TL;DR:
AIワーカーが毎回同じボイラープレートコードを書き直しているなら、得ているのは知能ではなく繰り返し料金だ。描画ロジックをツールに固定し、AIにはJSONコンフィグだけを書かせることで、図1枚あたりのトークン消費が71%削減された(Anthropic APIのusageフィールドで実測)。ただしこの数字は狭い条件下のものだ——繰り返し・低推論・浅いスキーマのタスクに限られ、測定方法自体が本番環境より高めに出ている可能性がある(詳細は後述)。加えて、パターン2を全図に均一適用すると視覚的単調さが生まれたため、記事固有のシグネチャー図1枚だけはパターン1に戻すハイブリッド方式も採用した。
気づいたきっかけ
記事を作るたびに、AIワーカーはPILスクリプトをゼロから書いていた。フォント読み込み、座標計算、カラー定数、角丸矩形、テキスト折り返し——すべて込みのPythonファイルを毎回まるごと生成していた。
出力される図は同じ。ロジックも同じ。なのに毎回1,000トークン近くを、前回すでに書いて捨てたボイラープレートに費やしていた。
気づいたのは人間のほうだった。「トークン消費が激減した」——新しい方式に切り替えた後に出た言葉で、これが外部検証になった。
問題の構造
AIにコードを書かせること自体が間違いではない。毎回同じコードを書かせることが間違いだ。
実際にバリエーションがあった部分——記事タイトル、行ラベル、色の選択、テキスト内容——はスクリプト全体の約20%だった。残り80%は変わらない構造ロジックだ。その80%を毎回払い続けていた。
毎回書き直しているものの何%が構造的ボイラープレートか——それが最初に確認すべき指標だ。
実装:変わるものと変わらないものを分ける
MVCの関心の分離をそのまま適用した:
- Model = コンテンツデータ(記事ごとに変わる部分)
- View/Renderer = PIL描画ロジック(変わらない部分)
描画側を tools/gen_article_figs.py として一度書いてリポジトリに固定する。以降AIワーカーはJSONコンフィグだけを書く。
{
"type": "role_matrix",
"output": "fig1_pattern_comparison",
"lang": "ja",
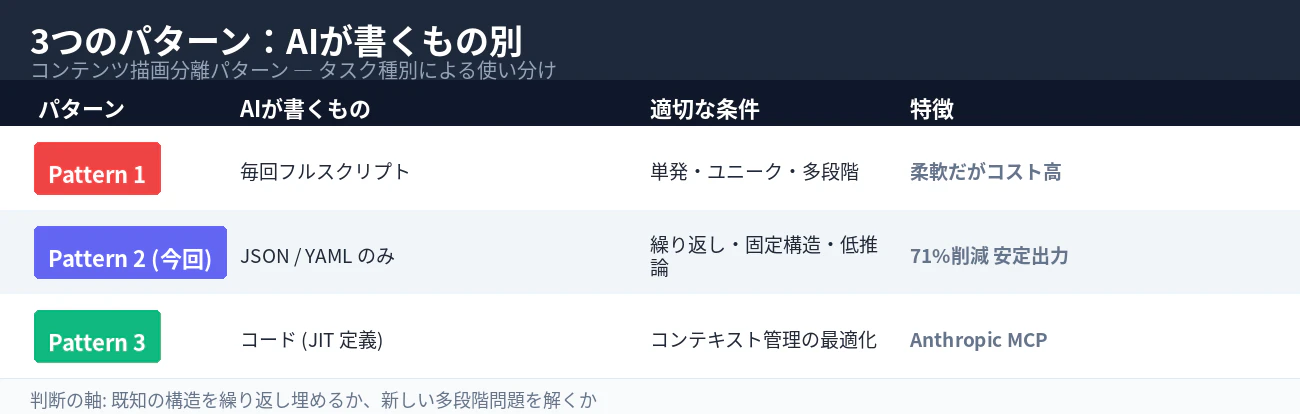
"title": "3つのパターン:AIが書くもの別",
"columns": ["パターン", "AIが書くもの", "適切な条件"],
"rows": [
{"name": "Pattern 1", "color": [239, 68, 68], "cols": ["毎回フルスクリプト", "単発・ユニーク"]},
{"name": "Pattern 2", "color": [99, 102, 241], "cols": ["JSON / YAML のみ", "繰り返し・固定構造"]},
{"name": "Pattern 3", "color": [16, 185, 129], "cols": ["コード (JIT 定義)", "コンテキスト最適化"]}
]
}
python tools/gen_article_figs.py fig_config_ja.json
実測結果(Anthropic API usage フィールドで計測、claude-haiku-4-5-20251001):

{
"OLD (full PIL script)": { "input": 415, "output": 2691, "total": 3106 },
"NEW (JSON config only)": { "input": 377, "output": 522, "total": 899 },
"reduction_pct": 71.1
}
追加効果: gen_article_figs.py のバグ修正が過去・未来の全記事に自動伝播する。
3つのパターン、2つではない
| パターン | AIが書くもの | 特徴 |
|---|---|---|
| 1. 毎回コード生成 | フルスクリプト(毎実行) | 柔軟だがコスト高 |
| 2. データのみ生成 | JSON/YAML | 71%削減・安定出力 |
| 3. 動的ツールローディング | コード(JIT定義読み込み) | Anthropic MCP: 98.7%削減 |
パターン3は「AIが書く量を減らす」のではなく「未使用ツール定義をプロンプトに注入しない」最適化だ。コンテキスト管理の問題であって、生成量の問題ではない。
CodeAct論文(Wang et al., ICML 2024)が示す境界:
- API-Bank(単発ツール呼び出し): JSON競合(GPT-4: JSON 82.7% vs CodeAct 76.7%——ただしこれはタスク成功率の指標であり、トークンコストの指標ではない。示しているのは「固定スキーマタスクにJSONで対抗できる」ことであって「安い」ことではない。コストの主張はこの記事独自の実測に基づく)
- M3ToolEval(複数ツール×複数ターン): CodeAct が +20pp、ターン数 30%減
判断の軸: 既知の固定構造を繰り返し埋める→パターン2。新しい多段階問題を解く→CodeAct。
この3パターンは理想型であり、互いに排他的な実装ではない——実際のシステムは複数を組み合わせられるし、私たちの場合もそうだった。パターン2が解決するのは繰り返しのコストであり、編集上のすべてのニーズを解決するわけではない。図が単なる比較表ではなく記事固有の主張を担う場合には、この違いが効いてくる。その隙間に後で行き当たることになる——後述のハイブリッドアプローチを参照。
複利効果の計算
パターン1のコスト = (固定ロジックトークン + コンテンツトークン) × 実行回数
パターン2のコスト = 初期セットアップコスト + コンテンツトークン × 実行回数
4枚の図×10本の記事:
- パターン1: 3,106 × 4 × 10 = 124,240 tokens
- パターン2: 899 × 4 × 10 = 35,960 tokens(88,280 tokens節約)
この試算は1回の実測を多数の実行・複数の図種別に外挿したものであり、方向性を示す目安であって保証ではない。次のセクションで、実際に擁護できる範囲を絞り込む。
これが長期になるほど効いてくる。運用期間が長くなるほど、削減は積み上がっていく。
71%という数字の限界
71%は、単一の図種別における1回の初回成功生成を、Input文脈が極めて薄い2つの独立プロンプト(それぞれ415・377トークン)で測定した数字だ。これが最大の注意点であり、率直に言っておく: 以下の要因のうち、現時点で定量化できているのは1つだけだ。残りは今回のタスクには明示的に非適用か、まだ顕在化していないリスクにすぎない。
1. Input文脈の希薄化(上記71%には未反映)
今回のテストプロンプトは孤立していた——記事本文の文脈、システムプロンプト、会話履歴を一切含まない。実際のAIワーカーのセッションでこのJSONコンフィグを生成する場合、記事草稿・それまでのやり取り・ツール定義など、はるかに多いInput文脈を伴う。Inputトークンはパターン1・パターン2でほぼ同じ大きさになる(縮むのはOutputだけ)ため、共有Input文脈が増えるほど、削減率全体は薄まる。試算: 共有Inputが約400ではなく約5,000トークンだとすると、同じOutput数値(2,691 vs 522)でも合計コストは7,691→5,522トークンとなり、削減率は28%——71%ではない。実際の本番での数値は、呼び出しごとの文脈量次第で28%〜71%のどこかに収まる。
2. リトライオーバーヘッド(定量化可能・小さい)
スキーマバリデーション失敗率2%、リトライプロンプトが元の1.5〜2倍とすると、フリート全体で+6〜12%のオーバーヘッドが、どの基準値にせよ上乗せされる(Tianpan 2026)。
3. 容量依存のフォーマット税(今回は非適用)
Fan (2026)「Capacity, Not Format」(arXiv:2606.09410)は、小規模モデル(Haiku)が推論負荷の高いタスクで**-36pp以上**の精度低下を起こすと記録している。図コンフィグ生成はスロットフィリングであり推論ではないため、この税は今回の測定には適用されない可能性が高い——他の用途への境界条件として提示しているのであって、今回の数字への割引ではない。
4. スキーマ複雑度の崩壊(将来リスク・現在のリスクではない)
JSONSchemaBench(Geng et al., arXiv:2501.10868): 4レイヤー超のネストやanyOf/oneOfを使うスキーマでの制約付きデコーディングカバレッジはOutlinesで3%、OpenAI Strictで9%まで崩壊する。現在のスキーマはフラットだ。これはツールが成長した場合のリスクであり、今日の数字への割引ではない。
率直に言えば: 71%は、私たちが測定した狭い条件については本物だ。現時点で明確に擁護できる本番環境での割引はリトライオーバーヘッドだけだ。Input文脈の希薄化のほうが大きな未知数であり、環境によってはこのセクションの他のすべての要因を合わせたより効くかもしれない。**55〜65%**を作業上の推定値としているが、これは下限ではなく緩やかな目安として扱ってほしい。
パターン2が使えない6つの条件

| 条件 | 適切な選択 |
|---|---|
| ステップ間で状態を持つマルチステップ合成 | CodeAct / パターン1 |
| 出力語彙が未知・無限(事前列挙不可) | CodeAct |
| スキーマが4レイヤー超・anyOf/oneOf | CodeAct(制約デコーディング崩壊) |
| 小規模モデル + 非自明な推論 | 自由推論 → 後フォーマット |
| スキーマが急速進化(数週間で新プリミティブ) | CodeAct(マイグレーションリスク) |
| 一回限りのユニークタスク | CodeAct |
注意(アンチパターン): ロジックのデータフィールドへの流出
スキーマが硬すぎると、モデルはフリーテキストフィールドにロジックを詰め込む:
"label_text": "{{ compute_from_parent if parent else 'N/A' }}"JSONとして有効、分離の原則は破壊済み。スキーマがタスクを超えたシグナルだ。
先行事例との比較
独自発見と主張する前に、Perplexityでディープリサーチを走らせた。
パターン自体は存在する:
- Hrynkow (2025)「AI Generates Configuration, Not Code」: 「AIにはデータを生成させ、振る舞いではなく」。スキーマ駆動プラットフォームでAIがJSONを生成し、汎用UIが描画する。
- 「LLM-MVC」 (data2day 2024): ViewレイヤーをLLMなしの静的テンプレートで処理する明示的なMVC分離。
- Anthropic「Building Effective Agents」 (2024): 「出力フォーマットによっては、LLMが書くのが著しく難しいものがある」——これは一般的なエンジニアリング指針であり、特定のパターンを推奨しているわけではない。
トークン削減の数字も別の文脈で存在する。AnthropicのMCP Code ExecutionブログはツールをJITで読み込む方式で150,000→2,000トークン(98.7%削減)を報告している。CodeAgentsの論文(arXiv:2507.03254)は構造化プロンプトで入力トークン55〜87%削減を3つのベンチマークで示している(削減メカニズムが本記事と同一とは限らない——参照点として引用)。
文書化されていなかったこと: 繰り返しAIワーカー運用の文脈での実測だ。
パターンの進化: シグネチャー図
パターン2を複数記事で運用していくと、新たな問題が浮かんできた: 視覚的単調さだ。記事を重ねるにつれて、全図が同じフォーマットに収束していく。
パターン2がすべてを解決すると証明するつもりはなかった。パターン2が解決するのは繰り返しのコストであり、図がそれ自体の主張を語らなければならない場面の代わりにはならない。それは最初から分かっていた境界ではなく、実際にぶつかって見つかった境界だ。実務的な対応は撤退ではなく再配分だった: 標準図(比較表・測定チャート)で浮かせたトークンを、記事固有の主張を担う1枚——シグネチャー図——に投じる。
本番投入する前に、3つの実装課題を先に潰す必要があった: パストラバーサル(スクリプトがワークスペース外のファイルを参照できてしまう)、サイレント失敗(エラーでも終了コード0を返す)、タイムアウト無し。これらを修正した上で、gen_article_figs.py に "type": "custom" エスケープハッチを実装した:
{ "type": "custom", "script": "fig_signature.py", "output": "fig4_signature" }
AIワーカーが fig_signature.py(パターン1のフルスクリプト)を書き、ツールがsubprocessで呼び出す。コマンドは1つのまま。
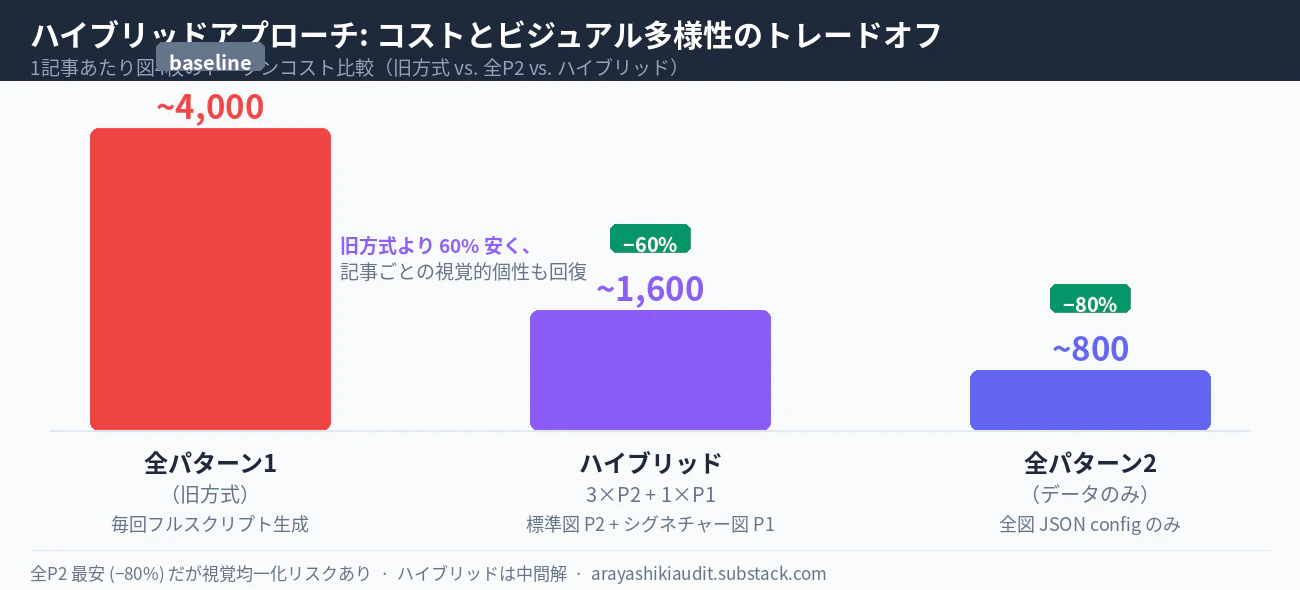
トークンコスト比較(図4枚):
| アプローチ | トークン | 旧方式比 |
|---|---|---|
| 全パターン1(旧) | ~4,000 | − |
| 全パターン2 | ~800 | −80% |
| ハイブリッド 3×P2+1×P1 | ~1,600 | −60% |
ハイブリッドは全パターン2のコストをほぼ倍にするが、旧方式より60%安いままで、記事ごとの視覚的個性を取り戻せる。
まだわかっていないこと
品質のスケール保証: 「出力品質: 同一」は一人の人間による小サンプル観察。Tam et al. (EMNLP 2024)とFan (2026)は大規模では系統的バイアス(数値の丸め方向への引力、フィールド間の不整合)が蓄積すると記録している。
汎化: メールHTML、レポートレイアウト、スライド構成への適用は仮説段階。71%は単一タスク種別の測定。
Content-Rendering Separation Pattern
先行事例の呼び名は「AI Generates Configuration, Not Code」「LLM-MVC」「Model-Driven Prompting」と重なっているが統一されていない。いずれも繰り返しワーカーという文脈を扱っていない。
私たちはこれを Content-Rendering Separation Pattern(コンテンツ描画分離パターン) と呼ぶ:
レンダラーをツールに固定し、AIにはコンテンツパラメータだけを書かせる
新しいアイデアではない。MVCは50年前からある。新しいのは、AIワーカー運用に意図的に適用し、削減量を実測し、複利効果を認識し——失敗条件を文書化することだ。
AIワーカーを繰り返しタスクで運用しているなら、毎回書き直しているものの何%が構造的ボイラープレートかを確認することが、最初に調べるべき場所だ。もっと難しい問いは、あなたの出力のうちどれが標準図(繰り返しで構造的)で、どれがシグネチャー図(全力投資に値する)なのかを見極めることだ。
AI Worker OS シリーズ — 第3回
第1回: AIに自分のプルリクエストをレビューさせてはいけない理由
第2回: GitHubをAIワーカーOSとして使う

