TL;DR:
AI がコードを書ける時代に、「誰がそのコードを本番に入れるか」という問いはまだ答えが出ていない。技術的には AI 自身が PR をマージできるツールが存在するが、それはコードレビューの独立性を根本から壊す。「Human が最終マージする」という概念は広まりつつあるが、「実装者と審査者を別のモデルに分けて、かつその役割分離をポリシーとして明文化する」という一歩先の実践は、2026年時点でも公開事例がほとんどない。この記事は、その問いを整理し、私たちがどう答えを実装したかを記録する。
AI がコードを書く時代になった。GitHub Copilot は補完から実装まで担うようになり、Devin は「AI ソフトウェアエンジニア」を名乗り、Claude Code は terminal からリポジトリを操作する。PR を作るのは、もう人間だけではない。
だが、そこで一つの問いが静かに浮かび上がる。
誰が、その PR を本番に入れる判断をするのか。
この問いへの答えは、ツールの進化速度に比べて驚くほど遅れている。
コードレビューとは何のためにあるか
コードレビューの目的を一言で言えば、実装者の視野の外にあるリスクを捕捉することだ。
実装者はコードの意図を知っている。だからこそ、意図に合致しない挙動に気づきにくい。バグは多くの場合、「こう動くはずだ」という前提の陰に隠れている。
レビュアーは意図を知らない分、コードをコードとして読む。そこに独立性の価値がある。
この前提が崩れる状況がある。実装者が審査者を兼ねるときだ。
財務の世界では、これは利益相反として制度的に禁止されている。論文査読では、著者が自分の論文を審査することはない。医療の倫理審査では、当事者が自分の研究計画を承認することはない。
コードレビューも同じ構造を持っている。変更を加えた人物が、その変更の安全性を判断する唯一の人物であってはならない。
そして今、この利益相反が AI の文脈で起きうる状況が生まれている。
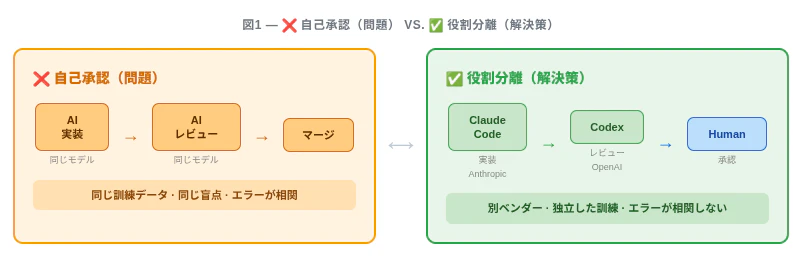
AI の自己承認が起きると何が起きるか
AI モデルが実装した PR を、同じモデル(または同じファミリーのモデル)がレビューすると、次の三つの問題が起きる。
① 訓練データのバイアスが共有される。 同じモデルファミリーは同じデータで訓練されている。あるパターンを「正しい」と学習していれば、実装でも採用し、レビューでも問題視しない可能性が高い。
② 実装時の文脈がレビューに持ち越される。 実装時の判断がそのままレビュー時の前提になる。人間でも「書いた人が自分でレビューする」と甘くなるのと同じ傾向だ。
③ エラーが相関する。 独立した二者が同じ間違いを犯す確率は、同じ一者が二回確認する場合より低い。Anthropic の Claude Code Review は、複数サブエージェントが並列でレビューする構成でカバレッジが 16% から 54% に向上したと報告されている(出典)。独立性には、測定可能な価値がある。
業界は今どこにいるか
「Human が最終マージを承認する」という運用は、主要ツールの設計に徐々に組み込まれてきた。だが、「広まりつつある」と「ルールとして文書化されている」は違う。
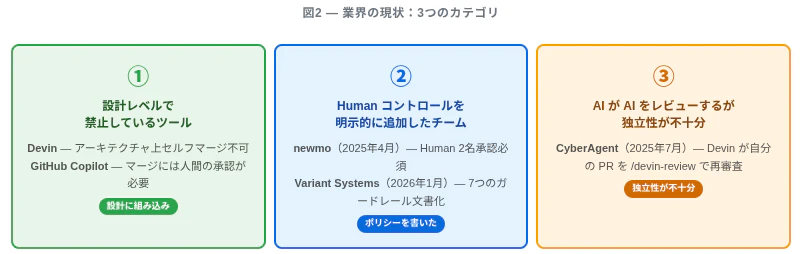
業界の事例は三つのカテゴリに分けられる。
① 設計上セルフマージを禁じているツール
Devin は設計上、自分では PR を self-merge できない仕様になっている(出典)。Copilot Coding Agent は PR を作るが、マージは人間が承認する(出典)。
② Human ブランチ保護ルールを追加したチーム
newmo は Devin が作った PR に対して「Human 2名の承認が必須」という branch protection を設定した(2025年4月)(出典)。このブログ記事の文体は示唆的だ——「当然やっていること」として書かれているのではなく、「こう設定しないと危なかった」という経験として記録されている。Variant Systems は 7 つのガードレールを文書化した(2026年1月)(出典)。
③ AI が AI をレビューするが独立性が不十分なケース
CyberAgent は Devin が自分の PR を /devin-review コマンドで再審査するワークフローを本番導入した(2025年7月)(出典)。「AI によるレビュー」の公開事例として最も近い構成の一つだが、実装した Devin がレビューもしている——独立性は確保されていない。
合理的な反論として: すべての PR にこの水準のガバナンスが必要か?当然違う。依存関係の自動更新や typo 修正にパイプラインは不要だ。ここで論じているのはデフォルト——誰も例外を明示していない変更についてのルールだ。
一歩先の問い:誰がレビューするか
「Human が最終マージする」は、ガバナンスの入口だ。だがもう一つ問いがある。マージ前の AI レビューを、誰が担当するか。
クロスベンダーの AI レビューはすでに実践されている。OpenAI Codex の Claude Code 向けプラグイン(2026年3月リリース)は、一方のエージェントが実装し別ベンダーがレビューするパターンを公式にサポートしている。
一方で、2026年時点の調査では、クロスベンダーレビューを組織ポリシーとして明文化した公開事例はほぼ確認できなかった。実践は広まっている。ポリシー化はほぼない。
これが埋めるべきギャップだ。
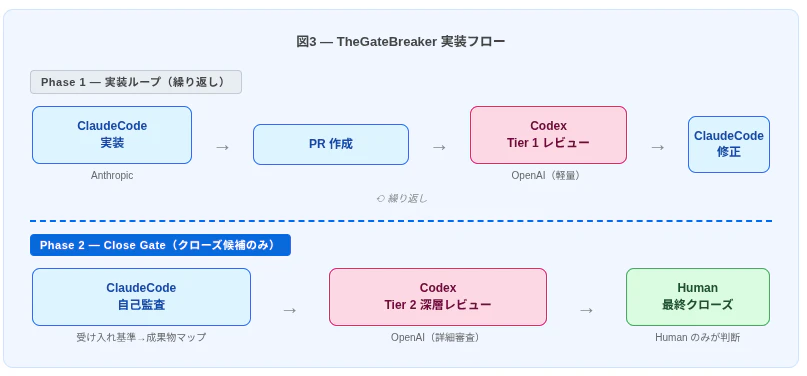
TheGateBreaker での実装
TheGateBreaker は、複数の AI ワーカーを GitHub Issues と Pull Request を通じて調整するワークフローの実験リポジトリだ。Human が最終的な意思決定者として機能する。この記事で論じているガバナンスパターンの動作中のテストベッドとして位置づけている。
私たちのリポジトリでは、この運用ポリシーをバージョン管理されたドキュメントとして保持している。
- 実装: ClaudeCode(Anthropic)
- 独立レビュー: Codex(OpenAI のクラウドコーディングエージェント)
- 最終クローズ判断: Human
重要なのは、これが口頭の慣習ではないことだ。リポジトリの設定ファイル(AGENTS.md と CLAUDE.md)に明文化されたポリシーとして存在している。ClaudeCode が自分の実装を自分でレビューすることはない。Codex が実装することもない。役割は意図的に、かつ記録として分離されている。
これが唯一の正しいアーキテクチャだとは主張しない。ClaudeCode と Codex だけが担当できるわけではない。重要なのは、実装・レビュー・最終承認が別々の役割として、例外が起きる前に書かれていることだ。
なぜ「当然」が危ない
「AI が実装したものを AI がレビューして AI がマージするのは危険」——今の開発者の多くは直感的にわかっている。だからこそ、多くのチームは自然とそういった運用を避けている。
問題は、「避けている」と「ポリシーとして決めている」の差だ。
チームメンバーが変わったとき、新しいツールを導入したとき、急いでいるとき——例外が生まれる。例外が慣習になる。慣習が問題になるまで見えない。
ルールを書くことは制約ではない。プレッシャー下でも誰もが「当然のこと」を覚えていると期待せずに、チームが速く動ける構造だ。
問いとして残るもの
Human final merge は広まりつつある。だが、以下はまだ多くのチームで答えが揃っていない。
- 実装者と審査者を別モデルにする、という判断をどこに記録するか
- どのモデルがどの役割を担うかを、慣習ではなくポリシーとして書いているか
- AI レビューが通れば Human は実質的に rubber-stamp になっていないか
- レビューの独立性のために、ベンダーの多様性は必要か
「当然のこと」には、記録が残らない。記録が残らないことは、次の人が同じ問いを一から考え直すことを意味する。
だから書く。
AI コーディングエージェントを、人間の説明責任レイヤーを迂回させずに活用するための実践的なノートを続けていきます。フォロー・購読をお待ちしています。
