Skylakeマイクロアーキテクチャの種類
Intel Skylakeマイクロアーキテクチャには2種類あり,Coreシリーズなどに実装されている「クライアント」構成と,Xeonシリーズなどに搭載されている「サーバ」構成に分かれています.
後者のサーバ構成はAVX-512命令セットに対応しています.
AVX-512は512ビット幅のSIMD命令セットで,256ビット幅のAVX・AVX2命令セットと比較してビット幅が増え,演算・操作の種類も増えています.
マイクロアーキテクチャの細かな仕様はWikiChipが詳しいです:クライアント構成,サーバ構成
クライアント構成でのAVX命令の実行
クライアント構成では実行ポート0番・1番・5番それぞれでAVX命令が実行されます.
下図はChester Lamによる,Chips and Cheeseのこちらの記事から引用しました.
ポート番号の記載はありませんが,Execution Engine内の左から3列が0番・1番・5番ポートに相当し,それぞれが256ビット幅の演算器となっています.
![]()
サーバ構成でのAVX-512命令の実行
サーバ構成の方の演算器構成が下図です.
図はJohan de GelasとIan Cutressによる,AnandTechのこちらの記事より引用しました.元々はIntelによるスライドのようです.
サーバ構成では256ビット幅の0番・1番ポートが協調して動作することで512ビット幅のAVX-512命令を実行します.
これに加え,クライアント構成で256ビット幅であった5番ポートが512ビットに拡張され,AVX-512命令を実行できるようになっています.

AVX・AVX-512ユニットの物理的構成
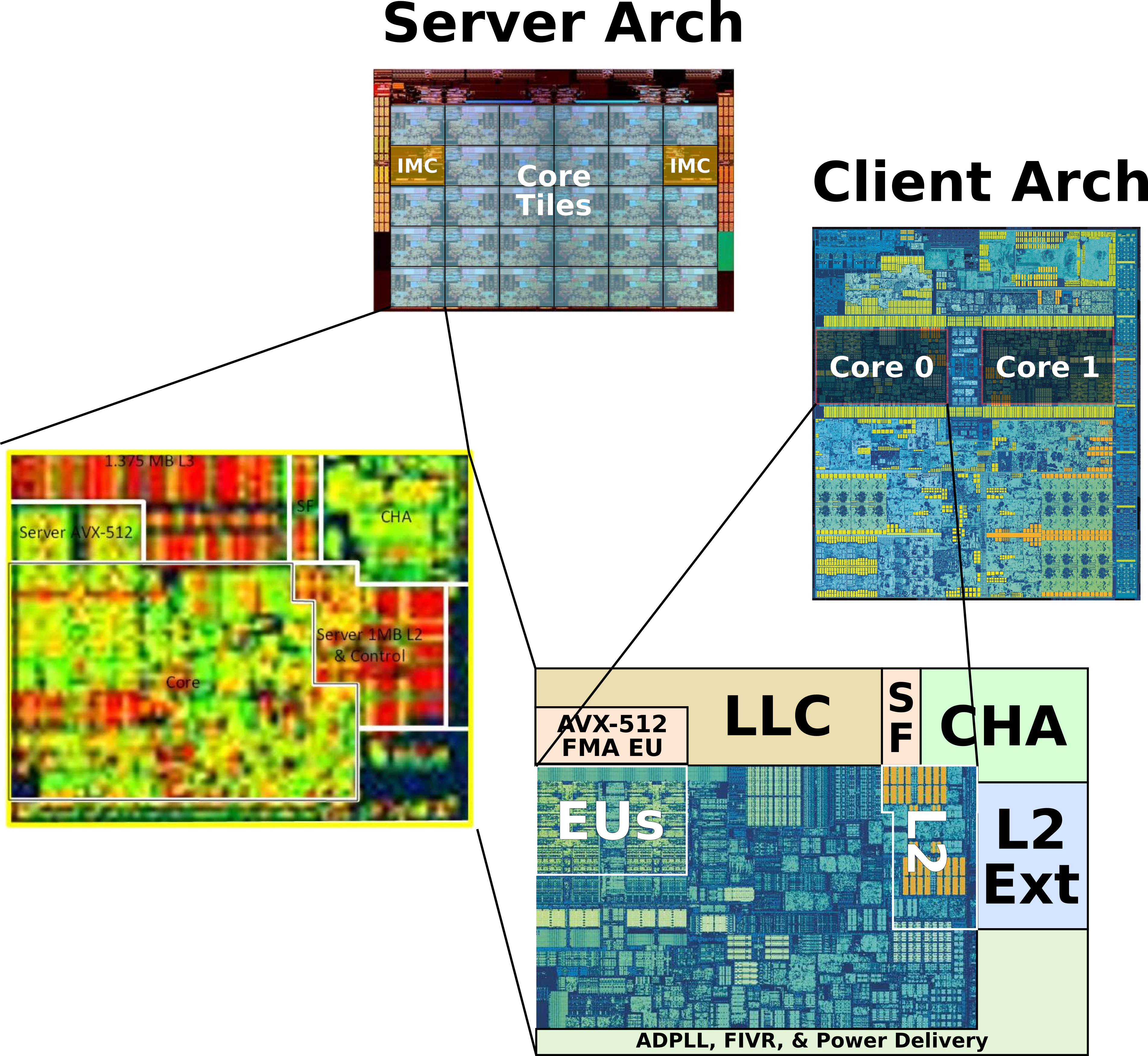
実は物理的にも,サーバはクライアントのチップ構成を拡張したものとなっています.
下図はWikiChipのこちらのページから引用した,クライアントとサーバのダイの写真です.
右図のクライアントでは各コアの上にL3キャッシュ(黄色の短冊)が全体的に配置されていますが,左図のサーバではこのL3キャッシュの一部分がAVX-512ユニットに置き換えられています.
その証左として,チップ上のすべてのコアが有効になっている場合だと,クライアント構成ではコアあたり2 MiB,サーバ構成では1.375 MiBのL3キャッシュ容量となっており,サーバの方がL3キャッシュが小さいです.
下図はLocuzaさんのポストです.
クライアントとサーバとで物理的な共通部分は多いものの,全てのユニットか同一というわけではないそうです.
Based on Skylake, w/o 2nd 512b FMA and extra registers, the overhead (orange) could be ~33% for the FPU.
— Locuza (@Locuza_) April 28, 2023
That should be manageable, especially when the number of "downported" VEX instructions would increase.
Of course, asymmetric ISA support on the SW level would be nice too. pic.twitter.com/SECoji7fVi
この図で,各コアの左側のxmm・ymm・zmmと書かれている箇所がAVX・AVX-512のSIMDレジスタです.
そのすぐ上に0番・1番ポートが配置されています(黄色の箇所にのみVec EUsと書かれていますが,橙色の箇所と黄色の箇所を合わせて0番・1番・5番ポートなのだと思われます).
右図のサーバ構成ではこの上方向に5番ポートが拡張されることとなります(緑色の箇所).
物理的構成による演算性能への影響
前節をまとめると,クライアント構成でもサーバ構成でも「レジスタ → 0番・1番ポート → 5番ポート」と物理的に並んでおり,5番ポートはレジスタから物理的に遠くに位置することになります.
この物理的距離は実際に性能に効いてくるようで,Intel 64 and IA-32 Architectures Optimization Reference Manual の第18.18章(FMA Latency)には次の記載があります.
FMAは融合積和演算(fused multiply-add)の意です.
When executing in 512-bit register port scheme, Port 0 FMA has a latency of 4 cycles, and Port 5 FMA has a latency of 6 cycles.
Bypass can have a -2 (fast bypass) to +1 cycle delay.
Therefore, instructions that execute on the Skylake microarchitecture FMA have a latency of 4-7 cycles.
ただこの記述は少し言葉足らずです; このあとの文章と整合を取ると次のことが言えます:
- FMA系の命令には実行に4サイクルかかるものと5サイクルかかるものがある.
- 浮動小数点演算系のFMA命令であれば4サイクル
- 整数乗算系のFMA命令であれば5サイクル
- 5番ポートでFMA系の命令を実行する際,全ての入力がFMA系の命令から来るのであれば,この命令は0番・1番ポートと同様に4サイクルまたは5サイクルで実行できる.
- 入力がFMA系の命令から来ないのであれば,(おそらくレジスタ経由でのやり取りとなり)命令の実行に追加で2サイクルかかる.
恐らくですが,5番ポートとレジスタの間の距離が物理的に大きいため,電圧降下による誤動作を避けるためか,信号遅延による動作周波数低下を避けるためか,間にフリップフロップが2段入っているのだと思われます.
ただ,これだと無視できないほど性能が劣化してしまうため,0番・1番ポートと5番ポートのFMA演算器の間にforwarding pathを入れたのだと思われます.
(2025/12/23追記)
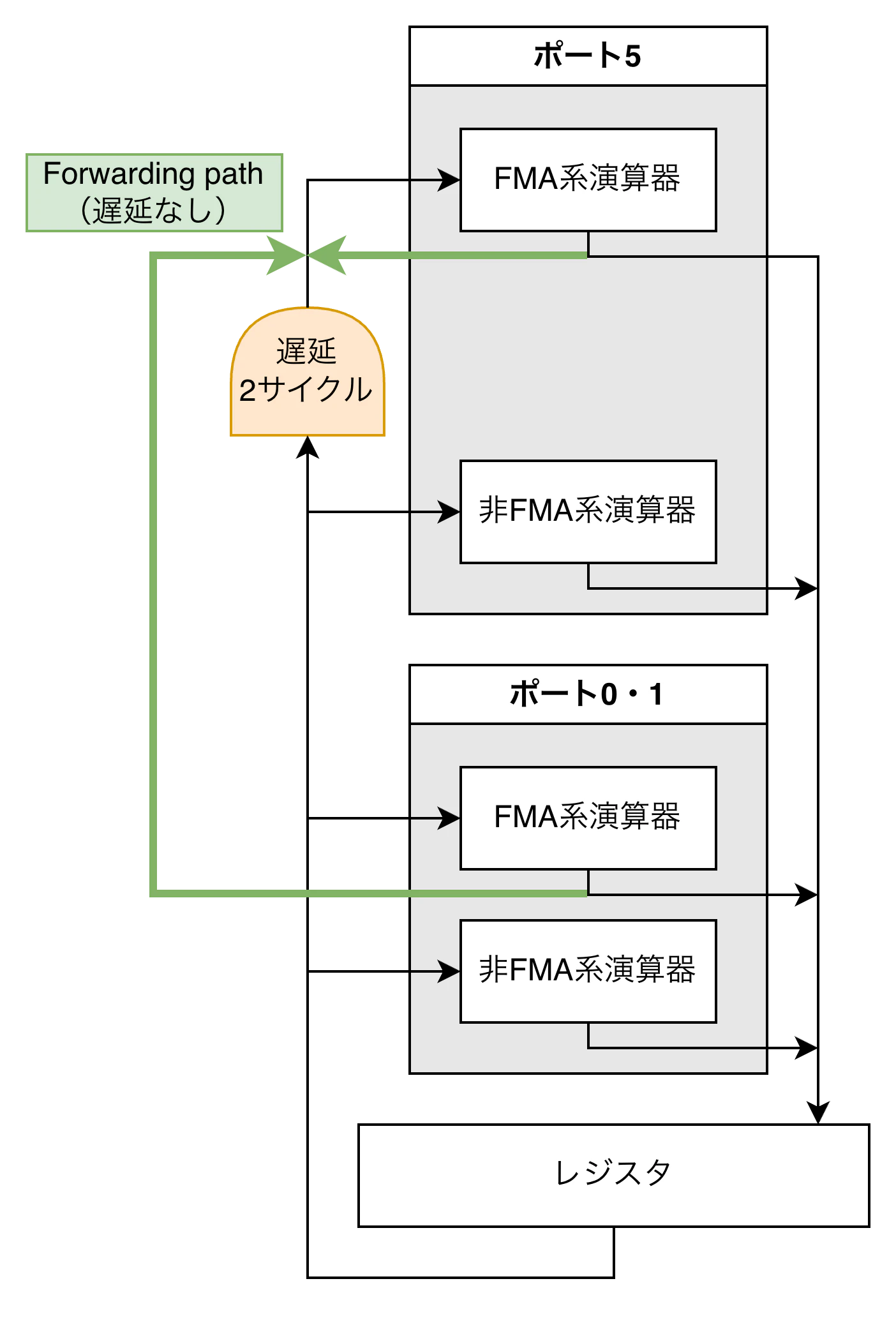
図にすると次のような感じでしょうか.
レジスタから5番ポートへは2サイクルの遅延(橙色)がありますが,FMA系演算器からはforwarding path(緑色)が出ており,遅延なしで受け取ることができます.
浮動小数点演算のFMA系の命令には,FMA演算だけでなく加減算や乗算,比較命令なども含まれています.
一般的な数値計算のアプリケーションであれば基本的にはFMA系の命令だけで構成されていそうです.
これらの命令のためのforwarding pathを設ければ,5番ポートを遠くに配置したとしても十分な性能が出ると判断されたのだと思われます.
これによりクライアント・サーバで設計をある程度共通化でき,論理・物理設計のコスト削減に繋がったのだと想像できます.
プロセッサ設計者の意図が透けて見えるようで面白いですね!
逆に,FMA系でない命令を5番ポートで実行し,それをFMA系の命令で受ける場合,命令の実行に2サイクル余分にかかることとなり,性能が低下することとなります.
次の記事ではこれを実際に確かめてみようと思います.