はじめに
前回の「オープンデータから花粉飛散量とスギの植生と風の影響を可視化する(前処理編)」の続編です。
前回の記事は以下のリンクから。
https://qiita.com/TakuTaku36/items/40cb590b0ae0c6340f8c
今回は全国の各観測地点における花粉飛散量やスギの植生、都道府県別の花粉症有病率といったものに影響を与えているであろう風をデータから可視化し、分析していきます。
風の可視化
今回の可視化編をまとめるまでに前回のデータの前処理編から少し期間が空いて、その間にデータのマージ等で扱いやすいように少し改良しているので全く同じにはなっていませんが悪しからず。
以下の表は複数のデータの前処理や集計を行なって、欲しいデータを取り出してまとめたものです。2019/2/15~2019/4/30の期間において毎時間観測された風向が対象期間の全体に占める割合を列にして追加しています。一つの観測地点につき16方位分あるのが116の観測地点の数だけ並んでいます。
| 都道府県 | 市区町村 | 風向 | 緯度 | 経度 | 観測された風向の各方角の全体に占める割合(%) |
|---|---|---|---|---|---|
| 三重県 | 四日市市 | 北 | 34.97 | 136.6 | 14.270 |
| 三重県 | 四日市市 | 北北東 | 34.97 | 136.6 | 5.584 |
| 三重県 | 四日市市 | 北北西 | 34.97 | 136.6 | 19.853 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 三重県 | 四日市市 | 西 | 34.97 | 136.6 | 6.148 |
| 三重県 | 四日市市 | 西北西 | 34.97 | 136.6 | 5.697 |
| 三重県 | 四日市市 | 西南西 | 34.97 | 136.6 | 8.009 |
| 三重県 | 津市 | 北 | 34.72 | 136.5 | 2.115 |
| 三重県 | 津市 | 北北東 | 34.72 | 136.5 | 2.449 |
| 三重県 | 津市 | 北北西 | 34.72 | 136.5 | 5.342 |
各観測地点がある市区町村別の風向別割合をレーダーチャートで可視化してみる
# レーダーチャートの枠組みの準備
import matplotlib.pyplot as plt
import numpy as np
# 単位円の0を始点、時計でいうと3時の方向から反時計回りに16方位をアルファベットで指定
labels=['E', 'ENE', 'NE', 'NNE', 'N', 'NNW', 'NW', 'WNW', 'W', 'WSW', 'SW', 'SSW', 'S', 'SSE', 'SE', 'ESE']
# データの各方角の割合を25%までで5%ずつ設定
markers = [0, 5, 10, 15, 20, 25]
# 表示
str_markers = ["0", "5", "10", "15", "20", "25"]
def make_radar_chart(name, stats, attribute_labels = labels, plot_markers = markers, plot_str_markers = str_markers):
labels = np.array(attribute_labels)
angles = np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats = np.concatenate((stats,[stats[0]]))
angles = np.concatenate((angles,[angles[0]]))
fig= plt.figure()
ax = fig.add_subplot(111, polar=True)
#ax.plot(angles, stats, 'o-', linewidth=1)
ax.fill(angles, stats, alpha=0.8)
ax.set_thetagrids(angles * 180/np.pi, labels)
plt.yticks(markers)
#ax.set_title(name)
ax.grid(False) # グリッド線を入れる場合はTrue
# 軸メモリラベルを消す
plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False)
# 軸メモリ線を消す
plt.tick_params(bottom=False, left=False, right=False, top=False)
# cityで指定した地点をそのまま画像のファイル名として保存
fig.savefig("%s.png" % name, transparent=True) # Trueで余白部分の透明化
return plt.show()
後にリストが多次元で扱いにくくなっていることがわかるのでここで1次元に平坦化する関数を定義
# 3次元配列になっているものを平坦化する関数
import collections
def flatten(l):
for el in l:
if isinstance(el, collections.abc.Iterable) and not isinstance(el, (str, bytes)):
yield from flatten(el)
else:
yield el
冒頭の表が一つの観測地点につき16方位分の行があるので、次の観測地点は16行飛ばしになるようにfor文を回す。
以下のコードで16方位分データを取り出しつつ、リストを平坦化しつつ、その観測地点のレーダーチャートを作成という流れを存在する観測地点の数だけやってくれます。今回はレーダーチャートの画像が116枚自動で作成・保存されます。
# 指定した市区町村の風向別にデータを取り出す
for i in range(0, 116):
# 16行ごとに市区町村が次のものになるので16行飛ばしで抽出とグラフ作成の自動化
city = count_wind['市区町村'].iloc[i * 16]
E = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '東'), ['観測された風向の各方角の全体に占める割合(%)']].values
ENE = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '東北東'), ['観測された風向の各方角の全体に占める割合(%)']].values
NE = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '北東'), ['観測された風向の各方角の全体に占める割合(%)']].values
NNE = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '北北東'), ['観測された風向の各方角の全体に占める割合(%)']].values
N = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '北'), ['観測された風向の各方角の全体に占める割合(%)']].values
NNW = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '北北西'), ['観測された風向の各方角の全体に占める割合(%)']].values
NW = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '北西'), ['観測された風向の各方角の全体に占める割合(%)']].values
WNW = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '西北西'), ['観測された風向の各方角の全体に占める割合(%)']].values
W = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '西'), ['観測された風向の各方角の全体に占める割合(%)']].values
WSW = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '西南西'), ['観測された風向の各方角の全体に占める割合(%)']].values
SW = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '南西'), ['観測された風向の各方角の全体に占める割合(%)']].values
SSW = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '南南西'), ['観測された風向の各方角の全体に占める割合(%)']].values
S = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '南'), ['観測された風向の各方角の全体に占める割合(%)']].values
SSE = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '南南東'), ['観測された風向の各方角の全体に占める割合(%)']].values
SE = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '南東'), ['観測された風向の各方角の全体に占める割合(%)']].values
ESE = count_wind.loc[(count_wind['市区町村'] == city) & (count_wind['風向'] == '東南東'), ['観測された風向の各方角の全体に占める割合(%)']].values
# 取り出した指定した市区町村の風向別のデータをリストに格納
# 単位円のように時計の3時の方向が開始位置なのでこの順で格納
wind_data = [E, ENE, NE, NNE, N, NNW, NW, WNW, W, WSW, SW, SSW, S, SSE, SE, ESE]
# リストの次元の平坦化
wind_data = list(flatten(wind_data))
# レーダーチャートの作成
make_radar_chart(city, wind_data)
方角のラベルやグリッド線をつけた状態で2019/2/15~2019/4/30の四日市市の風向を示したレーダーチャートがこちらです。このレーダーチャートを気象界隈では風配図というようです。NNWを大きく示しているということは対象期間において北北西から多く風が吹いていたということです。

このレーダーチャートのグリッド線等を消して中の青い図形のみを116の観測地点の数だけ画像のトリミングによって取り出していきます。この作業は手作業です。プログラムでできるなら教えて欲しいです。。。
とりあえず観測地点を日本地図にプロット
日本地図に緯度・経度を指定してマーカーをプロットする際にfoliumというライブラリが適しているとの情報を見つけたのでそれでやってみました。主にこちら(https://qiita.com/nanakenashi/items/824c0cb16860ca59a424) を参考にしました。
import folium
# 地図の基準として兵庫県明石市を設定
japan_location = [35, 135]
# 基準地点と初期の倍率を指定し、地図を作成する
map = folium.Map(location=japan_location, tiles='cartodbpositron', zoom_start=5)
for i in range(0, 116):
latitude = count_wind['緯度'].iloc[i * 16]
longitude = count_wind['経度'].iloc[i * 16]
city = count_wind['市区町村'].iloc[i * 16]
folium.CircleMarker(location=[latitude, longitude], radius=2, popup=city, color='#3186cc', fill_color='#3186cc').add_to(map)
map.save("pollen_ovservation.html")
map
北海道と沖縄を除く全国116の観測地点がプロットされました。
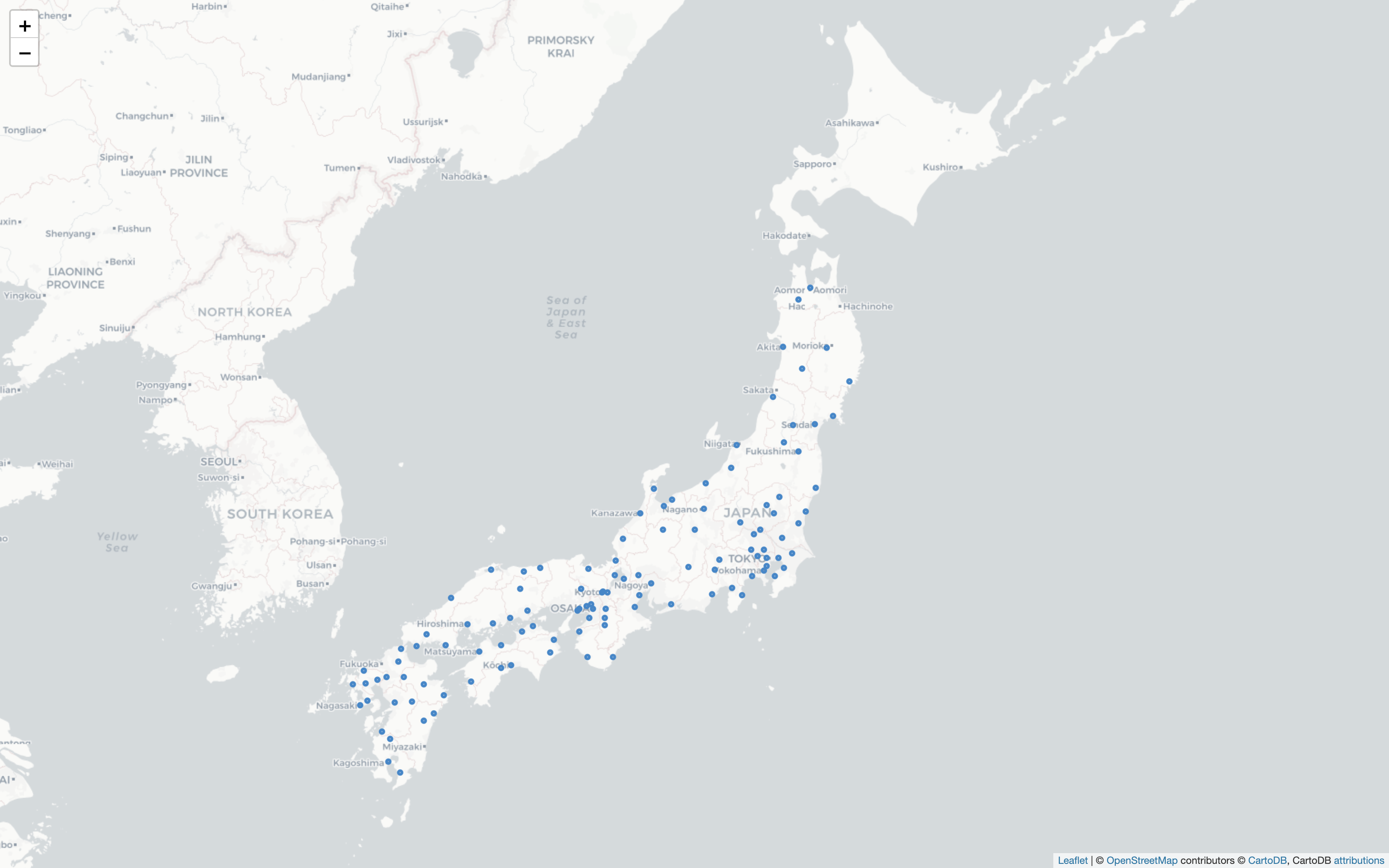
風配図を日本地図にプロット
ではこの点の位置に風配図も緯度・経度を指定して自動でプロットできるだろう!と思いきやできませんでした。何か方法があれば教えてください。。。
結局各観測地点の位置に手作業で風配図を配置して貼り付けることにしました。
小さいと作業しにくいので東日本に絞りました。他にも理由ありますが。
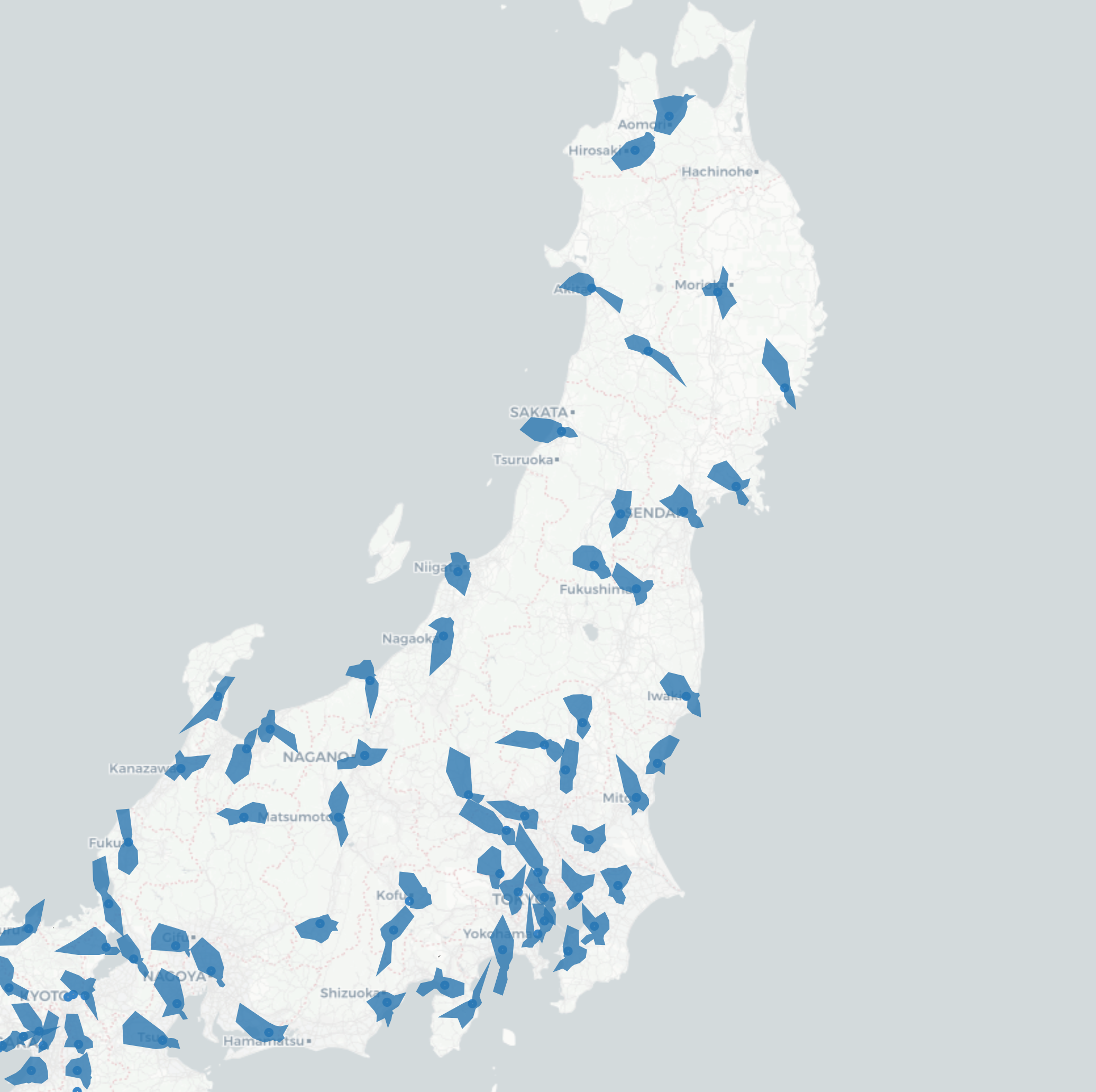
細長く伸びている方から風が吹いていて、それぞれのエリアで方角に傾向が出ていることがわかります。
風向をさらにわかりやすく可視化
風配図について知っている人ならともかく一般人がこの図を見て解釈の方法わかりますか?!って話なので矢印に置き換えました。これも自動化の方法がわからないので手作業です。
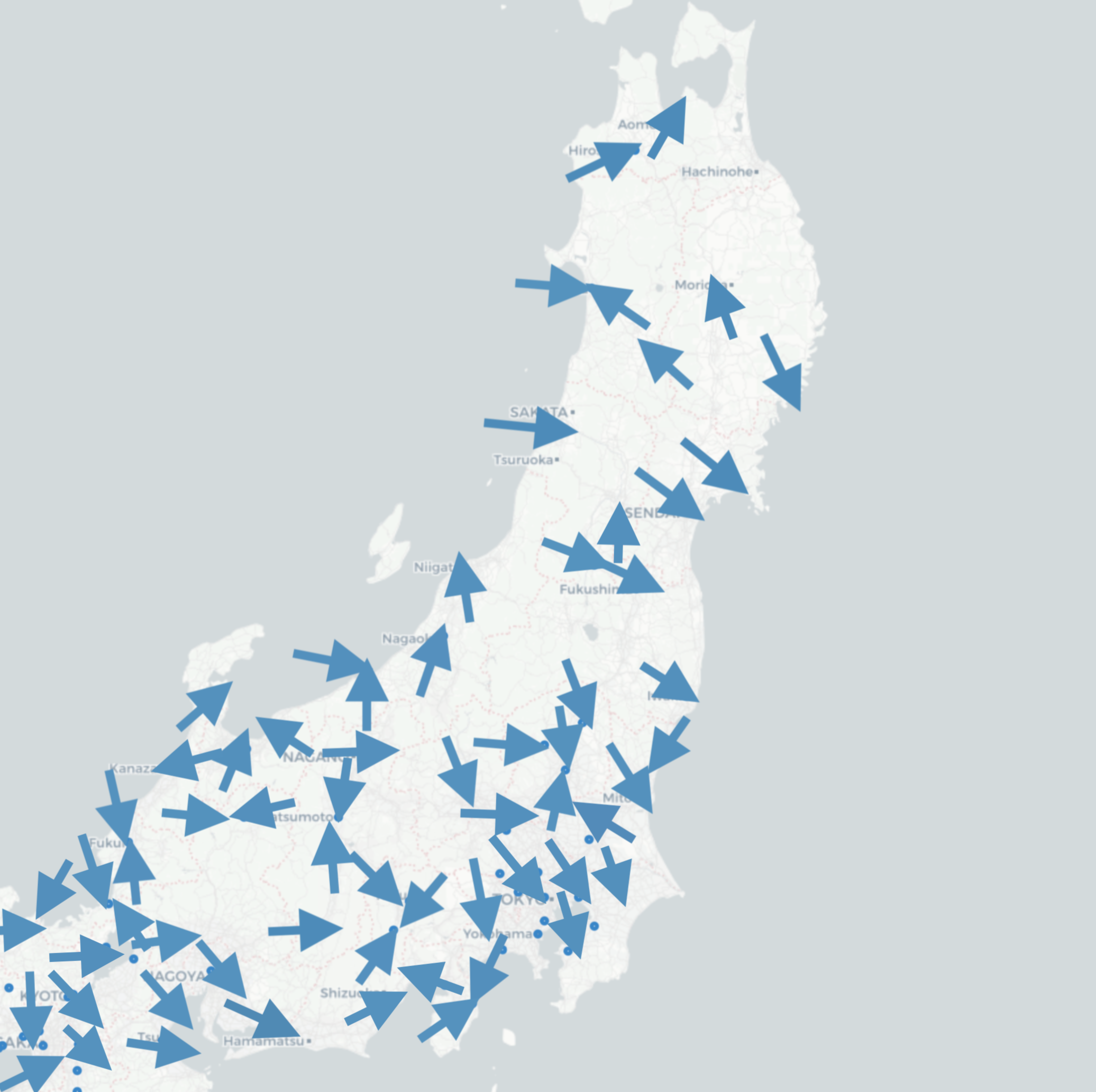
矢印の先が風下、矢印の根元が風上という具合です。
こんな図を天気予報等で見たことあると思うのですが、あれはアメダスで観測されたある日時のある特定の時間のデータです。対してこれはある程度長い期間を設定して総合的に見たときどっちに風が吹いていますか?!って話です。これで対象期間の風向の可視化は完了です。
最後に
前回はデータの前処理をやり、今回は風の可視化をやりました。ほぼ素材は揃ったので次回はあと数枚図を並べて現象とその要因を解釈していこうと思います。
関連
オープンデータから花粉飛散量とスギの植生と風の影響を可視化する(前処理編)
https://qiita.com/TakuTaku36/items/40cb590b0ae0c6340f8c