本記事の対象
本記事はRandomForestやXGBoost、LightGBMなどの学習器を使う人向けの内容になっています。
概要
自身が作成した数ある特徴量の中にはノイズとなりうるものが含まれます。実際にRandomForestやXGBoost、LightGBMなどの学習器を使って特徴量の重要度を表示した際、重要度の高い特徴量にそういったノイズが含まれている可能性があります。そこで今回は、偽の教師データを用いて重要度を測ることによって、ノイズに埋もれている特徴量をあぶり出し、真に重要な特徴量のみを選定する方法を紹介します。参考にした資料はこちらです。
準備
今回はscikit-learnのデータセットにあるBreast Cancerを使いました(特に理由はありません)。
# 必要なモジュールをインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
# データの取得
cancer = load_breast_cancer()
X = pd.DataFrame(cancer.data, columns=cancer.feature_names)
y = cancer.target
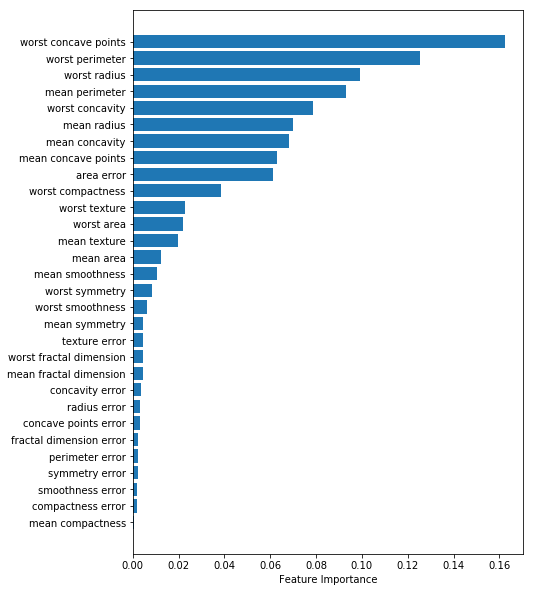
特徴量の重要度を確認
そのままのデータでモデルを学習し、特徴量の重要度を確認します。
# モデルの学習
clf = RandomForestClassifier(random_state=42)
clf.fit(X, y)
# 特徴量の重要度を含むデータフレームを作成
imp_df = pd.DataFrame()
imp_df["feature"] = X.columns
imp_df["importance"] = clf.feature_importances_
imp_df = imp_df.sort_values("importance")
# 可視化
plt.figure(figsize=(7, 10))
plt.barh(imp_df.feature, imp_df.importance)
plt.xlabel("Feature Importance")
plt.show()
実データと虚データで特徴量重要度を取得
ここからが本題です。先ほどの特徴量重要度が本当に正しいのかを検証します。目的変数をシャッフルしたデータを用いてモデルを学習し、そのモデルにおける特徴量重要度 (Null Importtance) を取得します。
def get_feature_importances(X, y, shuffle=False):
# 必要ならば目的変数をシャッフル
if shuffle:
y = np.random.permutation(y)
# モデルの学習
clf = RandomForestClassifier(random_state=42)
clf.fit(X, y)
# 特徴量の重要度を含むデータフレームを作成
imp_df = pd.DataFrame()
imp_df["feature"] = X.columns
imp_df["importance"] = clf.feature_importances_
return imp_df.sort_values("importance", ascending=False)
# 実際の目的変数でモデルを学習し、特徴量の重要度を含むデータフレームを作成
actual_imp_df = get_feature_importances(X, y, shuffle=False)
# 目的変数をシャッフルした状態でモデルを学習し、特徴量の重要度を含むデータフレームを作成
N_RUNS = 100
null_imp_df = pd.DataFrame()
for i in range(N_RUNS):
imp_df = get_feature_importances(X, y, shuffle=True)
imp_df["run"] = i + 1
null_imp_df = pd.concat([null_imp_df, imp_df])
各データから得られた重要度を比較
続いて、上記で得られたそれぞれの重要度を比較します。
def display_distributions(actual_imp_df, null_imp_df, feature):
# ある特徴量に対する重要度を取得
actual_imp = actual_imp_df.query(f"feature == '{feature}'")["importance"].mean()
null_imp = null_imp_df.query(f"feature == '{feature}'")["importance"]
# 可視化
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
a = ax.hist(null_imp, label="Null importances")
ax.vlines(x=actual_imp, ymin=0, ymax=np.max(a[0]), color='r', linewidth=10, label='Real Target')
ax.legend(loc="upper right")
ax.set_title(f"Importance of {feature.upper()}", fontweight='bold')
plt.xlabel(f"Null Importance Distribution for {feature.upper()}")
plt.ylabel("Importance")
plt.show()
# 実データにおいて特徴量の重要度が高かった上位5位を表示
for feature in actual_imp_df["feature"][:5]:
display_distributions(actual_imp_df, null_imp_df, feature)
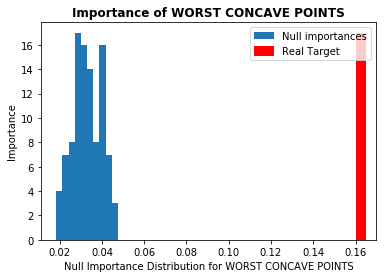
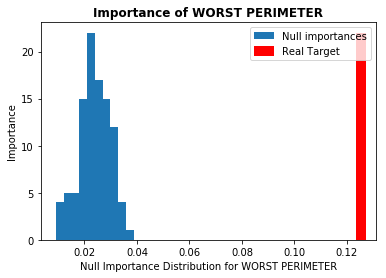
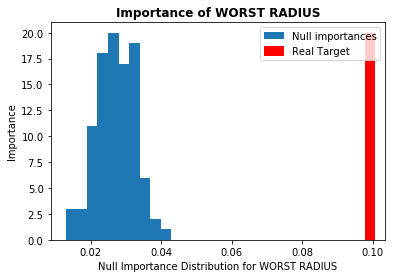
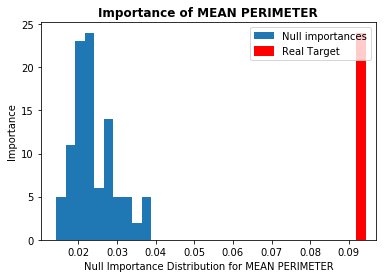
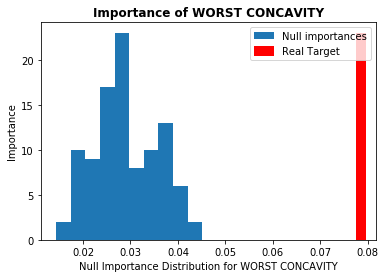
本記事では重要度が高いとされた上位5つの特徴量について見ていきます。図は横軸に各特徴量の重要度、縦軸にNull Importanceの頻度を取っています(青色がNull Importanceのヒストグラム分布)。ノイズに埋もれた特徴量の場合、赤色の縦線(実際の重要度)が青色の塊の中にあるか、それよりも重要度が低くなっています。今回使用したデータには、重要度の高い特徴量においてノイズとなり得るものはなさそうでした(他のデータではある場合があります)。
特徴量の選定
仮に重要度の高い特徴量の中にノイズが含まれる場合を想定し、その特徴量を除くために、設定した閾値を超える特徴量のみを取得する方法を記します。
# 閾値を設定
THRESHOLD = 80
# 閾値を超える特徴量を取得
imp_features = []
for feature in actual_imp_df["feature"]:
actual_value = actual_imp_df.query(f"feature=='{feature}'")["importance"].values
null_value = null_imp_df.query(f"feature=='{feature}'")["importance"].values
percentage = (null_value < actual_value).sum() / null_value.size * 100
if percentage >= THRESHOLD:
imp_features.append(feature)
imp_features
# ['worst concave points', 'worst perimeter', 'worst radius', 'mean perimeter', 'worst concavity', 'mean radius', 'mean concavity', 'mean concave points', 'area error', 'worst compactness']
今回は上記のグラフで示したノイズの分布を基準に、80%以上のNull Importanceを超えた特徴量を取得するようにしました。その結果、最初に求めた特徴量重要度のグラフにおいて、worst texture以下のものがノイズに埋もれていると判断されました。
まとめ
特徴量の中にはノイズとなりうるものが含まれている可能性があるため、何かしらの確認、および選定が必要です。その中でも、今回のNull Importanceを用いた方法は、比較的容易に、かつ図を使っての確認もできるため、個人的にはおすすめの手法です。
他にもっと良い方法があるよ、という方がいらっしゃったらコメントをいただけると幸いです。