本記事ではウェットで属人的なモデルの作成・学習プロセスをサポートする各種ツールに焦点をあてて整理してみたいと思います。目指せモデルの学習作業のバージョンアップ。
なお、本記事はABEJA Platform Advent Calendar 2018の21日目の記事ですが、本記事ではABEJA Platform自体の解説などは行いません。今回のサーベイ結果を参考に、ABEJA Platformをさらに便利にしていけたらと思って書きました。
本記事で対象とするツール群:
- 実験管理ツール
- sacred, artemis, MLflow
- ハイパーパラメータ最適化ツール
- hyperopt, SMAC
- ハイパーパラメータ最適化+実験管理ツール
- test-tube, randopt, optuna
良いツールが続々と出てきているので、使わない手はないですよ!
Tl;dr
- ツールを使って無作為的な探索実験は自動化・最適化しましょう
- 期待を込めたおすすめツール
- optuna
- あったらうれしい機能
- Data Augmentationの最適化
機械学習プロセスふりかえり
下記はよくある機械学習のプロセスを大雑把に整理したものです。

(「より良い機械学習のためのアノテーションの機械学習」より)
このプロセスにおいて、ABEJA Platform Annotationではアノテーション作業自体のプラットフォーム機能(ユーザー管理・アノテーション作業管理)だけでなく、汎用タスクに対するテンプレートUI、ABEJAの契約するアノテーターにアノテーションを委託できるサービスを提供しています。また、ABEJA Platform自体は、作成されたモデルを非常に簡単にクラウドにデプロイしAPIとして利用可能にしたり、そのAPIの運用監視をする機能を備えています。詳細については他の方の記事を参照してください。
一方で、学習プロセス自体については、ABEJA Platformでも学習の実行機能などのいくつかの機能サポートはあるものの、まだまだ属人要素が多く、自動化しきるには至っていません。そこで、本記事では学習プロセスに焦点を当てて、巷にあふれる学習プロセスの自動化をサポートするツールのいくつかを概観して、可能性を探ってみたいと思います。
「学習」の際に何をやっているか
ツールをサーベイするにあたって、自分がよくやる「学習」プロセスを定義しておきたいと思います。仕事としてやることはないですが、例としてcifar10をデータセットとして高精度な識別モデルを作成するタスクが降ってきたと思ってモデルを作るときの自分のワークフローを棚卸ししてみます。
説明するまではないかもしれませんが、cifar10は、Deep Learningのチュートリアルでしばしば使われる、画像データセットで、10種のカテゴリに対して32x32のサイズの小さな画像が6000枚(学習5000枚、テスト1000枚)ずつ含まれています。今回作成するモデルは、与えられた画像からカテゴリを推定するものです。

だいたいいつもやること/考えることは下記のとおりです。
1. ひたすらデータを観察する
まずやるべきことは、データをひたすら観察することです。cifar10の場合だと現実感がないですが、どんな物体が写っているのかとか、データの多様性はどんな感じかとか、人間がどれくらい認識可能なのかなどを様々な角度から潰さに考えます。この段階でこのデータなら出てもこれくらいの精度だろうな、というのがなんとなく感覚としてわかったりします(人間の精度を大幅に超えることは稀なので、人間の精度がキャップになります)。
2. 大雑把に方針を決める
先の観察から技術要素や難しそうなポイントを想像し、どんな方法でとけばよいのか大雑把に決めます。今回であれば10クラスの画像分類問題なので、CNNで画像分類が適当です。複雑なタスク・特殊なタスクでは、事前に論文を必死にサーベイしたり、githubで参考になりそうな実装を探したり、あるいは自分で手法を編み出したりというようなことを行います。
3. ベースラインのコードを作成
githubをサーフィンして使えそうなリポジトリを探したりすることもよくありますが、ここではいちから作る場合を想定します。
ベースモデル(ResNet50とかVGG16とか)はあとで変えたりするので、それがしやすいようにコードを汎用的に作っておきます。個人的な好みでPyTorchを使う事が多いのですが、PyTorch用の学習済みモデルを多数提供している下記のパッケージを愛用しています。かなりマイナーなモデルもサポートされており、なによりInterfaceがほぼ統一されているのが素晴らしいです。
- pretrainedmodels: https://github.com/Cadene/pretrained-models.pytorch
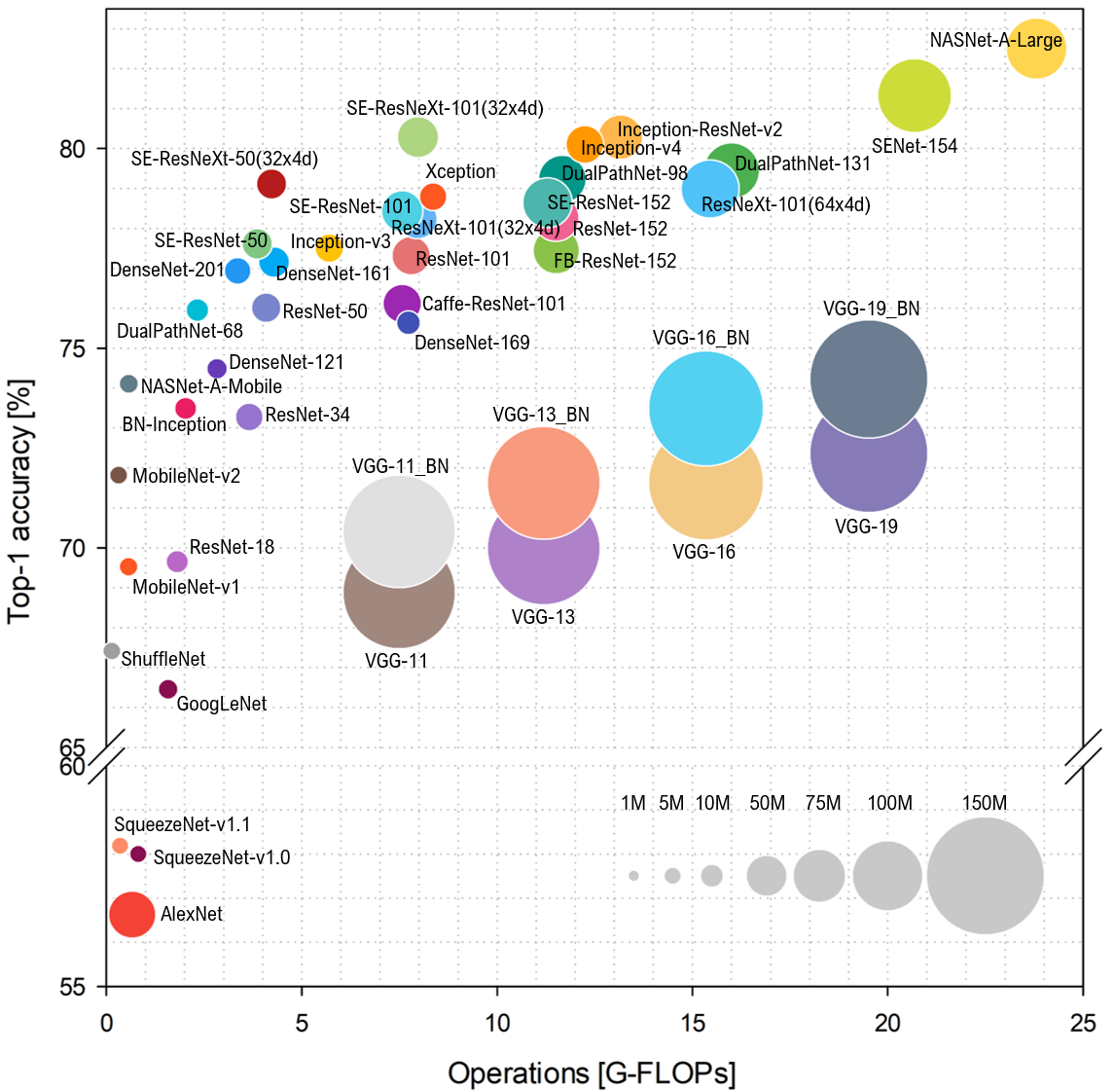
モデル選定にあたっては、出来合いのものだと私はSE ResNeXt50 (32x4d)をよく使います。ImageNetでの実績ですがモデルのサイズと精度がよくバランスされたモデルだと思います(小規模タスクだと大きすぎるかも)。その他のモデルのImageNetでの精度はpretrainedmodelsのリポジトリのREADMEにも記載されていますが、下記のrepository(論文もあります)が非常に参考になります。
下記は上記リポジトリのwikiから引用した図ですが、SE-ResNeXt-50(32x4d)は左上の隅あたりにいて、少なくともImageNet上ではかなりバランスのとれたモデルらしいことがわかります。
学習されたモデルの動作要件が厳しい場合やタスクが特殊な場合、自分で工夫をしたい場合はモデルは自作することもよくあります。その場合は、既存の有名モデルの構成を参考にしながら作ります。
4. パラメータを変えながら学習を走らせてみる
(ハイパー)パラメータセッティング(モデル含む)を変えながら実験を走らせます。
手動でパラメータは変えていったりすることが多いですが、なるべく影響の大きそうなところから優先的に可能性を絞り込んでいったほうが効率がいいので、大雑把には
- 画像の解像度を決める
- ロスを一つ選ぶ
- モデルを一つ選ぶ
- Data Augmentationの仕方を決める
- バッチサイズを選ぶ
- 学習率(learning rate)を一つ選ぶ
- 勘と経験で1~5のどれかにもどる
などの順番で探索をします(厳密にはこの順番は守らず、勘と経験でフレキシブルに探索します)。
が、基本的には実験結果を見ながら思い付き駆動で実験をしています。
メモリ使用量が大きくなりすぎたり(解像度が高すぎ、モデルが大きすぎ、バッチサイズが大きすぎ)という早々に失敗が判明するケースもあれば、一向に学習が進まなかったり(学習率が大きすぎたり実装がバグっていたり)などのちょっと観察しないとわからないケースもあります。うまく行っているのに最終的な精度が振るわないというケースもよくあります。そういうケースはなかなか希望が捨てられずじれったいです。
Deep Learningで試行錯誤するにあたって特につらいのは、一回の学習完了までに非常に時間がかかることです。メモリ使用量に余裕があるからと同一GPUコアを複数プロセスで並列的に使用しようとしたりすると、それらが競合して速度が出なくなってしまうため、原理的にコア数分しか学習は同時並列実行できません。一方でAWSやGCPなどで複数のGPUインスタンスを立ち上げて並列実行させようとすると、GPUインスタンスはそこそこコストが高いので、お財布的にも苦しくなってきます。
そのため、なるべく少ない試行回数でベターな解に探索的にたどり着くことが必要になります。
また、せっかく長い時間をかけて学習したモデルがあとから再現できなくなってしまっては元も子もないので、どんな実験を行って、どんな結果を得たかは必ず記録しておくようにします。ただし、モデルを各エポックで保存などしているといつのまにか数百GB占有したりしがちなので、泣く泣く心を込めたいくつかのモデルパラメータだけ保存することが多いです。
結果の記録を手動でやる場合、たとえばこんな感じ(データはダミーです)のspread sheetを手動管理したりすることもよくありますが、正直言ってツライです。たいてい書き間違いなどをして結局わけがわからなくなります。

学習されたモデルも忘れず保存し、できるだけ実行ログも保存しておきます。TensorBoardなどの可視化ツールをつかってるなら、実験の試行とそれらのログとがあとから明確に結び付けられるように、うまく管理しておく必要があります(私の場合、TensorBoard上での実行名と実験設定がごっちゃになることがしばしばあります)。
このあたりの作業はあからさまに自動化できそうな感じはありますが、タスクごとに保存したいものや(ハイパー)パラメータが全然違ったりして、いちいち自分でコードに書いて実現していかなければならないのもめんどくさいところです。コードもどんどん汚れていきます。なるべくシステマティックでクリーンで効率的な方法での実験設計・管理が求められます。
5. 学習されたモデルの比較評価
すべての実験が済んでから比較評価をするわけではなく、随時比較評価は行い、どんな実験設定での学習でよいモデルが得られたのかを理解していきます。
定量的なメトリックだけで比較検討できればいいのですが、ビジネス要件などとの絡みから**「メトリックがよいモデル=良いモデル」とならない**こともあります。そのため、定性評価も必ず行います。定性評価としては可視化(今回の場合画像に推論結果を紐づけてみる)をして自分の目で結果を確かめることが多いです。この段階でアノテーションに誤りがふくまれていることに気づいたり、特定ケースで失敗しやすいというような知見が得られたりします。
可視化結果は実験ごとにまるっと残しておくか、容易に再現可能にしておくのが望ましいです。
比較評価結果が思わしくない場合、再度学習方針・実験方針を再検討します。
とくに問題がなければ、もっとも良いと判断されたモデルを最終版とします。
6. その他
今回は単純な画像にたいする識別タスクなのでストーリーには出てこないですが、
- 特徴量エンジニアリング
- Deep以外のモデル/アルゴリズム
- Ensemble
なども検討対象になります。いきなりDeep Learningを適用してしまうのもいいですが、問題が比較的単純な場合は、簡単に特徴量設計をして線形回帰とかSVMとかRandom Forestなどでベースラインの精度評価をしておくと捗ると思います。
これらを含め、やること/探索空間は膨大なので、要件を考慮しつつそれをいかに狭められるかが腕の見せどころです。
対象とするツールリスト
ほしいのは下記の機能をもったツールです。
- ウェットで複雑な実験計画・結果をシステマティックに管理できる
- 実験を効率化する
また、やってる間に思いついたアイデアを簡単に試せるためにも
- ツールはなるべく依存が少なく小ぶりでコンパクトなこと
も個人的には重要な観点です。
下記の方針でツールの評価検討をします。
- 汎用的であること、何らかのツールへのロックインがないこと
- 導入が簡単なこと
- 依存ライブラリなどが少ないこも
- pythonで使えること
- 効果が大きいこと
- 最近でもメンテされていること
軽くさらってみた結果、抜け落ちなどたくさんありそうですが、下記のツールを比較検討してみることにしました。OSSで公開されているツールのみ選定しています。
実験結果や実行ログなどのもろもろを管理するツールです。実験結果の保存と再現性の確保が重要になります。
実験管理ツール
- sacred (https://github.com/IDSIA/sacred)
- artemis (https://github.com/QUVA-Lab/artemis)
- MLflow (https://github.com/mlflow/mlflow)
ハイパーパラメータ最適化
ハイパーパラメータの最適化に特化したものです。モデルづくりの探索的な作業の多いな部分はよいパラメータを探る部分にあるので、ハイパーパラメータ最適化が自動化されブラックボックス化できるとかなりワークフローがスッキリするはずです。
- hyperopt (https://github.com/hyperopt/hyperopt)
- SMAC (https://github.com/automl/SMAC3)
ハイパーパラメータ最適化+実験管理ツール
ハイパーパラメータの最適化だけではなく、ハイパーパラメータと実行結果のトラッキングや可視化もサポートしたツールです。
- test-tube (https://github.com/williamFalcon/test-tube)
- randopt (https://github.com/seba-1511/randopt)
- optuna (https://github.com/pfnet/optuna)
実験結果可視化ツール
解説記事もだいぶ多いため、下記のツール群については今回は割愛します。
- TensorBoard (https://github.com/tensorflow/tensorboard)
- Visdom (https://github.com/facebookresearch/visdom)
- ChainerUI (https://github.com/chainer/chainerui)
Neural Architecture Search系のツール
解説記事は少ないと思いますが、判別や回帰などの特定タスクに特化したツールが多い印象で、今回は汎用性に焦点を当てたいので割愛します。
各種ツールの評価検討
本記事は2日くらいでザーっと調べて執筆しているので、誤りなどあるかもしれません。その場合はご連絡いただければと思います。
実験管理ツール
Sacred
https://github.com/IDSIA/sacred

リポジトリに掲載されている上記サンプルのとおり、Experimentオブジェクトに実験設定と結果が記録し、MongoDBやRDBMS、jsonなどへ保存するスタイルです。以下、ドキュメントからの転載です。

Omniboard、Sacredboard、SacredBrowserのような3rdパーティのツールもあり、コミュニティも結構大きそうです。以前、tinydbというJSONストアに保存をする設定で使ってみたことがあるのですが、実験途中でエラーを起こしてしまったせいでDBが壊れて実験結果がみれなくなったという悲しい思い出があります。
artemis
from artemis.experiments import experiment_function
@experiment_function # Decorate your main function to turn it into an Experiment object
def multiply_3_numbers(a=1, b=2, c=3):
answer = a*b*c
print('{} x {} x {} = {}'.format(a, b, c, answer))
return answer
record = multiply_3_numbers.run() # Run experiment and save arguments, console output, and return value to disk
print(record.get_log()) # Pring console output of last run
print(record.get_result()) # Print return value of last run
ex = multiply_3_numbers.add_variant(a=4, b=5) # Make a new experiment with different paremters.
multiply_3_numbers.browse() # Open a UI to browse through all experiments and results.
実験=関数と考えて、パラメータを変えたり結果や標準出力をキャプチャしたりするインターフェイスを提供するスタイルです。上記のmultiply_3_numbers.browse()の結果、下記のような標準出力を得ます。
==================== Experiments ====================
E# R# Name All Runs Duration Status Valid Result
---- ---- ---------------------------- -------------------------- --------------- --------------- ------- --------
0 0 multiply_3_numbers 2017-08-03 10:34:51.150555 0.0213599205017 Ran Succesfully Yes 6
1 multiply_3_numbers <No Records> - - - -
-----------------------------------------------------
Enter command or experiment # to run (h for help) >>
使い勝手はsacredとあまり変わらなそうですが、ちょっとimportする対象が多くて、artemisに最適化されたコードが出来上がりそうなのが懸念点です。下記はartemisのリポジトリで提供されているexampleの一部です。
MLflow
まだBeta Releaseだそうですが、MLflow (currently in beta) is an open source platform to manage the ML lifecycle, including experimentation, reproducibility and deploymentだそうです。すごいですね!下記の3つのツールセットからなるようです。

このうち、MLflow Trackingはgit commitと連動して実験が走るようです。git連携は考えたことがあるのですが、gitでの開発のワークフローと実験のワークフローとが整合するのか気になります。実験の方はその性質上、思い付き駆動になりやすいので…
下記はMLflow Trackを使った実験管理コードのサンプルの一部です。
with mlflow.start_run():
# Log our parameters into mlflow
for key, value in vars(args).items():
mlflow.log_param(key, value)
# Create a SummaryWriter to write TensorBoard events locally
output_dir = dirpath = tempfile.mkdtemp()
writer = SummaryWriter(output_dir)
print("Writing TensorBoard events locally to %s\n" % output_dir)
# Perform the training
for epoch in range(1, args.epochs + 1):
train(epoch)
test(epoch)
# Upload the TensorBoard event logs as a run artifact
print("Uploading TensorBoard events as a run artifact...")
mlflow.log_artifacts(output_dir, artifact_path="events")
print("\nLaunch TensorBoard with:\n\ntensorboard --logdir=%s" %
os.path.join(mlflow.get_artifact_uri(), "events"))
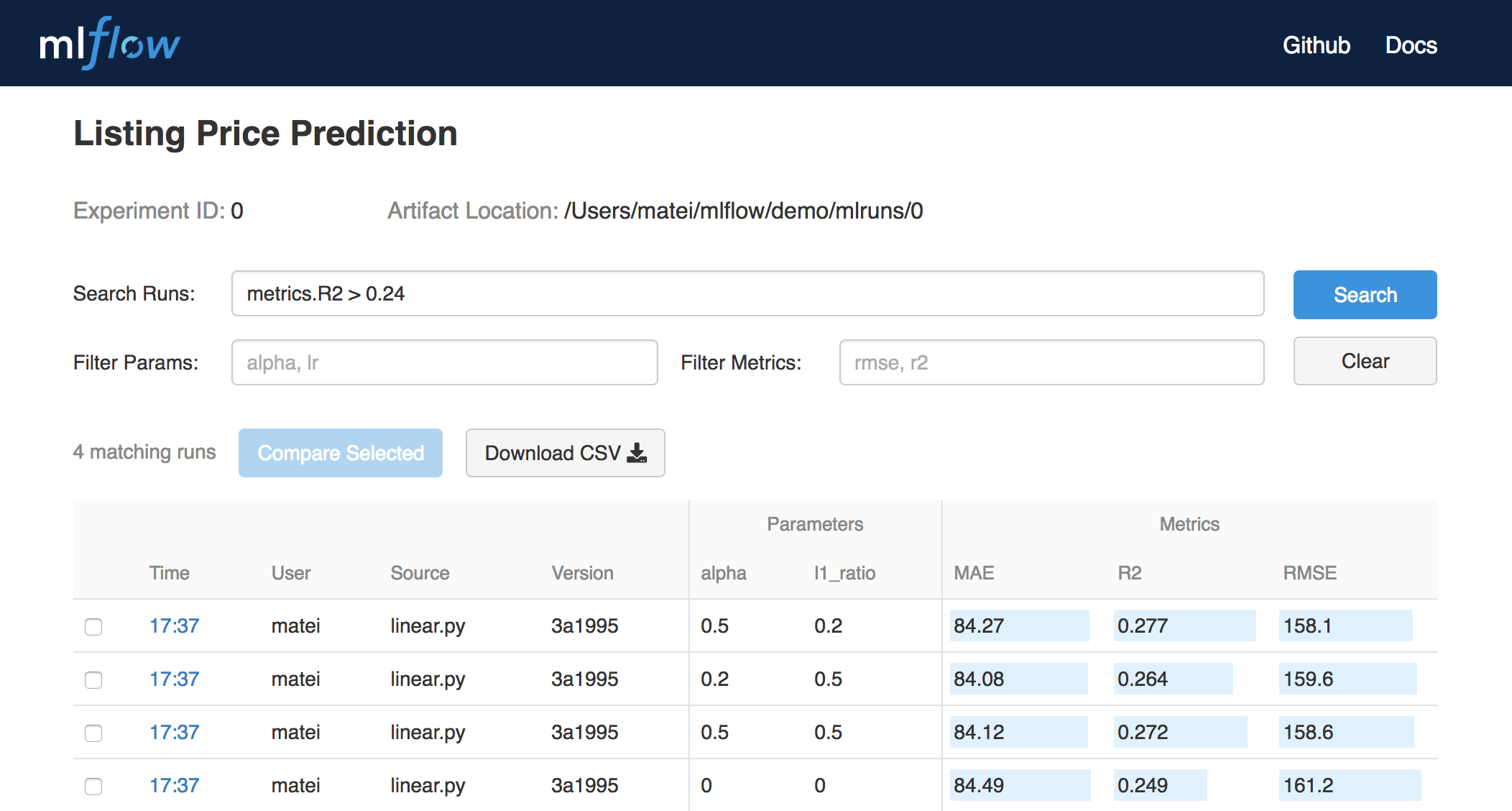
別のサンプルのケースですが、実行するとTracking UIで下記のようなUIで実験結果を確認できるようです。
MLflow Projectsは、condaを通じてpython環境の再現などをし、MLflow ModelsはモデルのAPIデプロイをサポートするツールのようです。これらは試してみないと感触がわからなそうです。
参考:
ハイパーパラメータ最適化
ハイパーパラメータの最適化に特化したものです。ハイパーパラメータ最適化には様々な手法がありますが、多くのツールでは、ランダムサーチ、Bayesian Optimization、進化的アルゴリズムが使われています。
その中で例えばhyperoptとoptunaではTPE(Tree-structured Parzen Estimator)が使われています。誤解をおそれずに言えば、TPEはうまく行った試行(上位γ%の試行)とそうでない試行のパラメータの分布の密度推定をし、(結果的に)前者の密度が後者の密度に対して相対的に高い点を優先的に調べる手法です。詳細は下記原著論文を参照してください。
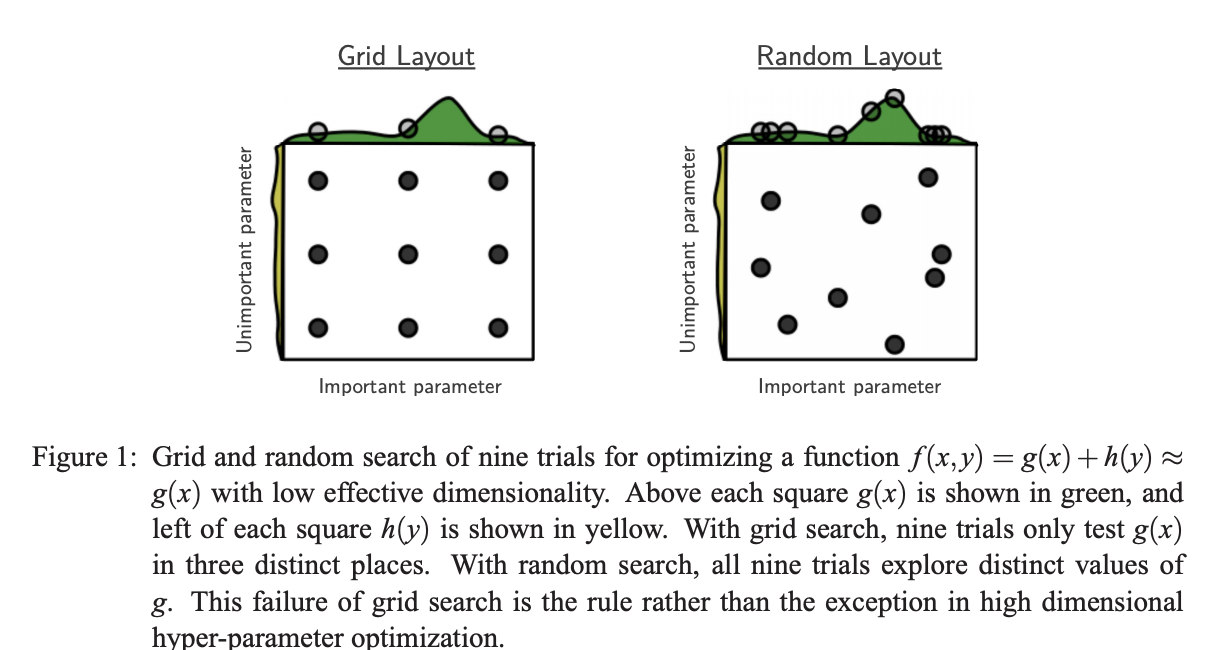
簡単な探索手法としてはGrid Searchもあり得ますが、下記論文で指摘されている通り、Grid Searchをすると、すでに不適切だと明らかになったパラメータセッティングが含まれてるケースでも愚直に何度も繰り返し探索されることになり、無駄が多くなります。
基本的には試行回数は限定的にならざるを得ないので、パラメータとmetricの応答関係を少ないデータから大雑把に把握する手法が向いているのかもしれません。
その他の手法などに関しては、下記の記事なども参考になると思います。
- Hyperoptなどのハイパーパラメータチューニングとその関連手法についてのメモ
- A Conceptual Explanation of Bayesian Hyperparameter Optimization for Machine Learning
hyperopt
random searchとTPEをサポートしたツールです。
from hyperopt import fmin, tpe, hp
best = fmin(fn=lambda x: x ** 2,
space=hp.uniform('x', -10, 10),
algo=tpe.suggest,
max_evals=100)
print best
(https://github.com/hyperopt/hyperopt/wiki/FMin より引用)
実験を関数として定義し、探索空間をなすパラメータの分布/範囲を指定すると、Random SearchやTPEで指定回数分探索が行われて最良の結果が返ってきます。
非常に直感的でわかりやすいです。MongoDBと連携することで、並列実行もできます。
SMAC
Sequential Model-based Algorithm Configuration (SMAC)という下記の論文で提案されている探索手法がメインのツールです。
- F. Hutter+,"Sequential Model-Based Optimization for General Algorithm Configuration"
基本的にはハイパーパラメータに対するコストの応答局面をRandom Forestで推定しつつ、もっとも寄与の大きそうなパラメータを優先的に探索します。
下記はiris datasetの識別タスクをSVMで行う例です。
import numpy as np
from sklearn import svm, datasets
from sklearn.model_selection import cross_val_score
# Import ConfigSpace and different types of parameters
from smac.configspace import ConfigurationSpace
from ConfigSpace.hyperparameters import CategoricalHyperparameter, \
UniformFloatHyperparameter, UniformIntegerHyperparameter
from ConfigSpace.conditions import InCondition
# Import SMAC-utilities
from smac.tae.execute_func import ExecuteTAFuncDict
from smac.scenario.scenario import Scenario
from smac.facade.smac_facade import SMAC
...
# Build Configuration Space which defines all parameters and their ranges
cs = ConfigurationSpace()
# We define a few possible types of SVM-kernels and add them as "kernel" to our cs
kernel = CategoricalHyperparameter("kernel", ["linear", "rbf", "poly", "sigmoid"], default_value="poly")
cs.add_hyperparameter(kernel)
# There are some hyperparameters shared by all kernels
C = UniformFloatHyperparameter("C", 0.001, 1000.0, default_value=1.0)
shrinking = CategoricalHyperparameter("shrinking", ["true", "false"], default_value="true")
cs.add_hyperparameters([C, shrinking])
...
# Scenario object
scenario = Scenario({"run_obj": "quality", # we optimize quality (alternatively runtime)
"runcount-limit": 200, # maximum function evaluations
"cs": cs, # configuration space
"deterministic": "true"
})
...
# Optimize, using a SMAC-object
print("Optimizing! Depending on your machine, this might take a few minutes.")
smac = SMAC(scenario=scenario, rng=np.random.RandomState(42),
tae_runner=svm_from_cfg)
incumbent = smac.optimize()
inc_value = svm_from_cfg(incumbent)
print("Optimized Value: %.2f" % (inc_value))
基本的にはパラメータの探索空間を設定し、SMACオブジェクトを作ってoptimize()するだけですが、ちょっと記述量が多くて煩雑な印象です。
ハイパーパラメータ最適化+実験管理ツール
ハイパーパラメータ探索機能と実験管理機能を備えたツール群です。
test-tube
Log, organize and parallelize hyperparameter search for Deep Learning experimentsと謳われている通り、Deep Learningに特化した実験管理・ハイパーパラメータ探索ツールです。Pythonのargparseモジュール上に構築されており、複数のGPUコア/ノードやHPCクラスターでのハイパーパラメータ探索ができます。下記はマルチGPUコア環境で実行するサンプルです。
from test_tube import HyperOptArgumentParser
# subclass of argparse
parser = HyperOptArgumentParser(strategy='random_search')
parser.add_argument('--learning_rate', default=0.002, type=float, help='the learning rate')
# let's enable optimizing over the number of layers in the network
parser.opt_list('--nb_layers', default=2, type=int, tunable=True, options=[2, 4, 8])
# and tune the number of units in each layer
parser.opt_range('--neurons', default=50, type=int, tunable=True, low=100, high=800, nb_samples=10)
# compile (because it's argparse underneath)
hparams = parser.parse_args()
# optimize across 4 gpus
# use 2 gpus together and the other two separately
hparams.optimize_parallel_gpu(MyModel.fit, gpu_ids=['1', '2,3', '0'], nb_trials=192, nb_workers=4)
シンプルでクリーンでわかりやすいですね。ただ、ハイパーパラメータ探索はコードを見る限り、Grid SearchとRandom Searchしかサポートしていないようで、どの辺りがfor Deep Learning experimentsなのかはわからなかったです。
randopt
randopt is a Python package for machine learning experiment management, hyper-parameter optimization, and results visualization
だそうです。以下はサンプルです。
import randopt as ro
def loss(x):
return x**2
e = ro.Experiment('myexp', {
'alpha': ro.Gaussian(mean=0.0, std=1.0, dtype='float'),
})
# Sampling parameters
for i in xrange(100):
e.sample('alpha')
res = loss(e.alpha)
print('Result: ', res)
e.add_result(res)
# Manually setting parameters
e.alpha = 0.00001
res = loss(e.alpha)
e.add_result(res)
# Search over all experiments results, including ones from previous runs
opt = e.minimum()
print('Best result: ', opt.result, ' with params: ', opt.params)
ハイパーパラメータの探索空間をExperimentオブジェクトに定義すると、パラメータのサンプリング(e.sample('alpha'))や結果の保存(e.add_result(res))ができるようです。
ハイパーパラメータの探索には進化的アルゴリズムとGrid Searchが使えるようです。
exp = ro.Experiment('simple_example', params={
'x': ro.Gaussian(0.0, 0.4),
'y': ro.Gaussian(0.0, 0.001)
})
fitness = lambda res1, res2: res1.result <= res2.result
exp = ro.Evolutionary(exp, elite_size=3, fitness=fitness)
exp = ro.Experiment('simple_example', params={
'x': ro.Choice([1, 2, 3]),
'y': ro.Choice([-1, 1]),
})
exp = ro.GridSearch(exp)
使い勝手は良さそうですね。roviz.pyというプログラムも用意されており、下記のような感じに結果の可視化もできるようです。
(https://cdn.rawgit.com/seba-1511/randopt/master/assets/html/simple_saved_report.html)
optuna
PFNからつい最近公開されたツールです。詳細な説明は公式リリースを見ていただいたほうがいいでしょう。
https://research.preferred.jp/2018/12/optuna-release/
import ...
# Define an objective function to be minimized.
def objective(trial):
# Invoke suggest methods of a Trial object to generate hyperparameters.
classifier_name = trial.suggest_categorical('classifier', ['SVC', 'RandomForest'])
if classifier_name == 'SVC':
svc_c = trial.suggest_loguniform('svc_c', 1e-10, 1e10)
classifier_obj = sklearn.svm.SVC(C=svc_c)
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32)
classifier_obj = sklearn.ensemble.RandomForestClassifier(max_depth=rf_max_depth)
iris = sklearn.datasets.load_iris()
x, y = iris.data , iris.target
score = sklearn.model_selection.cross_val_score(classifier_obj , x, y)
accuracy = score.mean()
return 1.0 - accuracy # A objective value linked with the Trial object.
study = optuna.create_study() # Create a new study.
study.optimize(objective , n_trials=100) # Invoke optimization of the objective function.
Chainerと同様、Define-by-Runスタイルで使えるため、必要に応じてパラメータをad-hocにサンプリングするだけで使えるため、ツールに縛られずにクリーンにコードを書くことができそうです。
アルゴリズムは基本的にはhyperoptと同様、TPEを用いているようですが、実行途中での枝刈りが実装されており、改善の見込みのないパラメータは早々と見切りをつける事ができます。また、バックエンドにRDBを使うことで学習履歴のトラッキングが出来たり、並列分散アルゴリズムにも対応しています。可視化用のダッシュボードも実装中だそうです。クリーンな上に全部入りで素晴らしいですね。ハイパーパラメータ最適化というより、ハイパーパラメータ最適化を含む実験最適化ツールといったほうがよさそうです。
個人的にはChainer以外のフレームワークでも同じ使い勝手で使いたいので、今後、Chainerに過度に最適化されすぎないことを期待しています(Chainerは好きです)。
まとめ
結局とりとめのない記事になってしまいましたが、Optunaを始め賢いアルゴリズムの実装されたクリーンな実験管理/ハイパーパラメータ最適化ツールがたくさんあるので、使わない手はないですね。
個人的には、Data Augmentationのチューニングをよく行うので、これらの自動最適化にも興味があります。Data Augmenationの場合、実行順序がクリティカルになったりするので、これらも最適化できるようになってくると非常に面白いと思いました。下記は昔NIPS2017の論文読み会で発表した資料ですが、この資料で解説した論文では、LSTMでData Augmentationを提案するモデルを強化学習することでData Augmenatationのブラックボックス最適化を実現しています。
Data Augmentationは他のHyperparameterと比べるとよりダイナミックに探索・更新できそうな感じもするので、既存のHyperparameter Optimizationの想定するスコープからは若干ずれるのかもしれませんが、サポートするツールが出てくると面白そうです。
便利な道具はどんどん導入してベストプラクティスを自然に提供するのがPlatformerの役目の一つだと思うので、継続的にサーベイをしていきつつ、オープンソースなどでツール公開をすることで機械学習業界に寄与して行きたいなと思います。