はじめ
前回はベクトル検索について詳しく解説しました。今回は最近話題になっているRAGについて、業務で実際に構築した例をベースにお話出来れば、と思います。
前回の記事:
本記事では、RAGについての軽い解説と実践について、ChatBotのAWS上でのアーキテクチャ例の紹介と一部実装例を紹介します。
検索拡張生成(RAG)について
大まかに以下のようなアーキテクチャを取るシステムです。
図1.RAGのアーキテクチャ
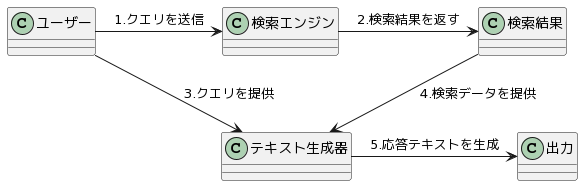
RAG(Retrieval-Augmented Generation)は、検索機能とテキスト生成を組み合わせた技術です。和訳して、検索拡張生成とも言います。上記アーキテクチャを採用することで、特定のクエリや質問に対してより正確で専門的な情報に基づいた回答を生成することができます。また、大規模言語モデルが起こすハルシネーション(嘘をさも本当のことかのように話してしまう)を軽減することができます。以下に各ステップについて詳しく説明していきます。
1.クエリの送信(図1の1.部分):
ユーザーがシステムにクエリ(質問やリクエスト)を送信します。このクエリは、通常、自然言語で表現されます。検索エンジンの種類によってはクエリは予め埋め込みベクトルに変換して検索エンジンに渡します。その場合ここにはクエリを埋め込みベクトルに変換する処理が入ります。
2.検索結果の取得(図1の2.部分):
検索エンジンは、見つかった情報を「検索結果」として返します。これには、クエリに関連するテキストやデータが含まれます。質問に答えられるほどの適切かつ十分な情報が含まれている必要があります。
3.テキスト生成器への入力(図1の3./4.部分):
テキスト生成器には通常ChatGPTやGemini、llamaなどのTransformerに準ずるものを利用した大規模言語モデル(LLM)を用います。検索結果はテキスト生成器に送られます。同時に、ユーザーからの元のクエリもテキスト生成器に直接提供されます。この組み合わせにより、テキスト生成器はより精度の高い応答を生成できるようになります。
余談ですが、この関連データを元にユーザーの質問に答えることをまるで文脈内を学習して答えているように見えるため”文脈内学習”と呼ぶが多いです。より大規模な言語モデルほどこの文脈内学習が行われていると研究結果もあります。
4.応答テキストの生成(図1の5.部分):
テキスト生成器は、検索データとユーザーのクエリを基に、適切な応答テキストを生成します。基本的に生成された応答は「出力」としてユーザーに返されます。この応答が適切かどうかを判定する場合はここにフィルタリングの処理を入れたりもできます。ユーザーのクエリに基づいた情報を含み、質問に答えるか、リクエストに対する情報を提供します。
検索拡張生成(RAG)の課題
上記のようにRAGは単純なアーキテクチャに見えるかもしれませんが、実際のRAGを使ったアプリケーション開発では様々な課題が存在します。以下に実際に運用してみて見えた課題と対策を書いていきます。
検索手法の最適化:
適切な検索結果を得るためには、高度な検索の最適化が必要です。特に専門的な知識やドメイン固有のデータに基づくベクトル検索を構築する際、多様な埋め込み・embbeding手法の中から最適なものを選ぶ必要があります。ここについては前回の記事のembeddingモデルの選定に詳細を書いたので、対策はそちらを参照してください。
検索データの最適化:
検索の精度をあげるためには、埋め込みベクトルとして変換される前のテキストデータの前処理方法の最適化が必要です。例えば、「。」で区切られた明確な文節や、一定の文字数で区切られたテキストなど、さまざまなデータの切り分け方法が検索精度に影響を及ぼします。事前にLLMに要約させるのも良いですが、重要な情報が消えてしまう場合もあります。一番は意味を保持したまま文字数の少ないテキストデータに落とし込むことです。htmlなどのタグがあれば文字数が少ない別の表現に置き換えたり(htmlをマークダウン形式に落とし込む)、見出しと文章の塊で切り出す、不必要な表現があれば消すのも対策として良いと思います。
データソースの統合と品質管理:
異なるデータソースからの情報を統合もしくは管理し、その正確性と関連性を維持することが重要です。様々な専門知識が入ってくると類似度検索が劣化するということが起こりがちです。この場合対策として、ベクトル検索時の事前フィルタリングなどを用いるかそもそものDBを用途別で分けて対応するようにすると類似度の検索が劣化しにくくなります。いずれにせよ類似度検索の精度を検証できるデータセット(例えば、質問に対して検索結果に出るべき正解データのペアのデータセット)を用意してテストや評価を出来るようにしておくと、より良くなります。
スケーラビリティとパフォーマンス:
多くのユーザーに対応するためには、システムの拡張性と高速な応答性が求められます。DB等であればレプリケーション、アプリケーションも非同期処理やマルチスレッドにするなどのパフォーマンス向上が必要になります。RAGの実装をする際には処理の重い自然言語処理をすることが多く、ノンブロッキングな実装について正しい理解と実装をする必要があります。
ChatBotアーキテクチャ例
図2.AWSで構築するRAGを使ったChatBotのアーキテクチャ例

上記アーキテクチャ図のplant umlのコードは以下のような感じ
@startuml
title AWS ECSを使用したRAGアプリケーションとOpenSearch
left to right direction
' ① アイコンの定義 & インポート
!define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/v17.0/dist
!includeurl AWSPuml/AWSCommon.puml
!includeurl AWSPuml/General/Client.puml
!includeurl AWSPuml/Groups/AWSCloud.puml
!includeurl AWSPuml/ApplicationIntegration/APIGateway.puml
!includeurl AWSPuml/Containers/ElasticContainerService.puml
!includeurl AWSPuml/Analytics/OpenSearchService.puml
!includeurl AWSPuml/AWSSimplified.puml
' ② 利用するアイコンを宣言
Client(clientUser, "ユーザー", "ユーザー端末")
' AWSクラウドの定義
AWSCloudGroup(awscloud) {
APIGateway(apiGateway, "API Gateway", "APIゲートウェイ")
ElasticContainerService(ecs, "ECS(RAG App)", "RAG用ECS")
OpenSearchService(opensearch, "OpenSearchService", "OpenSearch")
}
' OpenAIのAPIサーバーの定義
rectangle "OpenAI Completion API" as openAICompletion
rectangle "OpenAI Embedding API" as openAIEmbedding
' ③ アイコンの関係を記述
clientUser --> apiGateway : 1.クエリを送信
apiGateway --> clientUser : 10.応答を返す
apiGateway --> ecs : 2.クエリを送信
ecs --> apiGateway : 9.応答を返す
ecs --> openAIEmbedding : 3.埋め込み処理を実行
openAIEmbedding ---> ecs : 4.埋め込み結果を返す
ecs --> openAICompletion : 7.Completion APIを呼び出し
openAICompletion --> ecs : 8.テキスト生成の結果を返す
ecs --> opensearch : 5.ベクトル検索を実行
opensearch --> ecs : 6.関連するデータを返す
@enduml
構成要素:
ユーザー:エンドユーザーがクエリとして質問文などを送信します。
API Gateway:ユーザーからのリクエストを受け取り、適切なバックエンドサービス(この場合はECS)にルーティングします。
ECS (Elastic Container Service):RAGアプリケーションが稼働するAWSのコンテナ管理サービス。ここでクエリの処理が行われます。
OpenSearch Service:高度な検索機能を提供するAWSのサービスです。ECSからのリクエストに基づいて関連データを検索(ベクトル検索)し、結果をECSに返します。
OpenAI Completion API:応答に使うテキスト生成のために、ECSから呼び出されるOpenAIのAPIです。
OpenAI Embedding API:ベクトル検索を行うための前処理としてテキストの埋め込み処理を行うAPIで、ECSから呼び出されます。これは検索データをOpenSearchに貯めるものと同じEmbeddingモデルであるべきです。
ChatBotはMVPなどで作ることが多いので最初のうちはシンプルなアーキテクチャの方が良いと思います。軌道に乗ったら、API Gatewayの後ろにELB(Elastic Load Balancing)を配置することで並列処理やスケーリングを強化し、OpenSearch Serviceにレプリケーションを設定することで分散処理と耐障害性を向上させることも視野に入れてアーキテクチャを更新していけると良いかもしれないですね。
上記のアーキテクチャ例ではembeddingやテキスト生成をOpenAIのAPIを使っていますが、もしいずれかを自前で用意する場合は高性能なGPUを搭載したVPCを借りて、並列処理を考慮した実装をしなければいけません。実装も運用もコストが高い選択なので、専門性も高く戦略上自前で用意した方が有益か、かけられる予算・要件等を精査して採用するべきでしょう。
RAGを使ったChatBotの実装
メッセージテンプレート
基本的なChatBotの実装としては、メッセージテンプレートのようなものを予め用意しておくと良いです。pythonの場合以下のような感じ。
from dataclasses import dataclass
import textwrap
@dataclass(frozen=True)
class MessageTemplate:
error = "申し訳ありませんが、エラーが発生しました。\nもう一度お試しいただくか、しばらく待ってから再度ご利用ください。\n"
not_enough = "質問は2文字以上でお願いします。\n"
no_answer = "適切な回答を見つけることができませんでした。\n"
no_search = "お役に立てず申し訳ありません。他に質問があれば、お気軽にどうぞ。\n"
disclaimer = "※提供される情報は参考程度にご利用ください。正確性は保証されません。\n"
help_message = textwrap.dedent(
"""
このBotは最新のAI技術を基にしており、
あなたの質問に対して最適な案内を提供します。
例えば以下のような質問に答えることができます:
- 「今日の天気は?」
- 「数学の問題を解いて」
- 「最新のニュースを教えて」
など
"""
)
こんな感じでTemplateを書いておくとメッセージ管理がしやすいです。dataclassを使用してメッセージを整理し、textwrapモジュールで複数行のテキストを視認性高く管理することができます。メッセージテンプレートは、特定の質問のカテゴリーに対する案内メッセージやユーザー入力に対する固定的な反応(エラー・異常系)、一般的なFAQに対する回答テンプレートを重点的に揃えて置くと便利です。
embeddingの生成
OpenAIのEmbeddingAPIを使う場合を書いておきました。text-embedding-ada-002の場合は1536次元。その他BERTモデルを使う場合はtransformersなどを使って自前でTokenizeとエンコードをしてください。
import os
import time
import openai
from pkg.custom_error import CustomException
openai.api_key = os.environ["OPENAI_API_KEY"]
class EmbeddingDataSourceOpenAI():
def __init__(self):
self.model = "text-embedding-ada-002"
def create_embedding(self, text: str, max_retries=3, backoff_time=1):
"""Generate an embedding with retries on server errors."""
for attempt in range(max_retries):
try:
res = openai.Embedding.create(model=self.model, input=text)
embedding = res["data"][0]["embedding"] # type: ignore
return embedding
except Exception as err:
if "overloaded" in str(err) or "not ready" in str(err):
if attempt < max_retries - 1:
print(
f"Retry {attempt + 1}/{max_retries} after {backoff_time} seconds."
)
time.sleep(backoff_time)
backoff_time *= 2 # Exponential backoff
else:
raise Exception("Failed to generate embedding after retries.")
一応名古屋大のSimCSEのモデルでのembedding生成のコードも載せておきます。sentence transformersを使えば簡単。次元数は768だそうです。
from sentence_transformers import SentenceTransformer
sentences = ["テスト"]
model = SentenceTransformer("cl-nagoya/sup-simcse-ja-base")
embeddings = model.encode(sentences)
print(embeddings)
ベクトル検索
OpenSearchを使ってpythonでベクトル検索する関数とそのindexの作成、追加と削除する簡単なクラスを作っておきました。ABC,abstractmethodなどを使ってrepository_interfaceも合わせて作っておくと他のベクトル検索エンジン使うとなったときでも変えやすく、実装としてはより良いかもしれません。
from typing import List
from opensearchpy import OpenSearch
class VectorSearchClient:
def __init__(self):
# OpenSearchクライアントの初期化
self.client = OpenSearch(
hosts=[{'host': 'localhost', 'port': 9200}] # OpenSearchサーバーの設定
)
self.index_name = "my_vector" # 検索するインデックス名
def create_index(self):
"""インデックスを作成する関数。"""
body = {
"settings": {
"index": {
"knn": True,
}
},
"mappings": {
"properties": {
"content_vec": {
"type": "knn_vector",
"dimension": 1536, # ベクトルの次元数
"method": {
"name": "hnsw",
"space_type": "innerproduct",
"engine": "faiss",
"parameters": {
"ef_construction": 512,
"m": 40,
},
},
},
}
},
}
# インデックスの作成
self.client.indices.create(index=self.index_name, body=body)
def add_document(self, doc_id: str, document: Dict):
"""インデックスにドキュメントを追加する関数。"""
self.client.index(index=self.index_name, id=doc_id, body=document)
def remove_document(self, doc_id: str):
"""インデックスからドキュメントを削除する関数。"""
self.client.delete(index=self.index_name, id=doc_id)
def similarity_search(self, query_vec: List[float], k: int):
"""ベクトルの類似性に基づいてドキュメントを検索する関数。"""
try:
# 検索クエリの本体を定義
body = {
"query": {
"knn": {
"content_vec": { # ここで検索に使用するベクトルを指定
"vector": query_vec,
"k": k # 返すドキュメントの数
}
}
},
"size": k # 返されるドキュメントの最大数を指定
}
# OpenSearchに対して検索を実行
res = self.client.search(index=self.index_name, body=body)
hits = res["hits"]["hits"] # 検索結果を取得
# 検索結果から必要な情報を抽出
results = [
{
"document_id": hit["_id"], # ドキュメントのID
"content": hit["_source"]["content"], # ドキュメントの内容
"score": hit["_score"] # 類似性スコア
}
for hit in hits
]
return results
except Exception as err:
# エラーが発生した場合の処理
print(f"類似性検索の実行に失敗しました: {err}")
return []
# 使用例
client = VectorSearchClient()
query_vector = [0.5, -0.1, 0.3, ...] # 例としてのクエリベクトル
top_k_results = client.similarity_search(query_vector, 10) # トップkの結果を取得
# ドキュメントの追加
doc_id = "1"
document = {"content_vec": [0.5, -0.1, 0.3, ...]} # 例としてのドキュメント
client.add_document(doc_id, document)
# ドキュメントの削除
client.remove_document(doc_id)
add_documentでは検索データのembeddingsを入れてください。similarity_searchではクエリのembeddingsを入れます。ただし、ユーザーが入力したクエリをそのままembeddingするのではなく、一旦LLMなどでクエリから適切なクエリに変換してからembeddingをする手法もあるようです。例えば、この質問文に答えるための適切な検索クエリを考えて、とLLMに推論させてその結果をembeddingしてベクトル検索する、など。最終的にはこのクラスを使って関連するテキストデータなどが得られます。これをクエリと共にLLMに投げることでRAGが実現できます。
余談ですが、LLMで適切なクエリに変換してからそのまま全文検索のようなものに投げても曖昧検索のようなことが実現出来ると思います。無理に埋め込み表現にしてベクトル検索する必要はないかもしれません(この場合でもLLMがベクトル検索の役割を担っている、と解釈することもできる(LLMの内部ではembedding表現に変換されているため)と思いますが)
LLMでの応答生成
クエリと関連データを大規模言語モデル(LLM)にどのように提示すれば最も効果的かという問題に関して、明確な理論的根拠は現在のところ少ないです。言語モデルがどのように文脈内学習を行っているのかについては、まだ完全には理解されていません。ただし、研究によれば、モデルのパラメータ数が多いほど、文脈内の情報を理解し活用している傾向にあることが示されています[2]。現状では、経験則やデータセットに基づく評価が主な方法であり、特定のアプローチが絶対に効果的とは断言できないです。なので、具体例として、ChatBotフレームワークとして主流のLangChainで使われているプロンプトの構成を日本語に置き換えたものをここでは示しておきます。
システムプロンプト部分:
以下のコンテキストを使用してユーザーの質問に答えてください。
わからないことがあれば、それを明確に述べてください。
また、質問と直接関係がない場合は、「わからない」と答えてください。
コンテキストを抜粋・引用して簡潔に、かつ段階的に考えて答えを生成してください。
あなたの答えはコンテキストと質問に基づいていることを確認してください。
回答に不足がないようにしてください。
----------------
{{ベクトル検索で持ってきた関連データ}}
ユーザーの質問部分:
質問内容
上記のものをOpenAIのCompletionAPIに投げればRAGを実現できます。
最後に
この記事を通じて、RAG(Retrieval-Augmented Generation)を用いたチャットボットの基本的な構築と実装についての理解の助けができていれば幸いです。表面上は直感的で簡単に見えるRAGの実装ですが、経験則やテストデータセットなどで性能を評価したり、微調整に微調整を重ねる場面が多いなど実際にはかなり泥臭い部分が多いです。そもそも学術的にもLLMの文脈内学習は未解明の部分が多い分野です。これからどんどん知見が溜まっていずれベストなやり方が固定化していくでしょうが、色々いい形を模索していきたいですね!
参考文献
[1]Joshua Maynez, Shashi Narayan, Bernd Bohnet, Ryan McDonald. On Faithfulness and Factuality in Abstractive Summarization. https://arxiv.org/abs/2005.00661
[2]Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, Tengyu Ma. Larger language models do in-context learning differently. https://arxiv.org/abs/2303.03846