はじめに
こちらは以前記入したこちらの続きとなります。前々回はこちら。
さて、第一弾はデータの確認と特徴量の変換、つまり欠損値の穴埋め等。そして前回はfeaturetoolsを用いた特徴量の生成を行いました。そして今回はいよいよ機械学習をして提出します。
①で申し上げた通り、
説明変数(温度や曜日,メニュー名等) から 目的変数(お弁当の売上数)を予測してみましょう。
学習の準備
1.データの確認
復習ですが、これが前回までの段階で処理した状態のデータです。

これはtrainとtestを統合し、前処理を掛けたデータです。詳しくは前々回にて。
機械学習を行う際は統合したdatasを再度、train,testに分解します。
再度まとめますと…
- trainとtestデータの統合
- データの前処理
- trainとtestに分離。
このようなプロセスをたどります。このtrainとtestを統合/分離する際に接着剤が「カラムflg」です。
統合データの分解。 上記の3部分に当たります。
上記の③のデータの分解を行います。
# trainとtestにわける
train2 = datas3.query('flg == 1')
test2 = datas3.query('flg == 0')
queryメソッドを用いて、条件を指定しデータを抽出しています。
datasの中で、flg=1 であるものと flg=0 であるものををそれぞれ抽出して新たな変数に格納しています。
これが分割する前。
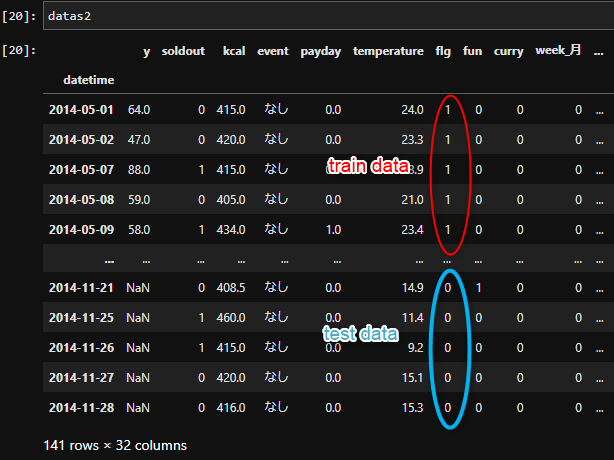
分割した後。
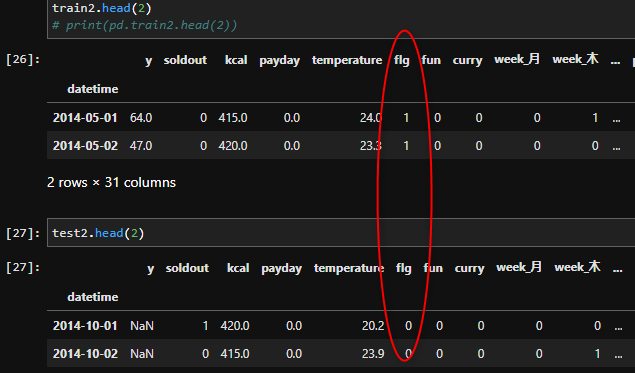
- flgはもう役割を果たしたのでdropしましょう。
train2 = train2.drop(columns = ["flg"])
test2 = test2.drop(columns = ["flg"])
- そしてtestデータの[y]カラムも削除しましょう。本来ないものですから。
test2 = test2.drop(columns = ["y"])
学習用にデータ分割
from sklearn.model_selection import train_test_split
train_X,test_X, train_y,test_y = train_test_split(
train2.drop('y', axis=1),
train2['y'], random_state=42)
これはtrainデータを4つに分割しております。
分割割合を確認して頂けると分かりやすいかも知れません。
train_X.shape,test_X.shape, train_y.shape,test_y.shape
参考画像も載せておきます。引用元
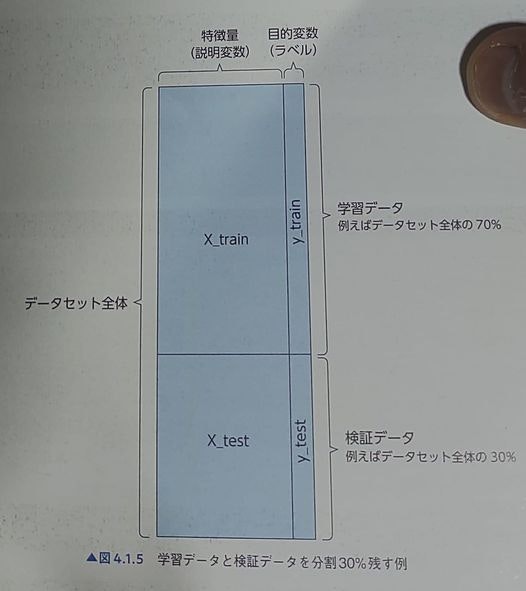
train_X: 機械学習モデル構築用の説明変数が格納されたデータ。
train_y: 機械学習モデル構築用の目的変数が格納されたデータ。 この2つで機械学習モデルを構築します。
test_X: その構築した機械学習モデルに取り入れて、pred(予測値)を算出数為の説明変数が格納されたデータ。
test_y: test_Xを元に予測したデータ(予測値)の模範解答となる目的変数。
予測値とtest_yがどの位乖離があるかで、学習モデル精度の指標となります。
実際の学習
いよいよ機械学習です。今回はTPOTというアルゴリズムを用いてみます。
TPOT:遺伝的プログラミングを用いて、機械学習モデルの選定やパラメータチューニングなどを自動で行ってくれるツールです。
詳細はこちら。
今回TPOTを用いた理由。
- ハイパーパラメータのチューニングの手間がない。(今回はデフォルト)
- 実行時間は気にしない。放置してもよい精度が出ればOK.
- 比較的操作が簡単。
実は他にも様々なアルゴリズムを模索しましたが、TPOTが一番良い成果が出ました。
# ライブラリのインポート
!pip install tpot #結構時間がかかります。
from tpot import TPOTRegressor
# TPOTのパラメータを設定⇒インスタンスを作成。
tpot = TPOTRegressor()
#TPOTにて機械学習。今回はTPOTデフォルトを使用します。
tpot.fit(train_X,train_y)
今回はTPOTのハイパーパラメータを設定しておりません。設定すると探索範囲を制限して時間短縮につながります。今回は時間に物を言わせて制限なしで挑戦しました。
TPOTは大量のパターンからじっくりと最適解を見つけるので、機械学習が大幅な時間がかかります。
私の場合は、googlecolabでは2時間30分経過しても達成できまず、jupyter labで一晩放置したら学習完了できておりました。
先に断っておきますが、上記は英語の公式マニュアルを見て私がそう理解したという事です。
私の考え違いならすみません。
機械学習の成果の確認。
学習ができたら精度を確認しましょう。
今回の精度はrmseです。小さいほど精度が良いのである程度の目安にはなるはずです。
# 予測
pred = tpot.predict(test_X) #先ほど学習したtPotを用いてtest_Xの機械学習をして予測値を出しております。
rmse = np.sqrt(mean_squared_error(test_y,pred)) #その予測値と答えを掛け合わせてrmseを算出しています。
print("rmseは",rmse)
#結果
#rmseは 13.180703690638085
私の感想で申し上げますと、このrmseは目安です。データ数が少なく過学習している事も多いです。
例えば、LightGBMでrmseを4が出ましたが、実際の提出時rmseは15とかでした。
提出。
機械学習と確認が済んだので提出します。
提出用の形式に矯正します。
testtime = pd.read_csv("C:/Users/user/Desktop/****/****/****/test.csv")
test = pd.read_csv("C:/Users/user/Desktop/****/****/****/sample.csv")
pred_submit = tpot.predict(test2)
先ほど構築したモデルtpotでtest2(前処理済テストモデル)のyの値を予測しています。これをsubmitという変数に格納しています。この予測したsubmitがどのくらい正解と近いかを提出して確かめます。
testtime["pred"] = pred_submit # testtimeに新たにpredという列ができる。
submit = testtime[["datetime","pred"]] # datetimeとpred列だけを残したものをsampleとする
submit2= submit.rename(columns={'datetime': 0, 'pred': 1}) #カラム名をサンプル通りに適合します。
submit3 = np.round(submit2,0) #小数点を丸めます。
submit3[1] = submit3[1].astype('int') #型をint型直します。
submit3.head(5) #これが提出のイメージです。
submit3.to_csv("C:/Users/user/Downloads/tpot(2).csv",index=False)
ファイル格納場所、そしてファイル名を記入します。
それではこちらから提出してみましょう。
以上お疲れさまでした。
まとめや考察。
- featuretoolsとTPOTというあまり聞き覚えのないもモジュールとアルゴリズムを用いて回帰予測を行いました。背景として今回これを用いてよい精度を出す、というよりむしろ、簡単に良い精度を出す為にはどうすればよいか?と模索していたらこの手段にたどり着いた印象。
- 双方とも認知度の低さから、資料は少なく公式のマニュアルを読んで進めなければならない。しかし、それに見合った有用性は確認できた。
- TPOTは簡単に良い精度を算出する事ができました。ハイパーパラメータチューニングもデフォルトが強いので使い勝手がよさそう。
今回の収穫、次回試したい事
- featuretoolsを用いて大量の特徴量を生成。そして特徴量の重要度選別やアルゴリズム選択はTPOTが行ってくれる
- このコンボで労力からお釣りが出るくらいには良い精度を算出することができた。
- 懸念点としては大幅な時間がかかる事。今回は元のカラム数も相当少ないが、それでも一晩程度の実行時間は要した。
- 今回はうまく行ったが、次回は更に大量の特徴量を生成して、TPOTのハイパーパラメータチューニングも深堀して実装してみたい。
- 今回は回帰だが、分類ではどのように発揮されるかも機会があれば試してみたい。
2021~2022年の情報で、featuretoolsとTPOTに関してまとめているサイトはごく少数です。featuretoolsに関しては記載方法が大きく変更したので、2022年に英語マニュアルに慣れていない筆者にとっては取り入れるのが大変でした。私と同じように英語マニュアルを読むことが億劫に感じる方々の助けになればと思います。
参照