はじめに
この記事では、Open Web UIのRetrieval Augmented Generation (RAG) の実装に焦点を当て、特にベクトルデータベースの使用方法とその重要性について掘り下げます。RAGは、情報検索と生成を組み合わせた強力な手法であり、ドキュメント参照によって、より正確な情報を生成することが可能になります。
Open Web UIとは何か?
Open WebUIは、完全にオフラインで操作できる拡張性が高く、機能豊富でユーザーフレンドリーな自己ホスティング型のWebUIです。OllamaやOpenAI互換のAPIを含むさまざまなLLMランナーをサポートしています。
RAGの役割
RAGは、質問に対する答えを生成する際に、関連するドキュメントを検索し、その内容を参照して回答を生成する技術です。これにより、回答の質が大幅に向上し、より信頼性の高い情報提供が可能になります。
ベクトルデータベースの重要性
ベクトルデータベースは、大量のデータを効率的に処理し、検索するための技術です。RAGの実装においては、このデータベースがドキュメントの検索と参照のプロセスを支える重要な役割を果たします。
この記事を通じて、GitHubリポジトリの具体的な分析を通じて、実際のコードの見方と理解の仕方を示すことができるでしょう。
Open Web UIの概要
ドキュメントの登録
Open Web UIには、ユーザーが問い合わせた内容に関連するドキュメントを検索し、その情報を基に回答を生成するドキュメント登録機能が備わっています。この機能は、AIが提供する情報の精度を高めるために重要な役割を果たします。
+でドキュメントを登録できる。
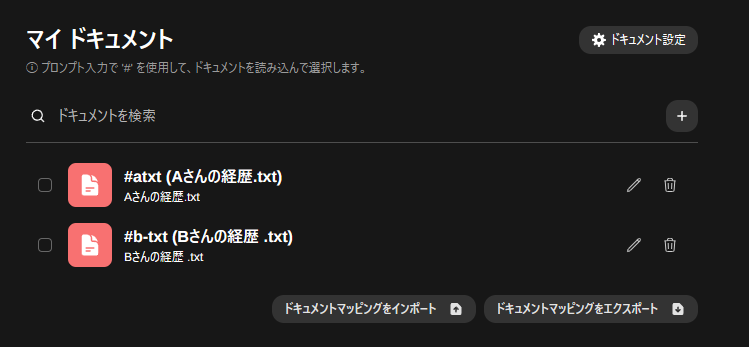
チャットでのドキュメントの参照方法

#で登録したドキュメントを参照できる
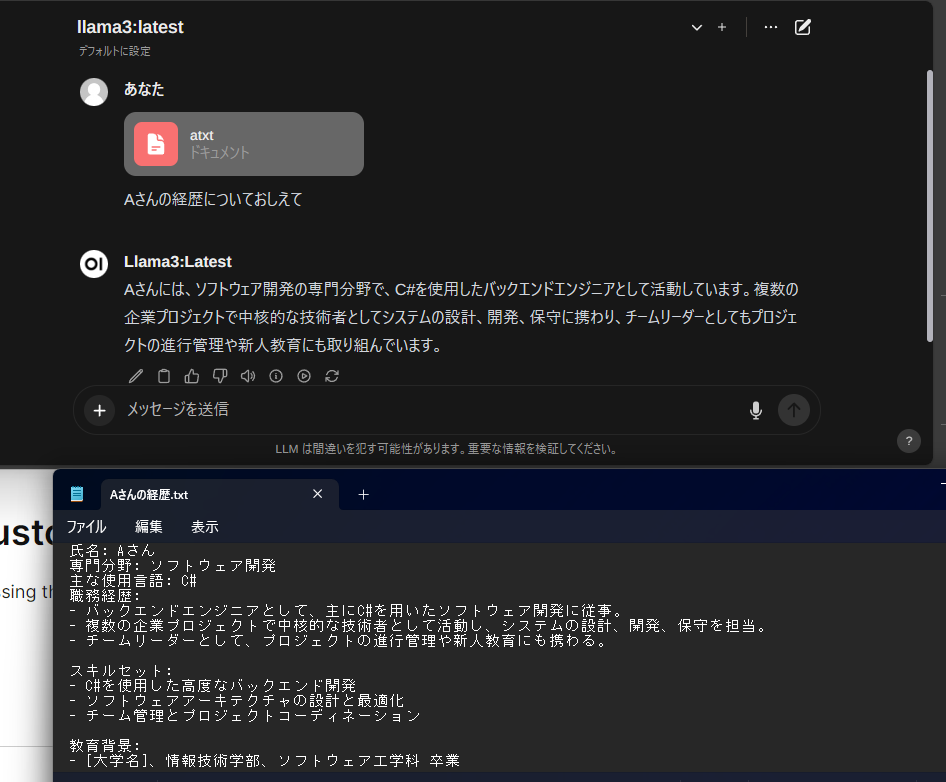

ローカルPCにインストールされたollamaというプラットフォームを使用し、llama3モデルを活用して、ドキュメントの内容に基づいて回答を生成しています。
もっと複雑なドキュメントになると、精度がどうなるかわからないが、これくらいの文章量だと抽出できてそう。
Open Web UIのRAGの実装の確認
機能が期待通りに動作していることに驚きました。この機能が実際にRAGを使用しているか疑問に思ったため、公式ドキュメントを確認しました。
公式サイトの確認
ちゃんと機能として実装されているようだ。ドキュメントをパースする、実装のリンクもしめされていた。
コードの確認
get_loader関数でファイルの拡張子ごとに分岐して処理しているようだ。

langchainの関数を使用してなど、ベクトルDBに登録した情報を蓄積しているようだ。TextLoaderなど。
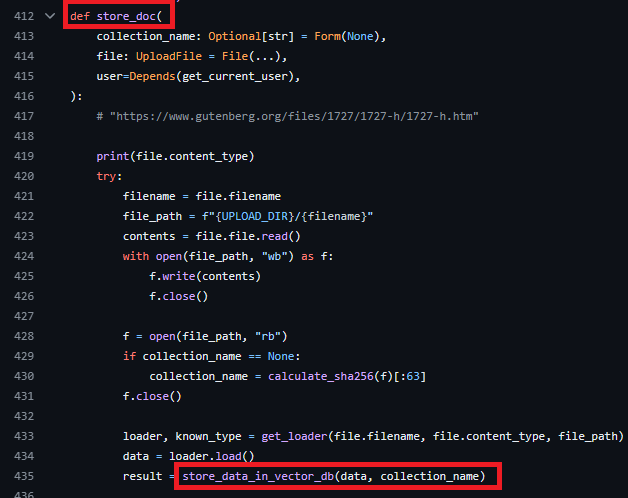
store_data_in_vector_db関数を通じて、テキストデータをベクトルデータベースに組み込む処理が行われているようだ。この関数では、テキストを分割し、各ドキュメントをベクトル化し、CHROMA_CLIENTを用いてデータベースにデータを追加しています。これにより、ベクトルデータベースに文書を格納し、後でチャットから参照が可能になっています。
まとめ
Open Web UIのRetrieval Augmented Generation (RAG) とベクトルデータベースの統合は、AIによる情報提供の精度を革新します。実装の分析と検証を通じて、これらの技術を適用するための方法論を確認しました。