はじめに
前回は deque の基本を学びました。今回は、実務でよく使われるパターンを解説します。特にスライディングウィンドウは deque の真価を発揮する場面です。
スライディングウィンドウ
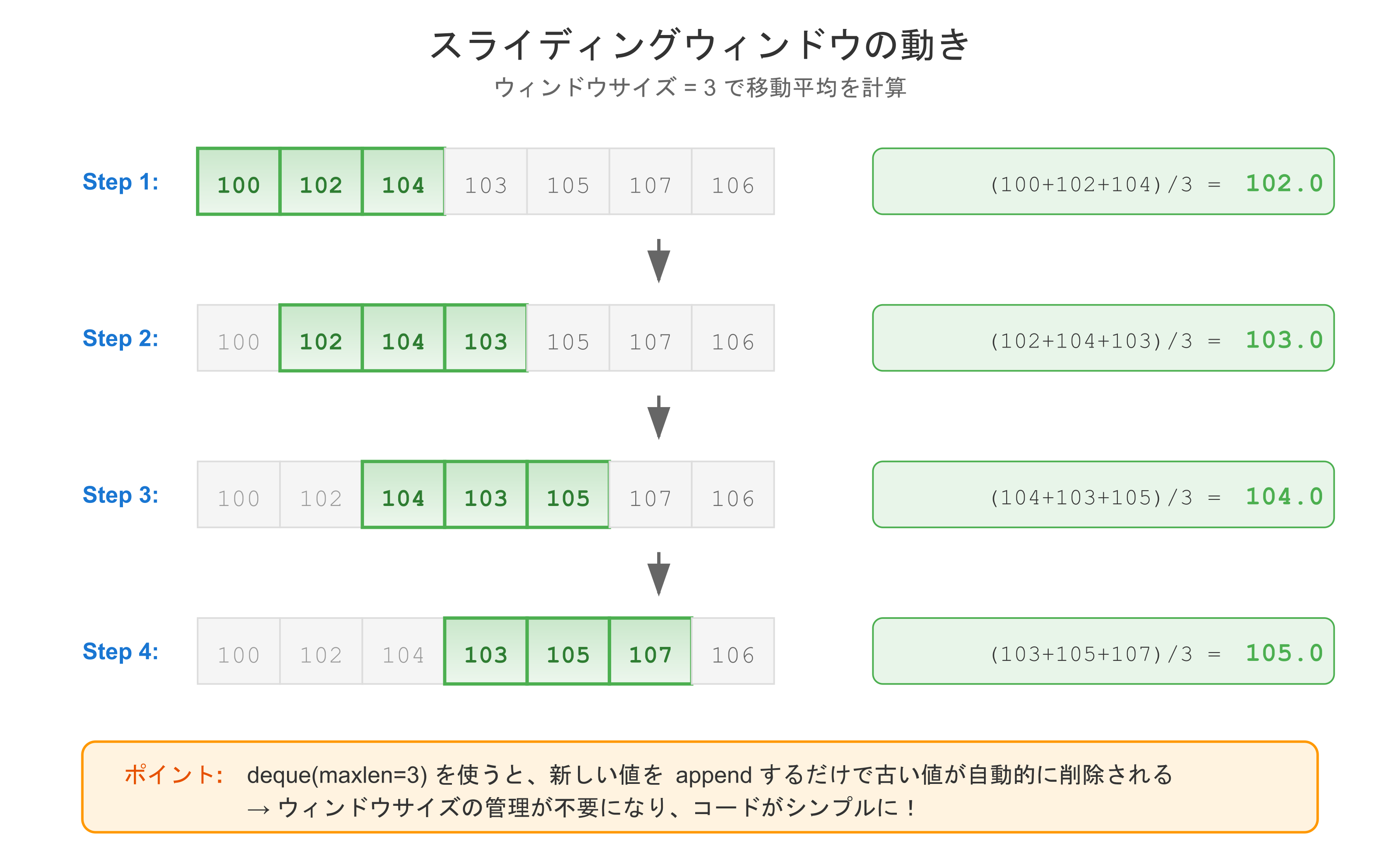
移動平均の計算
from collections import deque
def moving_average(data, window_size):
"""移動平均を計算"""
window = deque(maxlen=window_size)
results = []
for value in data:
window.append(value)
if len(window) == window_size:
avg = sum(window) / window_size
results.append(avg)
return results
# 株価データ
prices = [100, 102, 104, 103, 105, 107, 106, 108, 110, 109]
# 3日間の移動平均
ma = moving_average(prices, 3)
print(ma) # [102.0, 103.0, 104.0, 105.0, 106.0, 107.0, 108.0, 109.0]
最大値・最小値の追跡
from collections import deque
def sliding_max(data, window_size):
"""スライディングウィンドウの最大値を効率的に計算"""
result = []
dq = deque() # インデックスを格納
for i, value in enumerate(data):
# ウィンドウ外の要素を削除
while dq and dq[0] < i - window_size + 1:
dq.popleft()
# 現在の値より小さい要素を削除(不要になる)
while dq and data[dq[-1]] < value:
dq.pop()
dq.append(i)
# ウィンドウが満たされたら結果を記録
if i >= window_size - 1:
result.append(data[dq[0]])
return result
data = [1, 3, 2, 5, 4, 6, 2]
print(sliding_max(data, 3)) # [3, 5, 5, 6, 6]
リングバッファ
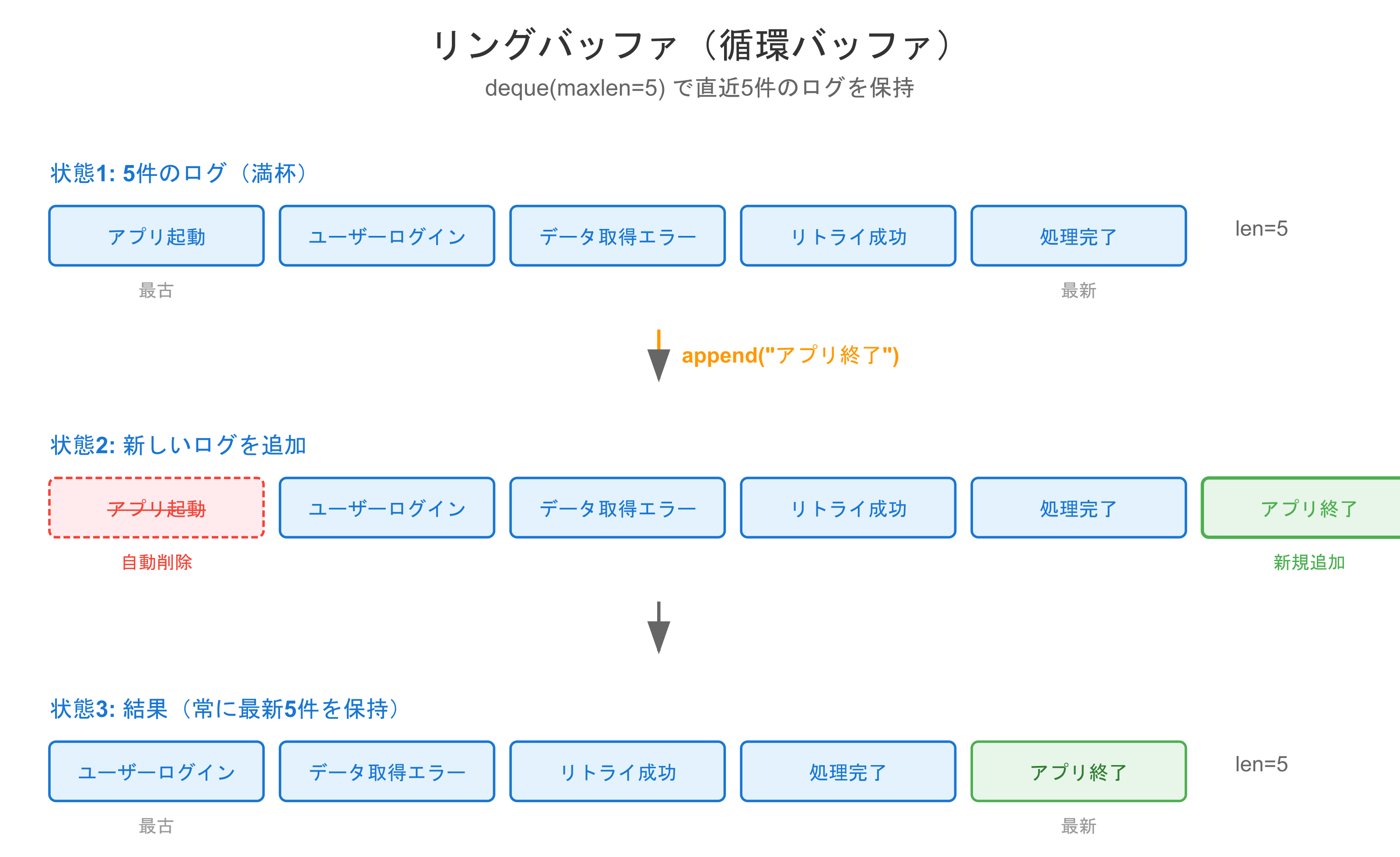
ログのローテーション
from collections import deque
from datetime import datetime
class RollingLog:
"""直近N件のログを保持"""
def __init__(self, max_entries=100):
self.entries = deque(maxlen=max_entries)
def add(self, message, level="INFO"):
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
self.entries.append({
"timestamp": timestamp,
"level": level,
"message": message
})
def get_recent(self, n=10):
"""直近N件を取得"""
return list(self.entries)[-n:]
def get_errors(self):
"""エラーログだけ取得"""
return [e for e in self.entries if e["level"] == "ERROR"]
# 使用例
log = RollingLog(max_entries=5)
log.add("アプリ起動")
log.add("ユーザーログイン")
log.add("データ取得エラー", "ERROR")
log.add("リトライ成功")
log.add("処理完了")
log.add("アプリ終了") # 最古のログが消える
print("直近のログ:")
for entry in log.get_recent(3):
print(f" [{entry['level']}] {entry['message']}")
Undo/Redo の実装
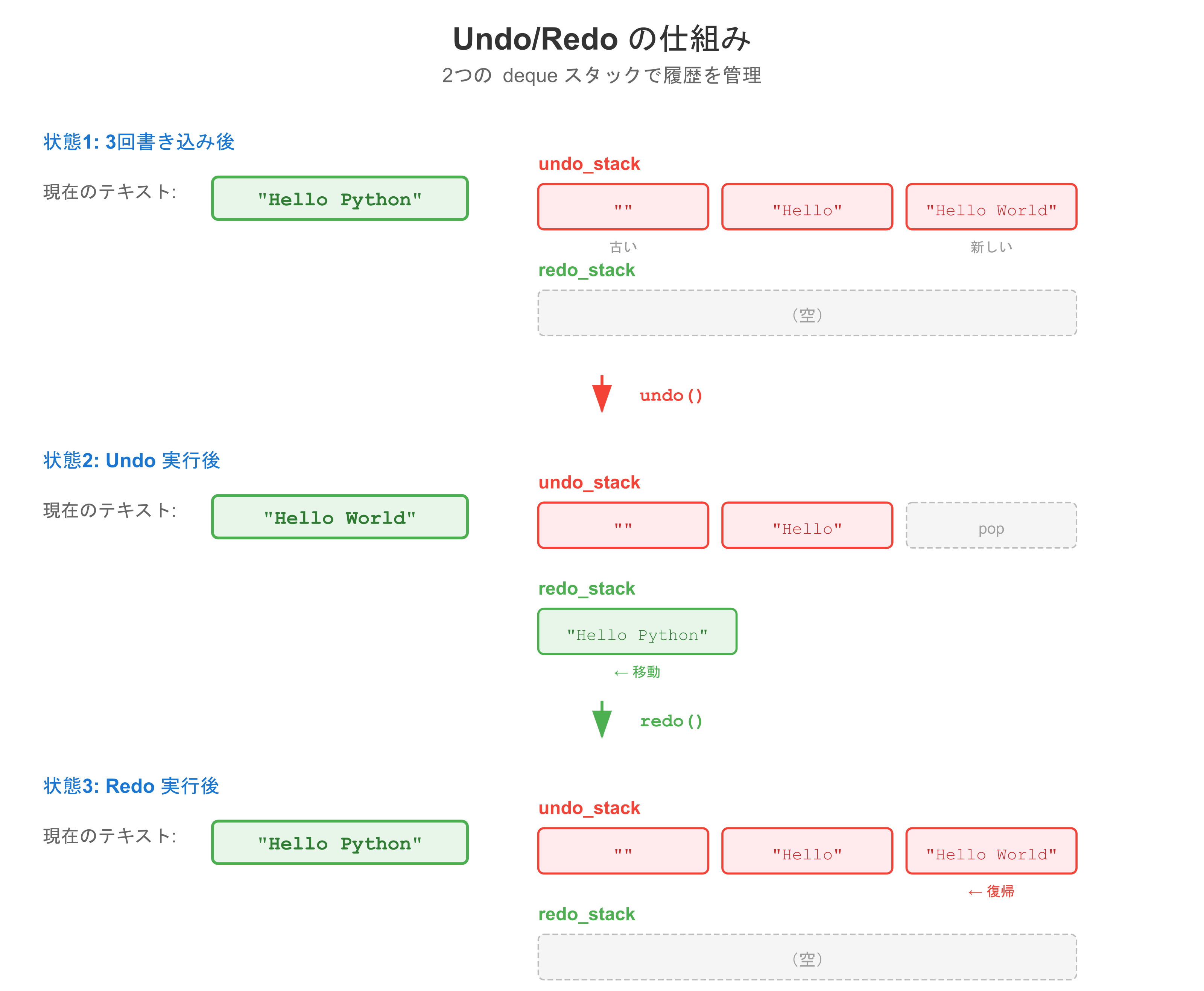
from collections import deque
class TextEditor:
"""Undo/Redo機能付きテキストエディタ"""
def __init__(self, max_history=50):
self.text = ""
self.undo_stack = deque(maxlen=max_history)
self.redo_stack = deque(maxlen=max_history)
def write(self, new_text):
"""テキストを書き込み"""
self.undo_stack.append(self.text)
self.redo_stack.clear()
self.text = new_text
def undo(self):
"""元に戻す"""
if self.undo_stack:
self.redo_stack.append(self.text)
self.text = self.undo_stack.pop()
def redo(self):
"""やり直し"""
if self.redo_stack:
self.undo_stack.append(self.text)
self.text = self.redo_stack.pop()
# 使用例
editor = TextEditor()
editor.write("Hello")
editor.write("Hello World")
editor.write("Hello Python")
print(editor.text) # Hello Python
editor.undo()
print(editor.text) # Hello World
editor.undo()
print(editor.text) # Hello
editor.redo()
print(editor.text) # Hello World
BFS(幅優先探索)
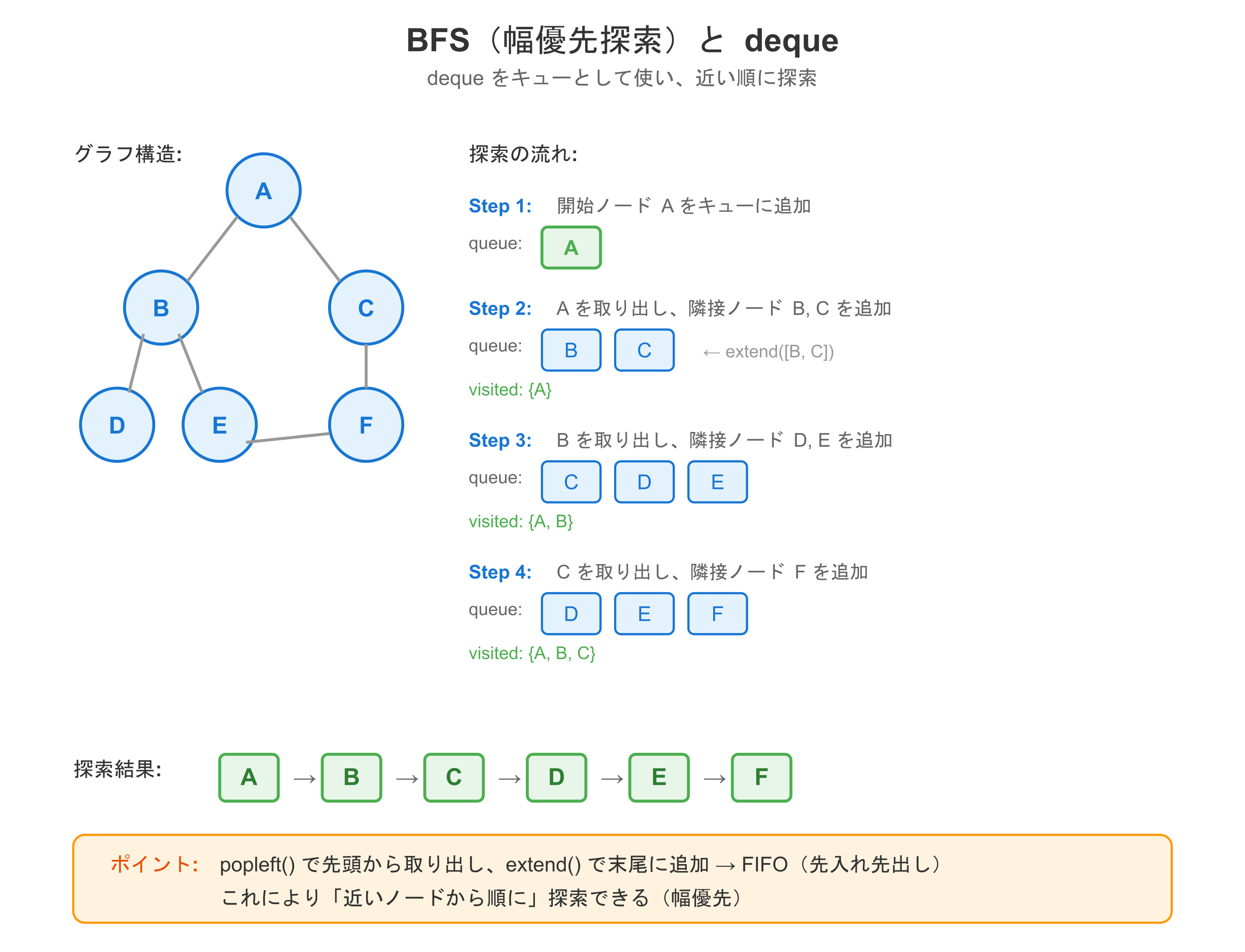
from collections import deque
def bfs(graph, start):
"""幅優先探索"""
visited = set()
queue = deque([start])
result = []
while queue:
node = queue.popleft()
if node not in visited:
visited.add(node)
result.append(node)
queue.extend(graph.get(node, []))
return result
# グラフ(隣接リスト)
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
print(bfs(graph, 'A')) # ['A', 'B', 'C', 'D', 'E', 'F']
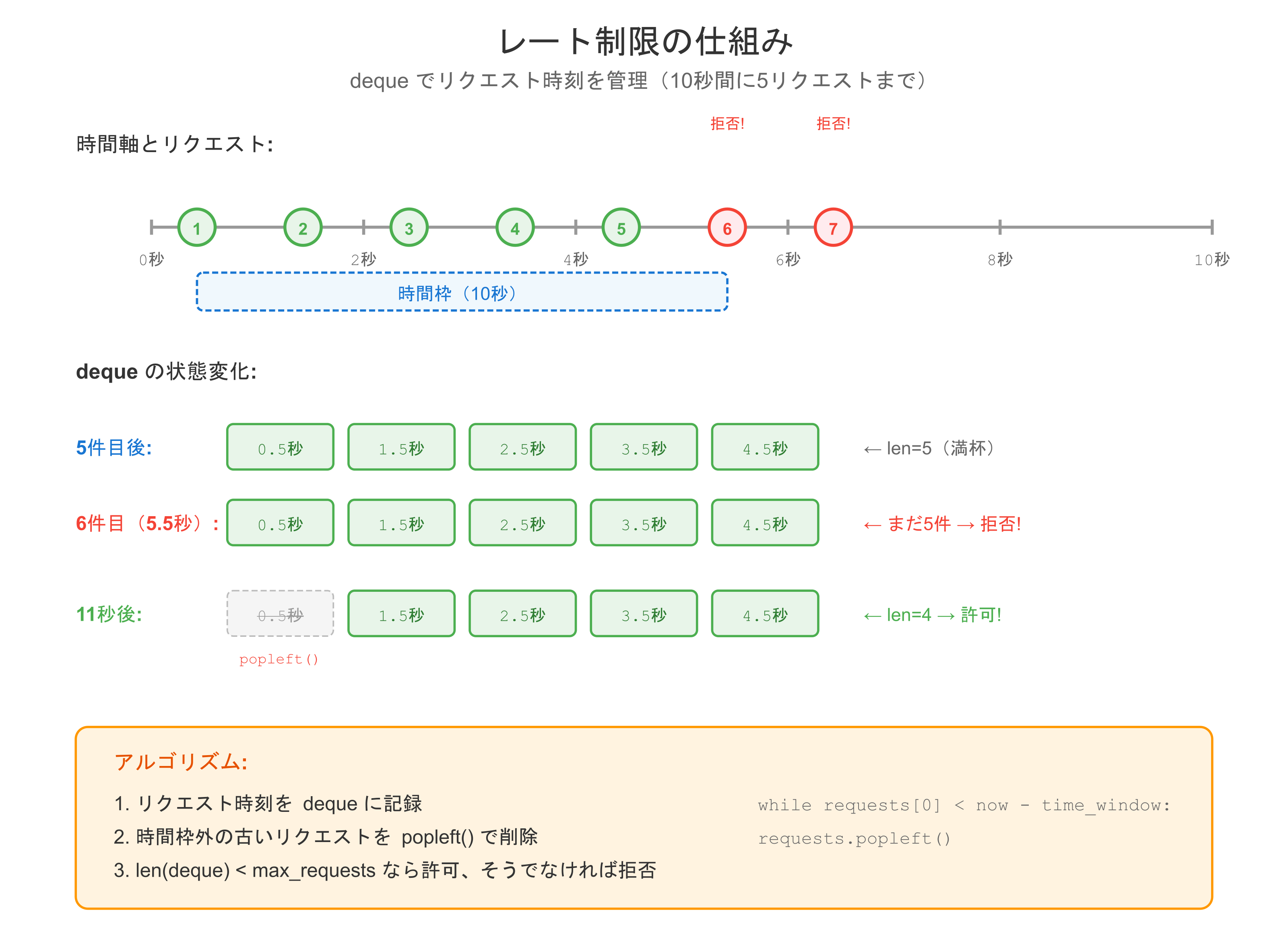
レート制限
from collections import deque
import time
class RateLimiter:
"""リクエストのレート制限"""
def __init__(self, max_requests, time_window):
"""
Args:
max_requests: 許可する最大リクエスト数
time_window: 時間枠(秒)
"""
self.max_requests = max_requests
self.time_window = time_window
self.requests = deque()
def is_allowed(self):
"""リクエストが許可されるか判定"""
now = time.time()
# 時間枠外のリクエストを削除
while self.requests and self.requests[0] < now - self.time_window:
self.requests.popleft()
if len(self.requests) < self.max_requests:
self.requests.append(now)
return True
return False
# 使用例: 10秒間に5リクエストまで
limiter = RateLimiter(max_requests=5, time_window=10)
for i in range(7):
if limiter.is_allowed():
print(f"リクエスト {i+1}: 許可")
else:
print(f"リクエスト {i+1}: 拒否(レート制限)")
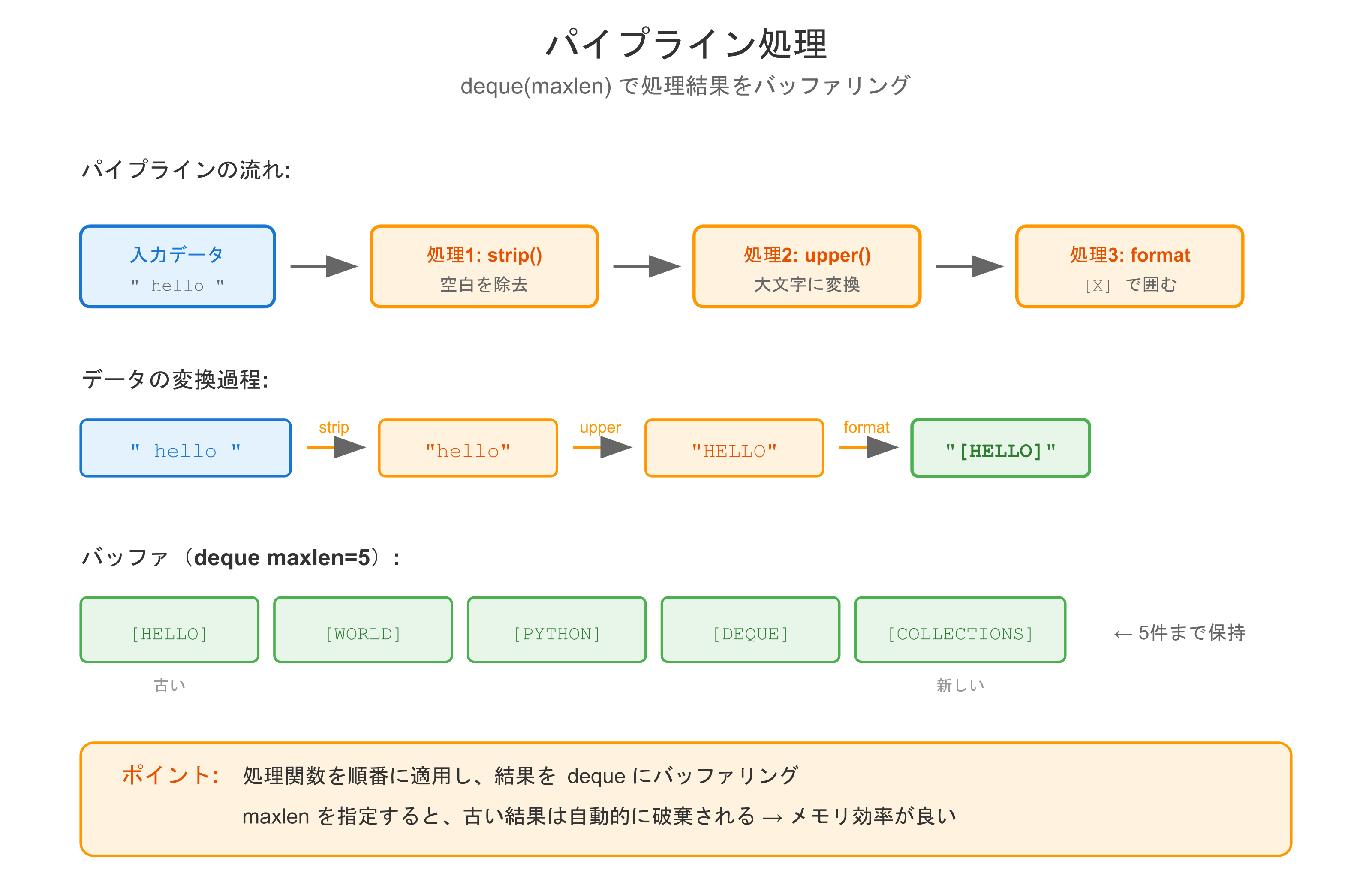
パイプライン処理
from collections import deque
class Pipeline:
"""データ処理パイプライン"""
def __init__(self, buffer_size=10):
self.buffer = deque(maxlen=buffer_size)
self.processors = []
def add_processor(self, func):
"""処理関数を追加"""
self.processors.append(func)
return self
def push(self, item):
"""データを投入"""
result = item
for processor in self.processors:
result = processor(result)
self.buffer.append(result)
def get_results(self):
"""結果を取得"""
return list(self.buffer)
# 使用例
pipeline = Pipeline(buffer_size=5)
pipeline.add_processor(lambda x: x.strip())
pipeline.add_processor(lambda x: x.upper())
pipeline.add_processor(lambda x: f"[{x}]")
data = [" hello ", "world", "python ", "deque", "collections"]
for item in data:
pipeline.push(item)
print(pipeline.get_results())
# ['[HELLO]', '[WORLD]', '[PYTHON]', '[DEQUE]', '[COLLECTIONS]']
回文判定

from collections import deque
def is_palindrome(text):
"""回文かどうか判定"""
# 空白を除去して小文字に
cleaned = ''.join(text.lower().split())
dq = deque(cleaned)
while len(dq) > 1:
if dq.popleft() != dq.pop():
return False
return True
print(is_palindrome("A man a plan a canal Panama")) # True
print(is_palindrome("hello")) # False
print(is_palindrome("level")) # True
deque vs queue.Queue
スレッドセーフが必要な場合は queue.Queue を使います。
from collections import deque
from queue import Queue
# deque: シングルスレッド向け(高速)
dq = deque()
dq.append(1)
dq.popleft()
# Queue: マルチスレッド向け(スレッドセーフ)
q = Queue()
q.put(1)
q.get()
| 項目 | deque | queue.Queue |
|---|---|---|
| スレッドセーフ | △(個別操作はアトミック) | ◎ |
| パフォーマンス | ◎ | △ |
| ブロッキング | × | ◎ |
| 用途 | 一般的なキュー | マルチスレッド |
注意: deque の append/pop 系メソッドは GIL により個別にはアトミックですが、
複合操作(例:if dq: dq.popleft())は競合状態になり得ます。
マルチスレッド環境ではqueue.Queueを推奨します。
まとめ
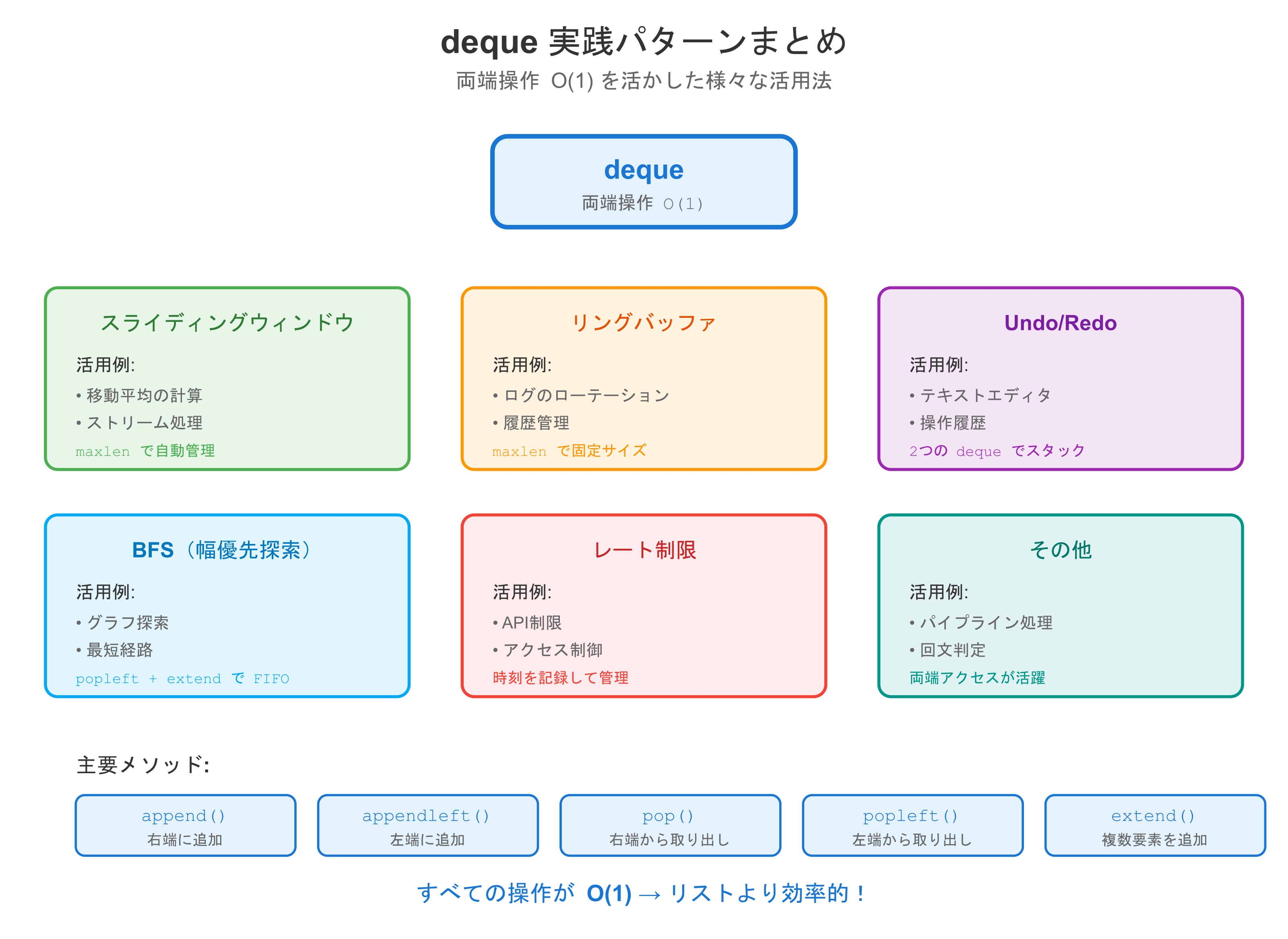
| パターン | 活用例 |
|---|---|
| スライディングウィンドウ | 移動平均、ストリーム処理 |
| リングバッファ | ログ、履歴管理 |
| Undo/Redo | エディタ、操作履歴 |
| BFS | グラフ探索、最短経路 |
| レート制限 | API制限、アクセス制御 |
deque は両端操作が O(1) という特性を活かして、様々なアルゴリズムを効率化できます!