はじめに
Kaggle テーブルデータコンペでよく利用するEDA・特徴量エンジニアリングのスニペットをたくさん集めました。間違いやもっとこうした方がいいなどあればコメントください。
Kaggle を始めたばかりの方はまず 実践Data Scienceシリーズ PythonではじめるKaggleスタートブック を読むことをお勧めします。ある程度慣れている方は Kaggleで勝つデータ分析の技術 を読むとよいでしょう。
また、Python によるデータ処理周りに不安があるひとは、事前に Python実践データ分析100本ノック や DS協会のデータサイエンス100本ノック(構造化データ加工編 を一通りこなしておくと基本的なデータ操作については学べると思います。
前提
以降全て Notebook 上での実行を想定。
ライブラリ
import os
import json
import multiprocessing
import sys
import warnings
from contextlib import contextmanager
from collections import deque
from itertools import chain
import matplotlib.pyplot as plt
import japanize_matplotlib # matplotlib を日本語表示に対応
import numpy as np
import pandas as pd
import pandas_profiling as pdp
import seaborn as sns
from pandas.io.json import json_normalize
設定
# warningを表示しないようにする。
warnings.filterwarnings('ignore')
# データフレームの表示数を増やす
# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.set_option.html
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', None)
pd.set_option("display.max_colwidth", 10000)
# データフレームの指数表記をしないようにする
pd.options.display.float_format = '{:.2f}'.format
# seabornのデフォルトスタイルを適用
sns.set()
マジックコマンド
Notebook のセルで実行できる IPython のマジックコマンド。ビルトインのマジックコマンドは こちら を参照。
# セル全体の実行時間を計測
%%time
# Notebook で自作ライブラリを import すると、読み込んだ時点のものが固定されてしまうが、
# 下記のコマンドを実行すると、後からライブラリの内容を変更しても再度読み込みをすれば反映される
%reload_ext autoreload
%autoreload 2
処理の実行時間確認
@contextmanager
def timer(name):
s = time.time()
yield
e = time.time() - s
print(f"[{name}] {e:.3f}sec")
with timer('load file'):
df_train = pd.read_csv(os.path.join(INPUT_DIR, 'df_train.csv')
df_test = pd.read_csv(os.path.join(INPUT_DIR, 'df_test.csv')
EDA
コンペデータのファイルを確認
!ls -GFlash /kaggle/input/<コンペ名称>/
例えば、2019 Data Science Bowl では、下記のように表示される。データの種類や、サイズなどを確認できる。
!ls -GFlash /kaggle/input/data-science-bowl-2019/
total 4.0G
4.0K drwxr-xr-x 2 root 4.0K Oct 23 16:22 ./
4.0K drwxr-xr-x 3 root 4.0K Oct 26 04:05 ../
12K -rw-r--r-- 1 root 11K Oct 23 16:21 sample_submission.csv
400K -rw-r--r-- 1 root 400K Oct 23 16:21 specs.csv
380M -rw-r--r-- 1 root 380M Oct 23 16:22 test.csv
3.7G -rw-r--r-- 1 root 3.7G Oct 23 16:22 train.csv
1.1M -rw-r--r-- 1 root 1.1M Oct 23 16:21 train_labels.csv
データをデータフレームとして読み取る
INPUT_DIR = '/kaggle/input/xxxxx/'
df_train = pd.read_csv(
os.path.join(INPUT_DIR, 'df_train.csv'),
dtype={'foo': str}, # カラムの dtype を str として指定
parse_dates=['bar'], # date 型としてパースする
usecols=['foo', 'bar'] # 読み取るカラムを指定
)
生データをスプレッドシートで眺める
Notebook でデータを見る前にコンペの Data > Data Description から、各データ・カラムの概要を理解する。そして csv でダウンロードして、スプレッドシートとして眺める。ファイルサイズが大きすぎて読み取れない場合は下記のように 10000 行ほどで書き出して眺めてみる。
OUTPUT_DIR = './output'
os.makedirs(OUTPUT_DIR, exist_ok=True)
n_rows = 10000
df_train.head(n_rows).to_csv(os.path.join(OUTPUT_DIR, f'train_{n_rows}.csv'))
Pandas Profiling で簡単なデータ探索を行う
EDA レポートのツールである Pandas Profiling を使って簡単なデータ探索を行う。下記はレポートを html にして書き出す。
from pandas_profiling import ProfileReport
profile = ProfileReport(df_train, title="Pandas Profiling Report")
profile.to_file("profile_report.html") # HTML ファイルを保存する
profile.to_notebook_iframe() # jupyter notebook 上で HTML のレポートを表示する
Kaggle Titanic における pandas profiling のサンプルはこちら
データをランダムサンプリングする
1000000 レコードでランダムサンプリングする場合。データが大きすぎて、EDAでデータをプロットするのに時間がかかってしまう時などに利用する。
df_train_sampled = df_train.sample(1000000)
print(df_train.shape)
df_train_sampled = df_train.sample(1000000)
print(df_train_sampled.shape)
--------------
(11341042, 11)
(1000000, 11)
行数と列数を表示する
print(f"{df_train.shape[0]} rows and {df_train.shape[1]} features in train set")
print(f"{df_test.shape[1]} rows and {df_test.shape[1]} features in test set")
メモリ使用量を減らす
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
df_train = reduce_mem_usage(df_train)
df_test = reduce_mem_usage(df_test)
下記のように メモリ使用量 を最適化してくれる
Memory usage of dataframe is 1959.88 MB
Memory usage after optimization is: 530.08 MB
Decreased by 73.0%
Memory usage of dataframe is 1677.73 MB
Memory usage after optimization is: 462.08 MB
Decreased by 72.5%
カラムごとのメモリ使用量の確認
print(df_train.memory_usage()).plot.barh()
df_train.memory_usage().plot.barh()
デバッグする
ブレークポイントとして下記を入れる。
from IPython.core.debugger import Pdb; Pdb().set_trace()
並列処理でデータを read する
data ディレクトリにあるファイルをメモリ使用量を減らしつつ、並列処理でデータフレームとして読み込む。
path = "/kaggle/input/<コンペ名称>/"
data_list = glob(path + '*.csv')
def load_data(data):
return reduce_mem_usage(pd.read_csv(data))
with multiprocessing.Pool() as pool:
sample, df_test, df_train = pool.map(load_data, data_list)
pandas 基本
分からない操作については Data Wrangling with pandas Cheat Sheet を見ると良い。
df_train.dtypes
df_train.info()
df_train['col_name'].value_counts()
df_train.shape
df_train.columns
df_train.query('col_name==xxxx and col_name2==xxxx')
df_train['col_name'].unique()
df_train.drop_duplicates()
df_train.isna()
df_train.describe(include='all')
df_train.isnull().sum()
df_train.sort_values(by='col_name', ascending=False))
df_train.eval('new_co_name = col_name * 2')
pd.to_datetime(df_train['time_col_name'])
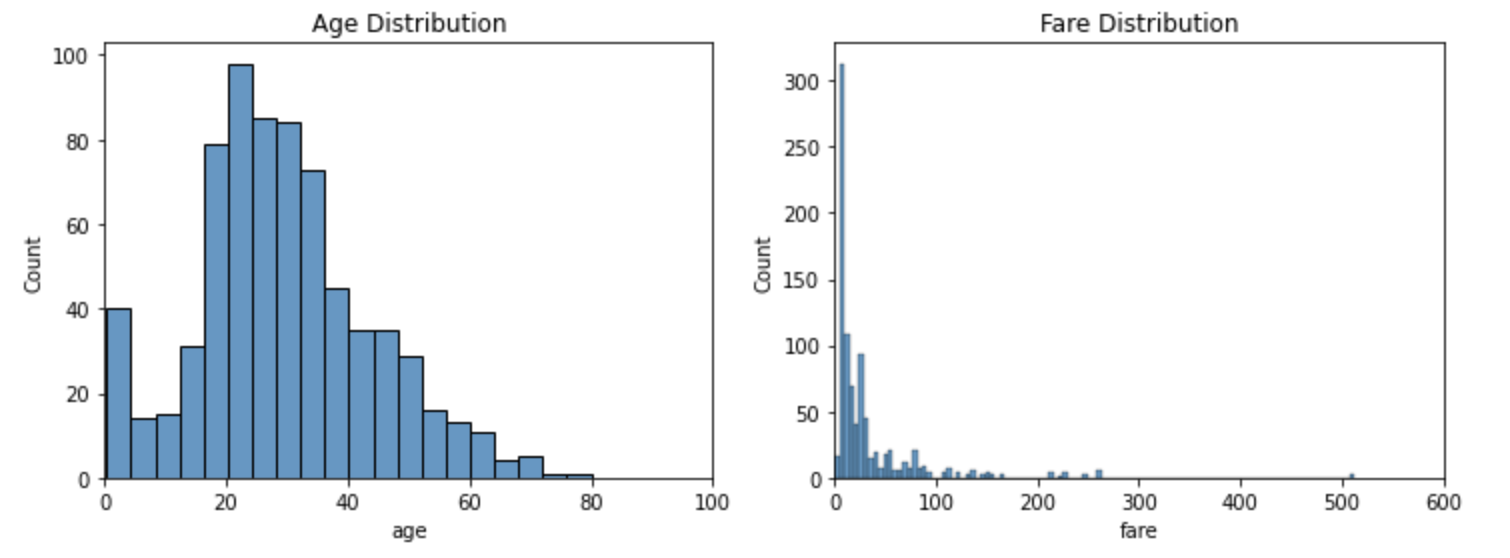
ヒストグラム
df = sns.load_dataset('titanic')
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
sns.histplot(data=df, x='age', ax=ax[0]).set(xlim=(0, 100), title='Age Distribution')
sns.histplot(data=df, x='fare', ax=ax[1]).set(xlim=(0, 600), title='Fare Distribution')
特定のカラムのヒストグラム表示
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
df_train['xxxxx'].hist(bins=50, ax=ax[0])
df_train['xxxxx'].hist(bins=50, ax=ax[1], log=True)
fig.tight_layout()
2値分類タスクで target のカテゴリごとに特定のカラムのヒストグラムを表示
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
df_train[df_train['target']==1]['col_name'].plot(kind='hist', bins=100, title='Log col name - 1', ax=ax[0])
df_train[df_train['target']==0]['col_name'].plot(kind='hist', bins=100, title='Log col name - 0', ax=ax[1])
plt.show()
散布図
plt.figure(figsize=(15, 5))
plt.scatter(df_train['x_cols'], df_train['y_cols'])
plt.title('title')
plt.xlabel('x_col_name')
plt.ylabel('y_col_name')
plt.show()
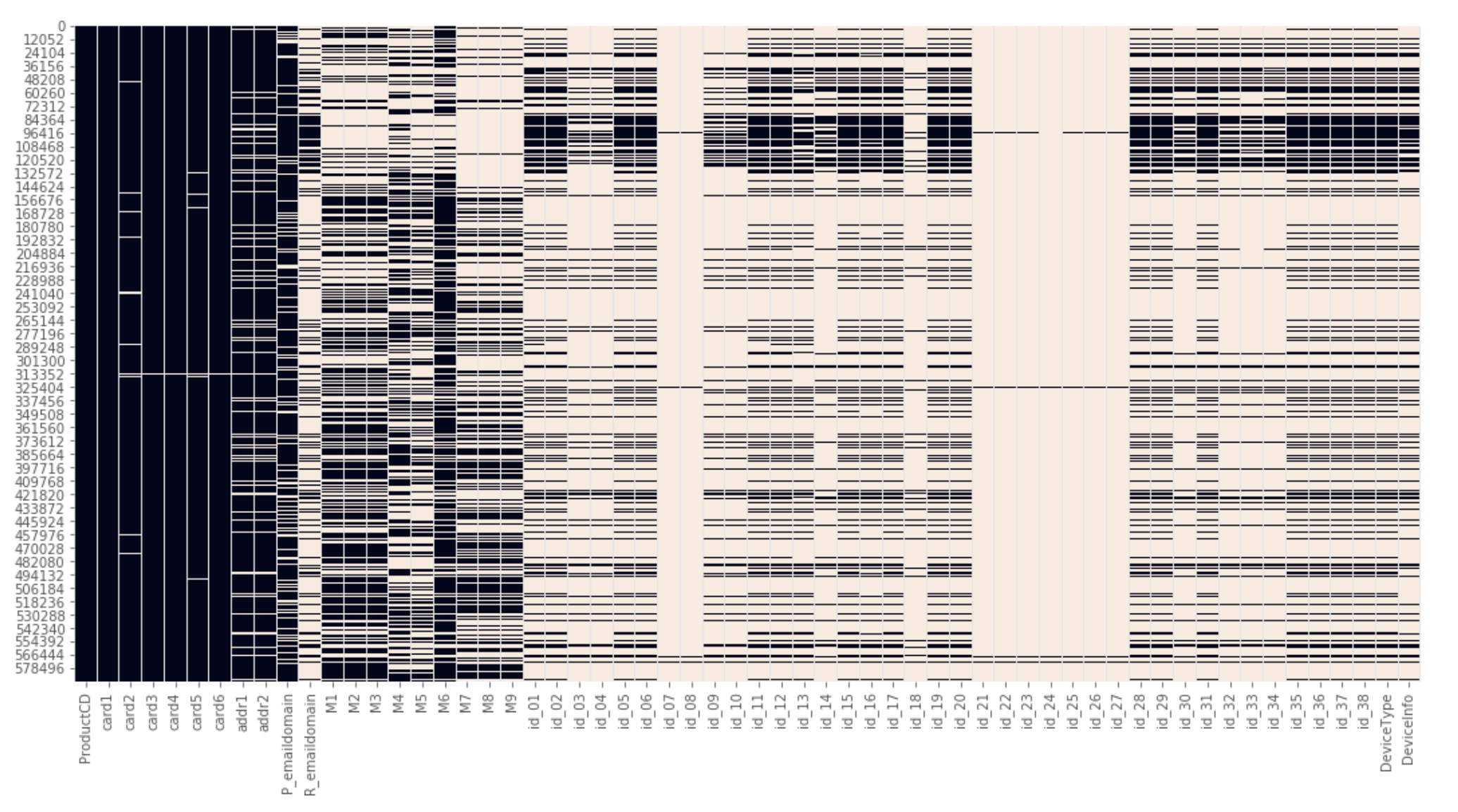
欠損値をヒートマップで視覚化
データ全体における欠損値を概要を理解する
plt.figure(figsize=(18, 9))
sns.heatmap(df_train.isnull(), cbar=False)
欠損している箇所が白く表示されるため、全体としてどのようにデータが欠損しているか理解できる。 参考:https://www.kaggle.com/suoires1/fraud-detection-eda-and-modeling より
特徴量同士の相関をヒートマップで表示
fig, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(df_train.corr(), square=True, vmax=1, vmin=-1, center=0)
ターゲットとその他の特徴量との相関
df_train.corr()['target'].sort_values()
分類タスクにおけるターゲット変数の割合
df_train['target'].value_counts()
変数のメモリ使用量を表示する
def compute_object_size(o, handlers={}):
dict_handler = lambda d: chain.from_iterable(d.items())
all_handlers = {tuple: iter,
list: iter,
deque: iter,
dict: dict_handler,
set: iter,
frozenset: iter,
}
all_handlers.update(handlers) # user handlers take precedence
seen = set() # track which object id's have already been seen
default_size = sys.getsizeof(0) # estimate sizeof object without __sizeof__
def sizeof(o):
if id(o) in seen: # do not double count the same object
return 0
seen.add(id(o))
s = sys.getsizeof(o, default_size)
for typ, handler in all_handlers.items():
if isinstance(o, typ):
s += sum(map(sizeof, handler(o)))
break
return s
return sizeof(o)
def show_objects_size(threshold, unit=2):
disp_unit = {0: 'bites', 1: 'KB', 2: 'MB', 3: 'GB'}
globals_copy = globals().copy()
for object_name in globals_copy.keys():
size = compute_object_size(eval(object_name))
if size > threshold:
print('{:<15}{:.3f} {}'.format(object_name, size, disp_unit[unit]))
# 100MB超のオブジェクト一覧を表示する
show_objects_size(100)
参考:https://qiita.com/nannoki/items/1466779987b68c4f4bf9
データのカラムリストから 特定のカラムを取り除いたリストを取得する
drop_cols = ['a', 'b', 'c', 'd', 'e'] # 取り除きたいカラムのリスト
cols = [c for c in df_train.columns if c not in drop_cols]
データフレームへの処理の並列化
def df_parallelize_run(df, func):
num_partitions, num_cores = psutil.cpu_count(), psutil.cpu_count()
df_split = np.array_split(df, num_partitions)
pool = multiprocessing.Pool(num_cores)
df = pd.concat(pool.map(func, df_split))
pool.close()
pool.join()
return df
特徴量エンジニアリング
日付・時間を処理
import jpholiday
import datetime as dt
df_train['datetime'] = pd.to_datetime(df_train['datetime']) # dtype を datetime64 に変換
df_train['year'] = df_train['datetime'].dt.year
df_train['month'] = df_train['datetime'].dt.month
df_train['day'] = df_train['datetime'].dt.day
df_train['dayofweek'] = df_train['datetime'].dt.dayofweek
df_train['hour'] = df_train['datetime'].dt.hour
df_train['minute'] = df_train['datetime'].dt.minute
df_train['second'] = df_train['datetime'].dt.second
df_train['is_holiday'] = df_train['datetime'].map(jpholiday.is_holiday).astype(int)
特定の文字を含んだカラム名のリストを得る
# 'target' という文字を含んだカラムを取得
cols = [c for c in df_train.columns if 'target' in str(c)]
json 形式のカラムを複数のカラムに展開する
df_json = json_normalize(df_train['json_col'].apply(lambda x: json.loads(x)))
複数の情報を含んだカラムを分割する
Android 6.0.1、iOS 11.4.0 といった OSとバージョン情報を複数含んだカラムを分割する。
# アンダーバーで分割
df_train['OS'] = df_train['OS_VERSION'].str.split('_', expand=True)[0]
df_train['VERSION'] = df_train['OS_VERSION'].str.split('_', expand=True)[1]
groupby でグループ化した文字列の操作
df = pd.DataFrame({
'id':['1', '2', '2', '2', '3', '3'],
'text':['a', 'a', 'b', 'v', 's', 'j']})
df.groupby("id")["text"].apply(' '.join)
id
1 a
2 a b v
3 s j
Name: text, dtype: object
df.groupby("id")["text"].apply(list)
id
1 [a]
2 [a, b, v]
3 [s, j]
Name: text, dtype: object
Count Encoding
カテゴリ変数の列で各カテゴリの出現回数をカウント。ここでは、train と test における出現回数を合計した特徴量を生成。カテゴリ値の人気度を測定しているようなものと解釈する。
参考:https://blog.datarobot.com/jp/automatedfeatureengineering
df_train['col_name_count'] = df_train['col_name'].map(pd.concat([df_train['col_name'], df_test['col_name']], ignore_index=True).value_counts(dropna=False))
df_test['col_name_count'] = df_test['col_name'].map(pd.concat([df_train['col_name'], df_test['col_name']], ignore_index=True).value_counts(dropna=False))
clipping
# 99%
upperbound, lowerbound = np.percentile(df_train['col_name'], [1, 99])
df_train['col_name_clipped'] = np.clip(df_train['col_name'], upperbound, lowerbound)
normalize
df_train['col_name_nomalize'] = (df_train['col_name'] - df_train['col_name'].mean() ) / df_train['col_name'].std()
カテゴリ変数のみ Label Eoncoding する
from sklearn.preprocessing import LabelEncoder
for col in df_train.columns:
if df_train[col].dtype == 'object':
le = LabelEncoder()
le.fit(list(df_train[col].astype(str).values) + list(df_test[col].astype(str).values))
df_train[col] = le.transform(list(df_train[col].astype(str).values))
df_test[col] = le.transform(list(df_test[col].astype(str).values))
行のNAN数を新しい特徴量に
df_train['number_of_NAN'] = df_train.isna().sum(axis=1).astype(np.int8)
ビニング処理
ビンに含まれる個数を指定
df['col_name_qcut_10'] = pd.qcut(df['col_name'], 10)
test データに無い場合1、ある場合は0にする特徴量
df_train['col_name_check'] = np.where(df_train['col_name'].isin(df_test['col_name']), 1, 0)
# test の場合は逆
df_test['col_name_check'] = np.where(df_test['col_name'].isin(df_train['col_name']), 1, 0)
全て0のカラムを作成する
df_train["col_name_zero"] = np.zeros(df_train.shape[0])
NaN とそれ以外の値の特徴量を作成する
df_train['col_name_nan'] = np.where(df_train['col_name'].isna(), 1, 0)
nan 数の同じカラムごとにグループ化
nans_groups = {}
nans = pd.concat([df_train, df_test]).isna()
for col in df_train.columns:
cur_group = nans[col].sum()
if cur_group > 0:
try:
nans_groups[cur_group].append(col)
except:
nans_groups[cur_group] = [col]
for n_group, n_members in nans_groups.items():
print(n_group, len(n_members), n_members)
Aggregated Features
カテゴリのグループごとに aggregation する。例えば、同じip, os, deviceの総クリック数を計算するなど。参考:Kaggle Masterに学ぶ実践的機械学習[Kaggle TalkingData Competition編]
agg_types = ['max', 'min', 'sum', 'mean', 'std', 'count']
for agg_type in agg_types:
new_col_name = cat_col + '_' + agg_col + '_' + agg_type
temp = pd.concat([df_train[[cat_col, agg_col]], df_test[[cat_col, agg_col]]])
temp = temp.groupby([cat_col])[agg_col].agg([agg_type]).reset_index().rename(columns={agg_type: new_col_name})
temp.index = list(temp[cat_col])
temp = temp[new_col_name].to_dict()
df_train[new_col_name] = df_train[cat_col].map(temp)
df_test[new_col_name] = df_test[cat_col].map(temp)
numeric feature を 0以上にシフトする
for col in df_train.columns:
if not ((np.str(df_train[col].dtype)=='category')|(df_train[col].dtype=='object')):
min = np.min((df_train[col].min(), df_test[col].min()))
df_train[col] -= np.float32(min)
df_test[col] -= np.float32(min)
numeric feature の 欠損値を -1 で埋める
for col in df_train.columns:
if not ((np.str(df_train[col].dtype)=='category')|(df_train[col].dtype=='object')):
df_train[col].fillna(-1, inplace=True)
df_test[col].fillna(-1, inplace=True)
frequency encoding
カテゴリ変数の出現回数で変数を置き換える。
def freq_enc(df_train, df_test, cols):
for col in cols:
df = pd.concat([df_train[col], df_test[col]])
vc = df.value_counts(dropna=True, normalize=True).to_dict()
vc[-1] = -1 # 欠損値を -1 で埋める場合
new_col = col + '_freq_enc'
df_train[new_col] = df_train[col].map(vc)
df_train[new_col] = df_train[new_col].astype('float32')
df_test[new_col] = df_test[col].map(vc)
df_test[new_col] = df_test[new_col].astype('float32')
freq_enc(df_train, df_test, feature_list)
特徴量同士を結合した特徴量を作成し Label Encoding
def conb_enc(col1, col2, df_train, df_test):
nm = col1 + '_' + col2
df_train[new_col] = df_train[col1].astype(str) + '_' + df_train[col2].astype(str)
df_test[new_col] = df_test[col1].astype(str) + '_' + df_test[col2].astype(str)
le = LabelEncoder()
le.fit(list(df_train[new_col].astype(str).values) + list(df_test[new_col].astype(str).values))
df_train[new_col] = le.transform(list(df_train[new_col].astype(str).values))
df_test[new_col] = le.transform(list(df_test[new_col].astype(str).values))
あるカラム群の欠損の数の合計を特徴量にする
df_train['missing'] = df_train[col_list].isna().sum(axis=1).astype('int16')
df_test['missing'] = df_test[col_list].isna().sum(axis=1).astype('int16')
特徴選択
constant なカラムを抜き出す
90%以上、同じ値のカラムを抜き出す
def get_constant_cols(df):
constant_cols = [col for col in df.columns if df[col].value_counts(dropna=False, normalize=True).values[0] > 0.9]
return constant_cols
cols = get_constant_cols(df_train)
不要なカラムを落とす
- 値が一つしかないカラム
- null が多いカラム
- ほとんど同じ値のカラム
one_value_cols = [col for col in df_train.columns if df_train[col].nunique() <= 1]
one_value_cols_test = [col for col in df_test.columns if df_test[col].nunique() <= 1]
many_null_cols = [col for col in df_train.columns if df_train[col].isnull().sum() / df_train.shape[0] > 0.9]
many_null_cols_test = [col for col in df_test.columns if df_test[col].isnull().sum() / df_test.shape[0] > 0.9]
big_top_value_cols = [col for col in df_train.columns if df_train[col].value_counts(dropna=False, normalize=True).values[0] > 0.9]
big_top_value_cols_test = [col for col in df_test.columns if df_test[col].value_counts(dropna=False, normalize=True).values[0] > 0.9]
cols_to_drop = list(set(many_null_cols + many_null_cols_test + big_top_value_cols + big_top_value_cols_test + one_value_cols+ one_value_cols_test))
df_train.drop(cols_to_drop, axis=1, inplace=True)
df_test.drop(cols_to_drop, axis=1, inplace=True)
再帰的特徴量選択
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
X_train = df_train.drop('target', axis=1)
y_train = df_train['target']
select = RFE(RandomForestClassifier(n_estimators=100, random_state=42), n_features_to_select=40)
select.fit(X_train, y_train)
X_train_rfe = select.transform(X_train)
X_test_rfe = select.transform(test)
コルモゴロフ-スミルノフ検定を利用した特徴量選択
from scipy.stats import ks_2samp
list_p_value =[]
for i in tqdm(df_train.columns):
list_p_value.append(ks_2samp(df_test[i], df_train[i])[1])
Se = pd.Series(list_p_value, index=df_train.columns).sort_values()
list_discarded = list(Se[Se < .1].index)
参考:https://www.kaggle.com/c/elo-merchant-category-recommendation/discussion/77537
Null Importance による特徴量選択
LightGBM などの学習器における feature importance で、上位に来た特徴量の中にノイズになっているものが含まれていることがある。そこで正しい目的変数で学習した結果の feature importance と目的変数を shuffle したデータを用いて学習した結果の feature importance を比較することでノイズになっている特徴量を抽出する。
def get_feature_importances(X, shuffle, seed=None):
cols_to_drop = ['col_to_drop_1','col_to_drop_2']
categoricals = ['cat_col']
y = X['target']
X = X.drop(cols_to_drop, axis=1)
if shuffle:
y = np.random.permutation(y)
train = lgb.Dataset(X, y, free_raw_data=False, silent=True)
lgb_params = {
'objective': 'binary',
'boosting_type': 'rf',
'subsample': 0.623,
'colsample_bytree': 0.7,
'num_leaves': 127,
'max_depth': 8,
'seed': 42,
'bagging_freq': 1,
'n_jobs': 4
}
clf = lgb.train(params=lgb_params, train_set=train, num_boost_round=200, categorical_feature=categoricals)
df_importance = pd.DataFrame()
df_importance["feature"] = list(X.columns)
df_importance["importance"] = clf.feature_importance()
df_importance['train_score'] = roc_auc_score(y, clf.predict(X)) # 二値分類の場合
return df_importance
def display_distributions(df_actual_importance, df_null_importance, feature):
actual_imp = df_actual_importance.query(f"feature == '{feature}'")["importance"].mean()
null_imp = df_null_importance.query(f"feature == '{feature}'")["importance"]
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
a = ax.hist(null_imp, label="Null importances")
ax.vlines(x=actual_imp, ymin=0, ymax=np.max(a[0]), color='r', linewidth=10, label='Real Target')
ax.legend(loc="upper right")
ax.set_title(f"Importance of {feature.upper()}", fontweight='bold')
plt.xlabel(f"Null Importance Distribution for {feature.upper()}")
plt.ylabel("Importance")
plt.show()
# 実際の目的変数で学習し、feature importance の DataFrame を作成
df_actual_importance = get_feature_importances(X=reduce_train, shuffle=False)
# シャッフルした目的変数で学習し、feature importance の DataFrame を作成
nb_runs = 100
df_null_importance = pd.DataFrame()
for i in range(nb_runs):
df_importance = get_feature_importances(X=reduce_train, shuffle=True)
df_importance["run"] = i + 1
df_null_importance = pd.concat([df_null_importance, df_importance])
# 実データにおいて特徴量の重要度が高かった上位5位を表示
for feature in actual_imp_df["feature"][:5]:
display_distributions(df_actual_importance, df_null_importance, feature)
# 閾値を設定
THRESHOLD = 80
# 閾値以下(ノイズ)の特徴量を取得
not_important_features = []
for feature in df_actual_importance["feature"]:
actual_value = df_actual_importance.query(f"feature=='{feature}'")["importance_split"].values
null_value = df_null_importance.query(f"feature=='{feature}'")["importance_split"].values
percentage = (null_value < actual_value).sum() / null_value.size * 100
if percentage < THRESHOLD:
not_important_features.append(feature)
参考
その他参考にする記事
おすすめの Kaggle関連本
-
実践Data Scienceシリーズ PythonではじめるKaggleスタートブック
- より初心者向け
-
Kaggleで勝つデータ分析の技術
- 初中級者向け
-
Python実践データ分析100本ノック
- データ処理を演習形式で学ぶことができる。初中級者向け