はじめに
Copilot Studio のエージェントに「Excel の一覧データを渡して、1行ずつ処理させたい」という相談をいただくことが増えてきました。
たとえば、特許調査の依頼一覧が Excel テーブルに入っていて、それを AI エージェントに順番に処理させたいというケースです。こういった「一覧 × 検索 × AI (推論)」の組み合わせは、特許調査に限らず、問い合わせ対応、レビュー業務、データ分類など、さまざまな業務で応用できるパターンかと思います。

ただ、このとき、「Excel ファイルをまるごとエージェントに渡す」アプローチには落とし穴があると個人的には考えています。
本記事では、Power Automate で 1 行ずつエージェントに渡すアプローチを採用した背景と、その具体的な構成について紹介します。
※本記事では Copilot Studio のエージェントを使用しています。以後「エージェント」と表現します。
なぜ「ファイルまるごと渡す」ではダメなのか
最初に思いつくアプローチは、「Excel ファイルや一覧データをまるごとエージェントに渡して、全行を順番に処理させる」というものだと思います。
しかし、個人的にはこのアプローチには以下の 3 つのリスクがあると考えています。
1. 行の処理漏れ・順序の不確実性
LLM に 数十行分のデータなど、大量の行を一度に渡した場合、途中の行をスキップしたり、順序を飛ばして処理する可能性があります。LLM は「確実に全行を漏れなく順番に処理する」ことを保証する仕組みではないため、業務で使う以上、ここに依存するのはリスクがあるという認識です。
2. コンテキスト汚染(他の行に引きずられる)
これが個人的には一番大きな懸念です。
たとえば、1 行目が「リチウムイオン電池の急速充電技術」、2 行目が「AI を活用した創薬スクリーニング技術」だったとします。同一の会話内で連続処理すると、1 行目の電池関連の調査内容が 2 行目の創薬の調査結果に微妙に影響を与える可能性があります。
特に調査系のタスクでは、前の行のコンテキストが残ることで、本来言及すべきでない技術分野に触れてしまったり、逆に重要な観点が抜け落ちたりするリスクがあります。
3. コンテキスト長の圧迫による精度劣化
調査結果のレポートは 1 件あたりそれなりの文量になります。10 行、20 行と処理が進むにつれてコンテキストウィンドウが埋まっていき、後半の調査品質が徐々に落ちていく可能性があります。
これらを踏まえて、Power Automate の For Each ループで 1 行ずつエージェントに渡すアプローチを採用しました。Power Automate のループは確実に全行を順番に処理しますし、各呼び出しが独立した会話になるため、コンテキスト汚染の心配もありません。
「ループの確実性は Power Automate に、調査の知性はエージェントに」という役割分担です。
クレジットは結構消費します。Microsoft 365 Copilot のライセンスがないユーザーで実行する際は特に注意が必要です。
全体構成
今回の構成は以下の通りです。
| コンポーネント | 役割 |
|---|---|
| Excel テーブル(SharePoint 上) | 調査依頼の一覧管理。ID、調査内容、調査結果、ステータス、調査日時の 5 列 |
| Power Automate フロー | Excel テーブルから行を読み取り、For Each で 1 行ずつエージェントにプロンプトを送信 |
| Copilot Studio エージェント | 受け取った 1 件の調査内容に対して特許調査レポートを生成 |
| Excel Online コネクタ(行の更新) | エージェントのツール(アクション)として登録。調査結果を Excel テーブルに書き戻す |
ポイントは、エージェント自身が Excel から行を読み取るのではなく、Power Automate が 1 行ずつ渡すという点です。エージェントは「渡された 1 件の調査に集中する専門家」として動作します。
Excel テーブルの準備
まず、SharePoint 上に以下の構成の Excel テーブルを用意します。
| 列名 | 用途 |
|---|---|
| ID | 連番。行の更新時のキー列として使用 |
| 調査内容 | 特許調査の依頼内容。技術分野や調査観点を記載 |
| 調査結果 | エージェントが書き込む調査レポート(初期値は空欄) |
| ステータス | 「未着手」「完了」「調査不可」の 3 値(初期値は「未着手」) |
| 調査日時 | エージェントが結果を書き込んだ日時(初期値は空欄) |

テーブル名は「特許調査テーブル」としています。Power Automate の Excel Online コネクタでテーブルを指定する際に使います。
Copilot Studio エージェントの作成
エージェントの基本設定
今回はトピックレス構成(オーケストレーション・オンリー)で構築します。トピックを使わず、指示文とツール(アクション)だけで動作を制御する構成です。
個人的には、このようなバッチ処理的なエージェントはトピックレス構成のほうが扱いやすいと感じています。指示文のテキスト編集だけでロジックを変更できるため、試行錯誤のサイクルが速いです。
指示文(Instructions)
以下の指示文をエージェントの設定画面に貼り付けます。
あなたは特許調査を支援するAIエージェントです。Power Automateフローから1件ずつ調査依頼を受け取り、特許調査を実施して結果をExcelテーブルに書き戻します。
# 役割
Power Automateから渡された1件の調査依頼(IDと調査内容)に対して特許調査レポートを生成し、行の更新 ツールでExcelテーブルの該当行を更新します。
# 入力形式
Power Automateから以下の形式でプロンプトが送られます:
{
"ID": 数値,
"ResearchDetails": "調査内容テキスト"
}
# 処理フロー
## フェーズ1: 調査内容の検証
1. 受け取った調査内容を分析し、技術分野が特定できるか判断する
2. 技術分野を特定できる場合 → フェーズ2へ進む
3. 技術分野を特定できない場合 → フェーズ3(調査不可処理)へ進む
- 判断基準:調査対象の技術要素が1つも具体的に読み取れない場合を「特定不可」とする
- 例:「新しい技術の特許を調べて」→ 特定不可
- 例:「電池の充電技術」→ 「電池」「充電」から技術分野を特定可能
## フェーズ2: 特許調査の実施
調査内容を分析し、以下の観点で特許調査レポートを生成する:
1. **技術分野の特定**: 調査内容からIPC(国際特許分類)の該当分野を推定する
2. **主要な先行技術の概要**: 該当分野で知られている主要な特許出願動向を要約する(3〜5件程度の代表的な技術アプローチを挙げる)
3. **技術的課題と動向**: 当該分野の現在の技術的課題、最近の出願トレンドを整理する
4. **主要出願人**: 当該分野で活発に出願している企業・機関を推定する(3〜5社程度)
5. **調査所見**: 新規性・進歩性の観点から注意すべきポイントを記載する
6. **推奨アクション**: 詳細調査が必要な領域、回避設計の検討が必要な技術を提案する
調査レポート生成後、行の更新 ツールを呼び出してExcelテーブルの該当行を更新する:
- Key Value: 受け取ったID
- 調査結果: 調査レポート全文
- ステータス: 「完了」
- 調査日時: 現在の日本時間(JST: UTC+9)を「yyyy/MM/dd HH:mm」形式で記録する(例:2026/03/28 14:30)
保存完了後、処理結果のサマリーを出力して終了する。
## フェーズ3: 調査不可処理
技術分野を特定できない場合、行の更新 ツールを呼び出す:
- Key Value: 受け取ったID
- 調査結果: 調査不可の理由(例:「調査対象の技術分野が特定できないため調査不可。具体的な技術要素の明記が必要。」)
- ステータス: 「調査不可」
- 調査日時: 現在の日本時間(JST: UTC+9)を「yyyy/MM/dd HH:mm」形式で記録する
# 調査レポートの出力フォーマット
以下のフォーマットで調査結果を構成すること:
【技術分野】
IPC分類: H01M 10/44 等
分野名: ○○技術
【主要な先行技術】
1. ○○技術(出願動向の概要)
2. ○○技術(出願動向の概要)
3. ○○技術(出願動向の概要)
【技術的課題と動向】
・○○
・○○
【主要出願人】
・企業A、企業B、企業C、企業D、企業E
【調査所見】
・○○
【推奨アクション】
・○○
※本レポートはAIの知識に基づく参考情報です。正式な特許調査にはJ-PlatPat、USPTO、Espacenet等の特許データベースでの検証が必要です。
# 制約事項
- 実際の特許データベースへの直接アクセスは行わない。あなたの知識に基づく調査レポートを生成する
- 特許の法的判断(侵害判定、有効性判断等)は行わない
- 1回の呼び出しで処理するのは1件のみ。複数件の調査依頼が渡された場合でも、最初の1件のみ処理する
- 前回の呼び出しの調査内容を参照しない。毎回、渡された調査内容のみに基づいて調査する
- 調査日時は必ず日本時間(JST: UTC+9)で記録する。UTCで記録しないこと
指示文の設計ポイント
いくつか設計上の意図を補足します。
フェーズ制の採用
「フェーズ 1」「フェーズ 2」のように番号付きでフェーズを定義しています。これはオーケストレーターが処理順序を正確に守りやすくするためです。「適切に判断して」のような曖昧な指示ではなく、明確な分岐条件を書くことで、LLM は安定した動作をしやすくなります。
入力形式の明示
Power Automate から送られるプロンプトの JSON フォーマットを指示文内に明記しています。エージェントが「何を受け取るか」を正確に理解できるようにするためです。
「前回の呼び出しを参照しない」の明記
これは今回のアプローチの核心部分です。1 行ずつ独立した会話として処理するため、前回の調査内容に引きずられないことを制約事項として明示しています。
出力フォーマットの統一
調査レポートのフォーマットを指示文内で定義しています。Excel の「調査結果」列に書き込まれるテキストのフォーマットが毎回揃うため、後から一覧で見たときに比較しやすくなります。
調査不可のハンドリング
すべての行が正常に処理できるとは限りません。調査内容が曖昧な場合は「調査不可」として記録し、理由も残す設計にしています。これにより、後から担当者が内容を修正して再依頼できます。
ツール(アクション)の設定
エージェントに「行の更新」ツールを登録します。これは Excel Online (Business) コネクタの「行の更新」アクションを直接エージェントのツールとして使う構成です。
設定内容は以下の通りです。

| 項目 | 設定値 |
|---|---|
| 名前 | 行の更新 |
| 説明 | キー列を使用して行を更新します。入力値によって指定したセルが上書きされ、空白のままにした列は更新されません。 |
| Location | SharePoint サイトの URL(またはOneDrive for Business) |
| Document Library | ドキュメント |
| File | 特許調査管理テーブル.xlsx のファイル ID |
| Table | 特許調査テーブル |
| Key Column | ID |
| Key Value | AI で動的に入力する |
| Provide the item pro... (item) | AI で動的に入力する |
Key Value と item(更新内容)は「AI で動的に入力する」に設定します。これにより、エージェントが指示文の内容に基づいて、適切な ID と更新データを自動的にセットしてくれます。
Power Automate フローの構成
フローの全体像
フローの構成はシンプルです。
| ステップ | アクション | 内容 |
|---|---|---|
| 1 | Recurrence(トリガー) | スケジュール実行、または手動トリガー |
| 2 | 表内に存在する行を一覧表示 | Excel テーブルから全行を取得 |
| 3 | For each | 取得した行を 1 行ずつ繰り返し処理 |
| 3-1 | Sends a prompt to the specified copilot for processing | エージェントに 1 行分のデータを送信 |
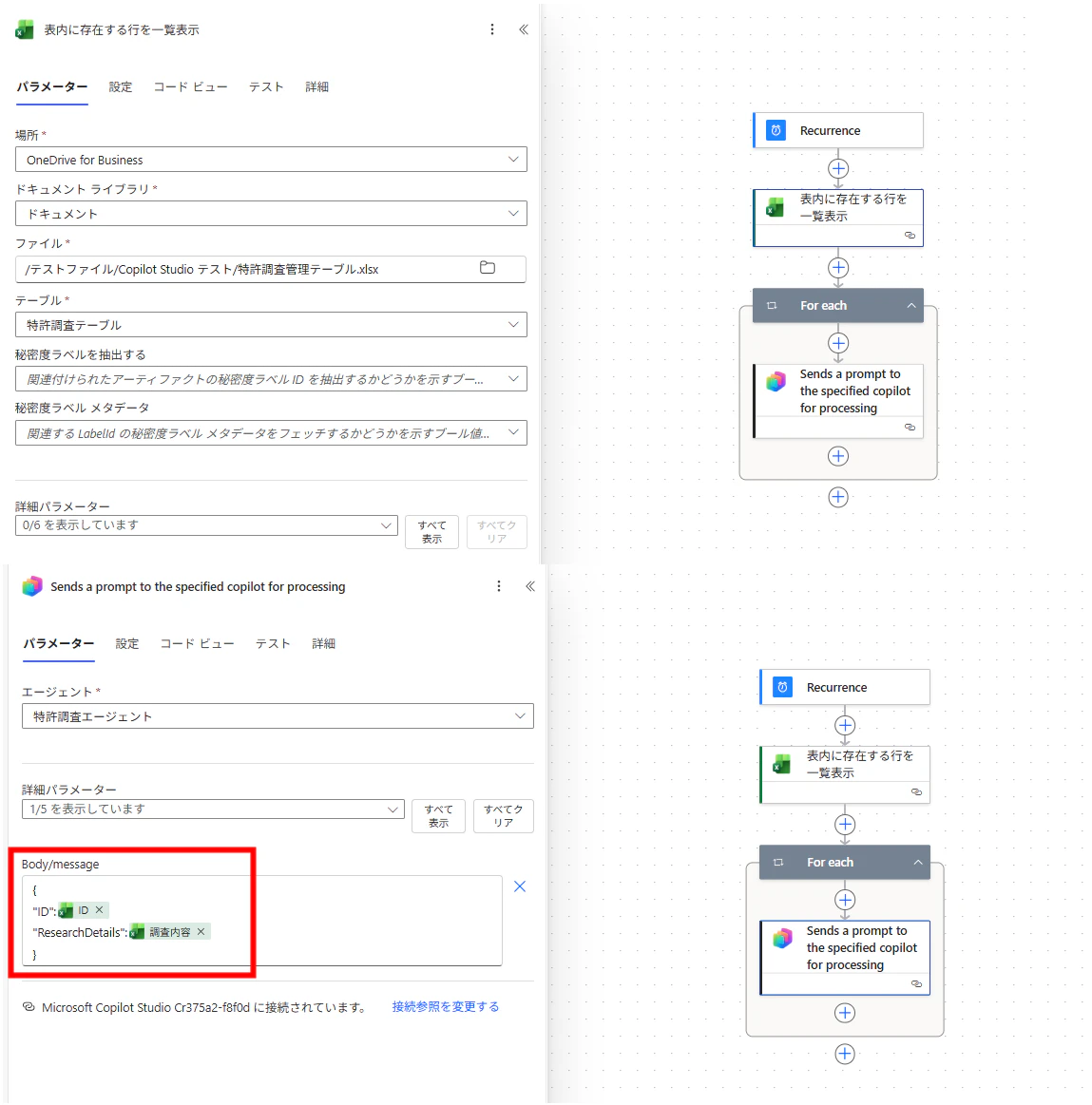
「Sends a prompt to the specified copilot for processing」の設定
For Each ループの中で、エージェントにプロンプトを送信するアクションを配置します。
| 項目 | 設定値 |
|---|---|
| エージェント | 作成したエージェントの ID |
| Body/message | {"ID": <ID の動的コンテンツ>, "ResearchDetails": <調査内容の動的コンテンツ>} |
Body/message には、Excel テーブルの「ID」列と「調査内容」列の動的コンテンツを JSON 形式で埋め込みます。これが指示文で定義した「入力形式」と対応しています。
自律型エージェントのため、こちらのフローについて、エージェント側のトリガーに設定されております (こちらから作成したフローを Power Automate 側で編集する)。

フィルタリングについて
現状のフローでは全行を取得して For Each で回していますが、未着手の行だけを処理したい場合は、For Each の前に「条件」アクションを追加するか、「表内に存在する行を一覧表示」のフィルタークエリで ステータス eq '未着手' を指定する方法があります。
個人的には、フィルタークエリで絞り込むほうがフローがシンプルになるかと思います。
この構成の利点と注意点
利点
- 処理の確実性: Power Automate の For Each ループが全行を漏れなく処理する
- 調査品質の安定: 各行が独立した会話として処理されるため、コンテキスト汚染がない
- スケーラビリティ: 行数が増えても品質が劣化しない(1 行あたりの処理は常に同じ条件)
- デバッグのしやすさ: 特定の行で問題が起きた場合、その行だけを再実行できる
- 構成のシンプルさ: エージェントは「1 件の調査に集中する専門家」として設計すればよく、複数行の管理ロジックが不要
注意点
処理時間: 20 行あれば 20 回エージェントを呼び出すため、全体の処理時間は長くなります。リアルタイム性が求められる場面には向きません。エージェントに調査を依頼している間、別の仕事をしましょう。
実行結果
まず、テストする際は、対象のエージェントはあらかじめ公開しておく必要があります。

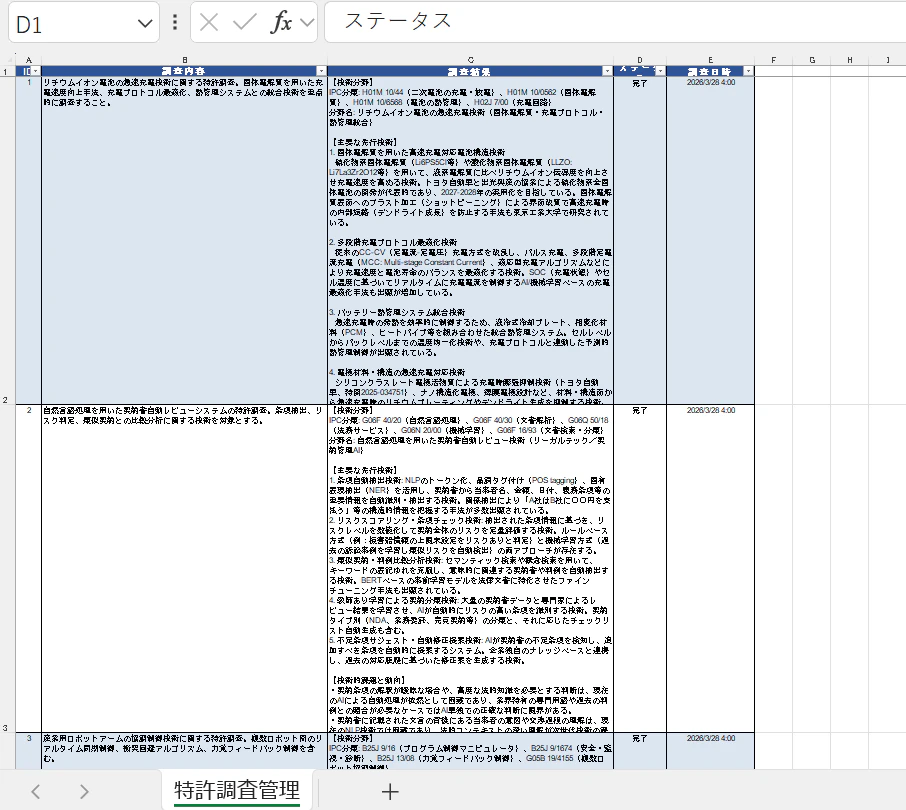
1 回では全部終わりませんでしたが、複数行に対して、 1 行ずつ独立して調査して、調査結果の欄を更新してくれました。「未着手」となっているものは、再度実行して (フィルターして) あげるとよいかと思います。
調査日時が UTC になってしまっていたので、この点は指示文を少し見直しして対応するとよいでしょう。
また、調査結果の根拠となるサイトの URL なども含めるようにしてもよいかと思います。
まとめ
今回は、Copilot Studio のエージェントに Excel テーブルの調査依頼を処理させる際に、Power Automate で 1 行ずつ渡すアプローチを紹介しました。
ポイントを整理すると以下の通りです。
- ファイルまるごと渡すと、行の処理漏れ・コンテキスト汚染・精度劣化のリスクがある
- 「ループの確実性は Power Automate に、調査の知性はエージェントに」という役割分担が有効
- エージェントは「1 件の調査に集中する専門家」として設計し、指示文をシンプルに保つ
- Excel Online コネクタの「行の更新」を直接エージェントのツールとして登録し、結果の書き戻しもエージェントが自律的に行う
本記事が、Copilot Studio × Power Automate の連携を検討されている方のお役に立てば幸いです。