はじめに
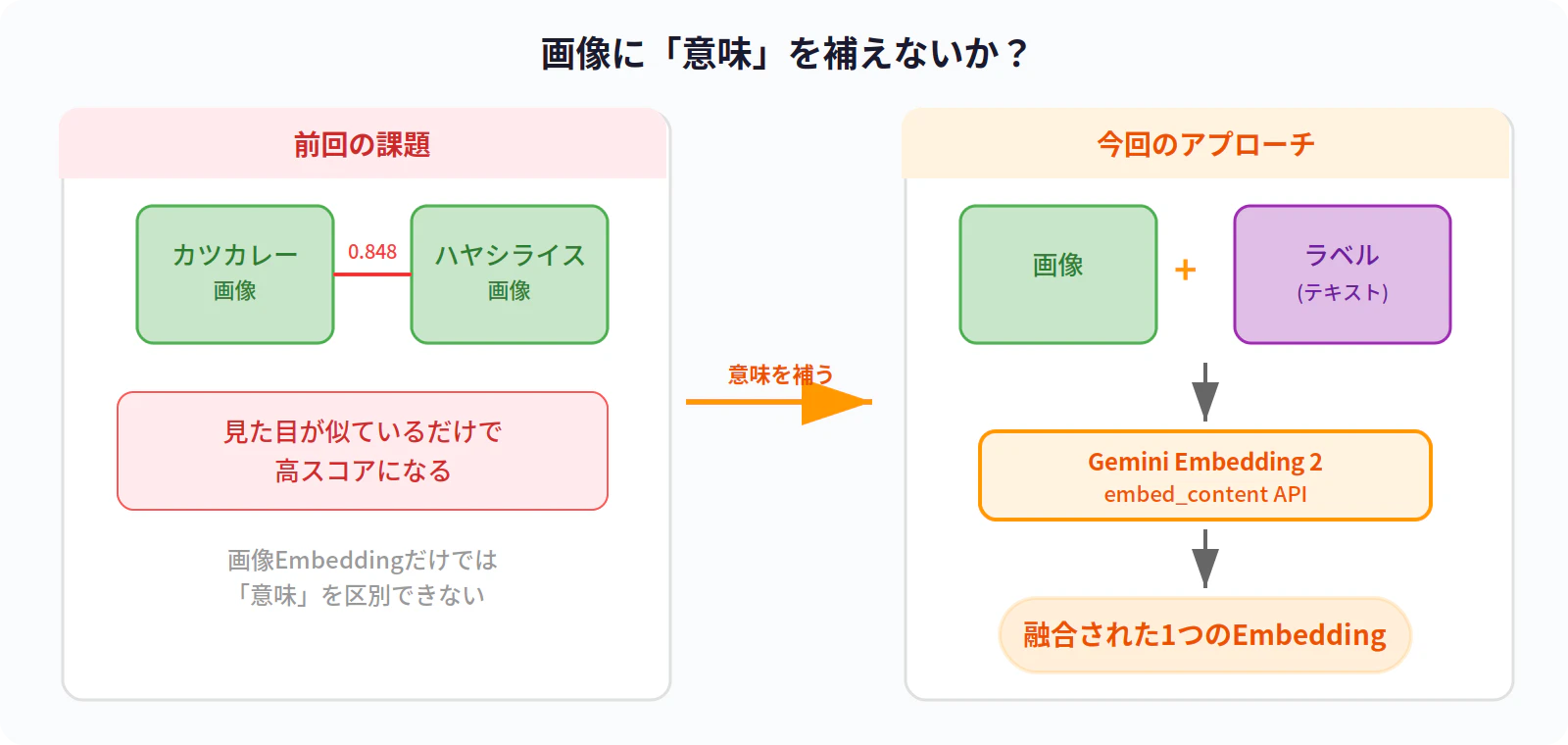
前回の記事では、Gemini Embedding 2 を使ってカレー画像の類似度を比較しました。
👉 前回の記事
その結果、画像Embeddingだけでは見た目が似ているだけで高スコアになるという課題が見えました。
👉 画像に「意味」を補えないか?
Gemini Embedding 2 には、画像とテキストをまとめて渡すとモデルが融合した1つのEmbeddingを返す機能があります。
公式ドキュメントでは「Embedding aggregation(集約エンベディング)」と呼ばれています。
👉 今回はこの機能を使って、画像+ラベル(テキスト)で類似度がどう変わるかを検証します。
集約エンベディングとは
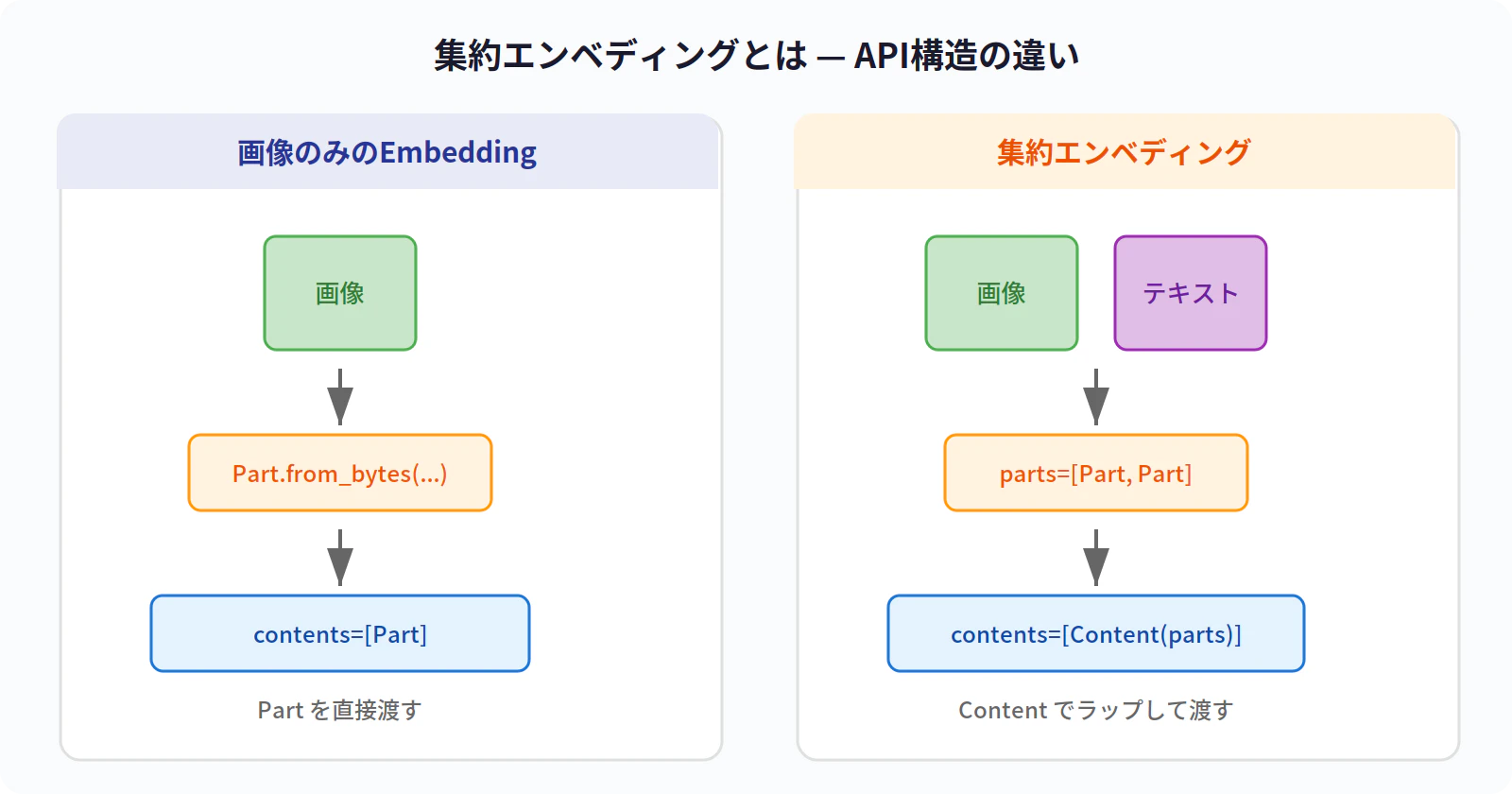
Gemini Embedding 2 の embed_content API で、parts に画像とテキストをまとめて渡します。
ポイントは types.Content(parts=[...]) でラップすることです。画像のみの場合と構造が異なります。
# 画像のみのEmbedding → Part を直接渡す
contents=[types.Part.from_bytes(data=img, mime_type=mime)]
# 集約エンベディング → Content でラップして parts に複数の Part を渡す
contents=[
types.Content(
parts=[
types.Part(text="orange curry, naan, creamy"),
types.Part.from_bytes(data=img_bytes, mime_type="image/jpeg")
]
)
]
👉 この構造の違いが「個別のEmbedding」と「集約エンベディング」の挙動の差を生む
👉 集約エンベディングでは、モデル側で画像とテキストを融合した1つのEmbeddingが返ってくる
👉 重みの設計は不要。API呼び出しも1回で済みます。
補足:taskType について
embed_content API では taskType(SEMANTIC_SIMILARITY、RETRIEVAL_DOCUMENT など)を指定できます。
今回の検証では taskType を指定せずデフォルトで実行しています。
用途によっては taskType を指定した方がスコアの品質が向上する可能性があります。
データ
前回と同じ8種類のカレー画像を使用します。以下のような画像です。他の画像を確認したい場合には、前回の記事を参照ください。


各画像に、短いラベル(見た目の特徴をキーワードで記述)を付与しています。
foods = {
"butter_chicken_nan": {"path": "butter_chicken_naan.jpg", "meta": "orange curry, naan, creamy"},
"butter_chicken_rice": {"path": "butter_chicken_rice.jpg", "meta": "orange curry, rice, creamy"},
"dry_curry": {"path": "dry_curry.jpg", "meta": "minced meat, rice, dry texture"},
"hayashi_rice": {"path": "hayashi_style.jpg", "meta": "brown stew, rice, separated"},
"katsu_curry": {"path": "katsu_curry.jpg", "meta": "rice, brown curry, fried cutlet"},
"keema_curry": {"path": "keema_curry.jpg", "meta": "minced curry, thick"},
"soup_curry": {"path": "soup_curry.jpg", "meta": "soup style, vegetables"},
"vegetable_curry": {"path": "vegetable_curry.jpg", "meta": "vegetables, colorful"}
}
結果
集約エンベディング(agg)と、参考として画像のみ(img)の結果を並べます。
katsu_curry をクエリにした場合
target agg img
------------------------------------------
hayashi_rice 0.861 0.848
butter_chicken_rice 0.851 0.832
butter_chicken_nan 0.823 0.787
vegetable_curry 0.822 0.832
soup_curry 0.822 0.809
dry_curry 0.821 0.805
keema_curry 0.808 0.761
butter_chicken_nan をクエリにした場合
target agg img
------------------------------------------
butter_chicken_rice 0.952 0.912
vegetable_curry 0.838 0.819
katsu_curry 0.823 0.787
keema_curry 0.808 0.801
hayashi_rice 0.761 0.776
soup_curry 0.761 0.745
dry_curry 0.752 0.733
dry_curry をクエリにした場合
target agg img
------------------------------------------
keema_curry 0.851 0.817
katsu_curry 0.821 0.805
hayashi_rice 0.790 0.768
soup_curry 0.781 0.772
butter_chicken_rice 0.774 0.752
vegetable_curry 0.757 0.790
butter_chicken_nan 0.752 0.733
良いところ
- butter_chicken_nan ↔ butter_chicken_rice が agg: 0.952 で圧倒的に1位。同一料理系の検出はうまくいっている
- 画像のみ(img)と比べて、全体的にスコアの並び順は妥当
課題が見えた
katsu_curry の結果をよく見ると、
- 1位:hayashi_rice(0.861)
- 最下位:keema_curry(0.808)
- 差はわずか 0.053
👉 すべてのスコアが 0.80〜0.86 に集中しており、ランキングの分解能が低い
なぜスコアが寄るのか
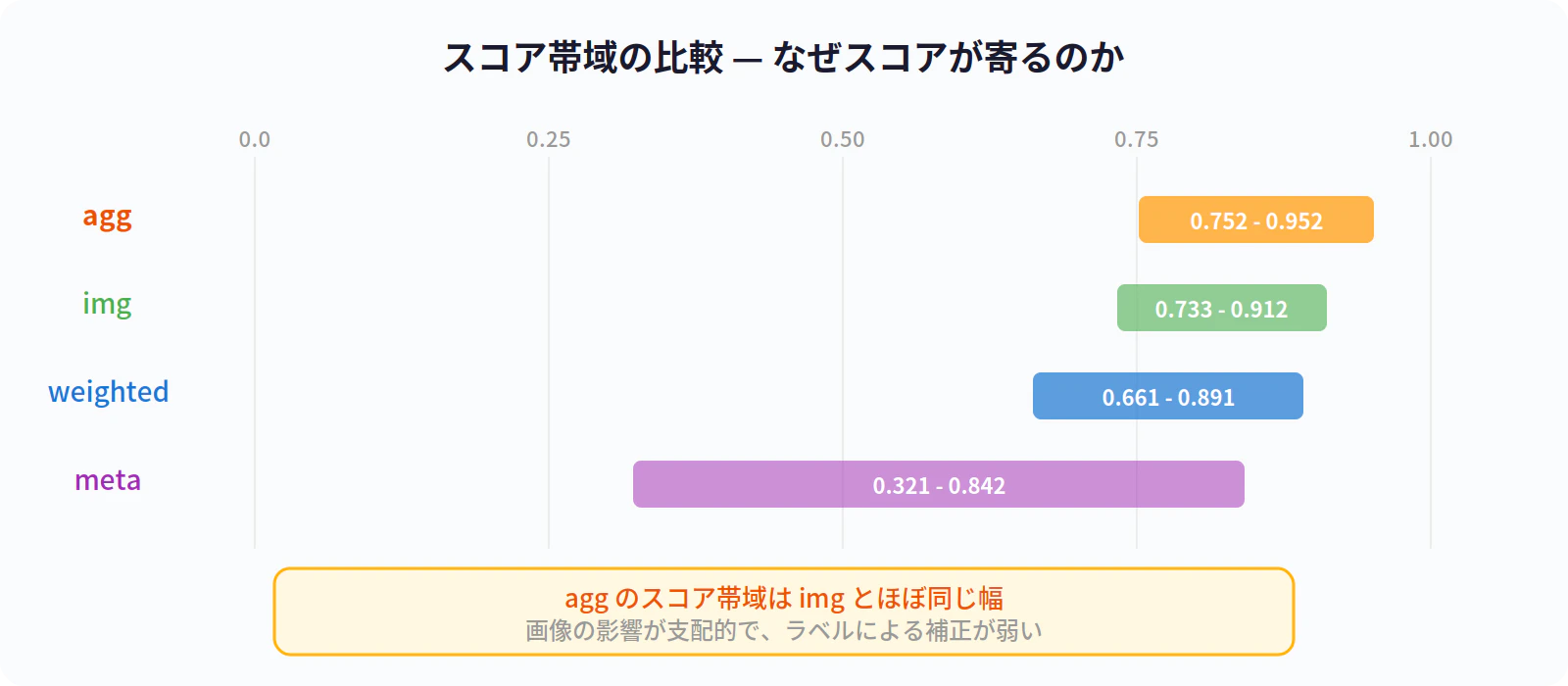
全データのスコア帯域を確認します。
| 方式 | 最小 | 最大 | 幅 |
|---|---|---|---|
| agg | 0.752 | 0.952 | 0.200 |
| img(参考) | 0.733 | 0.912 | 0.179 |
👉 aggのスコア帯域は img とほぼ同じ幅
👉 画像の影響が支配的で、ラベルによる補正が弱い
集約エンベディングはモデル内部で画像とテキストを融合しますが、その重みは制御できません。
👉 ブラックボックスであることが、ここでは弱点になる
改善策①:自分でスコアを制御する
集約エンベディングの課題は、融合の重みを制御できないこと。
👉 ならば、自分で重みを決めて融合する方式を試してみます。
なお、公式ドキュメントの Embedding aggregation セクションでも、複雑なオブジェクトに対しては「個別のエンベディングを集約する(例:平均化)ことを推奨する」と記載されています。
👉 以下のアプローチは、この公式推奨の延長線上にあるものです。
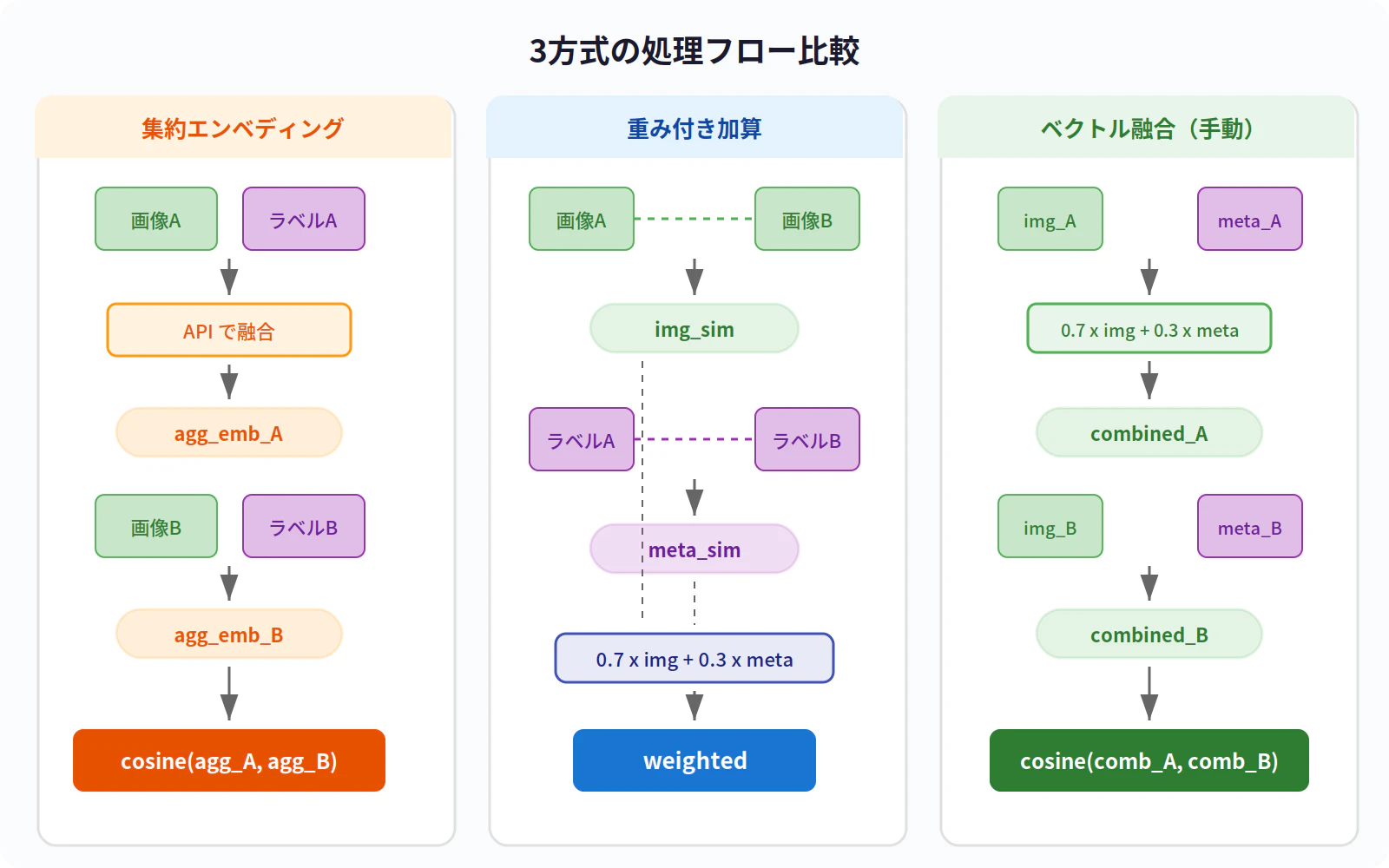
重み付き加算
画像同士・テキスト同士を別々に比較し、スコアレベルで合成します。
image_sim = cosine_similarity(画像A, 画像B)
label_sim = cosine_similarity(テキストA, テキストB)
weighted = 0.7 × image_sim + 0.3 × label_sim
- 重みは「画像が主、ラベルが補助」という前提で探索的に 7:3 に設定
- img と meta が分離して見える → 「なぜこのスコアになったか」が分析できる
ベクトル融合(手動)
画像EmbeddingとラベルEmbeddingを1つのベクトルにまとめてから比較します。
combined_A = 0.7 × image_emb_A + 0.3 × label_emb_A
combined_B = 0.7 × image_emb_B + 0.3 × label_emb_B
fused = cosine_similarity(combined_A, combined_B)
- 集約エンベディングと同じく1ベクトルで保存できるが、重みを自分でコントロールできる
- 実運用で検索インデックスに保存する際は、ベクトルDBによっては正規化済みベクトルを前提とするため、保存前に正規化を推奨
結果
katsu_curry をクエリにした場合:
target weighted fused agg img meta
---------------------------------------------------------------
hayashi_rice 0.771 0.827 0.861 0.848 0.594
butter_chicken_rice 0.754 0.797 0.851 0.832 0.572
dry_curry 0.706 0.758 0.821 0.805 0.476
butter_chicken_nan 0.692 0.732 0.823 0.787 0.470
keema_curry 0.682 0.754 0.808 0.761 0.496
vegetable_curry 0.679 0.754 0.822 0.832 0.321
soup_curry 0.671 0.746 0.822 0.809 0.350
分解能の違い
| 方式 | 1位 | 最下位 | 差 |
|---|---|---|---|
| agg | 0.861 | 0.808 | 0.053 |
| fused | 0.827 | 0.746 | 0.081 |
| weighted | 0.771 | 0.671 | 0.100 |
👉 weightedが最も差がつく
vegetable_curry の位置
| 方式 | スコア | 順位 |
|---|---|---|
| agg | 0.822 | 4位相当 |
| fused | 0.754 | 5位タイ |
| weighted | 0.679 | 6位 |
👉 meta: 0.321(ラベル類似度は低い)が、weighted ではしっかりスコアに反映されている
👉 見た目は似ているが意味は異なることを、weightedが最も正確に捉えている
改善策②:ラベルを充実させる
集約エンベディングの分解能が低い原因は、ラベルが短すぎるのではないか?
👉 ラベルをキーワードから説明文に変えて試してみます。
短いラベル(変更前)
"katsu_curry": "rice, brown curry, fried cutlet"
"hayashi_rice": "brown stew, rice, separated"
長いラベル(変更後)
"katsu_curry": "Japanese katsu curry. Thick golden-brown breaded pork cutlet
sliced into strips, served alongside white rice with Japanese curry sauce
poured over. The curry sauce is dark brown and thick, distinct from
hayashi rice demi-glace."
"hayashi_rice": "Japanese hayashi rice, a demi-glace based beef stew served
over white rice. Dark brown glossy sauce made from roux, red wine, and
tomato. Not a curry despite similar appearance. European-influenced
Japanese dish."

結果
katsu_curry をクエリにした場合(短いラベルの weighted 降順でソート):
--- 短いラベル --- --- 長いラベル ---
target weighted fused agg weighted fused agg
--------------------------------------------------------------------
hayashi_rice 0.771 0.827 0.861 0.817 0.826 0.915
b_chk_rice 0.754 0.797 0.851 0.773 0.767 0.795
dry_curry 0.706 0.758 0.821 0.775 0.771 0.816
b_chk_nan 0.692 0.732 0.823 0.724 0.713 0.751
keema_curry 0.682 0.754 0.808 0.723 0.730 0.793
vegetable_curry 0.679 0.754 0.822 0.795 0.795 0.846
soup_curry 0.671 0.746 0.822 0.750 0.749 0.833
※ b_chk_rice = butter_chicken_rice、b_chk_nan = butter_chicken_nan
期待と異なる結果
hayashi_rice の agg が 0.861 → 0.915 に上昇
👉 ラベルに「distinct from hayashi rice」と書いたのに、逆にスコアが上がった
👉 Embeddingは否定("not", "distinct from")を理解しない。「hayashi rice」という単語自体が類似度を上げてしまった
meta(ラベル同士のスコア)が全体的に底上げ
| ラベル | meta最小 | meta最大 | 幅 |
|---|---|---|---|
| 短い | 0.321 | 0.842 | 0.521 |
| 長い | 0.464 | 0.792 | 0.328 |
👉 長いラベルにしたことで、どのペアも「ある程度似ている」と判定されるようになった
👉 ラベルを詳しくしすぎると、かえって区別がつきにくくなる場合がある
⚠️ Embeddingにおけるラベル設計の原則
Embedding全般に通じる既知の原則として、以下があります。今回の検証結果もこれらと整合しています。
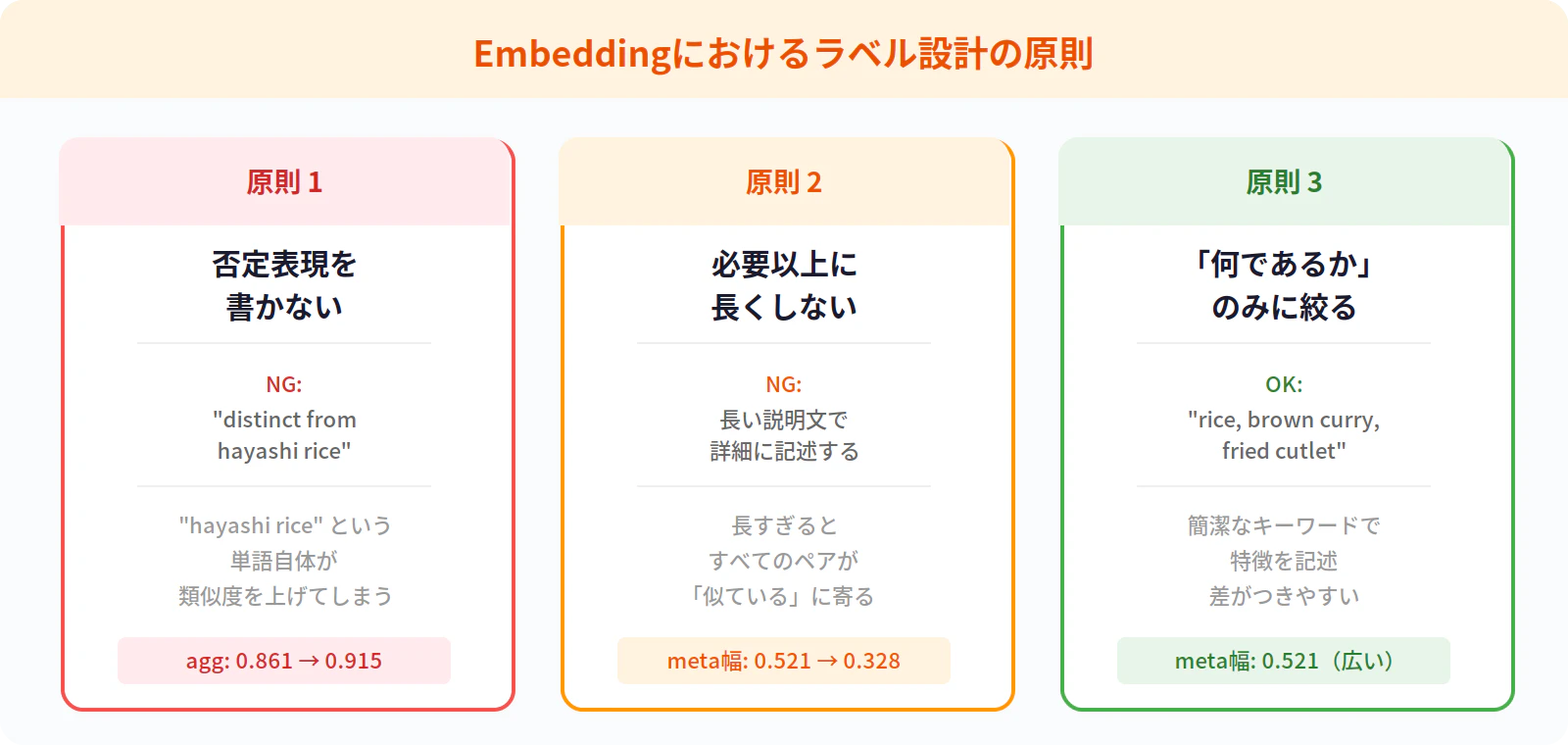
原則1:否定表現を書かない
- 「〇〇ではない」と書くと、〇〇との類似度が上がる
- Embeddingは否定の論理を扱えない
- 今回の例:「distinct from hayashi rice」→ hayashi_rice とのスコアが 0.861 → 0.915 に上昇
原則2:必要以上に長くしない
- ラベルが長いと、すべてのペアが「それなりに似ている」になる
- meta の帯域:短いラベル 0.521 → 長いラベル 0.328 に縮小
- 区別する力が落ちる
原則3:「何であるか」のみに絞る
- 「何であるか」を簡潔なキーワードで書く
- 「何でないか」「どう違うか」は書かない
- 短いキーワード形式の方が差がつきやすい
👉 これらはGemini Embedding 2に限らず、Embeddingを使うシステム全般で重要な原則です。
3方式の比較まとめ
| 観点 | 集約エンベディング | 重み付き加算 | ベクトル融合(手動) |
|---|---|---|---|
| ランキングの分解能 | △(差 0.053) | ◎(差 0.100) | ○(差 0.081) |
| 解釈のしやすさ | △(融合後は分離不可) | ◎(img/metaが分離) | △(融合後は分離不可) |
| 実装のシンプルさ | ◎ | ○ | ○ |
| 重み調整 | 不要 | 必要 | 必要 |
| 検索インデックス | ◎(1ベクトル) | △(2ベクトル必要) | ◎(1ベクトル) |
| API呼び出し回数 | 1回/食品 | 2回/食品 | 2回/食品 |
※ 分解能の差は katsu_curry クエリでの1位と最下位のスコア差
考察
集約エンベディングの評価
メリット:
- API呼び出しが1回で済む(コスト・レイテンシの削減)
- 重みの設計が不要
- 1ベクトルで検索インデックスに保存できる
- 同一料理系の検出は精度が高い(agg: 0.952)
注意点:
- スコアが高い帯域に集中しやすい
- 「似ていない」を明確に判定しにくい
- 画像の見た目の影響が強く残る傾向がある
実運用の進め方
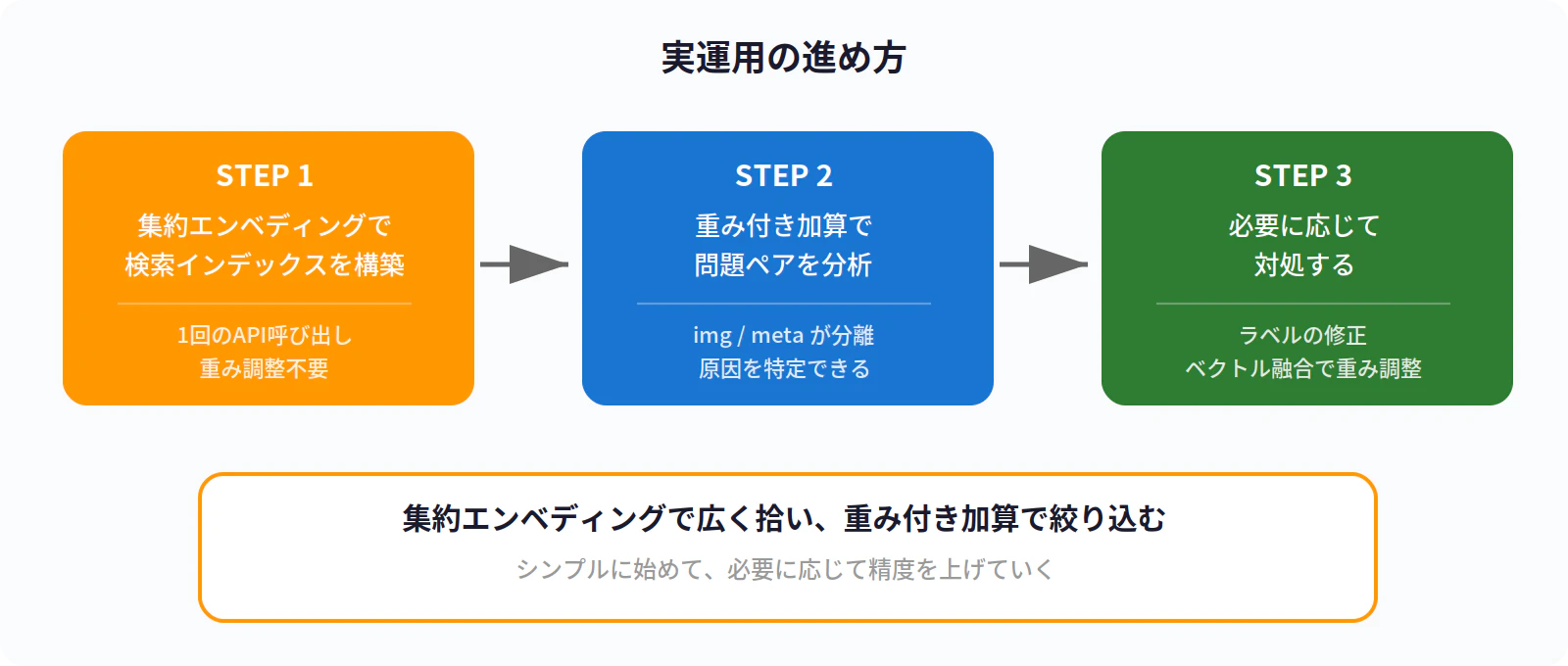
- まず集約エンベディングで検索インデックスを構築(シンプル・低コスト)
- 重み付き加算で分析して、問題のあるペアを特定(img/metaの分離が効く)
- 問題が見つかった場合の対処:
- ラベルの修正(ただし否定表現は使わない)
- **ベクトル融合(手動)**で重みを調整(テキスト重視にするなど)
- 特定ペアの閾値を個別に設定
👉 「集約エンベディングで広く拾い、重み付き加算で絞り込む」
ラベル品質について
- ラベルはLLMによる生成(推測を含む)であり、正解ラベルではない
- 短いキーワード形式の方が差がつきやすい
- 否定表現は使わない
- 長すぎるラベルはかえって分解能を下げる
注意点
- 今回の検証は8種類のカレーという小規模データで行っています。大規模データセットでは傾向が変わる可能性があります
- 画像EmbeddingとラベルEmbeddingはスコア分布が異なる
- 実運用では重みの調整・スコア正規化が重要(重み付き加算・ベクトル融合の場合)
- 今回の手法は誤認を完全に解消するものではなく、スコアの補正(re-ranking)が目的
-
taskTypeを変えた場合にスコアの品質が向上する可能性がある
実装
フルコード
!pip install -q google-genai numpy pillow
import numpy as np
import os
from google.colab import userdata
from google import genai
from google.genai import types
client = genai.Client(api_key=userdata.get("GOOGLE_API_KEY"))
def guess_mime_type(path):
ext = os.path.splitext(path)[1].lower()
if ext in [".jpg", ".jpeg"]:
return "image/jpeg"
elif ext == ".png":
return "image/png"
elif ext == ".webp":
return "image/webp"
else:
raise ValueError(ext)
def cosine_similarity(a, b):
denom = np.linalg.norm(a) * np.linalg.norm(b)
if denom == 0:
print(f"Warning: zero vector detected")
return 0.0
return float(np.dot(a, b) / denom)
def embed_image(path):
"""画像のみのEmbedding: Part を直接渡す"""
with open(path, "rb") as f:
img = f.read()
res = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[types.Part.from_bytes(data=img, mime_type=guess_mime_type(path))]
)
return np.array(res.embeddings[0].values, dtype=np.float32)
def embed_text(text):
res = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=text
)
return np.array(res.embeddings[0].values, dtype=np.float32)
def embed_aggregated(path, meta_text):
"""集約エンベディング: Content でラップして parts に複数の Part を渡す"""
with open(path, "rb") as f:
img = f.read()
res = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
types.Content(
parts=[
types.Part(text=meta_text),
types.Part.from_bytes(data=img, mime_type=guess_mime_type(path))
]
)
]
)
return np.array(res.embeddings[0].values, dtype=np.float32)
foods = {
"butter_chicken_nan": {"path": "butter_chicken_naan.jpg", "meta": "orange curry, naan, creamy"},
"butter_chicken_rice": {"path": "butter_chicken_rice.jpg", "meta": "orange curry, rice, creamy"},
"dry_curry": {"path": "dry_curry.jpg", "meta": "minced meat, rice, dry texture"},
"hayashi_rice": {"path": "hayashi_style.jpg", "meta": "brown stew, rice, separated"},
"katsu_curry": {"path": "katsu_curry.jpg", "meta": "rice, brown curry, fried cutlet"},
"keema_curry": {"path": "keema_curry.jpg", "meta": "minced curry, thick"},
"soup_curry": {"path": "soup_curry.jpg", "meta": "soup style, vegetables"},
"vegetable_curry": {"path": "vegetable_curry.jpg", "meta": "vegetables, colorful"}
}
# Embedding取得
image_embeddings = {}
meta_embeddings = {}
agg_embeddings = {}
for k, v in foods.items():
image_embeddings[k] = embed_image(v["path"])
meta_embeddings[k] = embed_text(v["meta"])
agg_embeddings[k] = embed_aggregated(v["path"], v["meta"])
# --- 集約エンベディング ---
def score_aggregated(q, t):
return cosine_similarity(agg_embeddings[q], agg_embeddings[t])
# --- 重み付き加算 ---
def score_weighted(q, t, alpha=0.7, beta=0.3):
img_sim = cosine_similarity(image_embeddings[q], image_embeddings[t])
meta_sim = cosine_similarity(meta_embeddings[q], meta_embeddings[t])
return alpha * img_sim + beta * meta_sim, img_sim, meta_sim
# --- ベクトル融合(手動) ---
def score_fused(q, t, alpha=0.7):
combined_q = alpha * image_embeddings[q] + (1 - alpha) * meta_embeddings[q]
combined_t = alpha * image_embeddings[t] + (1 - alpha) * meta_embeddings[t]
return cosine_similarity(combined_q, combined_t)
# --- 比較出力 ---
def compare_all(query):
print(f"\n{'='*60}")
print(f"Query: {query}")
print(f"{'='*60}")
results = []
for target in foods:
if target == query:
continue
weighted, img_sim, meta_sim = score_weighted(query, target)
fused = score_fused(query, target)
agg = score_aggregated(query, target)
results.append((target, weighted, fused, agg, img_sim, meta_sim))
results.sort(key=lambda x: x[1], reverse=True)
print(f"\n{'target':<25} {'weighted':>8} {'fused':>8} {'agg':>8} {'img':>8} {'meta':>8}")
print("-" * 73)
for name, w, f, a, i, m in results:
print(f"{name:<25} {w:>8.3f} {f:>8.3f} {a:>8.3f} {i:>8.3f} {m:>8.3f}")
for food in foods:
compare_all(food)
まとめ
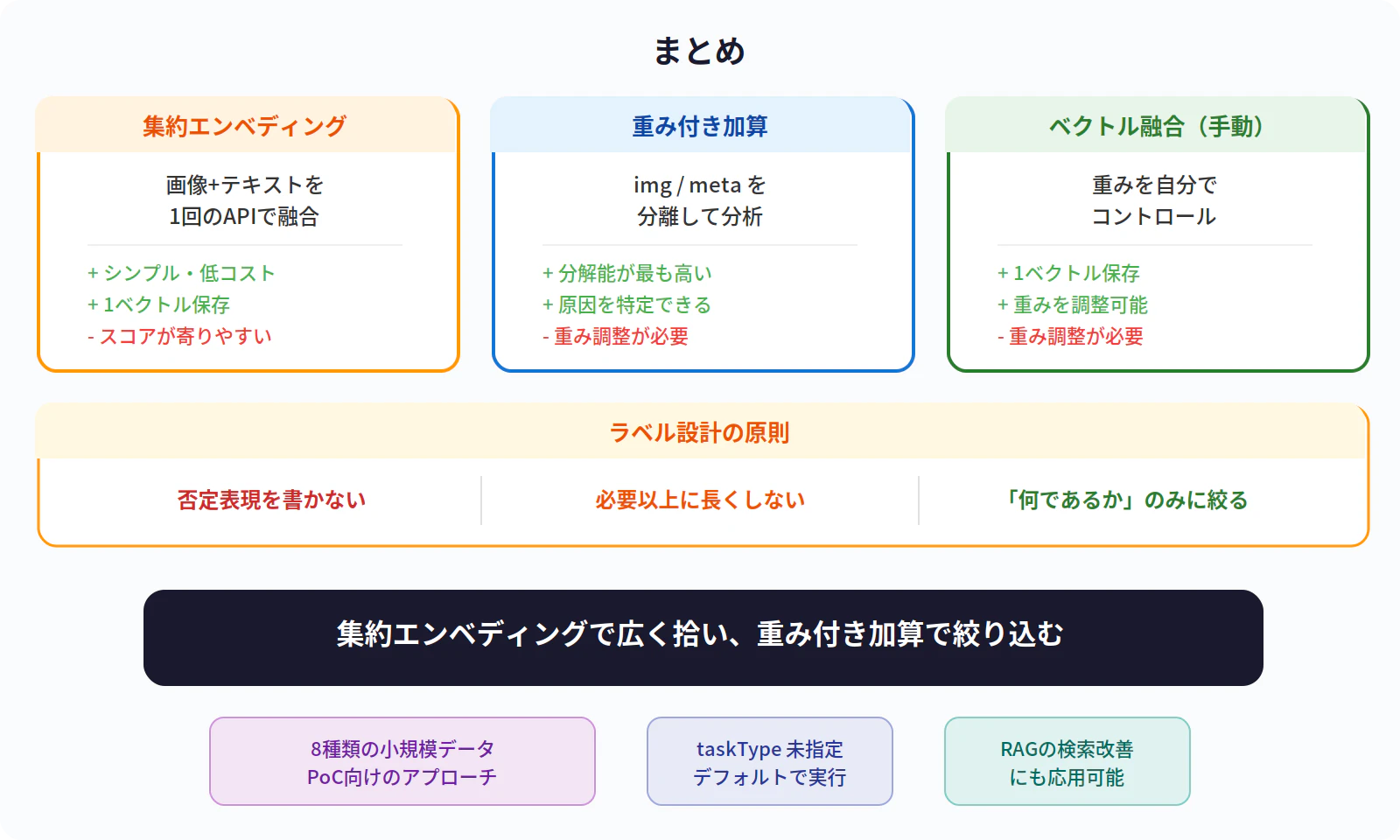
- Gemini Embedding 2 の集約エンベディング(Embedding aggregation)で画像+テキストを1つのEmbeddingにできる
- 同一料理系の検出は精度が高いが、スコアが寄りやすく分解能に課題がある
- 自分で重みを制御する方式(重み付き加算・ベクトル融合)と組み合わせることで改善できる
- ラベルを詳しくしすぎると逆効果になる場合がある(否定表現・情報過多)
- 実運用では「集約エンベディングで広く拾い、重み付き加算で絞り込む」が現実的
おわりに
Gemini Embedding 2 の集約エンベディングは、画像+テキストを1回のAPI呼び出しで融合できる便利な機能です。
ただし今回の検証で、スコアの分解能やラベル設計に注意が必要なことがわかりました。
万能な手法はなく、用途に応じた使い分けが重要です。
👉 「まず集約エンベディングで広く拾い、重み付き加算で絞り込む」
この考え方は、RAGの検索改善にもつながるアプローチです。