はじめに
TechTrainのアドベントカレンダー(https://qiita.com/advent-calendar/2019/techtrain) 11日目の担当で、大学1年生のPython学び始めて2ヶ月半の私が今の実力でオープンデータを使って軽く分析してみたものをまとめます。
内容
各都道府県の花粉症有病率のデータを見て、そんなにスギが生えているイメージがない東京を含む関東圏の広範囲で花粉症有病率が高いことがわかりました。そこでスギの植生と花粉飛散量の間に何か要因があるのだろうと、、、それは風ではないかと予想して、それらを可視化することで予想が正しいか、またどの程度影響しているかを見てみようという趣旨です。
やることが多いので今回はデータの前処理の部分のみまとめます。
使うデータ一覧
- 環境省花粉観測システム(はなこさん)
(http://kafun.taiki.go.jp/DownLoad1.aspx)
期間を2019/2/15〜2019/4/30に指定して北海道と沖縄を除く全国の観測所で観測された花粉飛散数とアメダスのデータ - おまるくんの技術ノート 市区町村コード表(緯度経度付き)
(http://note.omarukun.com/notes/4/)
最終的に日本地図にプロットしたいので観測地点の座標が欲しいため - 風向コード16方位対応表 (気象庁の資料を基に自作)
アメダスのデータの風向が方角ではなく番号で記されていたのでわかりやすいようにするため - スギ花粉症有病率の地域差について
(https://www.jstage.jst.go.jp/article/arerugi/59/1/59_KJ00006063684/_pdf)
都道府県別の花粉症有病率のデータ - 林野庁都道府県別森林率・人工林率
(http://www.rinya.maff.go.jp/j/keikaku/genkyou/h29/1.html)
都道府県別のスギの植生面積のデータ
データ読み込みとデータクレンジング
花粉飛散の地域と量と天気に関するデータ
import pandas as pd
import numpy as np
# データフレームの表示数を設定する
# 8行分を表示する
pd.set_option('display.max_rows', 10)
各地方ごとに出力されたCSVファイル読み込んでいきます
# 東北
touhoku = pd.read_csv('./pollen_touhoku.csv', encoding='shift_jis', header=None)
touhoku
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50210100 | 31312 | 20190215 | 1 | 青森市中央卸売市場 | 1 | 2 | 青森県 | 2201 | 青森市 | 0 | 10 | 3 | -3.2 | 0 | 0 |
| 50210100 | 31312 | 20190215 | 2 | 青森市中央卸売市場 | 1 | 2 | 青森県 | 2201 | 青森市 | 323 | 9 | 5 | -3.4 | 0 | 0 |
| 50210100 | 31312 | 20190215 | 3 | 青森市中央卸売市場 | 1 | 2 | 青森県 | 2201 | 青森市 | 69 | 9 | 4 | -3.1 | 0 | 0 |
| 50210100 | NaN | 20190215 | 4 | 青森市中央卸売市場 | 1 | 2 | 青森県 | 2201 | 青森市 | 86 | NaN | NaN | NaN | NaN | 0 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 50620100 | 35141 | 20190308 | 1 | 庄内総合支庁分庁舎 | 2 | 6 | 山形県 | 6426 | 東田川郡三川町 | 0 | 15 | 3 | 3.3 | 0 | 1 |
| 50620100 | 35141 | 20190308 | 2 | 庄内総合支庁分庁舎 | 2 | 6 | 山形県 | 6426 | 東田川郡三川町 | 45 | 16 | 3 | 1.1 | 1 | 0 |
| 50620100 | 35141 | 20190308 | 3 | 庄内総合支庁分庁舎 | 2 | 6 | 山形県 | 6426 | 東田川郡三川町 | 8 | 14 | 3 | 2.9 | 0 | 0 |
| 50620100 | 35141 | 20190308 | 4 | 庄内総合支庁分庁舎 | 2 | 6 | 山形県 | 6426 | 東田川郡三川町 | 4 | 13 | 3 | 3.1 | 0 | 0 |
| 23400 rows × 16 columns | |||||||||||||||
| これを残りの関東(kanto)、中部(chubu)、関西(kansai)、中国・四国(chugoku_shikoku)、九州(kyusyu)と読み込んでいきます。 | |||||||||||||||
| 同じこと且つ長いのでコードと結果は割愛します。 |
余分な列を削除する
東北地方のデータフレームを見てわかるように列のラベルが不明なので一つずつ調べて要らない列を削除します
touhoku.drop([0, 1, 5, 6, 13, 14, 15], axis=1, inplace=True)
kanto.drop([0, 1, 5, 6, 13, 14, 15], axis=1, inplace=True)
chubu.drop([0, 1, 5, 6, 13, 14, 15], axis=1, inplace=True)
kansai.drop([0, 1, 5, 6, 13, 14, 15], axis=1, inplace=True)
chugoku_shikoku.drop([0, 1, 5, 6, 13, 14, 15], axis=1, inplace=True)
kyushu.drop([0, 1, 5, 6, 13, 14, 15], axis=1, inplace=True)
欠損値の処理
まず欠損値の有無の確認
print(touhoku.isnull().sum())
print(kanto.isnull().sum())
print(chubu.isnull().sum())
print(kansai.isnull().sum())
print(chugoku_shikoku.isnull().sum())
print(kyushu.isnull().sum())
欠損値のある行の削除
touhoku.dropna(how='any', inplace=True)
kanto.dropna(how='any', inplace=True)
chubu.dropna(how='any', inplace=True)
kansai.dropna(how='any', inplace=True)
chugoku_shikoku.dropna(how='any', inplace=True)
kyushu.dropna(how='any', inplace=True)
削除後のデータを表示する
touhoku
| 2 | 3 | 4 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|
| 20190215 | 1 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 0 | 10 | 3 |
| 20190215 | 2 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 323 | 9 | 5 |
| 20190215 | 3 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 69 | 9 | 4 |
| 20190215 | 5 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 16 | 9 | 5 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 20190430 | 21 | 株式会社江東微生物研究所 東北中央研究所 | 福島県 | 7204 | いわき市 | 0 | 8 | 2 |
| 20190430 | 22 | 株式会社江東微生物研究所 東北中央研究所 | 福島県 | 7204 | いわき市 | 0 | 9 | 3 |
| 20190430 | 23 | 株式会社江東微生物研究所 東北中央研究所 | 福島県 | 7204 | いわき市 | 0 | 8 | 3 |
| 20190430 | 24 | 株式会社江東微生物研究所 東北中央研究所 | 福島県 | 7204 | いわき市 | 0 | 9 | 2 |
| 23310 rows × 9 columns | ||||||||
| 欠損値のある行を削除することで東北地方に関しては90行減りました | ||||||||
| これを先ほどと同様に各地方見ていきます |
各データにどの市区町村が含まれるのかを確認する
それぞれのデータにたくさんの観測地点がありますが、一体いくつあるのかを観測地点がある市区町村の数でカウントしてみます
# 北海道と沖縄を除く各地方における観測地点の市区町村の数を確認
print(len(touhoku.groupby(9).count()))
print(len(kanto.groupby(9).count()))
print(len(chubu.groupby(9).count()))
print(len(kansai.groupby(9).count()))
print(len(chugoku_shikoku.groupby(9).count()))
print(len(kyushu.groupby(9).count()))
# 北海道と沖縄を除く全国の観測地点の市区町村の数の合計を確認
print(len(touhoku.groupby(9)) + len(kanto.groupby(9)) + len(chubu.groupby(9)) + len(kansai.groupby(9)) + len(chugoku_shikoku.groupby(9)) + len(kyushu.groupby(9)))
東北: 13
関東: 20
中部: 23
関西: 19
中国・四国: 21
九州: 20
合計: 116
各地方ごとに分かれたデータフレームを1つに結合
結合したら約21万行のデータフレームになりました
alljapan = pd.concat([touhoku, kanto, chubu, kansai, chugoku_shikoku, kyushu])
alljapan
| 2 | 3 | 4 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|
| 20190215 | 1 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 0 | 10 | 3 |
| 20190215 | 2 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 323 | 9 | 5 |
| 20190215 | 3 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 69 | 9 | 4 |
| 20190215 | 5 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 16 | 9 | 5 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 20190430 | 21 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 8 | 11 | 1 |
| 20190430 | 22 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 4 | 10 | 1 |
| 20190430 | 23 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 0 | 11 | 1 |
| 20190430 | 24 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 0 | 10 | 1 |
| 208273 rows × 9 columns |
列のラベルがこのままではわかりにくいので列名を編集します
alljapan.columns = ['年月日', '時間', '観測地点', '都道府県', '市区町村コード', '市区町村', '花粉飛散数(個/m^3)', '風向コード', '風速(m/s)']
風向のデータをわかりやすくしたい
風向コードと16方位で表される風向の対応表を用意する
wind_direction = pd.read_csv('./wind_direction_code.csv', encoding='UTF-8', header=0)
wind_direction
| 風向 | 風向コード |
|---|---|
| 北北東 | 1 |
| 北東 | 2 |
| 東北東 | 3 |
| 東 | 4 |
| 東南東 | 5 |
| 南東 | 6 |
| 南南東 | 7 |
| 南 | 8 |
| 南南西 | 9 |
| 南西 | 10 |
| 西南西 | 11 |
| 西 | 12 |
| 西北西 | 13 |
| 北西 | 14 |
| 北北西 | 15 |
| 北 | 16 |
| この風向コードの対応表と観測データを結合します | |
| 結合にあたりデータ型を揃えるためにalljapanの風向列のデータ型をfloatからintに変換 |
alljapan['風向コード'] = alljapan['風向コード'].astype(np.int64)
風向コードを軸にして2つのデータフレームを結合する
alljapan2 = pd.merge(
alljapan, wind_direction,
on = '風向コード',
how = 'left'
)
alljapan2
| 年月日 | 時間 | 観測地点 | 都道府県 | 市区町村コード | 市区町村 | 花粉飛散数(個/m^3) | 風向コード | 風速(m/s) | 風向 |
|---|---|---|---|---|---|---|---|---|---|
| 20190215 | 1 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 0 | 10 | 3 | 南西 |
| 20190215 | 2 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 323 | 9 | 5 | 南南西 |
| 20190215 | 3 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 69 | 9 | 4 | 南南西 |
| 20190215 | 5 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 16 | 9 | 5 | 南南西 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 20190430 | 21 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 8 | 11 | 1 | 西南西 |
| 20190430 | 22 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 4 | 10 | 1 | 南西 |
| 20190430 | 23 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 0 | 11 | 1 | 西南西 |
| 20190430 | 24 | 鹿児島県大隅地域振興局本庁舎 | 鹿児島県 | 46203 | 鹿屋市 | 0 | 10 | 1 | 南西 |
風向コード0番目が含まれていたので削除する
風向コード0は「静穏」を示すが今回は不要なため
alljapan3 = alljapan2[alljapan2['風向コード'] != 0]
座標に関するデータを結合したい
市区町村コードと座標の対応表を読み込む
データフレームをマークダウン用に出力したので緯度経度の小数点以下が2桁しか表示されていませんが実際にはもっと細かい値が出ています。
city_lon_lat = pd.read_csv('./citycode_coordinate_correspondence_table.csv', encoding='UTF-8', header=0)
city_lon_lat
| 市区町村コード | 都道府県 | 市区町村 | Unnamed: 3 | 緯度 | 経度 |
|---|---|---|---|---|---|
| 11011 | 北海道 | 札幌市 | 中央区 | 43.06 | 141.3 |
| 11029 | 北海道 | 札幌市 | 北区 | 43.09 | 141.3 |
| 11037 | 北海道 | 札幌市 | 東区 | 43.08 | 141.4 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 473758 | 沖縄県 | 宮古郡 | 多良間村 | 24.67 | 124.7 |
| 473812 | 沖縄県 | 八重山郡 | 竹富町 | 24.29 | 123.9 |
| 473821 | 沖縄県 | 八重山郡 | 与那国町 | 24.47 | 123.0 |
| 1896 rows × 6 columns |
余分な列を削除する
city_lon_lat.drop(['都道府県', '市区町村', 'Unnamed: 3'], axis=1, inplace=True)
市区町村コードの下一桁はチェックデジットなので左の5桁が一般的に使われている市区町村コードになるので下一桁を取り除く
# city_lon_latの市区町村コード列のデータ型をintからstrに変換
city_lon_lat['市区町村コード'] = city_lon_lat['市区町村コード'].astype(str)
# city_lon_latの市区町村コード列の下一桁を削除して再代入する
city_lon_lat['市区町村コード'] = city_lon_lat['市区町村コード'].str[:-1]
# city_lon_latの市区町村コード列のデータ型をstrからintに変換
city_lon_lat['市区町村コード'] = city_lon_lat['市区町村コード'].astype(int)
alljapan3とcity_lon_latを「市区町村コード」列を軸にしてマージする
join_alljapan = pd.merge(
alljapan3, city_lon_lat,
on='市区町村コード',
how='left'
)
join_alljapan
| 年月日 | 時間 | 観測地点 | 都道府県 | 市区町村コード | 市区町村 | 花粉飛散数(個/m^3) | 風向コード | 風速(m/s) | 風向 | 緯度 | 経度 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 20190215 | 1 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 0 | 10 | 3 | 南西 | 40.82 | 140.7 |
| 20190215 | 2 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 323 | 9 | 5 | 南南西 | 40.82 | 140.7 |
| 20190215 | 3 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 69 | 9 | 4 | 南南西 | 40.82 | 140.7 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 20190430 | 22 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 0 | 13 | 1 | 西北西 | 40.82 | 140.7 |
| 20190430 | 23 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 4 | 11 | 1 | 西南西 | 40.82 | 140.7 |
| 20190430 | 24 | 青森市中央卸売市場 | 青森県 | 2201 | 青森市 | 0 | 14 | 1 | 北西 | 40.82 | 140.7 |
データ型と各列のデータ数を確認
join_alljapan.info()
年月日 201422 non-null int64
時間 201422 non-null int64
観測地点 201422 non-null object
都道府県 201422 non-null object
市区町村コード 201422 non-null int64
市区町村 201422 non-null object
花粉飛散数(個/m^3) 201422 non-null float64
風向コード 201422 non-null int64
風速(m/s) 201422 non-null float64
風向 201422 non-null object
緯度 196486 non-null float64
経度 196486 non-null float64
緯度・経度に欠損値があるようであるので具体的に確認すると3つの観測地点の市区町村の市区町村コードに誤りがあったようです。
join_alljapan[join_alljapan['緯度'].isnull()]
# 静岡県庁の所在地、静岡市葵区の市区町村コードが22201ではなく正しくは22101のようであるので修正する
alljapan3.市区町村コード[alljapan3.市区町村コード == 22201] = 22101
# 熊本市医師会ヘルスケアセンターの所在地、熊本市中央区の市区町村コードが43201ではなく正しくは43101のようであるので修正する
alljapan3.市区町村コード[alljapan3.市区町村コード == 43201] = 43101
# 鹿児島県姶良・伊佐地域振興局伊佐庁舎の所在地、鹿児島県伊佐市の市区町村コードが46209ではなく正しくは46224のようであるので修正する
alljapan3.市区町村コード[alljapan3.市区町村コード == 46209] = 46224
改めてalljapan3とcity_lon_latを市区町村コード列を軸にしてマージする
join_alljapan = pd.merge(
alljapan3, city_lon_lat,
on='市区町村コード',
how='left'
)
データ型と各列のデータ数を確認
今度はデータ数が全て一致し、欠損値なくマージできたようです
join_alljapan.info()
年月日 201422 non-null int64
時間 201422 non-null int64
観測地点 201422 non-null object
都道府県 201422 non-null object
市区町村コード 201422 non-null int64
市区町村 201422 non-null object
花粉飛散数(個/m^3) 201422 non-null float64
風向コード 201422 non-null int64
風速(m/s) 201422 non-null float64
風向 201422 non-null object
緯度 201422 non-null float64
経度 201422 non-null float64
観測地点の数の検算
print(len(join_alljapan.groupby('市区町村コード')))
116
スギの植生のデータ
sugi_area = pd.read_csv('./sugi_h29.csv', encoding='UTF-8', header=4)
sugi_area
 52 rows × 24 columns
52 rows × 24 columns
sugi_area.drop(['Unnamed: 0', 'Unnamed: 1', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20+'], axis=1, inplace=True)
sugi_area.columns = ['都道府県', 'スギ植生面積(m^2)']
# 欠損値のある行の削除
sugi_area.dropna(how='any', inplace=True)
sugi_area = sugi_area.drop(47)
sugi_area
| 都道府県 | スギ植生面積(m^2) |
|---|---|
| 北海道 | 32,128 |
| 青森県 | 198,690 |
| 岩手県 | 200,525 |
| ・・・ | ・・・ |
| 宮崎県 | 224,828 |
| 鹿児島県 | 153,298 |
| 沖縄県 | 237 |
都道府県別花粉症有病率のデータ
pollen_prevalence = pd.read_csv('./pollen_prevalence.csv', encoding='UTF-8', header=0)
pollen_prevalence = pollen_prevalence.drop(47)
pollen_prevalence
| 都道府県 | 有病率 |
|---|---|
| 北海道 | 2.2 |
| 青森 | 12.5 |
| 岩手 | 12.1 |
| ・・・ | ・・・ |
| 宮崎 | 8.2 |
| 鹿児島 | 12.1 |
| 沖縄 | 6.0 |
CSVファイルで取り込んだデータのデータクレンジングは以上です。
集計
次はクレンジング済みのデータを集計して必要なデータを求めていきます。
各市町村における花粉飛散数の平均
pollen_amount = pd.DataFrame(join_alljapan.groupby(['都道府県']).mean()['花粉飛散数(個/m^3)'])
# pollen_amount.insert(0, '市区町村', join_alljapan['市区町村'])
pollen_amount

各観測地点の風向の集計
各観測地点で毎時間観測されている風向を観測した期間において集計することで、その観測地点における大まかな風向を求めたい、、、ということで集計していきます。
# 都道府県・市区町村・風向でグルーピングして各方位ごとの観測回数をまとめてデータフレームを新しく作成する
count_wind = pd.DataFrame(join_alljapan.groupby(['都道府県', '市区町村', '風向']).size())
count_wind.columns = ['風向の各方位における観測回数']
# 「風向の全方位における合計観測回数」を新しい列として追加する
count_wind['風向の全方位における合計観測回数'] = join_alljapan.groupby(['都道府県', '市区町村']).size()
# 「観測された風向の各方角の全体に占める割合(%)」を新しい列として追加する
count_wind['観測された風向の各方角の全体に占める割合(%)'] = count_wind['風向の各方位における観測回数'] / count_wind['風向の全方位における合計観測回数'] * 100
count_wind
こんな具合です
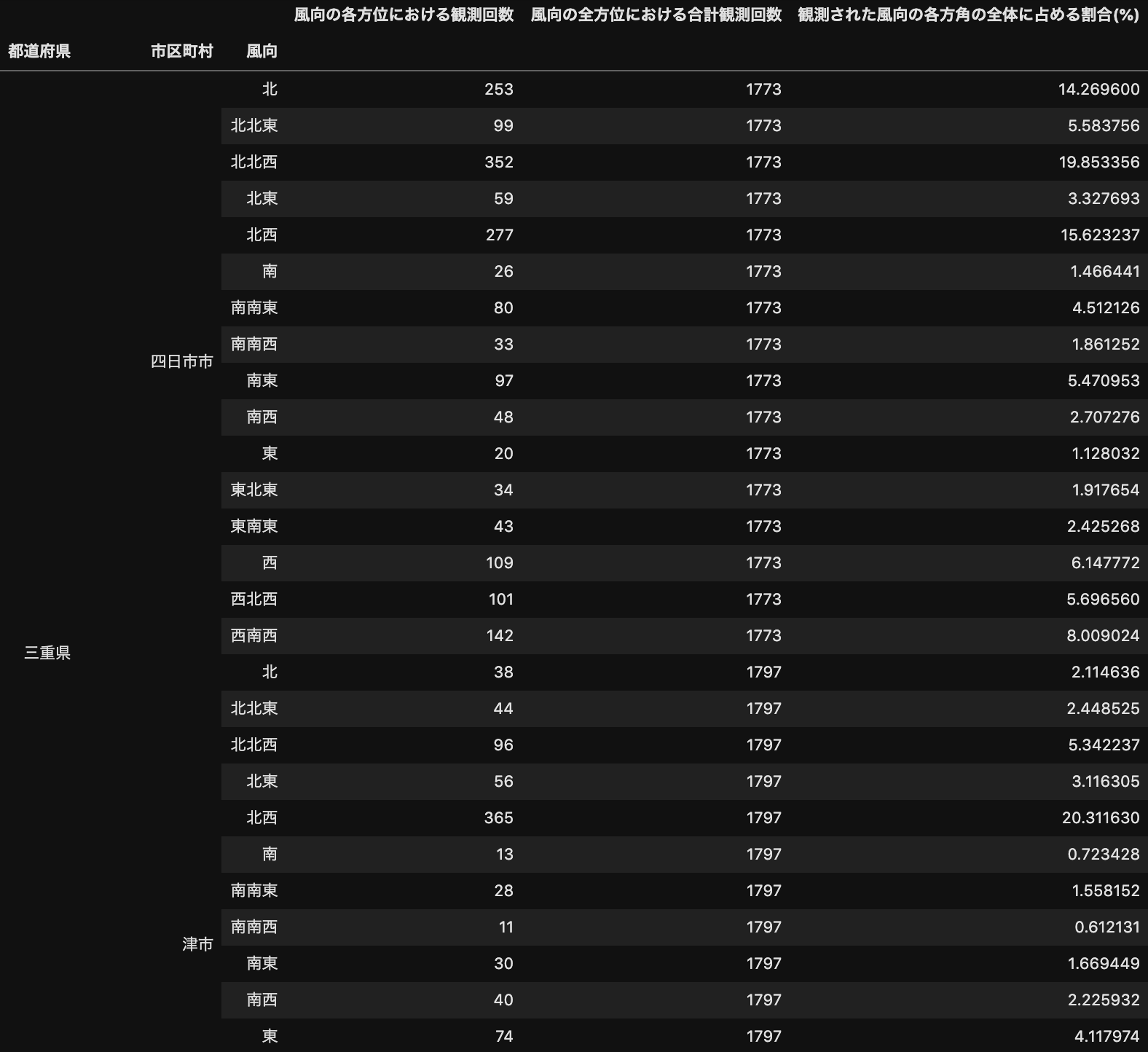
花粉飛散数と風向の集計のテーブルを作成しましたが、列の左の方にデータフレームとして列になっていない状態です。
そこに都道府県の列を追加できたら可視化の準備が完了します。
ただ、そこに手間取っているので今回はここまでにします。。。
最後に
今回はやりたかった分析の一連の流れのうちデータ前処理のみまとめました。
あと少し改良してデータを可視化できる状態にして、実際に可視化するのが自分の宿題です。。。
まとめられたらQiita更新します。
関連
オープンデータから花粉飛散量とスギの植生と風の影響を分析する(可視化編)
https://qiita.com/TakuTaku36/items/e9fa09b38f86be188070