はじめに
私は10年目のシステムエンジニアです。
これまではVM、Load Balancer、ストレージといったIaaS領域が主戦場でした。
今年からモダン開発に関わり、Azure PaaS と CI/CD Pipelines を組み合わせた環境構築を担当することになりました。
正直、VMがコンテナになるだけでしょ? くらいに高をくくっていましたが、「PaaSの種類の多さ」「権限設計の厳密さ」「ログの追跡難易度」 に直面し、何度も壁にぶつかりました。
本記事は、私が実際にハマり、そして解決したポイントを「IaaS脳からの脱却」という視点でまとめたものです。
対応プロジェクト概要
本プロジェクトは、既存のIaaS WebアプリケーションをAzure PaaSへ移行し、インフラ構築、デプロイ、運用プロセス全体をモダン化することが求められました。
採用した主要技術
| 分野 | 採用リソース / ツール |
|---|---|
| アプリケーション | Azure App Service (コンテナ化) |
| インフラ | IaCツール(Terraform) |
| CI/CD | Bitbucket Pipelines |
| データベース | Azure Database for PostgreSQL |
| 機密情報管理 | Azure Key Vault |
| 監視/ログ | Azure Monitor (Log Analytics、Application insights) |
環境構成
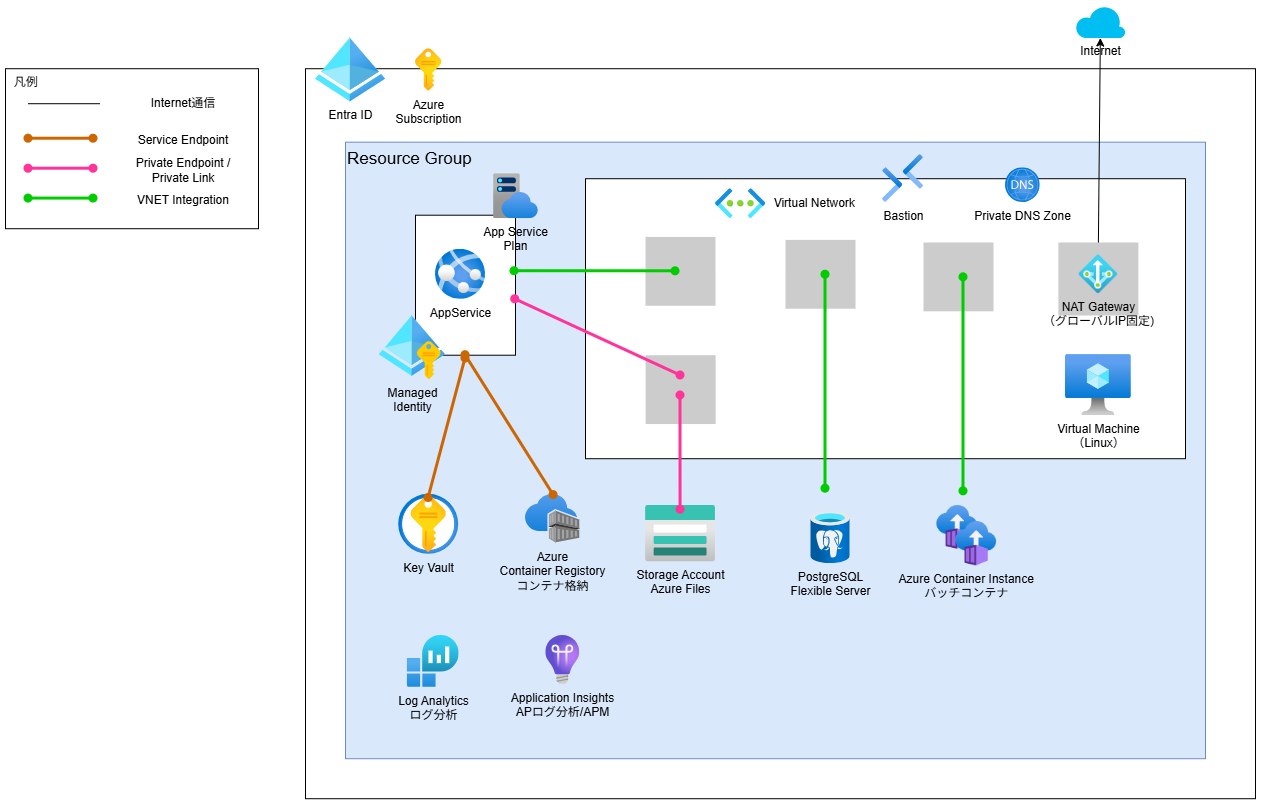
苦労したポイントと対処法
1) PaaSの「種類多すぎ問題」と選定の軸
IaaSなら「スペック(CPU/メモリ)を見極めてVMを立てる」のが基本ですが、PaaSは選択肢が多く「どれが適切?」と混乱しました。
苦労したこと:
Webアプリを動かすだけで App Service, Container Apps, Functions と選択肢があり、それぞれの特性(VNET統合、タイムアウト時間、スケーリング)が分からなかった。
対処法:
最初は以下のマッピングで整理すると、IaaSエンジニアにとって腹落ちしやすかったです。
| サービス名 | IaaSエンジニア視点のイメージ | 選定基準 |
|---|---|---|
| App Service | 管理されたIIS/Tomcat | 既存のWebアプリをそのまま移行したい。VNET統合や常時起動が必要。最もIaaSに近い感覚。 |
| Azure Functions | イベントトリガースクリプト | 定期実行バッチや、APIの裏側だけ動かしたい(常駐させない)。 |
| Container Apps | 簡易なKubernetes | マイクロサービス化したい、0→1のスケーリングを厳密にやりたい場合(少し学習コスト高)。 |
最初は App Service (Web Apps for Containers) が一番「サーバーの感覚」を残しつつPaaSの恩恵を受けられるため、迷ったらここから始めるのが無難でした。
2) ネットワーク分離の「見落とし」と SKU選定の壁
IaaSではVMをVNetに入れるのは当然でしたが、PaaSリソースの多くはデフォルトでパブリックアクセスが許可されています。
そのネットワーク分離を可能にする機能が、リソースのSKU(プラン)によって制限されるという点が、IaaS脳で見落としがちな大きな壁でした。
苦労したこと:
- バックエンドサービス(Key Vault, DBなど)へプライベートアクセスしたい時、VNet統合やPrivate Endpointなど何を使えばいいのか、両方必要な場面があるのか、判断に苦労しました。
- セキュリティ機能の存在は把握していたが、どの機能がどのSKUで利用可能かを事前に把握しておらず、リソース再作成の手間が発生しました。
対処法:
残念ながら、ここは各リソース固有の仕様に依存します。
その為、必ず採用するPaaSリソースの公式ドキュメントを参照し、VNet統合またはPrivate Endpointのどちらが適切か、またそれを実現するのに必要なSKU/エディションを確認するようにしました。
3) マネージド ID と RBAC による「最小権限」の壁
苦労したこと:
IaaS時代は「とりあえずContributor(共同作成者)をつけておけばOK」で済ませがちでしたが、自動化の世界ではそれが大きなセキュリティリスクになります。
また、環境変数にパスワードをベタ書きする「秘匿情報の管理」も課題でした。
対処法:
「誰が」「何を」するのかを分解し、「マネージド ID (Managed Identity)」 を徹底活用しました。
- Bitbucket Pipelines (CI/CD) に渡す権限
- スコープ: サブスクリプション全体ではなく、「対象リソース」のみに限定。
- ロール: AcrPush (コンテナレジストリへのPushのみ)や、KeyVaultSecretUser(Key Vaultのシークレット参照)など最小限で付与。
- マネージド ID によるパスワードレス接続
- DB接続やKey Vault参照において、接続文字列(ID/Pass)をアプリに持たせるのをやめ、リソースそのもの に権限を付与。
- 例えば、App ServiceのマネージドIDを有効化し、Key Vault 側でそのIDに対してのみログイン許可を出す。これで「パスワード漏洩」のリスクを構造的に排除できました。
4) ログが見えない? Azure Monitor での調査術
「サーバーに直接入ってログを見る」ことができないPaaSでのトラブルシューティングは、最も戸惑うポイントでした。
苦労したこと:
ログの出力先や種類がサービスによって異なり、どこを見ればよいかわからなかった。
App Serviceの場合、「ログストリーム」を見ても流れてこない(または流れすぎて追えない)ことが頻発した。
対処法:
「診断設定」をONにし、Log Analytics ワークスペースへ集約することが必須です。
集約後は、Log Analytics のクエリ言語である KQL (Kusto Query Language) にて、複数のログソースを横断的に検索することが可能になります。
例えば、AppServiceでは以下の3つのテーブルを使い分けるの必要がありました。
| テーブル名 | ログ内容 |
|---|---|
| AppServiceConsoleLogs | 標準出力・標準エラー出力。 アプリが吐いた生ログはここにあります。 |
| AppServiceHTTPLogs | IIS/Nginxレベルのアクセスログ。 ステータスコード 500 が出ているか等はここで確認。 |
| AppServicePlatformLogs | コンテナの起動失敗やDocker pullエラーなど。 アプリが動く「手前」の問題はここにある。 |
アプリ内部の深い挙動(依存関係のパフォーマンスや例外)を追うなら、Application Insights を併用すると、IaaS時代のログ調査よりも圧倒的に楽になります。
5) CI/CDパイプラインでの「環境別リリース」設計
苦労したこと:
開発(Dev)、検証(Staging)、本番(Prod)といった複数環境へのデプロイを、コード(yaml)の冗長性を避けつつどう切り分けるか。
対処法:
Bitbucketの 「Deployments」 機能を活用しました。これにより、yaml内のコードは共通化しつつ、環境ごとに異なる変数(ACR名やWebアプリ名)を注入できます。
# bitbucket-pipelines.yml の例
definitions:
steps:
- step: &docker-build
name: Build & Push Docker Image
image: mcr.microsoft.com/azure-cli
script:
# 変数 $AZURE_APP_NAME は Deployment 側で環境別に定義
- docker build -t $ACR_NAME/app:$TAG . ...
services:
- docker
pipelines:
custom:
dev-container-build:
- stage:
# ここで指定した環境の変数が読み込まれる
deployment: Development
name: Deploy (Dev)
steps:
- step: *docker-build
stg-container-build:
- stage:
# ここで指定した環境の変数が読み込まれる
deployment: Staging
name: Deploy (Stg)
steps:
- step: *docker-build
【番外編】AI 活用による Terraform 開発の高速化
今回のプロジェクトでは、インフラ構築の IaC 化(Terraform)を、AI(GitHub Copilot )とのペアプログラミングによって進めました。
Terraform 初体験かつ、PaaS という未知の領域の IaC を扱う際、AI は以下の 2 点で開発効率を劇的に向上させました。
-
ベースラインを即時生成
Azure PaaS のようにリソースの依存関係が複雑な場合、どのリソースを、どのような順番で書くべきかというリファレンス参照のコストが膨大になります。
AI に「App Service(VNet 統合かつ Private Endpoint)、PostgreSQL Flexible Server(VNet統合)」といった要件を伝え、ベースラインとなるコードを生成させることで、初動調査にかかる時間を最低限に抑えることができました。 -
Terraform コードからの逆生成により、設計書の管理が容易に
従来のインフラ管理では、リソース修正時の設計書やパラメータシートの変更漏れが大きなリスクでした。
AI を活用することで、Terraform のコード(HCL)を基に、AI でパラメータ一覧を抽出・整形し、パラメータシートを自動生成しました。
これにより、これにより、コードと設計書の齟齬というリスクを排除し、品質向上に繋がりました。
実践チェックリスト(IaaSエンジニア向け)
PaaS運用を始める前に、確認しておくこと。
- 接続はパスワードレスか?(マネージド ID 活用)
- アプリからDBやKey Vaultへの接続に、接続文字列やパスワードを直接利用せず、マネージド ID (Managed Identity) を有効化し、リソースレベルでのアクセス制御を行っているか?
- ネットワーク分離とSKU選定の整合性
- バックエンドリソースへのアクセス遮断に必要なSKU(プラン)を選定し、VNet統合とPrivate Endpoint**を適切に使い分けているか?
- ログの収集先は一元化されているか?(診断設定)
- PaaSリソースの診断設定 (Diagnostic settings) を有効化し、ログを Log Analytics ワークスペースへ漏れなく集約しているか?
- アプリケーションの性能情報や例外は Application Insights で構造化して収集しているか?
- 環境ごとの設定を外部化しているか?(CI/CDの変数管理)
- 開発、ステージング、本番といった環境固有の変数は、コードに埋め込まず、Bitbucketの Deployments 機能や Secret Storeで一元管理しているか?
- 権限は最小限かつ定期見直し可能な設計か?(RBACとスコープ)
- CI/CDや各リソースへのアクセス権限は、必要な操作ができる最小限のロールに絞り、そのスコープ(範囲)をリソースグループ単位以下に限定しているか?
まとめ:IaaS脳からPaaS脳への「思考の転換」
本記事は、IaaSからAzure PaaSとCI/CDの運用に挑むエンジニアが直面する 「5つの壁」 と、それを乗り越えるための具体的な方法を紹介しました。
PaaS運用の本質は、「サーバー管理」から「アクセス管理とデータ管理」への思考の転換です。
IaaS脳から脱却するために意識すべき主要なポイントは以下の通りです。
- サーバーのスペックから特性とSKUへ
| IaaS脳での思考 | PaaS脳での思考 |
|---|---|
| VMのスペックを見極めればいい。 | サービスが常時稼働かイベント駆動かでサービス(App Service, Functionsなど)を選定する。 |
| ネットワーク分離はVNetに入れるだけ。 | 必要な機能(VNet統合/Private Endpoint)を動かす最小SKUは何か?を優先して確認する。 |
- 直接操作から自動化と最小権限へ
| IaaS脳での思考 | PaaSの腕の思考 |
|---|---|
| SSH/RDPでサーバーに入り、手動で設定する。 | CI/CDパイプラインを唯一のデプロイ手段とし、環境固有設定は外部変数で管理する。 |
| 認証情報は環境変数に設定、権限はContributorで済ませる。 | 認証情報はマネージド ID(パスワードレス)でリソースに付与し、CI/CDの権限は最小ロールに限定する。 |
最初は「ブラックボックス」に見えた PaaS も、ログの参照場所や権限の通り道、そして CI/CD による環境ごとのデプロイ管理を理解できれば、IaaSよりも運用が格段に楽になります。
本記事が、これから Azure PaaS と CI/CD に挑戦される方の一助となれば幸いです。
We Are Hiring!