくりしました。困ったこと下にまとめました。
-
投稿数が200件しか取れなくて、これじゃあツイ廃の人絶対困るだろうなと思いました。
- -
Tweepy経由だと誰がいいねしたのかが取れない。restAPIぶん回したら、いいねをしたアカウントのユーザーIDは取れるみたいでした。ちなみにユーザーIDはユーザー名じゃないです。見ても誰のアカウントなのか分かりません。気になる人のためにリンクを貼っておきます。
これです。 -
Tweepy経由で取得したツイートに、Twitter Developerに登録されているツイートが混じる。マジで理由がわかりませんが、高校生の時のツイートとか混じってて恥ずかしいし、ノイズ過ぎて困りました。
この問題が謎すぎるので、解決した経験のある方は教えていただけると幸いです。
ということでAPI作戦は諦めました。
最近は、InstagramのAPIで遊べることも減ったみたいで寂しいですね。阿保みたいにスクレイピング食らってサーバーに負担掛かるくらいならAPI公開してほしいと思うのですが、、、
残された手段としてSeleniumを使うことにしました。
技術的なproblemの解決
Twitterの投稿URLを見ていただければ、気づくと思うんですが
このtwitter.comの後ろが、アカウント名になっていてstatusの後ろがTweetIDになっているので、一旦TweetIDだけを取り切ってファイルに保存しておきます。
そのあとに、それぞれのTweetIDからURLを合成してrequestsとかで各投稿ごとに詳細情報を取ってデータレイクにでもぶっこんでおこうという魂胆です。
MongoDBにでも突っ込んでおきます。
でどうやって取ってくるのかいうと、Seleniumと無限スクロールで取れました。
import selenium
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome('C:/selenium/chromedriver.exe')
driver.get('http://twitter.com/otnk23')
# 無限スクロールの部分
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
soup = driver.page_source
text = BeautifulSoup(soup,'html.parser')
# IDを抜く部分
_id_list = []
for tweet in text.select("div.tweet"):
_id_list.append(tweet['data-tweet-id'])
# リツイートによる重複を無くす
new_list = list(set(_id_list))
# ファイルに書き込み
for tweet in new_list:
with open ('otnk23_id.txt','a',encoding='utf-8') as f:
f.write(tweet+'\n')
f.close()
こんな感じで取れました。
自分のアカウントのURLと合成するので、多分リツイートが除外される、はず。。。
API経由だとパラメータで指定していた気がします。
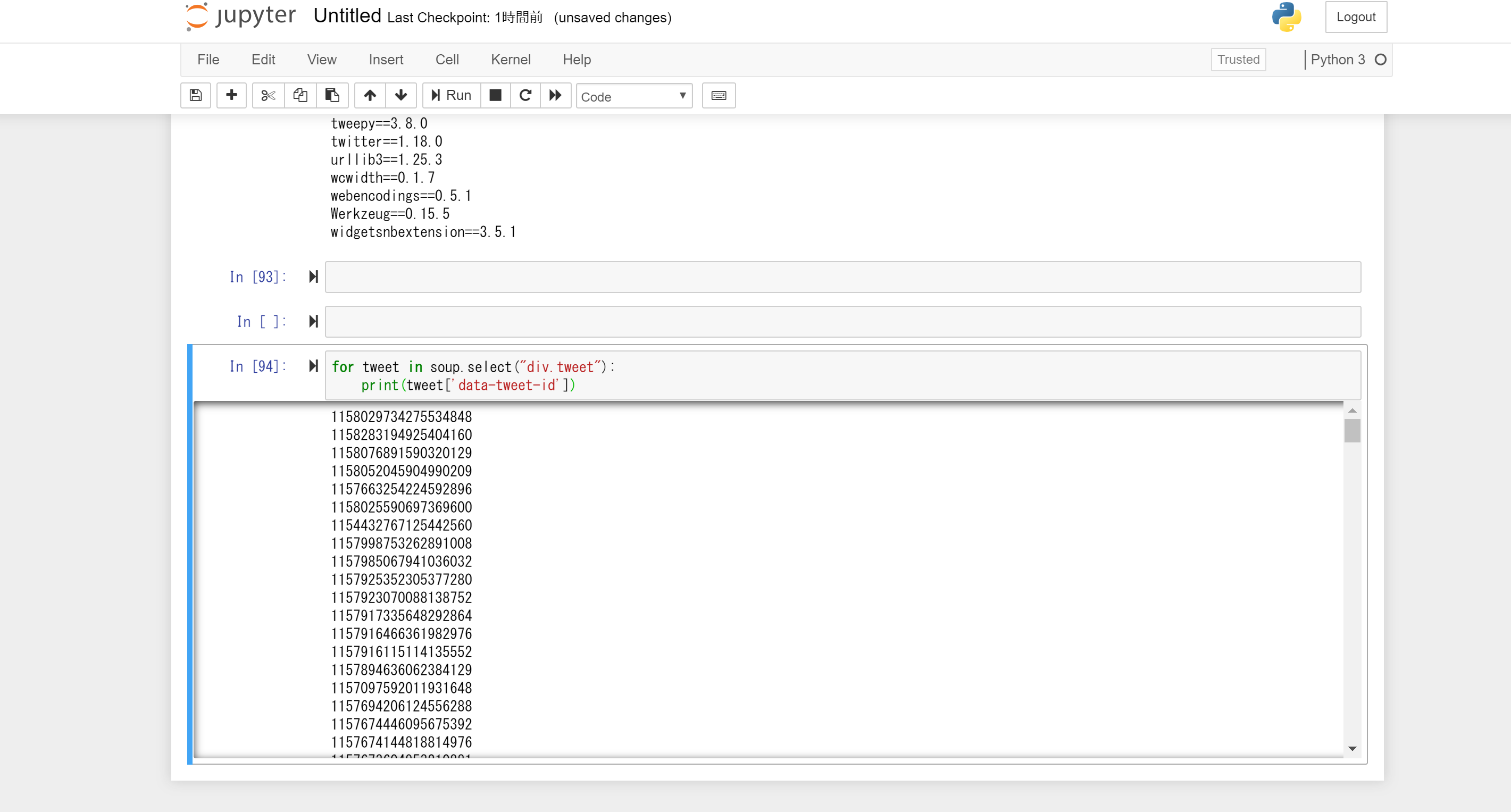
jupyter上で回したので、無限スクロール一回しか書いていないけど、本格運用するならwhileとtime.sleepかけてあげてください。
無限スクロールで参考にした記事
BeautifulSoupのとこで参考にした記事
seleniumで参考にした記事
後は、詳細情報を取ってCSVにでも吐き出しますだけですがが、お腹が減ったので次の記事に書きます。