はじめに
AWSのデータベースサービスには多様な選択肢があり、ワークロードに応じて最適なサービスを選択する必要がありますが、一定の知識が無いとどれを選択すべきか分かりません。本記事では、AWS Summit Tokyo 2019 における AWS におけるデータベースの選択指針 - YouTube というセッションをベースに、AWSの各データベースサービスについて概要を理解し、データベース選択のガイドラインを説明したいと思います。
データベースの歴史
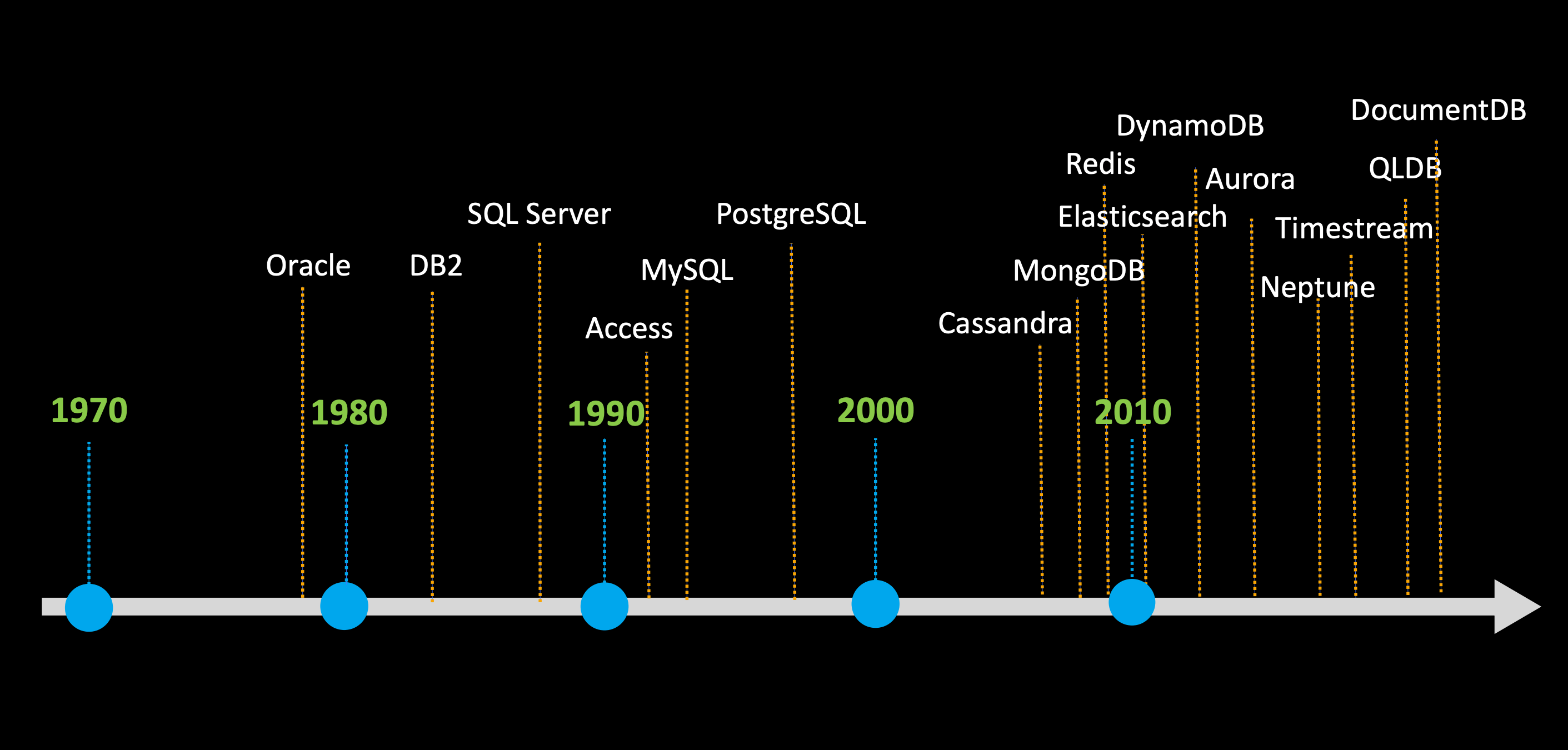
リレーショナルデータベース
1970年代後半〜1990年代前半にOracleやDB2(IBM)、SQL Server(Microsoft)、Access(Microsoft)などの商用リレーショナルデータベースが開発され、その後 2000年にかけてMySQLやPostgreSQLといったOSSのリレーショナルデータベースが登場しました。
NoSQL
しかし2000年を超えてくると、MongoDB、RedisなどNoSQL(非リレーショナル)データベースが台頭してきます。ではなぜこの頃からNoSQLが登場し始めたのでしょうか。
インターネットの登場

多くの方が記憶にあるかと思いますが、2000年以降インターネットが普及しました。これによってアプリケーションに対する要件が大きく変わっていきました。例えば、
- ユーザ数の増加
- データ量がTB~EBといったサイズに増加
- ミリ秒・マイクロ秒のパフォーマンス需要
といった変化があり、リレーショナルデータベースではこれらの要件を満たすことが難しいため、様々なNoSQL(非リレーショナルデータベース) が登場したというのが歴史的な背景になります。
万能のデータベースは存在しない
Amazon.com CTOの書いた記事 では下記の言葉があります。
A one size fits all database doesn't fit anyone.
「万能のデータベースは存在しない」
これは、様々なワークロードを満たすデータベースは存在しないため、最適なデータベースを選択すべきだという主張です。実際にAWSでは多様なデータベースの選択肢があり、Purpose Build、つまり適材適所のデータベース選択が求められます。
以降は各データベースの説明、AWSのデータベースサービスの概要について説明し、多様なサービス群からどうやって適材適所の選択を行うのかについて紹介しようと思います。
データベースサービスの種類
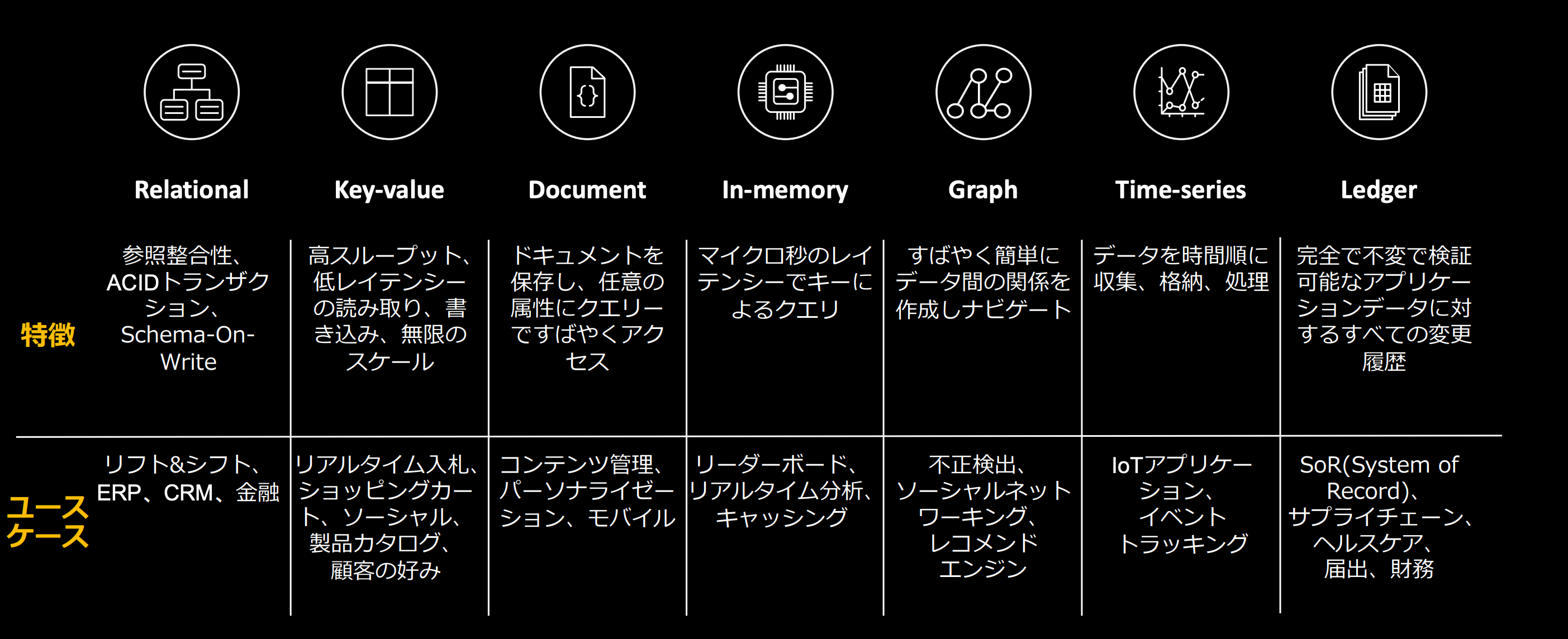
AWSのデータベースサービスのカテゴリは下記の種類があり、カテゴリごとに特徴があり、ユースケースも異なってきます。
- リレーショナルデータベース
- キーバリューデータベース
- ドキュメントデータベース
- インメモリデータストア
- グラフデータベース
- 時系列データベース
- 台帳データベース

各カテゴリごとのAWSのデータベースサービスをまとめたものがこちらになります。詳細については、これから述べますが共通して言えるのはどのサービスもマネージドサービスであるという点です。
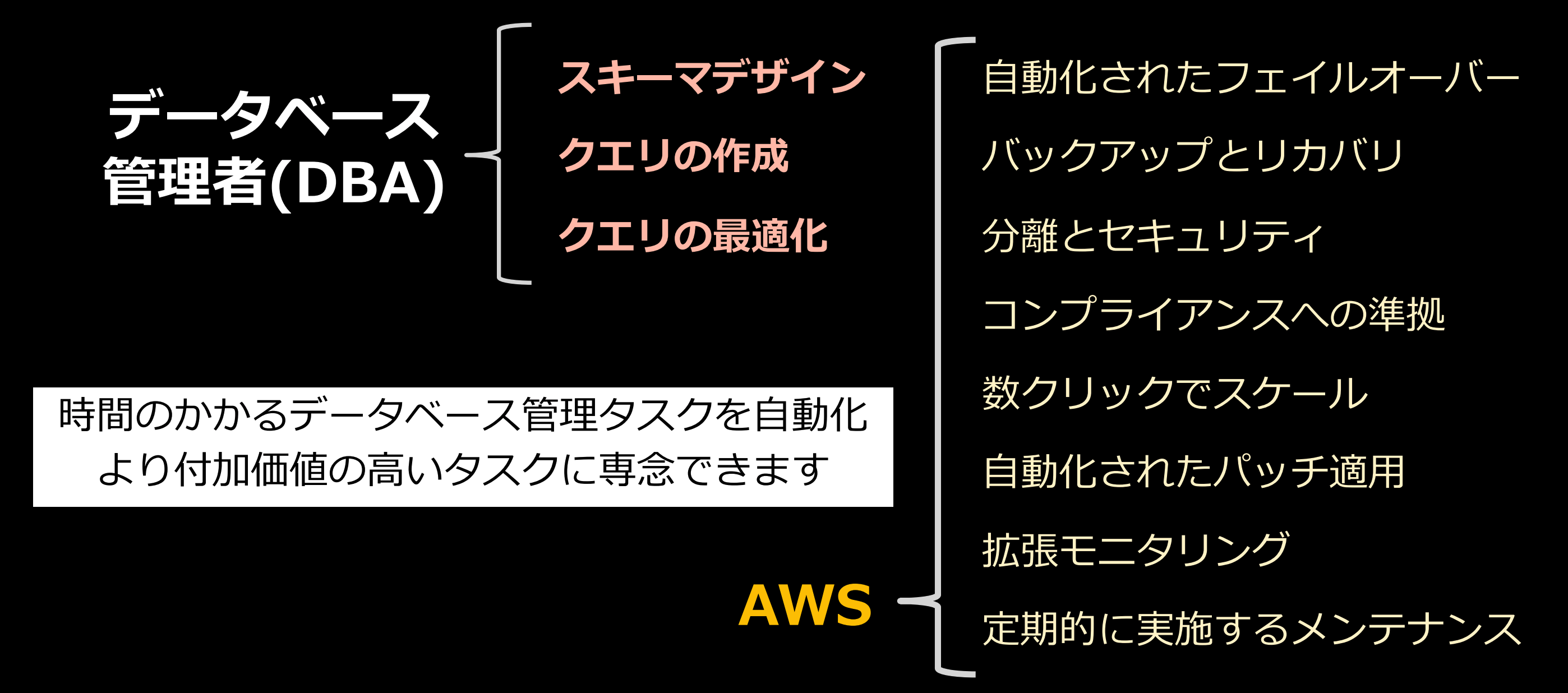
マネージドサービスとは?
AWSにおけるマネージドサービスとは機能だけでなく、運用管理なども一体として提供してくれるサービスのことです。データベースサービスの場合、データベースのインストールやパッチ適用やバックアップ、拡張性などがAWSによってマネージ(管理)され、アプリケーションのみユーザが管理するということです。
マネージドサービスを利用することで、スキーマデザイン、クエリ作成、クエリ最適化などより付加価値の高いタスクに集中できるようになります。
これらの中で一般的に利用されることが多いリレーショナルデータベース、キーバリューデータベース、ドキュメントデータベース、インメモリデータストアについて概要をまとめます。
リレーショナルデータベースとは?
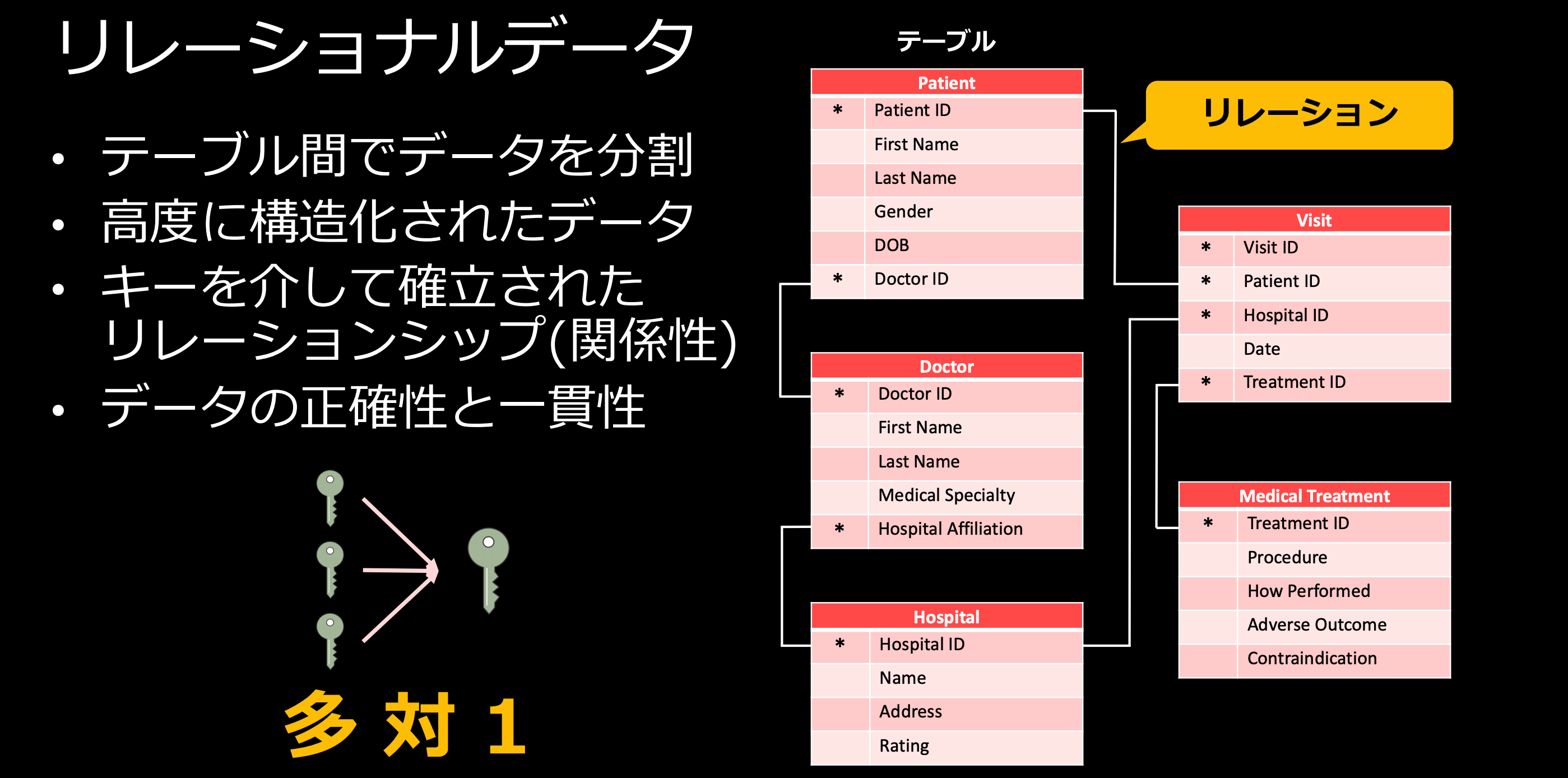
多くの人がデータベースと言われて思い浮かべるものは、リレーショナルデータベースになるのではないでしょうか。リレーショナルデータベースとは、テーブル間でデータを分割、キーを介して確立されたリレーションシップを持ったデータ項目の集合体を指します。特徴としては厳格なスキーマ設計を行うことでデータの正確性や一貫性を担保することができるという点です。AWSではリレーショナルデータベースのサービスをリレーショナルデータベースサービス(RDS)と呼びます。
どういう時にRDSを選択する?
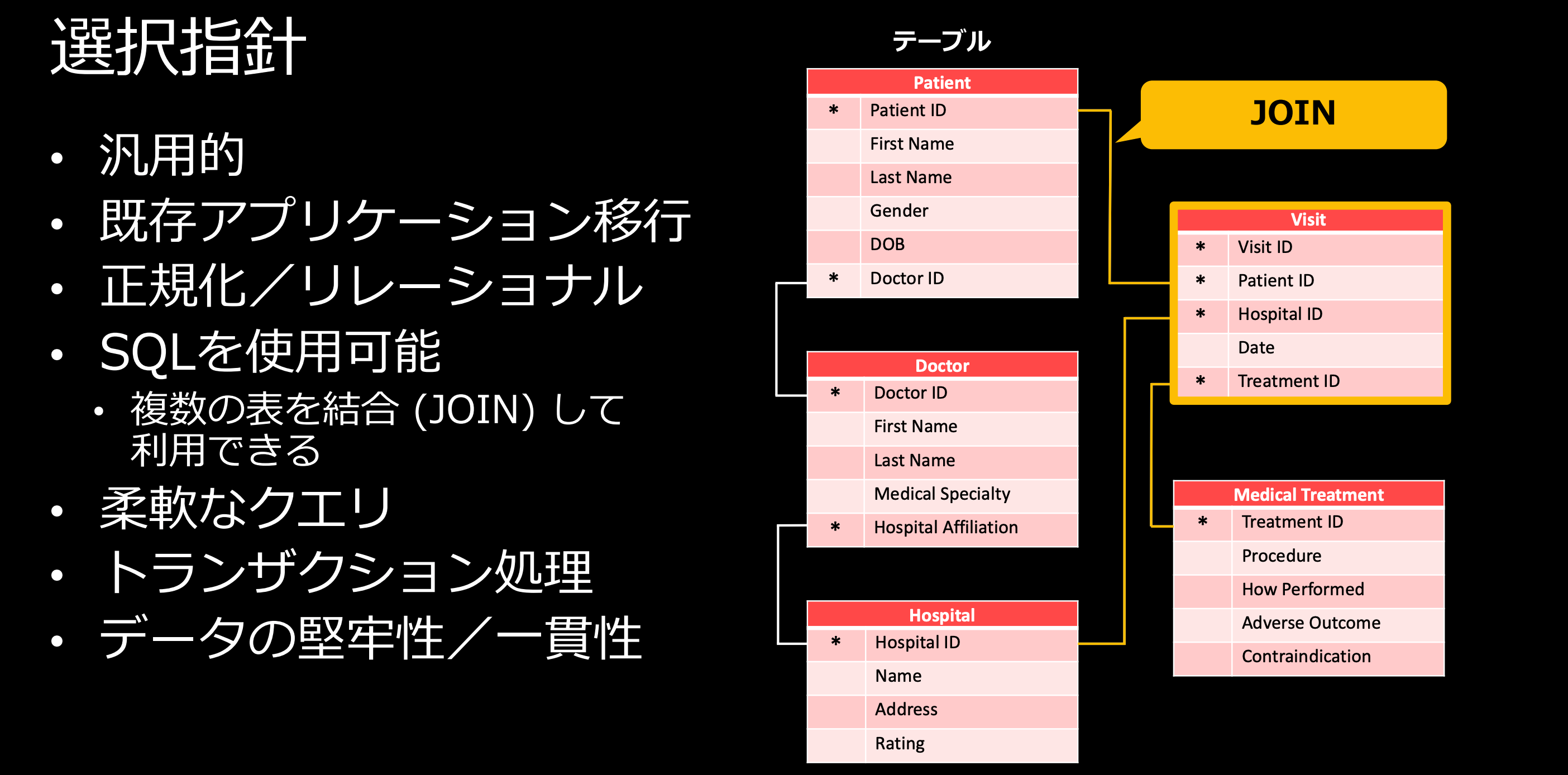
ではどういう時にRDSを選択するのでしょうか。RDSは非常に汎用的なため、既存アプリケーションを移行する際によく使用されます。また、SQLを利用し、複数の表をJOINすることで分析をする用途に向いている点、またトランザクション処理といったデータの一貫性が求められるような場合にRDSを選択すると良いでしょう。
以下、AWSの各リレーショナルデータベースサービスについて説明します。
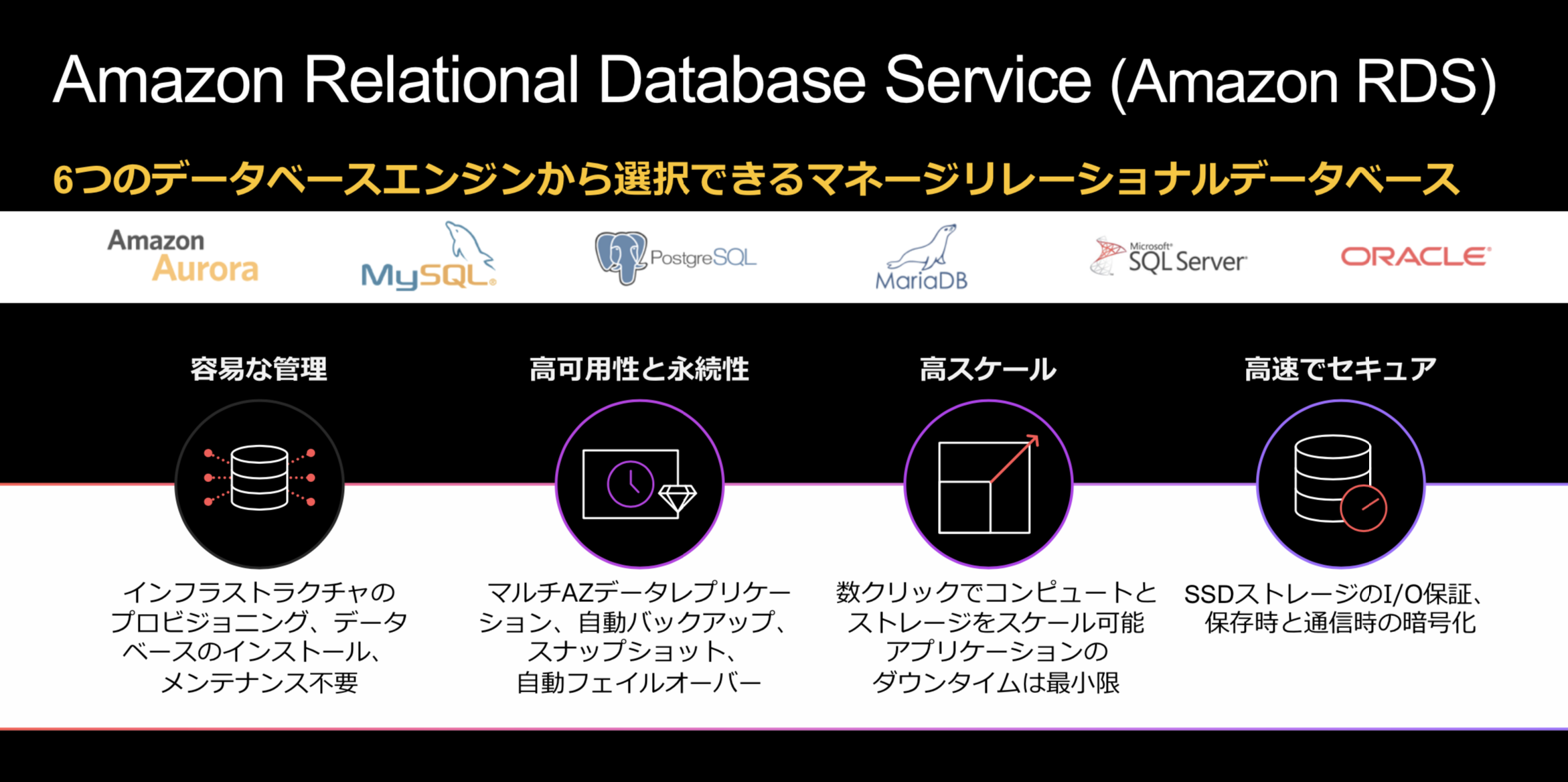
Amazon RDS
リレーショナルデータベースのセットアップ、運用、およびスケーリングを簡単に行うことのできるマネージド型サービスです。6つのデータベースエンジン Aurora、Community(MySQL、PostgreSQL、MarinaDB)、Commercial(SQLServer, Oracle)から選択が可能です。
Amazon Aurora
Amazonがクラウド時代に向けて設計した、高性能の商用データベースの速度や信頼性と、オープンソースデータベースのシンプルさや費用対効果を兼ね備えたリレーショナルデータベースエンジンです。 完全マネージドで、MySQL および PostgreSQL と互換性を持ちます。
住信SBIネット銀行では、オンプレミス環境のOracleデータベースをAWS Auroraに移行したという事例 があります。Amazon Aurora PostgreSQL10を採用したことで、データベース運用にかかるランニングコストの83%の低減(5年間トータル)が可能となるほか、住信SBIネット銀行が実施した従来の商用データベースとの比較検証においても、性能・可用性・拡張性の優位性が確認されました。
リレーショナルデータベースが必要かつ、エンジンについては特に要件がない場合は クラウドに最適化された Auroraを選択するのが良いのだと思います。
NoSQLデータベースとは?
NoSQLデータベースとは "Not only SQL" と解釈され、リレーショナルデータベース以外のデータベースを指す総称のことです。データベースの歴史においても説明しましたが、NoSQLは従来のリレーショナルデータベースの課題を解決するために生まれ、非常に多くの種類が存在します。

リレーショナルデータベースとNoSQLの主な特徴について

リレーショナルデータベースが得意な点は、トランザクション処理のような一貫性を持った処理になります。しかし性能をあげるには、スケールアウトを行うことは難しく、スケールアップを行う必要があります。一方、NoSQLに関しては、トランザクション処理に関しては限定的ですが、その分スケーラビリティがあり性能が高いといった特徴があります。
では、ここからはNoSQLのサービスについて詳細を書いていこうと思います。
キーバリューストア
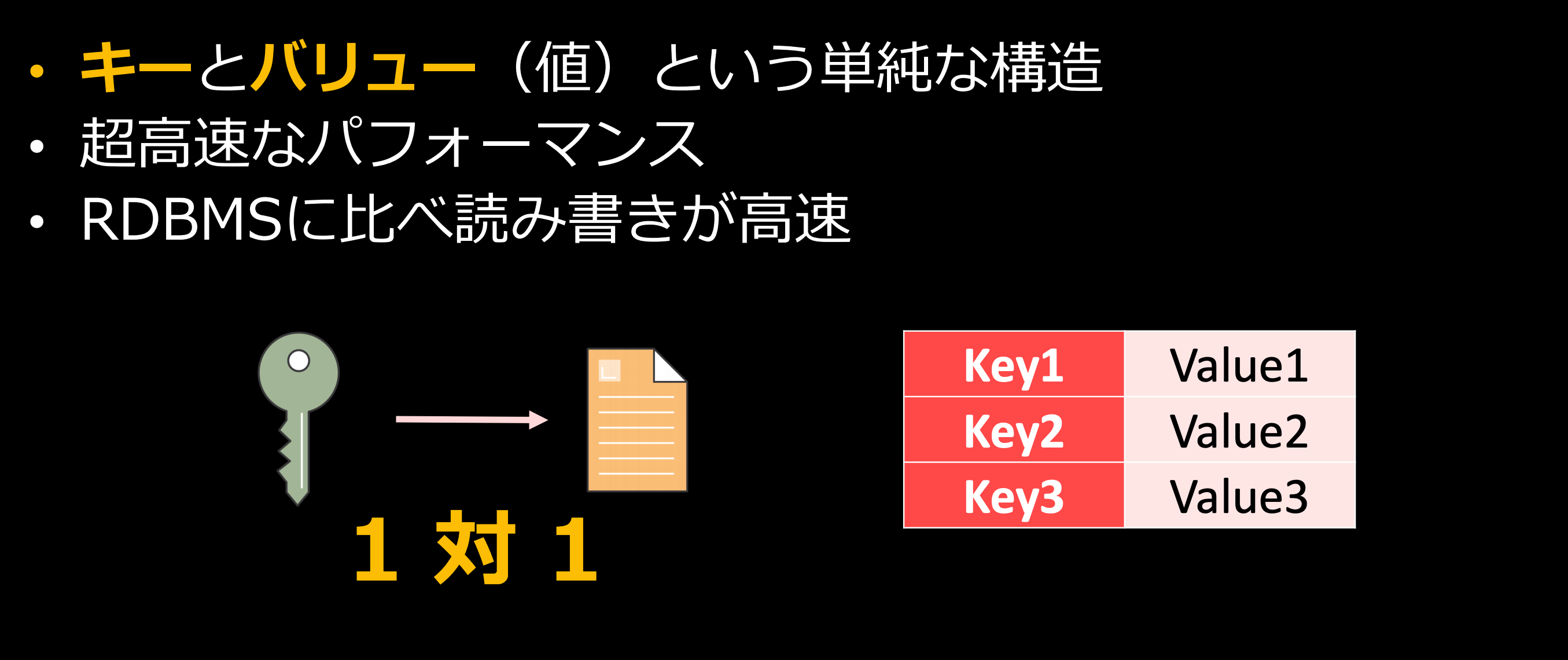
キーバリューストア(KVS)とは、文字通りキーにひもづくバリューが格納されてたデータベースになります。KVSは1対1の関係でとてもシンプルな構成のため、超高速なパフォーマンスを発揮します。よって、低レイテンシーかつ高スループットのデータアクセスに利用されます。具体的には、オンラインゲームデータやEコマースのショッピングカートなどに利用されます。
どういう時にKVSを選択する?
インターネットスケールのシステムを設計することを想像してください。スケール規模を事前予測するのが難しく、低レイテンシー・高スループットが求められることが容易に想像つくと思います。仮にリレーショナルデータベースを用いると考えた場合、スケールアップはハードウェアの性能・容量に依存しますし、スケールアウトするには分散管理が必要で大変なため、インターネットスケールのシステムには不向きなことがわかると思います。こういった時に、超高速なパフォーマンスを発揮し、スケーラビリティもあるKVSが向いているのです。
Amazon DynamoDB
AWSのKVSサービスは、DynamoDBになります。どんな規模にも対応する高速で柔軟なキーバリューストア型(KVS)のマネージドデータベースで、データをキーとバリューという一対一の構造で保持します。リレーショナルデータベースより高速に読み書きが可能です。
- 管理不要で信頼性が高い
- プロビジョンドスループットのため、テーブルごとにReadとWriteそれぞれに対し、必要な分だけのスループットキャパシティを割り当てる
- ストレージの容量制限がない
例えば、Amazon.conではOracleからDynamoDBに移行をすることで、顧客体験の改善、コストの削減に結びつきました。
ドキュメントデータベース
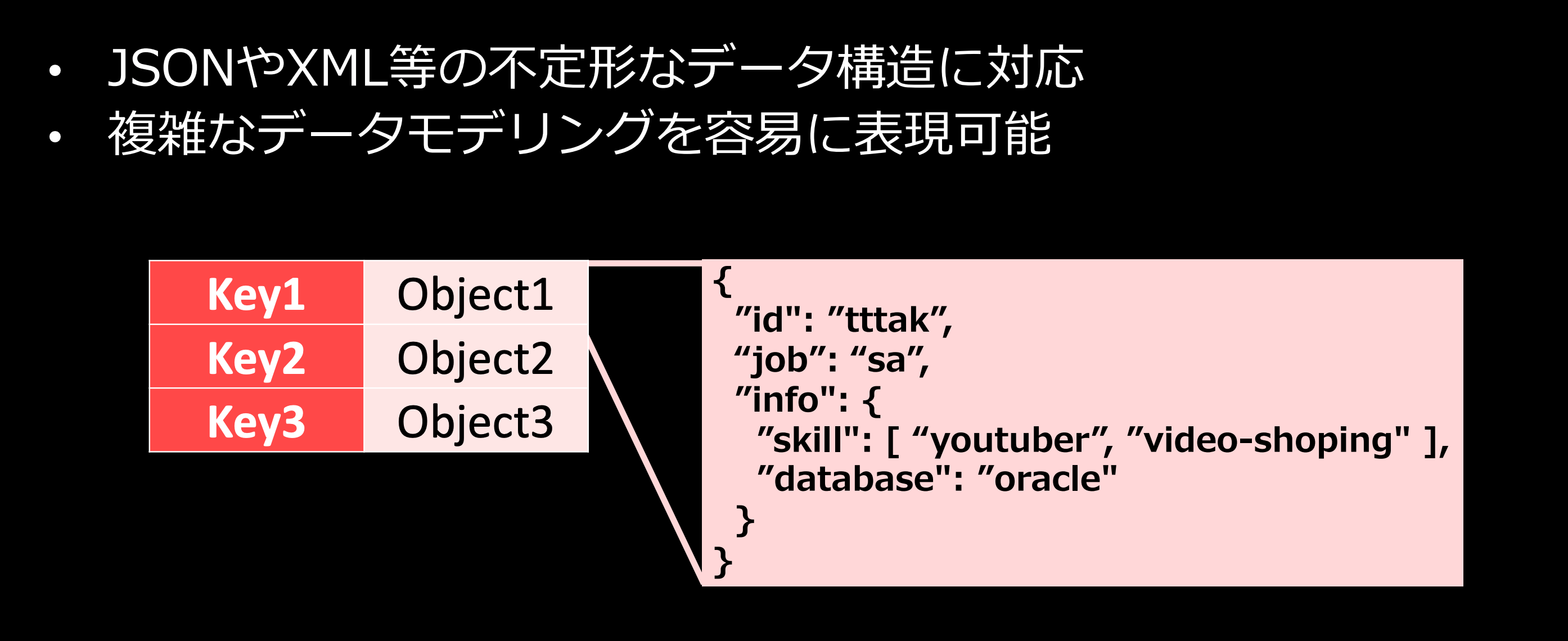
ドキュメントデータベースとは、jsonやxmlなど事前にスキーマを決める必要がなく、不定形なデータに対応したデータベースになります。よって、情報の変化があるニュース記事だったり、カタログなどによく利用されます。
どういう時にドキュメントデータベースを選択する?
Amazon.com の商品属性情報を格納するデータベースを選択することを考えた場合、属性情報というのは商品によってある情報や無い情報があり、また頻繁に変わることもあると思います。仮にリレーショナルデータベースを用いると考えた場合、事前にスキーマを定義する必要があるため柔軟に属性情報の変更は難しそうです。こういった時に、事前にスキーマを決める必要がなく、不定形なデータに対応したドキュメントデータベースが向いているのです。
Amazon DocumentDB
MongoDB互換の高速でスケーラブルかつ高可用性のフルマネージドドキュメント指向データベースで、JSONやXMLなど不定形なデータ構造に対応し複雑なデータモデリングを容易に実装可能にします。DocumentDBは頻繁に変更される属性情報(例:Amazon.comの商品属性情報)など、RDBではスキーマ設計が必須で属性を定義しないとINSERTができません。かといって全ての属性情報を定義するのは難しいです。よって、不定形なデータ構造に対応したDocumentDBが開発されました。
インメモリデータベースとは?
データをディスクや SSD に保存するデータベースではなく、データストレージ用のメモリを利用するKVS型のデータベースです。インメモリデータベースは、ディスクにアクセスする必要性を除くことによって、最小限の応答時間を達成するよう設計されました。すべてのデータはメインメモリにのみ保存および管理されているので、処理やサーバー障害によって失われてしまうリスクがありますが、すべてのオペレーションをログに保存したりスナップショットを取得したりすることで、データを存続することができます。
どういう時にインメモリデータベースを選択する?
ゲームリーダーボード、セッションストア、リアルタイム分析などの、マイクロ秒の応答時間が必要でいつでも**トラフィックが急増する可能性がある場合かつ、障害時のデータ損失リスクが許容できるまたはその他のデータストアを持ちデータの永続化ができるような時に利用するのが良いでしょう。
Amazon ElastiCache
Redis、Memcached互換のインメモリデータストア、キャッシュサービスです。RDBでは難しいマイクロ秒単位の応答時間が求められるレイテンシクリティカルな処理(ゲーム、Webサイト)などに利用される。
事例: ElastiCacheを利用したリアルタイム分析基盤
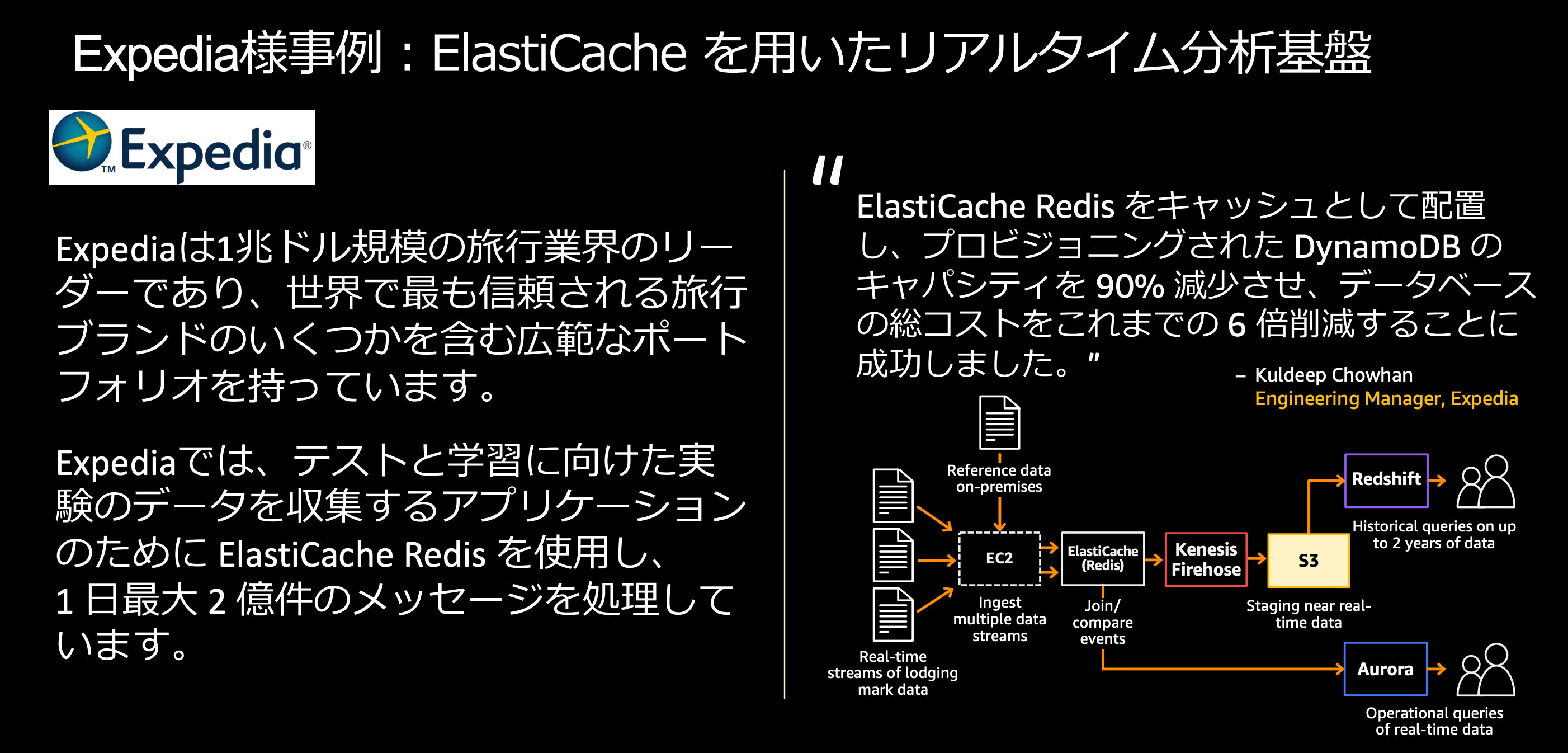
ElastiCacheをDynamoDBの前段に置くことで、キャッシュ層として利用することで、DynamoDBへのアクセスをさばくことでコストが6倍削減できた事例です。
列指向データベースとは?
最初に説明したAWSのデータベースサービスの一覧にはありませんでしたが、列指向データベースというものもあります。リレーショナルデータベースがデータ行の保存向けに最適化され、通常はトランザクション型アプリケーション用であるのに対し、データ列の高速な取得向けに最適化されたデータベースが列指向データベースになります。通常は分析アプリケーションに使用されます。
Amazon Redshift
高速、スケーラブルで費用対効果の高いデータウェアハウス(DWH)およびデータレイク分析マネージドサービスです。Wikipedia から引用するとDWHとは、一般に時系列に整理された大量の統合業務データ、もしくはその管理システムで、複数の基幹系システム(製造管理システム、販売管理システム、会計システムなど)から、トランザクション(取引)を抽出して、再構成・再蓄積したシステムを指します。これらの蓄積したデータを分析することで、企業の意思決定に利用します。
またデータレイクとは、規模にかかわらず、すべての構造化データと非構造化データを保存できる一元化されたリポジトリです。データをそのままの形で保存できるため、データを構造化しておく必要がありません。また、ダッシュボードや可視化、ビッグデータ処理、リアルタイム分析、機械学習など、さまざまなタイプの分析を実行し、的確な意思決定に役立てることができます。
Amazon Redshift の特徴としては下記があります。
- 列指向ストレージでブロックサイズは1MB
- データウェアハウス・分析向けに特化したRDB
- ペタバイト級までスケールアウト
- データレイク上のデータへの直接アクセス (Redshift Spectrum)
- 初期費用なし、小規模から始めて、利用に応じた支払いが可能
一般的なリレーショナルデータベースはデータ行の保存に最適化され、トランザクション型のアプリケーションに向いてているのに対し、Redshiftのような列指向型のデータベースは、データ列の高速な取得向けに最適化され、通常は分析アプリケーションに使用される。
列指向って?
ここで列指向について詳細を理解したいと思います。Redshiftは主に分析用に使用されますが、これは列指向型のデータベースという点が分析クエリのパフォーマンス最適化に寄与しているからです。
行指向のデータベースの場合、行全体を構成する連続した各列の値がデータブロックにシーケンシャルに格納されます(下図参照)。 オンライントランザクション処理アプリケーションでは、ほとんどのトランザクションに、通常は一度に 1 レコードまたは少数のレコードの、レコード全体の値の頻繁な読み取りおよび書き込みが含まれます。その結果、行対応のストレージはオンライントランザクション処理アプリケーション用のデータベースに最適であるといえます。
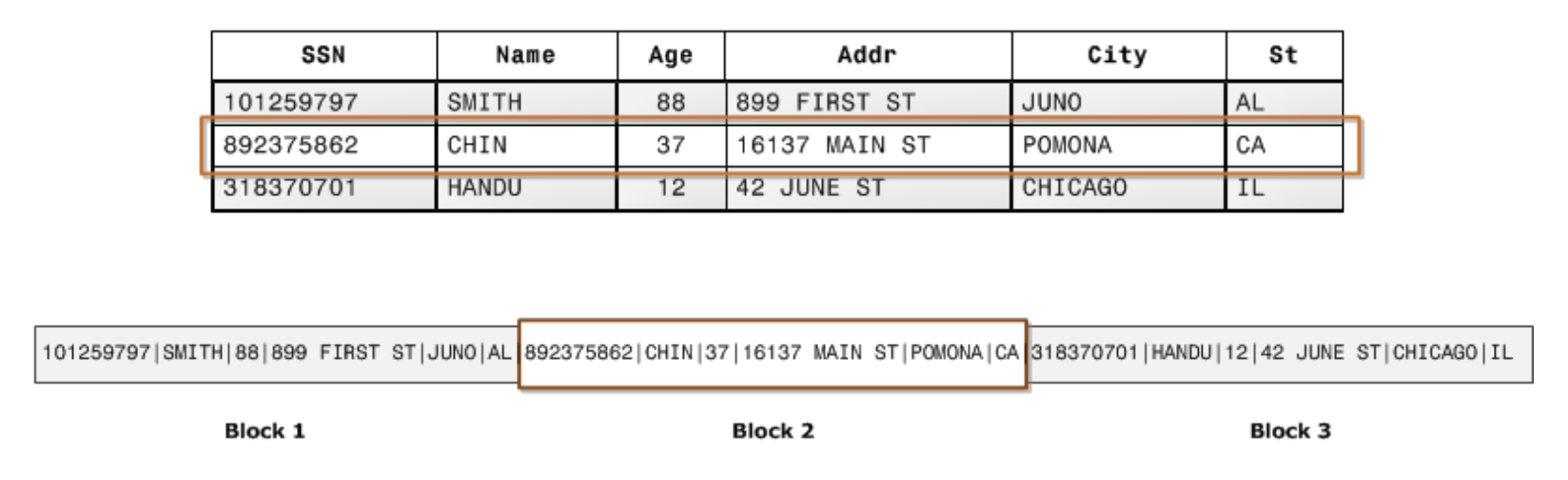
一方、列指向のデータベースの場合、各列の値がディスクブロックにシーケンシャルに格納されます(下図参照)。 例えば、SSN列の101259797, 892375862, 318370701という値を読みたい場合、行指向では、3データブロック分読み込む必要がありますが、列指向の場合、1ブロック分のみになり、必要な I/O 操作は 1/3になります。列数と行数がさらに大きい場合は、さらなる効率化が図れます。
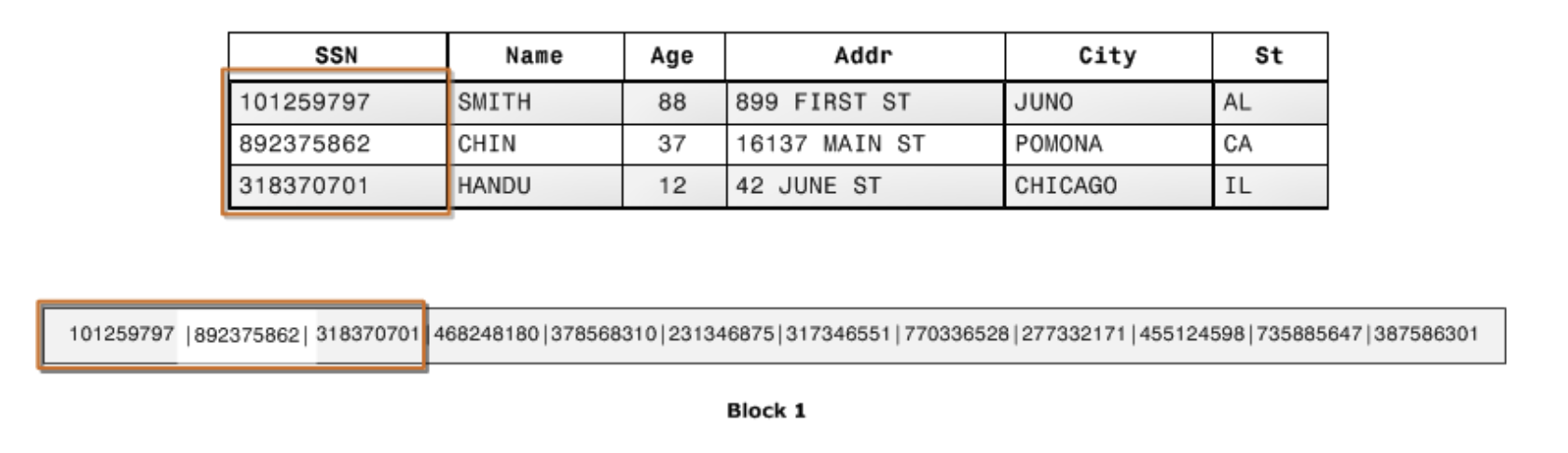
また、列指向のデータベースは、データブロックの中に同じ型のデータを保持するため、特定の圧縮方式を使用することができ、ディスク容量と I/O がさらに減ります。これらの要因から、ディスクからロードする必要のあるデータ量が減少することで分析クエリのパフォーマンスが行指向データベースに比較して高くなるということがわかると思います。
一言でまとめると
最後にこれまで説明したデータベースサービスをまとめます。
リレーショナルデータベース
- Amazon RDS
- Aurora
- MySQL, PostgreSQL互換のクラウド時代に最適化されたRDS
- Community
- エンジンが MySQL、PostgreSQL、MarinaDBのRDS
- Enterprise
- エンジンが SQLServer, OracleのRDS
- Aurora
- Amazon Redshift
- データウェアハウス(DWH)およびデータレイク分析用の列指向データベース
非リレーショナルデータベース(NoSQL)
- Amazon DynamoDB
- 高速で柔軟なキーバリューストア型(KVS)のマネージドデータベース
- Amazon DocumentDB
- JSONやXMLなど不定形なデータ構造に対応した、高速でスケーラブルかつ高可用性のフルマネージドドキュメント指向データベース
- Amazon ElastiCache
- マイクロ秒単位の応答が可能なインメモリデータストア、キャッシュサービス
おわりに
私のTwitterアカウント でクラウドサービスや機械学習に関する情報を発信していますので興味のある方はフォローをお願いします。また Hello, Data Science というデータサイエンスに関するブログも書いているのでぜひこちらも。