記事の内容
ローカル上のCSVファイルにあるデータをDynamoDB上に登録する。また現在時点のDynamoDBのデータをローカルにCSV出力する必要が出てきたため、簡易的な実装を行いました。メモがてら記事に。尚、DyanmoDBのScan操作については1回のリクエストにつき、最大1MBまでしかデータを取得できないので、それ以上のデータをダウンロードしたい場合、別の実装を行う必要があります。
構成とDB外観
構成
構成は以下の通りです。DynamoDBへアクセスする度にログが残るよう、ClaoudWatchと連携しています。

DB外観
テーブル名がkokyakuパーティションキーがidとなっています。今回はサンプルとして予め2件のデータを登録した状態でスタートします。
IAMロール
まず始めにIAMロールを作成します。ここでロールを作成せずとも後述のLambda作成のタイミングでそちらの画面上からIAMロールを作成することもできるのですが、そうやって作成されたロールを別に作成したLambda関数にアタッチするとデフォルトで作成されるはずのCloudWatchロググループが作成されない現象が起こってしまいます。なので、予めロールから先に作ってしまった方が何かと良いかと思います。
ロールですが、DyanomoDBとCloudWatchへのアクセスポリシーが必要になります。[ロールの作成]->[一般的なユースケースでLambdaを選択]した後、以下の2つのポリシーをアタッチします。

Lambda
ソースコードはこちら
import json
import boto3
from boto3.dynamodb.conditions import Key
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('kokyaku')
def table_scan():
scan_data = table.scan()
items = scan_data['Items']
# scanしたデータのログ出力
print(items)
return items
def table_put(id, mail, phone):
response = table.put_item(
Item={
'id': id,
'mail': mail,
'phone': phone
}
)
# HTTPステータスコードが正常だった場合レスポンスログ出力
if response['ResponseMetadata']['HTTPStatusCode'] != 200:
print(response)
else:
print('Successed.')
return response
def lambda_handler(event, context):
# event log の出力
print(event)
operation = event['operation']
try:
if operation == 'scan':
return table_scan()
elif operation == 'put':
id = event['id']
mail = event['mail']
phone = event['phone']
return table_put(id, mail, phone)
except Exception as e:
print("Error Exception.")
print(e)
Lambda上でテストケースを作成し、挙動を確認します。
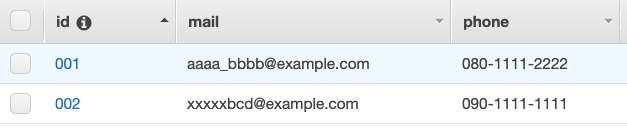
テストケース1とそのレスポンス
テストケース
{
"operation": "scan"
}
レスポンス
[
{
"id": "001",
"mail": "aaaa_bbbb@example.com",
"phone": "080-1111-2222"
},
{
"id": "002",
"mail": "xxxxxbcd@example.com",
"phone": "090-1111-1111"
}
]
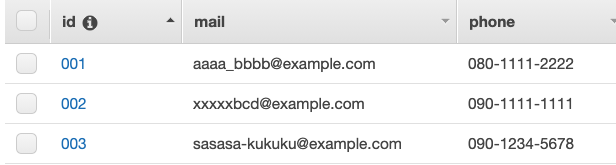
テストケース2と結果
テストケース
{
"operation": "put",
"id": "003",
"mail": "sasasa-kukuku@example.com",
"phone": "090-1234-5678"
}
結果
API Gateway
次にAPI Gatewayを実装していきます。メソッドはGETとPUTを用意し、DBからデータを取得してくる方(SCAN)をGET、DBにデータを登録する方(PUT)をPOSTで実装します。
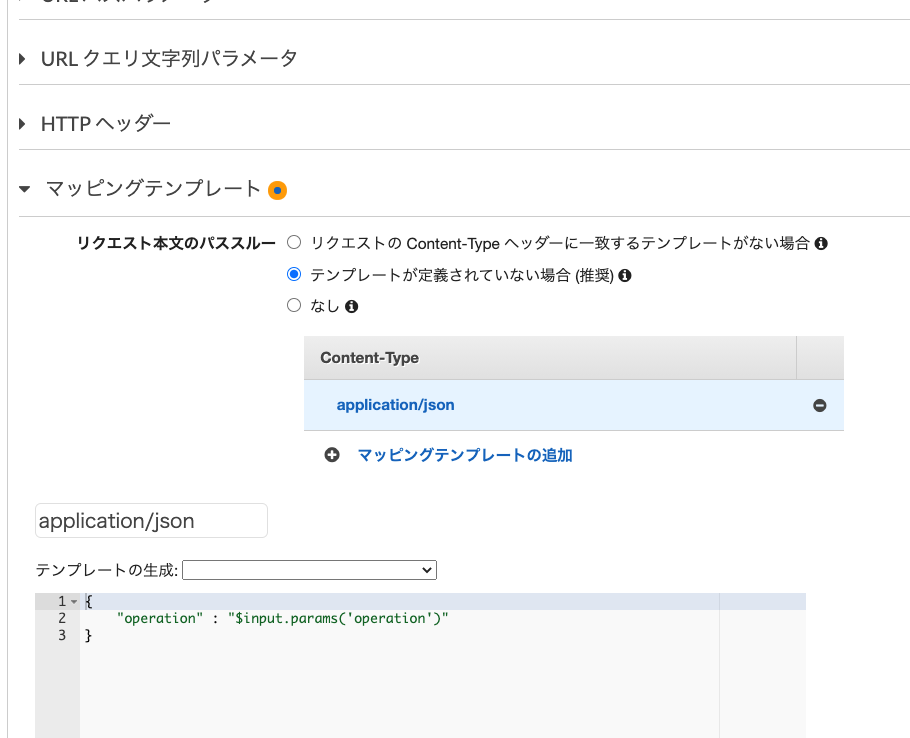
まずGETのメソッドを作成し、先ほど作成したLambda関数をアタッチすることで、Lambda関数がわのトリガーとして現在作成中のAPI Gatwayが設定されます。次に[統合リクエスト]から以下のようにマッピングテンプレートを設定します。
作成したところでAPIのテストを行います。
からクエリ文字列にoperation=scanを渡し、テストボタンを押下します。ステータスコード200とともに以下のレスポンスが返ってくるかと思います。
[
{
"id": "001",
"mail": "aaaa_bbbb@example.com",
"phone": "080-1111-2222"
},
{
"id": "003",
"mail": "sasasa-kukuku@example.com",
"phone": "090-1234-5678"
},
{
"id": "002",
"mail": "xxxxxbcd@example.com",
"phone": "090-1111-1111"
}
]
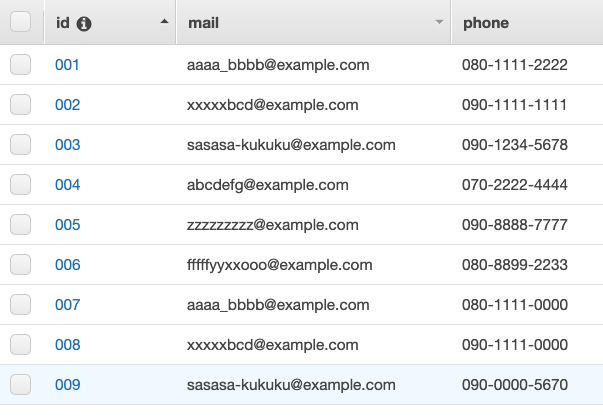
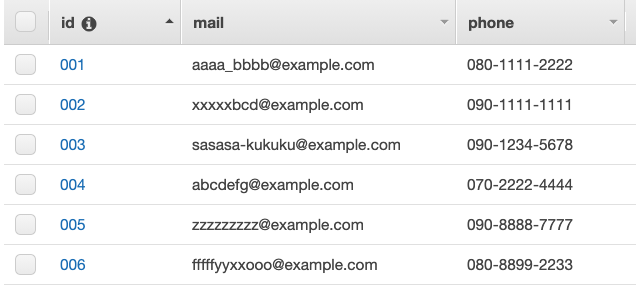
テストが成功するのを確認したのち、任意のステージ名にAPIをデプロイします。更に生成されたエンドポイントが正常に動作していることを確認するために {生成されたエンドポイント}?operation=scanのURLをブラウザから叩いてみます。
(沢山、関係ないデータが出ていますがこの後の操作で色々データを追加した後にURLを叩いているだけなので気にしないでください。)

同様の方法でにPOSTメソッドも実装します。実装後は以下のようにコマンドを叩いて挙動を確認します。jqコマンドをパイプで渡すことで、レスポンスを整形しています。
$ curl -X POST '{生成されたエンドポイント}?operation=put&id=006&mail=fffffyyxxooo@example.com&phone=080-8899-2233' | jq
結果
ローカルの実装
ローカルのディレクトリ構成は以下の通りです。
.
├── DynamoDB.csv // DynamoDBからエクスポートした結果
├── input.csv // DynamoDBに新規登録するデータ
└── main.py
main.pyのコードはこちら
import argparse
import json
import requests
import pandas as pd
SCAN_ENDPOINT = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
PUT_ENDPOINT = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
parser = argparse.ArgumentParser()
parser.add_argument('-o', '--operation', type=str, required=True)
args = parser.parse_args()
OPERATION = args.operation
def main():
if OPERATION == 'scan':
url = SCAN_ENDPOINT + '?' + f'operation={OPERATION}'
res = requests.get(url)
res = res.json()
ids, mails, phones = [], [], []
for row in res:
ids.append(row['id'])
mails.append(row['mail'])
phones.append(row['phone'])
df = pd.DataFrame()
df['id'] = ids
df['mail'] = mails
df['phone'] = phones
df = df.sort_values('id')
df = df.reset_index(drop=True)
df.to_csv('DynamoDB.csv', index=False, header=['id', 'mail', 'phone'])
print(df.head())
if OPERATION == 'put':
df = pd.read_csv('input.csv', dtype=str)
cnt = 0
for i in range(df.shape[0]):
idx = df.iloc[i, 0]
mail = df.iloc[i, 1]
phone = df.iloc[i, 2]
url = PUT_ENDPOINT + \
'?' + f'operation={OPERATION}' + \
f'&id={idx}&mail={mail}&phone={phone}'
res = requests.post(url)
status_code = res.status_code
if status_code != 200:
print(f'Error {status_code}')
print(f'ID:{id} was not registered.')
else:
cnt += 1
if cnt == df.shape[0]:
print('\nAll data success.')
if __name__ == '__main__':
main()
DynamoDBからCSVをエクスポート
以下のようにコマンドライン引数を渡すことでDynamoDBのデータをCSVファイルとしてエクスポートできます。
$ python main.py -o scan
出力されたCSV
id,mail,phone
001,aaaa_bbbb@example.com,080-1111-2222
002,xxxxxbcd@example.com,090-1111-1111
003,sasasa-kukuku@example.com,090-1234-5678
004,abcdefg@example.com,070-2222-4444
005,zzzzzzzzz@example.com,090-8888-7777
006,fffffyyxxooo@example.com,080-8899-2233
ローカルCSVファイルのデータをDynamoDBに新規登録
$ python main.py -o put
ローカルCSV
id,mail,phone
007,aaaa_bbbb@example.com,080-1111-0000
008,xxxxxbcd@example.com,090-1111-0000
009,sasasa-kukuku@example.com,090-0000-5670
結果