記事の概要
単語誤り率4.3%(人間の認識エラー率は5.1%)を達成したIBMのThe Watson Speech to Text(以下STT)が、インターネットに接続せずに使用できる組み込みAIとして提供された。
そこで、カスタマイズされた言語モデルの認識信頼度の高さや、話者ラベルや周波数解析による背景音除去がもたらす認識信頼度の変化について、Webアプリを作成して試してみた。
本記事では、バックエンドで稼働させるSTTを作成する。
背景
2022年10月25日 IBMは、組み込み可能なAIソフトウェア・ポートフォリオの拡張を発表した。
IBM Watson Natural Language Processingライブラリー:意図(インテント)や感情(センチメント)から意味や文脈を解釈し、言語を処理する機能のライブラリー
IBM Watson Speech to Textライブラリー:迅速かつ正確な音声書き起こしを可能にするライブラリー
IBM Watson Text to Speechライブラリー:テキストをさまざまな言語や音声で正確かつ自然な音声に変換する機能のライブラリー
本製品は、組み込みAIであるため、インターネットに繋ぐことなく、より秘匿性の高いデータに対しても分析可能である。
例えば企業の企画に対して、SNSから取得したデータを用いて世論調査を実施することや、クレーム内容やレビュー内容と購入情報等のデータから商品開発も可能だろう。
また、2022年12月時点では、180日有効な試用ライセンスが提供されていることから、どのようなことが実施できるのか、試してみる。
(個人的には、スポーツ心理や人間工学研究において、音声のテキスト化及び自然言語分析は重要であるため、所属した板研究室の後輩に勧めている最中である。)
環境
自分のパソコンには、諸事情により導入することが出来なかったため、Linuxの仮想サーバーを立てた。仮想サーバーのスペックは以下の通りである。
cpu cores: 4
MemTotal: 8129000 kB
podman version 4.2.0
openjdk version "17.0.5" 2022-10-18 LTS
OpenJDK Runtime Environment (Red_Hat-17.0.5.0.8-2.el8_6) (build 17.0.5+8-LTS)
OpenJDK 64-Bit Server VM (Red_Hat-17.0.5.0.8-2.el8_6) (build 17.0.5+8-LTS, mixed mode, sharing)
Red Hat Enterprise Linux release 8.7 (Ootpa)
実施方法
こちらのGithubの手順に沿って実施する。
STT Client ApplicationとあるフロントエンドのWebアプリのセットアップと、STTが動作するバックエンドのDockerコンテナーのセットアップである。
Githubでは英語とフランス語の言語モデルを用いているが、本Qiitaでは、領域一般な日本語モデルと英語モデル、そして医療用にカスタマイズされた英語モデルを用いる。
フロントアプリでは、
- 領域特有の言語モデルと領域一般な英語モデルの比較
- ノイズキャンセリング
- 話者ラベルの付与
- 録音されたデータをフロントエンドのWebアプリからアップロードし、テキスト化
を実施する。
完成系は以下の通りである。
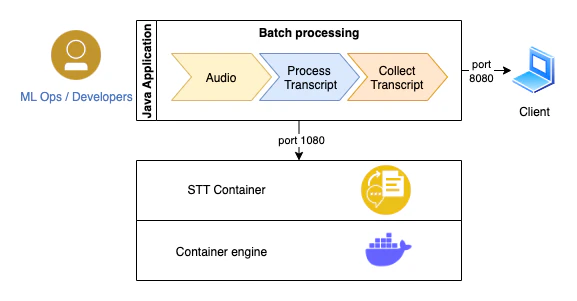
モデル別音声認識
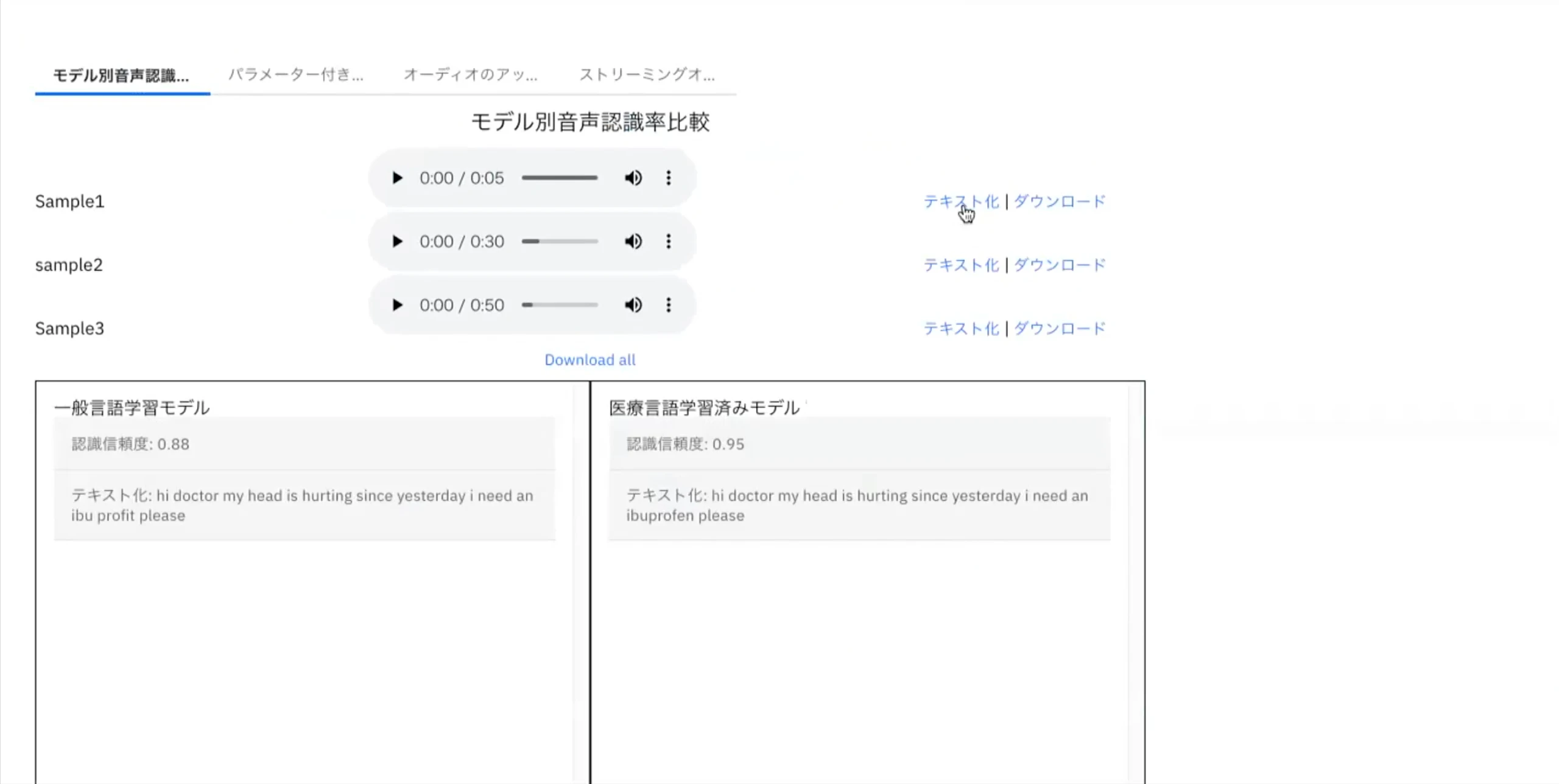
パラメータべ別機能

フロントアプリからデータのアップロード
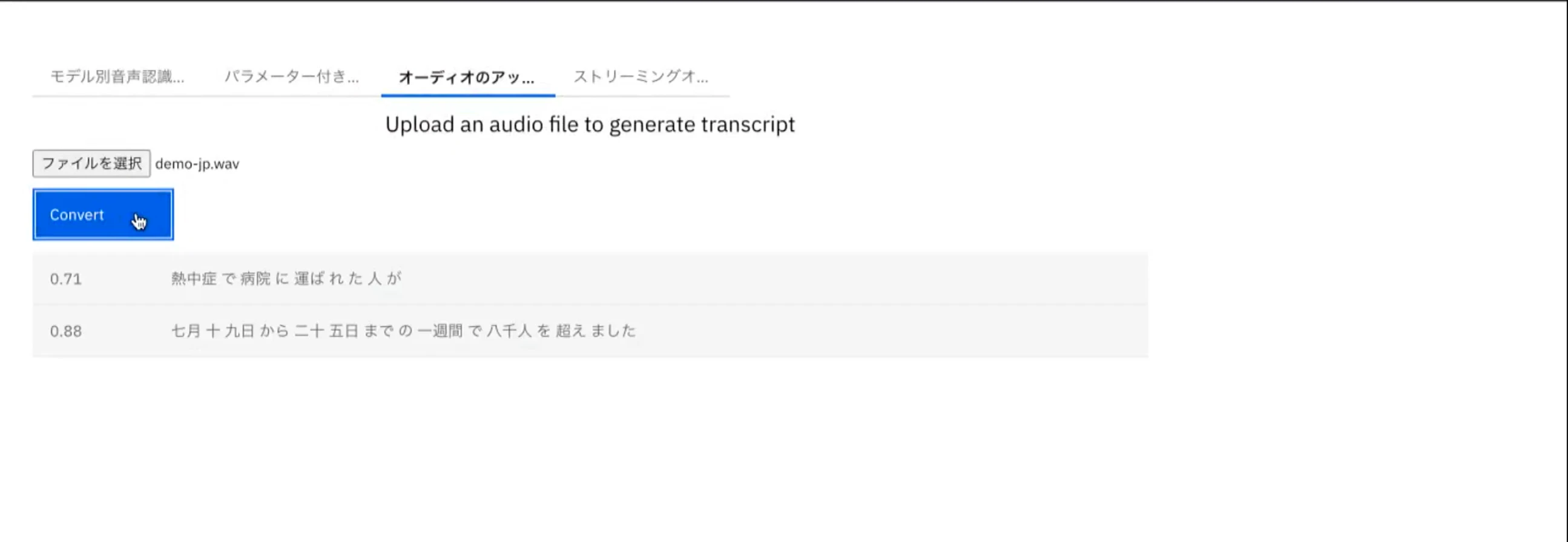
本編
STTが動作するバックエンドのDockerコンテナーのセットアップ
今回dockerコマンドの代わりにpodmanコマンドを使用するため、
alias docker=podman
IBM Entitled Registryにログインして、コンテナイメージをプルする。なお、IBM_ENTITLEMENT_KEYは、HPの「Start your free speech-to-text trial」から無料申請の後に、My IBMから取得可能である。
echo $IBM_ENTITLEMENT_KEY | docker login -u cp --password-stdin cp.icr.io
# Login Succeeded!
サンプルコードリポジトリのクローンを作成
git clone https://github.com/ibm-build-lab/Watson-Speech.git
# Cloning into 'Watson-Speech'...
# remote: Enumerating objects: 1026, done.
# remote: Counting objects: 100% (37/37), done.
# remote: Compressing objects: 100% (34/34), done.
# remote: Total 1026 (delta 14), reused 11 (delta 2), pack-reused 989
# Receiving objects: 100% (1026/1026), 61.43 MiB | 11.89 MiB/s, done.
# Resolving deltas: 100% (508/508), done.
サンプルコードを含むディレクトリに移動する。
cd Watson-Speech/single-container-stt
ls
# Dockerfile README.md chuck_var prepareModels.sh sample_dataset
以下のようになっていると正しい。
single-container-stt
├── Dockerfile
├── README.md
├── chuck_var
│ ├── env_config.json
│ ├── resourceRequirements.py
│ ├── sessionPools.py
│ └── sessionPools.yaml
└── prepareModels.sh
言語モデルの選定
現在のサンプルモデルでは、言語モデルが、英語とフランス語になっているため、医療用にカスタマイズされた言語モデルと日本語モデルに変更する。
使用できる言語モデルは、こちらのマニュアルから確認できる。
変更したファイルは、Dockerfile、env_config.json、sessionPools.yamlである。
# Model images
FROM cp.icr.io/cp/ai/watson-stt-generic-models:1.0.0 as catalog
# Add additional models here
FROM cp.icr.io/cp/ai/watson-stt-ja-jp-multimedia:1.0.0 as ja-jp-multimedia
FROM cp.icr.io/cp/ai/watson-stt-en-ww-medical-telephony:1.0.0 as en-ww-medical-telephony
FROM cp.icr.io/cp/ai/watson-stt-en-us-multimedia:1.0.0 as en-us-multimedia
# Base image for the runtime
FROM cp.icr.io/cp/ai/watson-stt-runtime:1.0.0 AS runtime
# Environment variable used for directory where configurations are mounted
ENV CONFIG_DIR=/opt/ibm/chuck.x86_64/var
# Copy in the catalog and runtime configurations
COPY --chown=watson:0 --from=catalog catalog.json ${CONFIG_DIR}/catalog.json
COPY --chown=watson:0 ./${LOCAL_DIR}/* ${CONFIG_DIR}/
# Intermediate image to populate the model cache
FROM runtime as model_cache
# Copy model archives from model images
RUN sudo mkdir -p /models/pool2
# For each additional models, copy the line below with the model image
COPY --chown=watson:0 --from=ja-jp-multimedia model/* /models/pool2/
COPY --chown=watson:0 --from=en-ww-medical-telephony model/* /models/pool2/
COPY --chown=watson:0 --from=en-us-multimedia model/* /models/pool2/
# Run script to initialize the model cache from the model archives
COPY ./prepareModels.sh .
RUN ./prepareModels.sh
# Final runtime image with models baked in
FROM runtime as release
COPY --from=model_cache ${CONFIG_DIR}/cache/ ${CONFIG_DIR}/cache/
{
"allowDashboard": false,
"anonymizeLogs": false,
"baseModelsSURL": {
"service": "localPath",
"urlSuffix": "var/catalog.json"
},
"clusterGroups": {
"default": {
"service_type": "speech-to-text",
"component": "runtime",
"group": "default",
"models": [
"ja-JP_Multimedia",
"en-WW_Medical_Telephony",
"en-US_Multimedia"
]
}
},
"defaultSTTModel": "ja-JP_Multimedia",
"defaultVerbosity": "DEBUG",
"meteringEnabled": false,
"requireCookies": false,
"setCookies": false,
"serviceDependencies": {
"baseModelsStore": {
"type": "UrlService",
"healthCheckSuffix": "/",
"baseUrl": "http://127.0.0.1:3333/"
}
}
}
defaultPolicy: DefaultPolicy
sessionPoolPolicies:
PreWarmingPolicy:
# UPDATE BELOW WITH MODELS USED
- name: ja-JP_Multimedia
- name: en-WW_Medical_Telephony
- name: en-US_Multimedia
以上のように変更後、ビルドする。
docker build . -t stt-standalone
# [1/6] STEP 1/1: FROM cp.icr.io/cp/ai/watson-stt-generic-models:1.0.0 AS catalog
# --> 56f1a98978a
# [2/6] STEP 1/1: FROM cp.icr.io/cp/ai/watson-stt-ja-jp-multimedia:1.0.0 AS ja-jp-multimedia
# --> bb473ae840a
# [3/6] STEP 1/1: FROM cp.icr.io/cp/ai/watson-stt-en-ww-medical-telephony:1.0.0 AS en-ww-medical-telephony
# Trying to pull cp.icr.io/cp/ai/watson-stt-en-ww-medical-telephony:1.0.0...
# Getting image source signatures
# Copying blob 7277a345802a skipped: already exists
# Copying blob b336a633f9e2 skipped: already exists
# Copying blob ce4f3aa04a2f skipped: already exists
# Copying blob 26f8eacd231d skipped: already exists
# Copying blob 5b989cea83ad skipped: already exists
# Copying blob d6e3788a121c skipped: already exists
# Copying blob bb556f886d1d skipped: already exists
# Copying blob 431e9e7a5a19 skipped: already exists
# Copying blob 8b25fb391a0e skipped: already exists
# Copying blob 47ba7e68ec14 skipped: already exists
# Copying blob 3a6eb1629a02 done
# Copying blob b59fd008ae67 done
# Copying blob 9459eab370ac done
# Copying blob 6705dd761fc1 done
# Copying blob 1c5abab5e06e done
# Copying config 55f4a92611 done
# Writing manifest to image destination
# Storing signatures
# --> 55f4a926110
# [4/6] STEP 1/4: FROM cp.icr.io/cp/ai/watson-stt-runtime:1.0.0 AS runtime
# [4/6] STEP 2/4: ENV CONFIG_DIR=/opt/ibm/chuck.x86_64/var
# --> Using cache 22d0c681e8e7f2a20411a81f6a661920dc7d8061a61c741f5f9f4cfa5c744343
# --> 22d0c681e8e
# [4/6] STEP 3/4: COPY --chown=watson:0 --from=catalog catalog.json ${CONFIG_DIR}/catalog.json
# --> Using cache 2c15cd1d71279c1dc94bb2581da4c7b640402422b5d17e473ed9b7d38bdfef96
# --> 2c15cd1d712
# [4/6] STEP 4/4: COPY --chown=watson:0 ./${LOCAL_DIR}/* ${CONFIG_DIR}/
# --> 4aee86a6c32
# [5/6] STEP 1/6: FROM 4aee86a6c32844066b37ad4d55519eb5cdef3628f7f95d967cd258875c0db080 AS model_cache
# [5/6] STEP 2/6: RUN sudo mkdir -p /models/pool2
# sudo: unable to send audit message: Operation not permitted
# --> d30509bf211
# [5/6] STEP 3/6: COPY --chown=watson:0 --from=ja-jp-multimedia model/* /models/pool2/
# --> 45d5313528b
# [5/6] STEP 4/6: COPY --chown=watson:0 --from=en-ww-medical-telephony model/* /models/pool2/
# --> ab1f1202373
# [5/6] STEP 5/6: COPY ./prepareModels.sh .
# --> e84a97c74cd
# [5/6] STEP 6/6: RUN ./prepareModels.sh
# 127.0.0.1 - - [15/Dec/2022 08:47:05] "GET /pool2/ja-JP_Multimedia.standard.2022-03-15.b93de56c.tar.pzstd HTTP/1.1" 200 -
# 127.0.0.1 - - [15/Dec/2022 08:47:05] "GET /pool2/ja-JP_Multimedia.low-latency.2022-03-15.12c54318.tar.pzstd HTTP/1.1" 200 -
# 127.0.0.1 - - [15/Dec/2022 08:47:05] "GET /pool2/spkInfo_16k.2020-10-08.895a1741.tar.pzstd HTTP/1.1" 200 -
# 127.0.0.1 - - [15/Dec/2022 08:47:05] "GET /pool2/en-WW_Medical_Telephony.standard.2022-03-15.14755af4.tar.pzstd HTTP/1.1" 200 -
# 127.0.0.1 - - [15/Dec/2022 08:47:05] "GET /pool2/en-WW_Medical_Telephony.low-latency.2022-03-15.ec853fee.tar.pzstd HTTP/1.1" 200 -
# 127.0.0.1 - - [15/Dec/2022 08:47:05] "GET /pool2/spkInfo_8k.2020-10-08.88e74eb8.tar.lz4 HTTP/1.1" 200 -
# <2022-12-15 08:47:06,286 src/global.cc:28> RD_INFO RAPID recognizer 5.4.0 (C) IBM Corp. 2015-2020 (git revision 4e52e03fe57718461388d29838b4d269bbd1fb91-modified )
# fatal: not a git repository (or any of the parent directories): .git
# fatal: not a git repository (or any of the parent directories): .git
# Model initialization complete
# Clean shutdown
# --> 3edc4b87e3d
# [6/6] STEP 1/2: FROM 4aee86a6c32844066b37ad4d55519eb5cdef3628f7f95d967cd258875c0db080 AS release
# [6/6] STEP 2/2: COPY --from=model_cache ${CONFIG_DIR}/cache/ ${CONFIG_DIR}/cache/
# [6/6] COMMIT stt-standalone
# --> da2ed7db155
# Successfully tagged localhost/stt-standalone:latest
# da2ed7db1553f671878fafaf356aa6d9c0fdecdb001906ed778af9ec811ca3d9
コンテナを実行
docker run --rm -it --env ACCEPT_LICENSE=true --publish 1080:1080 stt-standalone
実行されたSTTサービスの言語モデルを確認する。別のターミナルを開き、以下のコマンドを実行する。
実行が成功していれば、以下のように、設定した言語モデルが表示される。
curl "http://localhost:1080/speech-to-text/api/v1/models"
# {
# "models": [
# {
# "name": "en-WW_Medical_Telephony",
# "rate": 8000,
# "language": "en-WW",
# "description": "Global English Medical telephony model for narrowband audio (8kHz)",
# "supported_features": {
# "custom_acoustic_model": false,
# "custom_language_model": true,
# "low_latency": true,
# "speaker_labels": true
# },
# "url": "http://localhost:1080/speech-to-text/api/v1/models/en-WW_Medical_Telephony"
# },
# {
# "name": "ja-JP_Multimedia",
# "rate": 16000,
# "language": "ja-JP",
# "description": "Japanese multimedia model for broadband audio (16kHz or more)",
# "supported_features": {
# "custom_acoustic_model": false,
# "custom_language_model": true,
# "low_latency": true,
# "speaker_labels": true
# },
# "url": "http://localhost:1080/speech-to-text/api/v1/models/ja-JP_Multimedia"
# },
# {
# "name": "en-US_Multimedia",
# "rate": 16000,
# "language": "en-US",
# "description": "US English multimedia model for broadband audio (16kHz or more)",
# "supported_features": {
# "custom_acoustic_model": false,
# "custom_language_model": true,
# "low_latency": true,
# "speaker_labels": true
# },
# "url": "http://localhost:1080/speech-to-text/api/v1/models/en-US_Multimedia"
# }
# ]
注意点
コンテナを実行された際に、以下のようなエラーが出ることがある。
docker run --rm -it --env ACCEPT_LICENSE=true --publish 1080:1080 stt-standalone
Error: cannot listen on the TCP port: listen tcp4 :1080: bind: address already in use
どうやら以前コンテナで1080ポートで実行したまま、使用され続けている。この際にポートをkillしてもコンテナが生きたままになることがあるので、必ずコンテナを止める必要がある。
# ダメな例
sudo lsof -i -P | grep ":1080"
# conmon 221630 root 5u IPv4 4013664 0t0 TCP *:1080 (LISTEN)
sudo kill -9 221630
# 良い例
docker ps
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 9c175ef9b833 localhost/stt-standalone:latest /opt/ibm/chuck.x8... 56 minutes ago Up 56 minutes ago 0.0.0.0:1080->1080/tcp romantic_jang
docker rm --force 9c175ef9b833
参考記事
・ IBM、AIポートフォリオの拡張により、エコシステム・パートナーのAIの導入を加速
・IBM Helps Ecosystem Partners Accelerate AI Adoption by Making it Easier to Embed and Scale AI Across Their Business
・Announcement Letters