記事の流れ
- Microsoft AzureのBing Image Searchを使った画像収集
- EfficientNet(pre trained)でネットワークの学習
- ネットワークの精度検証
- おまけ
尚、今回のブログ記事のコードは以下にまとめています。
https://github.com/spider-man-tm/predict_type_of_pokemon
もしもこの記事がお役に立てた時は、Gitのstar、もしくはQiitaのイイねボタンを押して頂けると励みになります。
動機
- ポケモンバトルにおいてタイプの相性は最重要要素と言っても過言では無い。
- がしかし、自身がポケモン剣盾をしていて、新しいポケモンを覚えきれないことによるタイプの読み間違いが多発している。(ググればすぐ出てくるけど面倒)
- そこでディープラーニングを使った場合、未知のポケモンに対するタイプ予測をどの程度正確にできるのか単純に興味があった。おそらくかなり難しいタスクなのであまり期待はしていない。
Microsoft AzureのBing Image Searchを使った画像収集
まずはじめに画像収集です。今回はMicrosoft AzureのBing Image Searchを使って画像を集めます。Bing Image Searchはこちらから入れます。尚、使用に当たってはMicrosoftアカウントが必要になります。上記サイトをクリックしていただけるとアカウント作成まで誘導してくれるのでオススメです。(2020年1月現在)
アカウント登録
上記サイトからBing Search Imageを始めると以下の画面になります。
「名前」の箇所は既に使われてるものを登録しようとするとエラーになります。インスタンスの価格レベルは、使う機能や必要なスペックに応じて決定してください。色々あるのでこちらを参照するといいと思います。
実際のソースコード
実際のコードがこちらです。
import argparse
import requests
import cv2
import os
import yaml
from utils import load_generation_yml
API_KEY = '******************************'
MAX_RESULTS = 6
GROUP_SIZE = 6
URL = 'https://api.cognitive.microsoft.com/bing/v7.0/images/search'
headers = {
'Ocp-Apim-Subscription-Key' : API_KEY
}
EXCEPTIONS = set([
IOError, FileNotFoundError,
exceptions.RequestException, exceptions.HTTPError,
exceptions.ConnectionError, exceptions.Timeout
])
parser = argparse.ArgumentParser()
parser.add_argument('-t', '--train_test', type=str, help='Choice Train or Test')
parser.add_argument('-g', '--generation', type=int, help='Choice Pokemon Generation')
args = parser.parse_args()
generation = args.generation
train_test = args.train_test
def mkdir_func(path):
if not os.path.isdir(path):
os.mkdir(path)
def make_param(term):
params = {
'q': term,
'offset': 0,
'count': GROUP_SIZE,
'imageType': 'Photo',
'color': 'ColorOnly',
'aspect': 'Square',
}
return params
def set_params(headers, params):
print(f"\nLet's search for {params['q']}\n")
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
estNumResults = min(results['totalEstimatedMatches'], MAX_RESULTS)
return estNumResults
def main():
total = generation * 10000
output = os.path.join(f'data/{train_test}')
mkdir_func(output)
pokemons = load_generation_yml(generation)
for term, pokemon_type in pokemons.items():
params = make_param(term)
estNumResults = set_params(headers, params)
for offset in range(0, estNumResults, GROUP_SIZE):
params["offset"] = offset
search = requests.get(URL, headers=headers, params=params)
search.raise_for_status()
results = search.json()
for v in results["value"]:
try:
print(f'[Fetch] {v["contentUrl"]}')
r = requests.get(v['contentUrl'], timeout=30)
ext = v['contentUrl'][v['contentUrl'].rfind('.'):v['contentUrl'].rfind('?') if v['contentUrl'].rfind('?') > 0 else None]
if ext=='.jpg' or ext=='.png':
if len(pokemon_type)==1:
p = os.path.sep.join([output, f'{str(total).zfill(5)}_{pokemon_type[0]}.jpg'])
elif len(pokemon_type)==2:
p = os.path.sep.join([output, f'{str(total).zfill(5)}_{pokemon_type[0]}_{pokemon_type[1]}.jpg'])
with open(p, 'wb') as f:
f.write(r.content)
else:
continue
except Exception as e:
if type(e) in EXCEPTIONS:
print(f'[Skip] {v["contentUrl"]}')
continue
image = cv2.imread(p)
if image is None:
print(f'[Delite] {p}')
os.remove(p)
continue
# update the counter
total += 1
if __name__ == '__main__':
main()
上記スクリプトに、コマンドライン引数を渡し画像を収集していきます。第一世代ポケモンは10000台、第二世代は20000台から始まるファイル名で保存され、さらにタイプもファイル名に追記され保存されます。
今回は各ポケモン6枚ずつ集めていきます。また第一世代をdata/test、それ以外の世代をdata/train ディレクトリに保存します。尚、今回は後に画像をリサイズする事を考慮して正方形に近い画像のみ収集しています。
python img_search.py -t test -g 1
python img_search.py -t train -g 2
python img_search.py -t train -g 3
# 以下略
第一世代を検証データとして使用するのは、個人的にタイプを予測しやすいキャラデザインだと考えたからです。(思い出補正かもしれませんが)
今回は試していないのですが、各世代のクロスバリデーションを行うことで、世代ごとの精度比較をしてみても面白いかもしれません。尚、ポケモンの名前、およびタイプの情報はyamlファイルから引っ張ってきているのですが、こちらはKaggleにあるpokemon datasetからCSVをダウンロードし、それをyml形式に整形してあげることで、簡単に作成することができます。因みに完全に余談ですが、Kaggleにはpokemonに関するデータセットとその考察が山のようにあったので、それをのぞいて見るだけでも面白いかもしれません。
目視チェック
こちらが実際に集まった画像の一部です。見ての通り、使い物にならないものや、他のポケモンが入り込んでいるものもあります。因みに「こうらのカセキ」から復元される有名なカブト。その英語名はKabutoらしく、出てきた写真はご覧の有様です。気になって調べてみたのですが、これはOGK Kabutoと呼ばれる日本のヘルメット&車両部品メーカーの商品で、画像検索をするとポケモンよりこっちの方がヒットするという悲しい状況になってしまっていました。
発見できた画像は目視で削除していますが、結構適当なので、抜け漏れある可能性は十分にあります。尚、進化後や進化前ポケモンが混ざることもかなりの割合であるのですが、タイプは大きく変わらないと思うので、今回は気づけば削除する程度に留めています。

また、ここで初めて気づいたのですが元のCSVの情報が間違っているようで、いくつかのポケモンはタイプがおかしなことになっていたりするようです。しかしこれを一つずつチェックするのは流石に無理なので厳密さはかけてしまいますが、今回はそのままモデル構築に進んで行きたいと思います。
EfficientNet(pre trained)でネットワークの学習
概要
今回の記事では、EfficientNetをファインチューニングしていきたいと思います。EfficientNetの詳細については以下を参照ください。
元論文: Tan, Mingxing, and Quoc V. Le. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks." arXiv preprint arXiv:1905.11946 (2019).(ICML 2019採択)
GitHub: こちら(TensorFlow)
Qiita記事: 2019年最強の画像認識モデルEfficientNet解説
EfficientNetは、2019年5月にGoogle Brainから発表されました。その精度やスピードから、今ではかなりメジャーなニューラルネットです。今回はその中でも最も層の浅いB0を使っていきたいと思います。
targetの分布
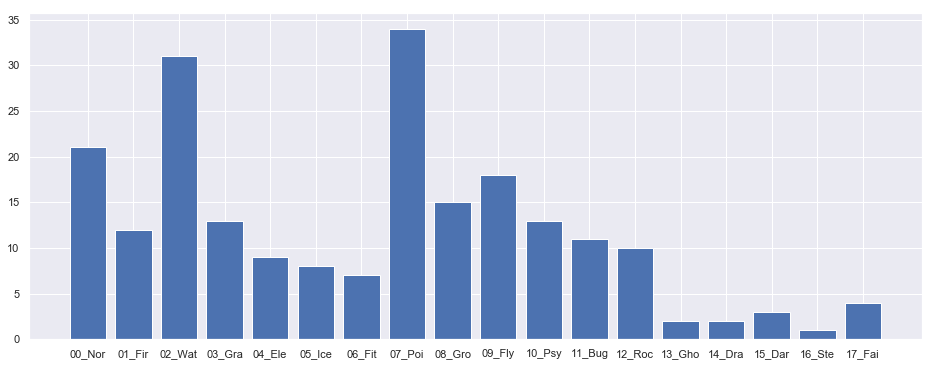
モデルの学習の前にtargetの分布を可視化してみました。下図が結果です。
【第一世代】
【その他世代】
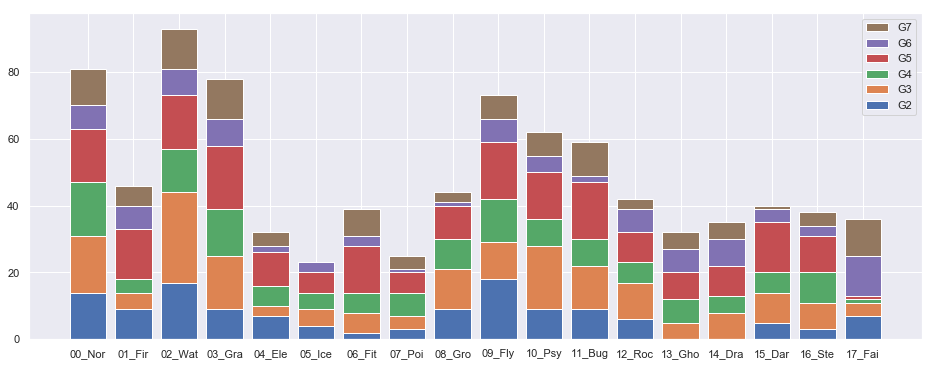
第一世代、イメージ通りゴーストやドラゴンはかなり希少だったようです(ゲンガーやカイリューなど)。更に鋼・悪・フェアリーは後世代から追加された新タイプということもあり、割合的にはかなり少なくなっています。その代わり何故かどくタイプがかなり多い。
一方、後継世代になると、どくタイプはキャラデザイン的にも人気がないのか、息してないです。二〜七世代全て足しても第一世代のどくタイプポケモンより数少ないです。
第六世代に至っては追加の毒ポケモンがクズモーとその進化系のドラミドロの2体しかいないです。今、環境で猛威を振るっているらしいフェアリータイプに刺さるどくタイプですが、開発側には不評なのかもしれません。
学習の前準備
seedの固定
再現性を保つために最低限のseedを以下の関数で固定しています。
# utils.py の一部を抜粋
def seed_everything(seed):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
data augmentation
data augmentation(データ拡張)とはなんぞやという方は以下の記事を参照ください。
今回は基本の二つプラスMixUpを使用して学習を行います。尚、TTA(Test Time Augmentation)は行いません。
def train_augmentation():
train_transform = [
albu.Resize(256, 256, interpolation=cv2.INTER_AREA, p=1),
albu.HorizontalFlip(p=0.5),
albu.RandomBrightness(p=0.5),
]
return albu.Compose(train_transform)
MixUpについては以下の様に実装しました。
def mixup(data, targets, alpha=1, n_classes=18):
indices = torch.randperm(data.size(0))
data2 = data[indices]
targets2 = targets[indices]
lam = torch.FloatTensor([np.random.beta(alpha, alpha)])
data = data * lam + data2 * (1 - lam)
targets = targets * lam + targets2 * (1 - lam)
return data, targets
入力はdata loaderから出力されるimage data と labelのテンソルです。出力結果については以下の様に可視化してみるとイメージつきやすいかと思います。
batch_iterator = iter(train_loader)
inputs, labels = next(batch_iterator)
inputs2, labels2 = mixup(inputs, labels)
mixup 前
print('label:', labels[0])
im1 = inputs[0].numpy().transpose(1, 2, 0)
plt.imshow(im1)
- label: tensor([0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
dtype=torch.float64)

mixup 後
print('label2:', labels2[0])
im2 = inputs2[0].numpy().transpose(1, 2, 0)
plt.imshow(im2)
- label2: tensor([0.0000, 0.2112, 0.0000, 0.0000, 0.7888, 0.0000, 0.0000, 0.0000, 0.0000,
0.7888, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.2112, 0.0000, 0.0000],
dtype=torch.float64)

mixupを適用すると、この様に二つの画像を重ね合わせた画像と、その配合割合(lam)を乗じたtargetのテンソルを返します。上記の例で例えると、元画像の正解ラベルは草1・飛行1タイプだったのに対し、変換後画像の正解ラベルは炎0.2112・草0.7888・飛行0.7888・悪0.2112になります。また、lamはnp.random.beta(alpha, alpha)を使って、ランダムに生成しています。
今回はHolizontalFlipを50%、RandomBrightnessを50%、mixupを25%の確率で適用させています。
ロスと評価関数
ロス関数
今回、targetは一つのクラス(炎単タイプ)の場合もあれば、二つの場合(炎+飛行タイプ)もあるマルチラベルの画像分類タスクになります。
通常、正解ラベルが一つの他クラス分類では、出力層の活性化関数としてソフトマックス関数、更にロス関数として、categorical-cross-entropy関数を使います。しかし今回は正解が1つとは限らないので、出力層の活性化関数としてsigmoid関数、ロス関数としてbinary-cross-entropyを使用します。
def criterion(logit, truth, weight=None):
logit, truth = logit.float(), truth.float()
loss = F.binary_cross_entropy(logit, truth, reduction='none')
if weight is None:
loss = loss.mean()
else:
pos = (truth>0.5).float()
neg = (truth<0.5).float()
pos_sum = pos.sum().item() + 1e-12
neg_sum = neg.sum().item() + 1e-12
loss = (weight[1]*pos*loss/pos_sum + weight[0]*neg*loss/neg_sum).sum()
return loss
上記のweight引数は正例、負例で重み付けをしたい時に使う引数です。今回はひとまずbase modelなのでNoneでいきたいと思います。
評価指標
評価指標ですが、以下の通り、複合タイプかそうでないかで条件分岐しようと思います。本当はthrsholdで区切って、該当クラスかそうでないかを予測していこうかと思ったのですが、それだとかなり厳しい気がしたので。(予測前に対象が単タイプか複合タイプか分かってしまうので、実質リークになってしまいますが、今回はスルーします。)
def metric(true, pred):
if np.sum(true)==1:
# 単タイプの場合、最も高い確率を出力したラベルと同じであれば1を返す。
if np.argmax(true)==np.argmax(pred):
return 1
else:
return 0
else:
# 複合タイプの場合、出力の高い上位二つのラベルとも正解の場合1を返す。
# 一つだけ正解の場合0.5を返す。
pred_max_idx = set(np.argpartition(-pred, 2)[:2])
true_max_idx = set(np.argpartition(-true, 2)[:2])
return 1 - len(true_max_idx - pred_max_idx)/2
その他
- 一回のバッチデータで得られるロスから更新するのではなく、数回(下記コードのbatch_multiplierで回数を定義)の平均で更新しています。こうすることによって、擬似的に大きなバッチサイズで学習した時と同じ様な効果をもたらします。
- trainとvalidの分割をランダムシャッフルしてしまうと、同じ種類のポケモンがtrainとvalidに存在してしますので、validation scoreが高く出てしまいます。今回は第七世代をvalidation、二〜六世代をtrain dataとして使用します。

モデルの学習
学習コードは以下の通りです。
import pandas as pd
import matplotlib.pyplot as plt
import time
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau
from torchvision import transforms
from efficientnet_pytorch import EfficientNet
from aug import train_augmentation, val_augmentation, mixup
from config import Config
from dataset import PokemonDataset
from loss import criterion
from utils import seed_everything, metric, load_typ_yml
export_model = './export_model'
export_figure = './export_figure'
train_csv_path = 'data/train.csv'
train_img_path = 'data/train'
config = Config()
num_epochs = config.num_epochs
seed = config.seed
batch_size = config.batch_size
device = config.device
batch_multiplier = config.batch_multiplier
use_mixup = config.use_mixup
train_aug = train_augmentation()
val_aug = val_augmentation()
transforms = transforms.Compose([
transforms.ToTensor(),
])
type_dic = load_typ_yml()
seed_everything(seed)
train = pd.read_csv(train_csv_path)
train, valid = train[:2680], train[2680:].reset_index(drop=True)
train_dataset = PokemonDataset(train, train_img_path, train_aug, transforms)
valid_dataset = PokemonDataset(valid, train_img_path, val_aug, transforms)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
loaders_dict = {'train': train_loader, 'val': valid_loader}
model = EfficientNet.from_pretrained('efficientnet-b0', num_classes=18)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer, factor=0.5, patience=2, cooldown=0)
def main():
torch.backends.cudnn.benchmark = True
num_train_imgs = len(loaders_dict['train'].dataset)
num_val_imgs = len(loaders_dict['val'].dataset)
batch_size = loaders_dict['train'].batch_size
logs = []
for epoch in range(num_epochs):
t_epoch_start = time.time()
epoch_train_loss = 0.0
epoch_val_loss = 0.0
epoch_train_score = 0.0
epoch_val_score = 0.0
print('-----------------------')
print(f'Epoch {epoch+1}/{num_epochs}')
print('-----------------------')
for phase in ['train', 'val']:
if phase == 'train':
model.train()
optimizer.zero_grad()
else:
model.eval()
count = 0
for img_batch, label_batch in loaders_dict[phase]:
if use_mixup:
mixup_flag = np.random.randint(use_mixup)==1
if mixup_flag:
img_batch, label_batch = mixup(img_batch, label_batch, alpha=1, n_classes=18)
img_batch = img_batch.to(device, dtype=torch.float)
label_batch = label_batch.to(device, dtype=torch.float)
if (phase=='train') and (count==0):
optimizer.step()
optimizer.zero_grad()
count = batch_multiplier
with torch.set_grad_enabled(phase == 'train'):
output = torch.sigmoid(model(img_batch))
if phase == 'train':
loss = criterion(output, label_batch)
loss /= batch_multiplier
loss.backward()
count -= 1
epoch_train_loss += loss.item() * batch_multiplier
for pred, label in zip(output, label_batch):
pred = pred.detach().cpu().numpy()
label = label.detach().cpu().numpy()
epoch_train_score += metric(label, pred)
else:
loss = criterion(output, label_batch)
loss /= batch_multiplier
epoch_val_loss += loss.item() * batch_multiplier
for pred, label in zip(output, label_batch):
pred = pred.detach().cpu().numpy()
label = label.detach().cpu().numpy()
epoch_val_score += metric(label, pred)
train_loss = epoch_train_loss / num_train_imgs
val_loss = epoch_val_loss / num_val_imgs
train_score = epoch_train_score / num_train_imgs
val_score = epoch_val_score / num_val_imgs
t_epoch_finish = time.time()
print(f'epoch: {epoch+1}')
print(f'Epoch_Train_Loss: {train_loss:.3f}')
print(f'Epoch_Val_Loss: {val_loss:.3f}\n')
print(f'Epoch_Train_Score: {train_score:.3f}')
print(f'Epoch_Val_Score: {val_score:.3f}\n')
print('timer: {:.3f} sec.'.format(t_epoch_finish - t_epoch_start), '\n')
t_epoch_start = time.time()
for g in optimizer.param_groups:
print('lr: ', g['lr'], '\n\n')
log_epoch = {
'epoch': epoch+1,
'train_loss': train_loss,
'val_loss': val_loss,
'train_score': train_score,
'val_score': val_score,
}
logs.append(log_epoch)
df = pd.DataFrame(logs)
df.to_csv(f'{export_model}/log.csv', index=False)
torch.save(model.state_dict(), f'{export_model}/model_epoch{epoch+1}.pth')
scheduler.step(val_loss)
df = pd.read_csv(f'{export_model}/log.csv')
plt.plot(df['train_loss'], label='train loss')
plt.plot(df['val_loss'], label='val loss')
plt.legend()
plt.savefig(f'{export_figure}/loss.png')
plt.close()
plt.plot(df['train_score'], label='train score')
plt.plot(df['val_score'], label='val score')
plt.legend()
plt.savefig(f'{export_figure}/score.png')
plt.close()
if __name__ == "__main__":
main()
ネットワークの精度検証
結果
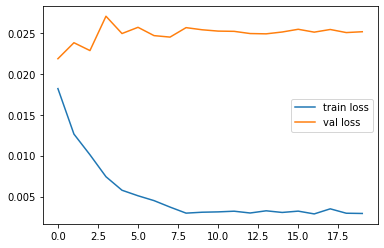
【ロスの推移】
【スコア(Accuracy)の推移】
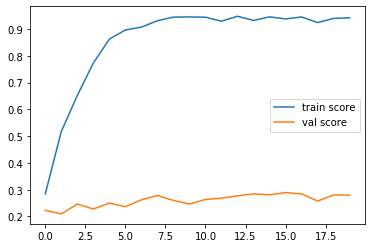
正直、もう少し期待していたのですが全然ダメでした。ここから色々工夫すればスコアを伸ばせる可能性もあるとは思うのですが、スタートがこのレベルだとかなり厳しい気がします。そもそも集めた画像の品質も良くないので、それもスコアが上がらない原因の一つかも知れません。背景色とか画像の質感、サイズもバラバラなので。
ただ、trainに関しては、かなり高スコアなので、一度インプットしたポケモンに関しては、ほぼほぼ正確にタイプを推論できることが分かりました。
この結果で、この記事も企画倒れ感否めない感じになってしまいましたが、いよいよ第一世代(151体、616枚の画像データ)の予測精度の確認です。一応、validation scoreが最も高かったepoch時のmodelをロードしています。
結果 Accuracy(正解率): 0.369
!?
思ったより悪くない(笑)第七世代だと決して30%を超えることなかったscoreが37%弱まで上がっています。18タイプの中から選んで正解率37%なので、そんなに的外れな予想でもない気がすると同時に、やはり第一世代はデザイン的にタイプの特性を色濃く出しているという仮説も正しいかも知れません。
おまけ
以下の写真のタイプを予測してみました。

予想上位5つの結果(分かりやすい様に百分率表記)
| タイプ | 出力 |
|---|---|
| はがね | 52% |
| あく | 26% |
| エスパー | 23% |
| むし | 8% |
| 水 | 1% |
予想以上に納得感のある結果で驚きました(笑)
デザイン的にもそうですが、映画でもアイアンスパイダーマンとか出てくるし、旧作ではベノムに寄生されてダークになったりするし、そういう素質ありそうです。できれば虫タイプが1番に来て欲しいところでしたが、4位につけているのでまずまずかと。
タイプ毎の分析
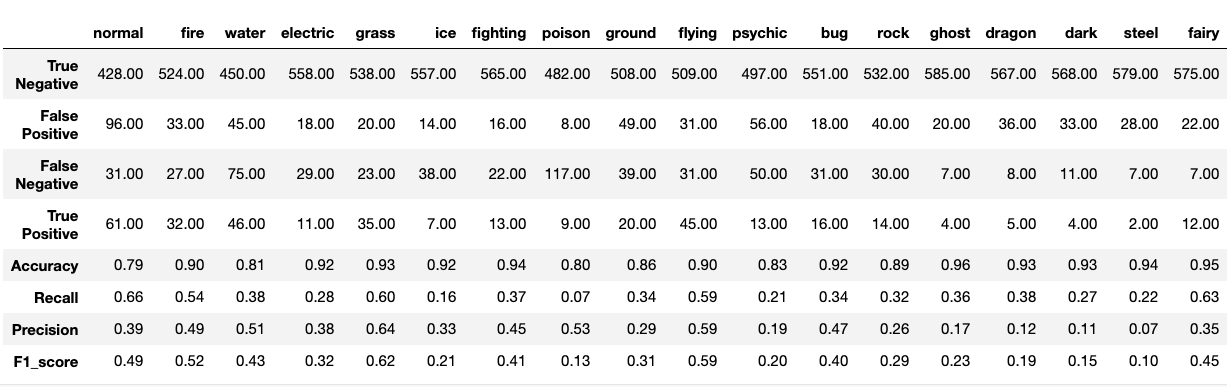
下記は、タイプ毎に切り分けた結果です。
上記を分かりやすくするためにF値だけ棒グラフ化してみました。
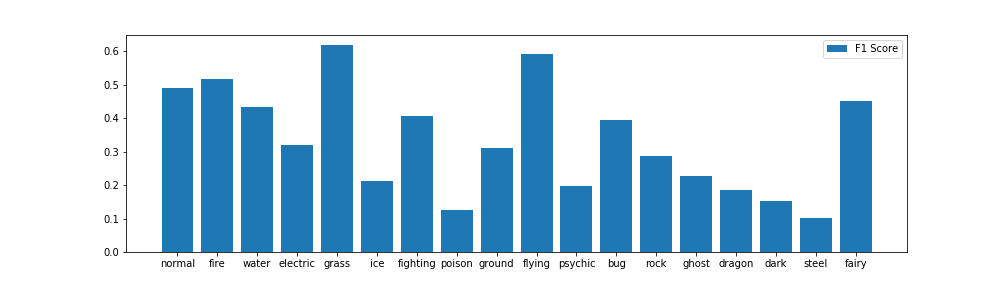
この結果をみると、草・飛行・炎・ノーマルあたりのスコアが高く、他世代と分布に大きな差が見られた毒タイプのスコアが低いことが分かります。117枚の画像をFalse Negative(本当は毒タイプだが、他のタイプで予測している)していますが、テーブルを見てもこれはダントツの数字です。
スコアの高いタイプに関しては、個人的にその特徴も色濃く出ているポケモンが多い気がするので(色とか)、個人的に納得感を持てる結果となりました。