個人の備忘録として、改めてNULLの扱いには気をつけないといけないなと思ったのでブログとして残しておきます。
問題のクエリ
サンプルとして以下のクエリをBiqQueryに投げてみます。
sample.sql
create or replace table `project_id.dataset.table`
(
id int64
, ratio float64
, check string
);
insert into `project_id.dataset.table`
values
(1, 0.2, 'takashi'),
(1, 0.3, 'ichiro'),
(1, null, 'ken'),
(1, null, 'takashi'),
(2, 0.5, 'ichiro'),
(2, null, 'yusuke'),
(2, null, 'atsushi'),
(2, 1.2, 'taro'),
(3, null, 'jiro'),
(3, null, 'saburo'),
(3, null, 'taro')
;
/*
実行の度に結果が変わってしまう
*/
select
*
, row_number() over(partition by id order by ratio) as rn
from
`project_id.dataset.table`;
前半2つはテーブルを作成しているだけなので特に問題ないと思います。3つ目もよくあるパターンだと思いますが、window関数を使ってidが同じgroupの中で、ratioの順序情報をrnカラムとして定義している形になります。
そして肝心の結果ですが、以下のように実行のタイミングで異なるケースが出力されてしまうパターンがありました。
| case1 | case2 |
|---|---|
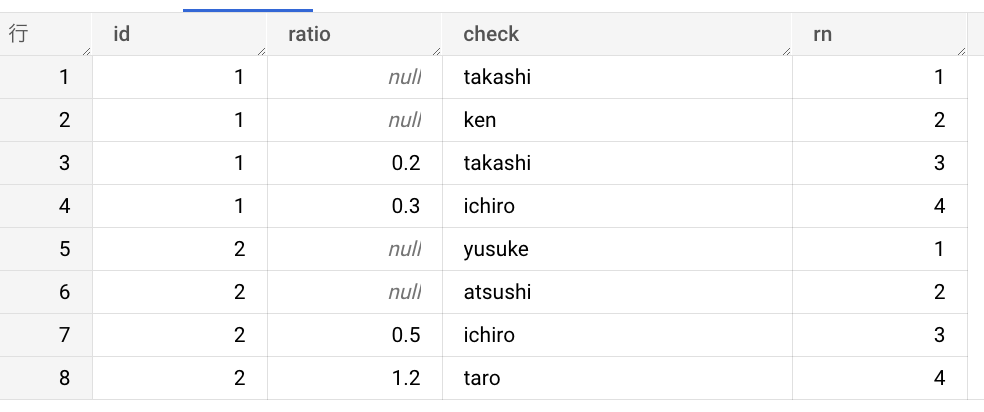 |
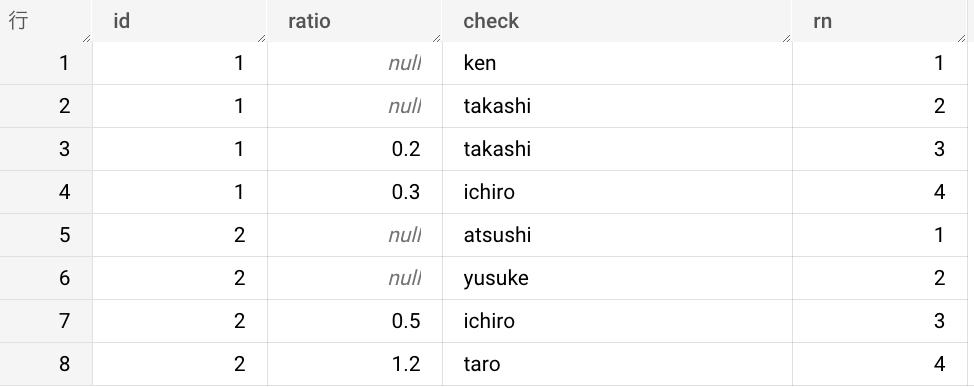 |
対応
普段のソートと違ってグループ内順序を考慮していきたいケースにおいて、予期せぬバグを産んでしまう可能性もある挙動だと思います。sortがstableなのかどうか意識が抜けてしまう可能性も大いにあるかなと。
なので、もし同順位であることを明示的に示したい場合、row_numberでなく積極的にrankを使うのも一つの手であるかもしれません。
そうすることでnullに関して以下のような形でrankingが当てられます。勿論割り当てられる数字がユニークでなくなる事には注意が必要ですが。
sample2.sql
/*
row_number -> rank へ変更
*/
select
*
, rank() over(partition by id order by ratio) as ranking
from
`project_id.dataset.table`;
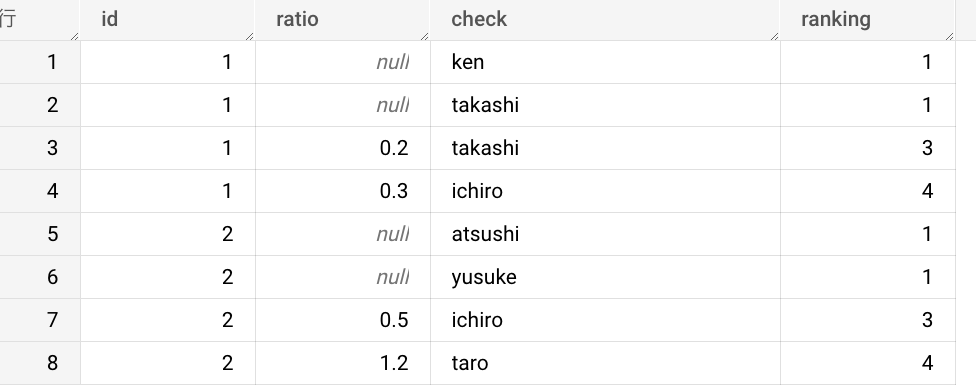
いずれのパターンにせよ、row_numberとrankの挙動の違いを意識することは大切そう。