はじめに

Salesforce の Apex には、1トランザクションあたり 10,000ミリ秒(非同期は60,000ミリ秒) という CPU タイムリミットが設定されています。このリミットを超えると System.LimitException: Apex CPU time limit exceeded が発生し、処理が強制終了されます。
大量データの処理やループ内での複雑なロジックを扱うとき、気づかないうちに CPU 消費が膨れ上がることがあります。本記事では、CPU タイムリミットを超えないための コード設計パターン を体系的に紹介します。
CPU タイムを消費する主な原因
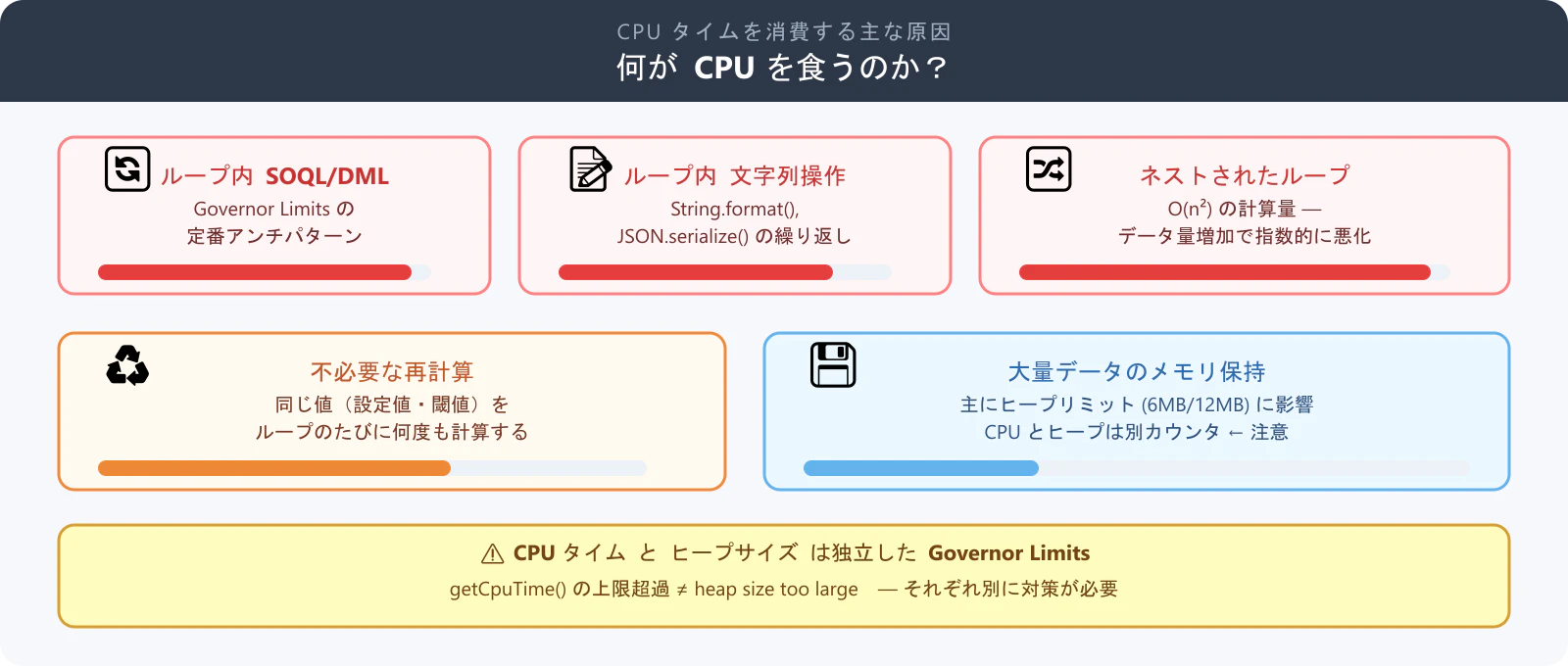
まず、何が CPU を食うのかを把握しておきましょう。
| 原因 | 説明 |
|---|---|
| ループ内 SOQL / DML | Governor Limits の定番アンチパターン |
| ループ内の重い文字列操作 |
String.format()、JSON.serialize() の繰り返し |
| ネストされたループ | O(n²) の計算量 |
| 不必要な再計算 | 同じ値を何度も計算する |
| 大量データのメモリ保持 | Map/List の肥大化(主にヒープリミットに影響。CPU とヒープは別カウンタであることに注意) |
補足 — CPU とヒープは別リミット:
System.LimitException: Apex CPU time limit exceededとApex heap size too largeは別の Governor Limits です。Map/List の肥大化は主にヒープ(同期: 6MB、非同期: 12MB)を圧迫しますが、大量オブジェクトのアロケーション・GC 処理が CPU に間接的に影響することもあります。設計時は両方を意識しましょう。
パターン 1: SOQL / DML をループの外に出す(Bulkify)
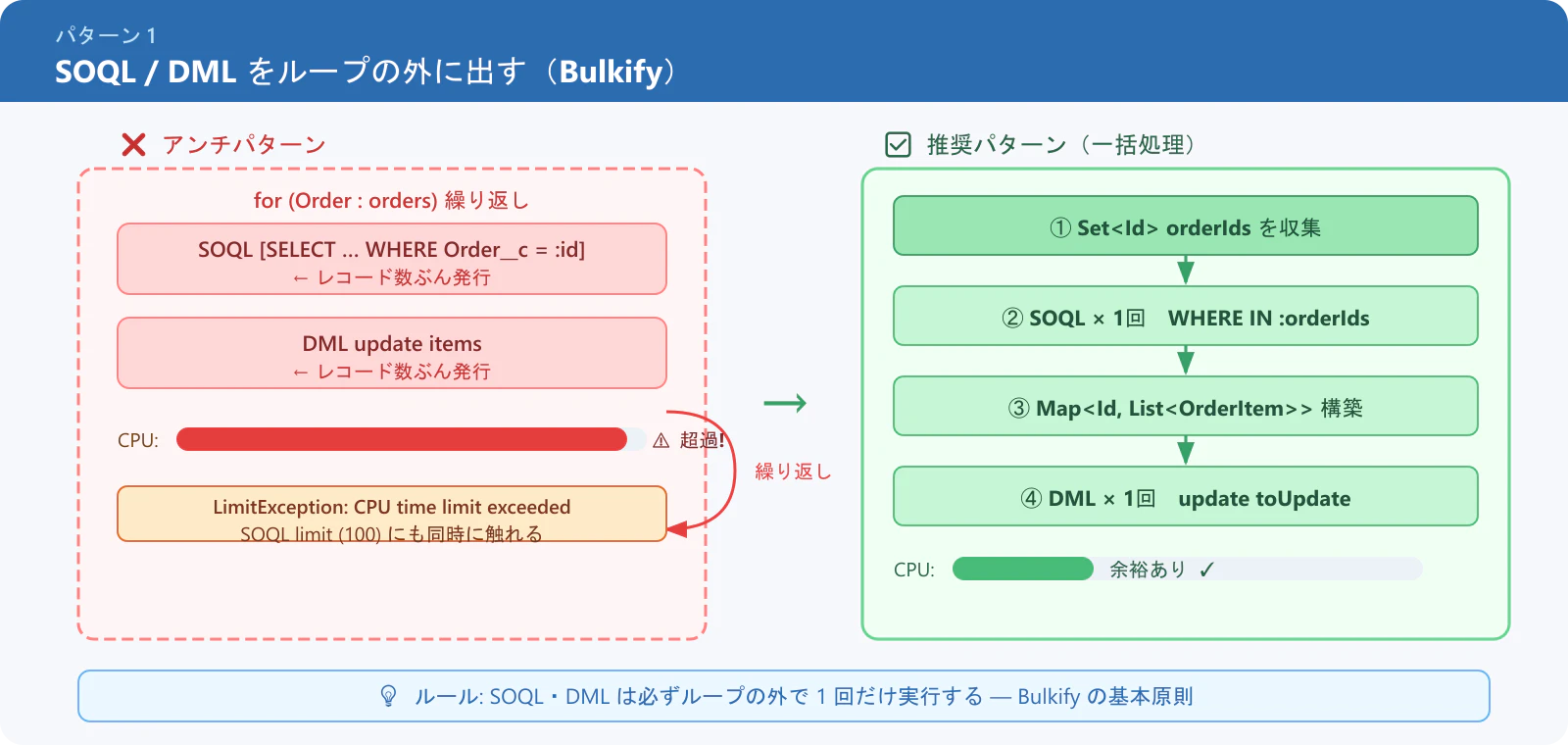
❌ アンチパターン
for (Order__c order : orders) {
// ループ内 SOQL → CPU・SOQL 両方の浪費
List<OrderItem__c> items = [
SELECT Id, Price__c FROM OrderItem__c WHERE Order__c = :order.Id
];
// ループ内 DML
update items;
}
✅ 推奨パターン
// 先に必要な Id を集める
Set<Id> orderIds = new Map<Id, Order__c>(orders).keySet();
// SOQL は 1 回だけ
Map<Id, List<OrderItem__c>> itemsByOrder = new Map<Id, List<OrderItem__c>>();
for (OrderItem__c item : [
SELECT Id, Price__c, Order__c FROM OrderItem__c WHERE Order__c IN :orderIds
]) {
if (!itemsByOrder.containsKey(item.Order__c)) {
itemsByOrder.put(item.Order__c, new List<OrderItem__c>());
}
itemsByOrder.get(item.Order__c).add(item);
}
// DML は 1 回にまとめる
List<OrderItem__c> toUpdate = new List<OrderItem__c>();
for (Order__c order : orders) {
if (itemsByOrder.containsKey(order.Id)) {
for (OrderItem__c item : itemsByOrder.get(order.Id)) {
item.Price__c = calcPrice(item);
toUpdate.add(item);
}
}
}
update toUpdate;
パターン 2: Map を活用してネストループを排除する
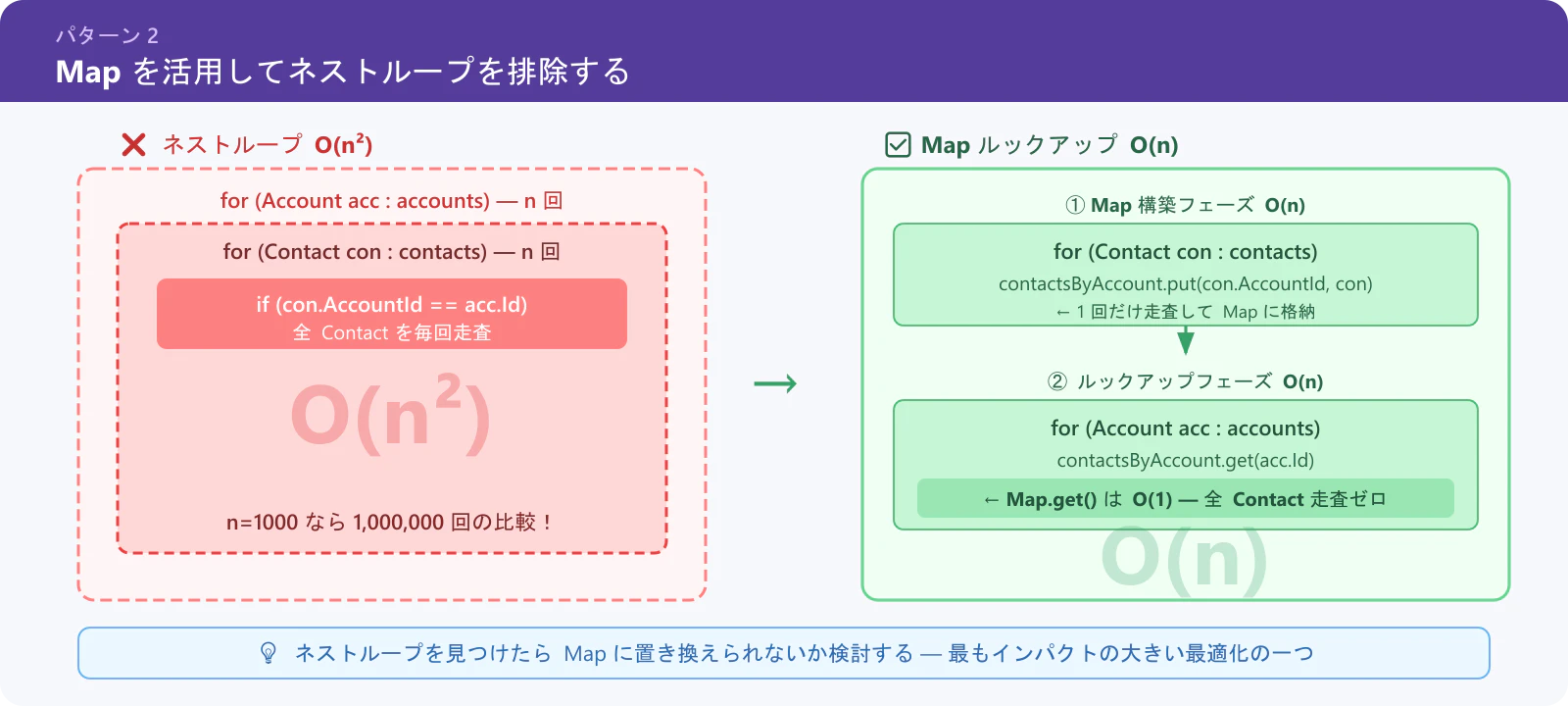
O(n²) のネストループは CPU の天敵です。Map によるルックアップで O(n) に落としましょう。
❌ アンチパターン(O(n²))
for (Account acc : accounts) {
for (Contact con : contacts) {
if (con.AccountId == acc.Id) {
// 処理
}
}
}
✅ 推奨パターン(O(n))
// Contact を AccountId でグループ化
Map<Id, List<Contact>> contactsByAccount = new Map<Id, List<Contact>>();
for (Contact con : contacts) {
if (!contactsByAccount.containsKey(con.AccountId)) {
contactsByAccount.put(con.AccountId, new List<Contact>());
}
contactsByAccount.get(con.AccountId).add(con);
}
// Account のループは 1 回だけ
for (Account acc : accounts) {
List<Contact> related = contactsByAccount.get(acc.Id);
if (related != null) {
// 処理
}
}
パターン 3: 計算結果をキャッシュする
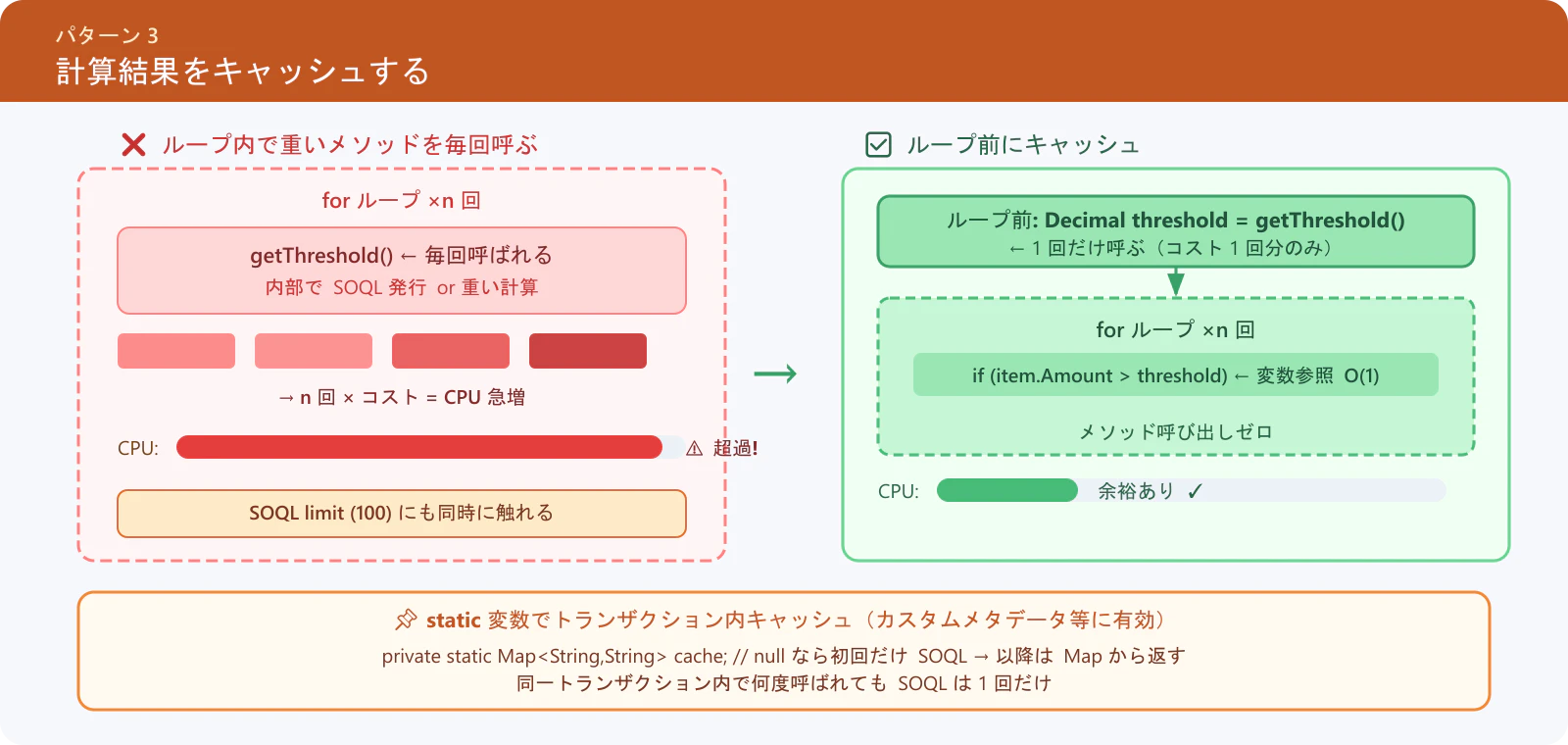
同じ計算を何度も繰り返すのは CPU の無駄遣いです。結果を変数や Map に保持しましょう。
ポイント:
List.size()自体は軽量な操作なので、それ単体のキャッシュによる効果は限定的です。本パターンで本当に重要なのは、SOQL を内部で発行するメソッドや複雑な計算処理など、コストの高いメソッド呼び出しをループ外にキャッシュすることです。
❌ アンチパターン
for (Integer i = 0; i < items.size(); i++) {
// getThreshold() が SOQL や重い計算を含む場合、毎回呼ぶと致命的
if (items[i].Amount__c > getThreshold()) {
// 処理
}
}
✅ 推奨パターン
// 重いメソッドの結果をループ前にキャッシュする(これが本質)
Decimal threshold = getThreshold();
Integer itemCount = items.size(); // size() 自体は軽量だが、意図を明示する意味でキャッシュしても良い
for (Integer i = 0; i < itemCount; i++) {
if (items[i].Amount__c > threshold) {
// 処理
}
}
カスタムメタデータ・設定値のキャッシュ
public class ConfigCache {
// static 変数でトランザクション内キャッシュ
private static Map<String, String> cache;
public static String get(String key) {
if (cache == null) {
cache = new Map<String, String>();
for (App_Config__mdt cfg : [SELECT Key__c, Value__c FROM App_Config__mdt]) {
cache.put(cfg.Key__c, cfg.Value__c);
}
}
return cache.get(key);
}
}
パターン 4: 文字列操作は String.join() / List を使う
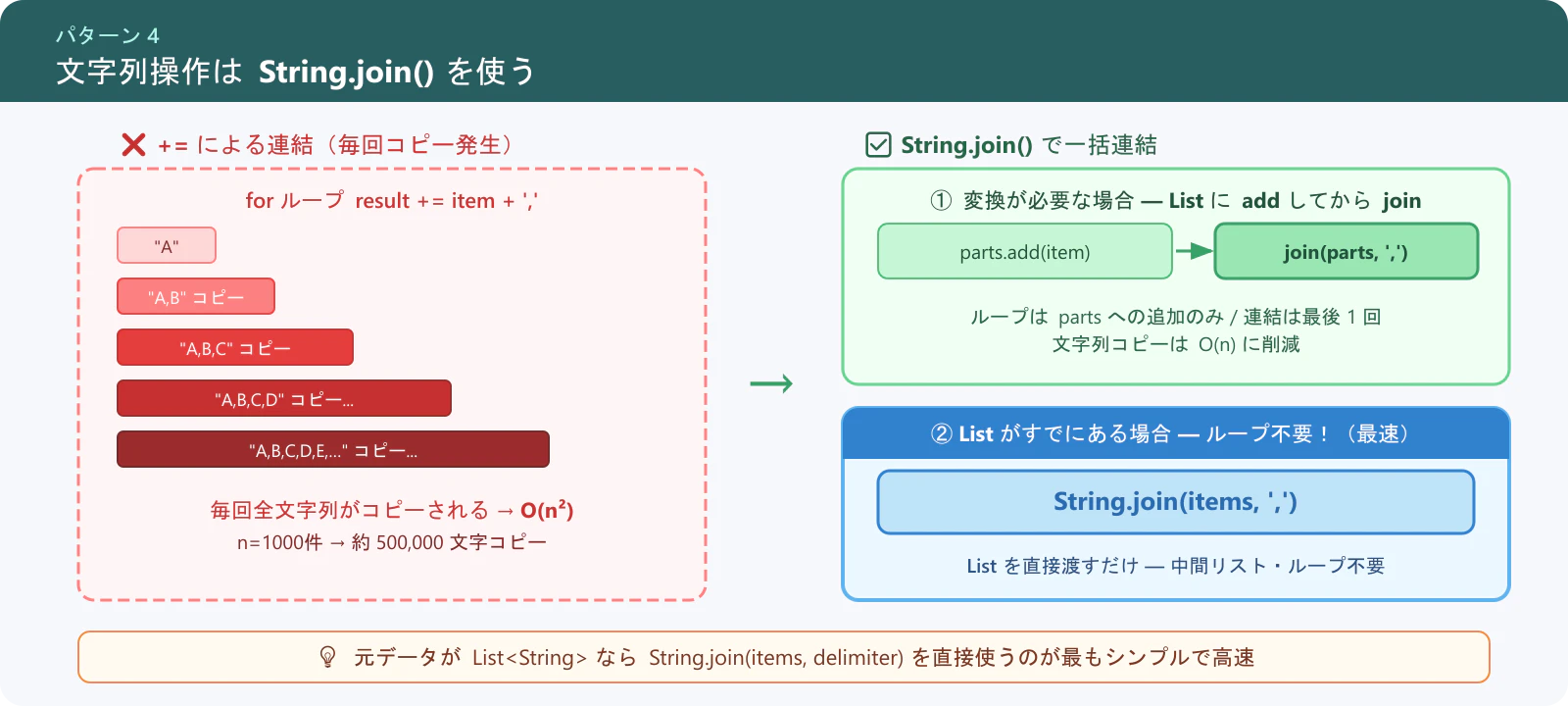
String の += による連結はループ内で使うと、文字列のコピーが毎回発生して CPU を消費します。
❌ アンチパターン
String result = '';
for (String item : items) {
result += item + ','; // 毎回コピーが発生
}
✅ 推奨パターン
List<String> parts = new List<String>();
for (String item : items) {
parts.add(item);
}
String result = String.join(parts, ','); // 最後に 1 回だけ連結
✅ さらにシンプルなパターン(既に List がある場合)
最初から List<String> が手元にある場合は、中間リストへの詰め替えループ自体が不要です。
// items が List<String> であれば直接渡せる
String result = String.join(items, ',');
ポイント:
String.join()は第1引数にList<String>を直接受け取れます。ループで別リストに詰め替えてから渡すのは冗長なので、元データがすでにList<String>であればこの形が最もシンプルで高速です。
パターン 5: 処理を Batch Apex で分割する
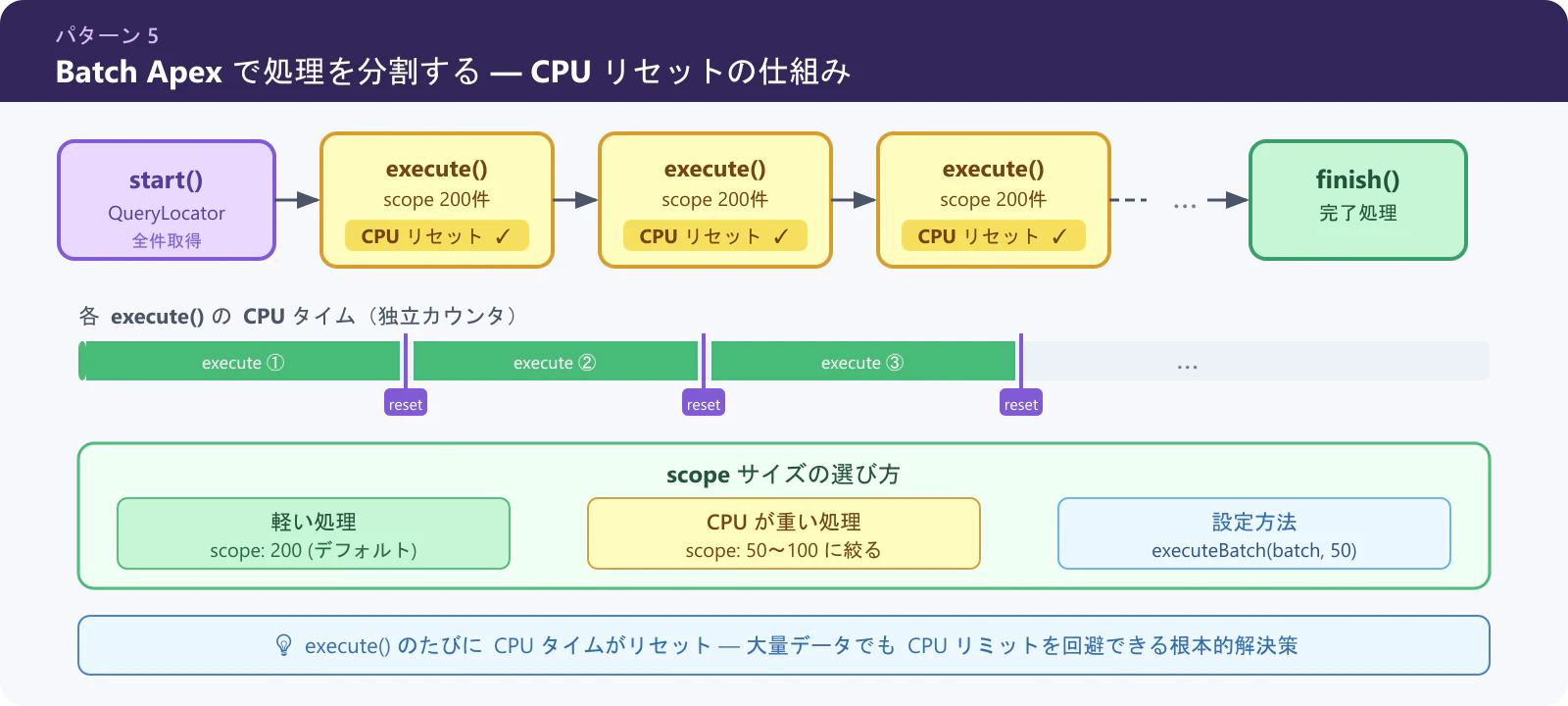
大量データを一括処理する場合は Database.Batchable を使い、チャンク単位に分割して CPU リミットをリセットします。
public class OrderBatch implements Database.Batchable<SObject> {
public Database.QueryLocator start(Database.BatchableContext bc) {
return Database.getQueryLocator([
SELECT Id, Status__c FROM Order__c WHERE Status__c = 'Pending'
]);
}
public void execute(Database.BatchableContext bc, List<Order__c> scope) {
// ここは scope のサイズ(デフォルト 200 件)ごとに CPU がリセットされる
List<Order__c> toUpdate = new List<Order__c>();
for (Order__c o : scope) {
o.Status__c = 'Processed';
toUpdate.add(o);
}
update toUpdate;
}
public void finish(Database.BatchableContext bc) {}
}
ポイント:
execute()のscopeサイズはDatabase.executeBatch(new OrderBatch(), 50)のように第2引数で調整できます。CPU の重い処理なら小さい値に設定しましょう。
パターン 6: Queueable / Future で非同期化する
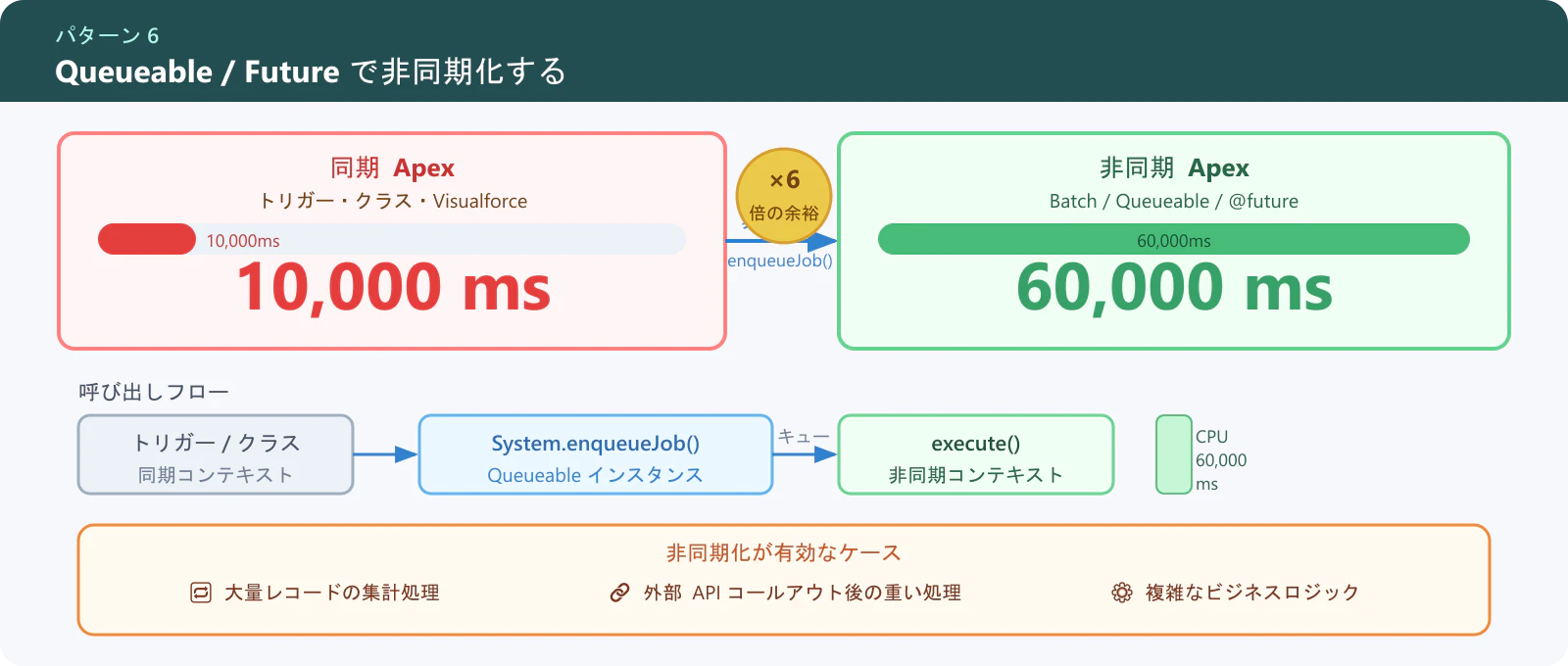
同期 Apex のリミット(10,000ms)に対し、非同期 Apex は 60,000ms まで使えます。重い処理は非同期に逃がしましょう。
public class HeavyProcessQueue implements Queueable {
private List<Id> targetIds;
public HeavyProcessQueue(List<Id> ids) {
this.targetIds = ids;
}
public void execute(QueueableContext ctx) {
// 非同期なので CPU リミットが 60,000ms
List<Account> accounts = [SELECT Id, Name FROM Account WHERE Id IN :targetIds];
// 重い処理...
}
}
// 呼び出し側
System.enqueueJob(new HeavyProcessQueue(accountIds));
パターン 7: Limits クラスで残 CPU を監視する
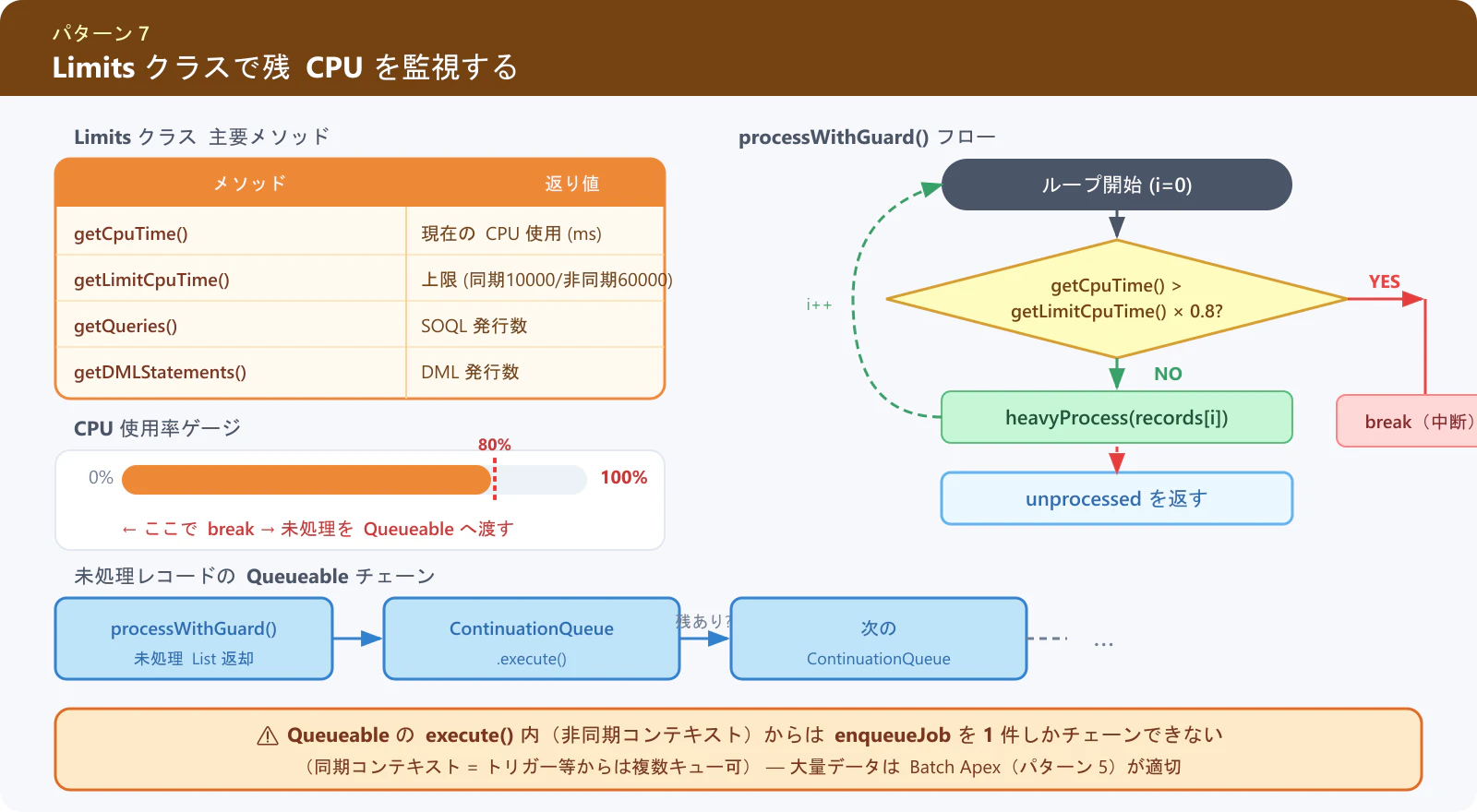
処理の途中で CPU 残量をチェックし、リミットに近づいたら早期リターンするパターンです。break した際の未処理レコードは、Queueable に渡して後続処理に引き継ぐことが重要です。
public static List<SObject> processWithGuard(List<SObject> records) {
Integer i = 0;
Integer total = records.size(); // size() をキャッシュ(パターン 3 と同じ考え方)
for (; i < total; i++) {
// CPU が 80% を超えたら中断(indexOf を使わずインデックスで残件数を計算)
if (Limits.getCpuTime() > Limits.getLimitCpuTime() * 0.8) {
System.debug('CPU 警告: ' + Limits.getCpuTime() + 'ms 使用済み。残り ' + (total - i) + ' 件を後続処理へ。');
break;
}
heavyProcess(records[i]);
}
// i 以降がすべて未処理
List<SObject> unprocessed = new List<SObject>();
for (; i < total; i++) {
unprocessed.add(records[i]);
}
return unprocessed;
}
未処理レコードが残った場合は Queueable で後続に引き継ぎます。
public class ContinuationQueue implements Queueable {
private List<Id> remainingIds;
public ContinuationQueue(List<Id> ids) {
this.remainingIds = ids;
}
public void execute(QueueableContext ctx) {
List<SObject> records = [SELECT Id FROM MyObject__c WHERE Id IN :remainingIds];
List<SObject> unprocessed = MyProcessor.processWithGuard(records);
// さらに未処理が残れば次の Queueable をチェーン
if (!unprocessed.isEmpty()) {
List<Id> nextIds = new List<Id>();
for (SObject r : unprocessed) nextIds.add(r.Id);
System.enqueueJob(new ContinuationQueue(nextIds));
}
}
}
注意: Queueable の
execute()内(非同期コンテキスト)からはenqueueJobを 1 件しかチェーンできません。このコード例はまさにその制限が適用される構造です。一方、トリガーや同期 Apex からは複数の Queueable をキューに積むことができます。大量データを確実に処理したい場合は Batch Apex(パターン 5)の方が適しています。
補足: 本コードはガードパターンの考え方を示す概念サンプルです。実際の実装では、具体的なオブジェクト型および取得フィールドを要件に合わせて調整してください。
Limits クラスの主なメソッド:
| メソッド | 説明 |
|---|---|
Limits.getCpuTime() |
現在の CPU 使用時間(ms) |
Limits.getLimitCpuTime() |
上限値(同期: 10000、非同期: 60000) |
Limits.getQueries() |
SOQL クエリ発行数 |
Limits.getDMLStatements() |
DML 発行数 |
パターン 8: JSON 処理のコストを理解し設計を見直す
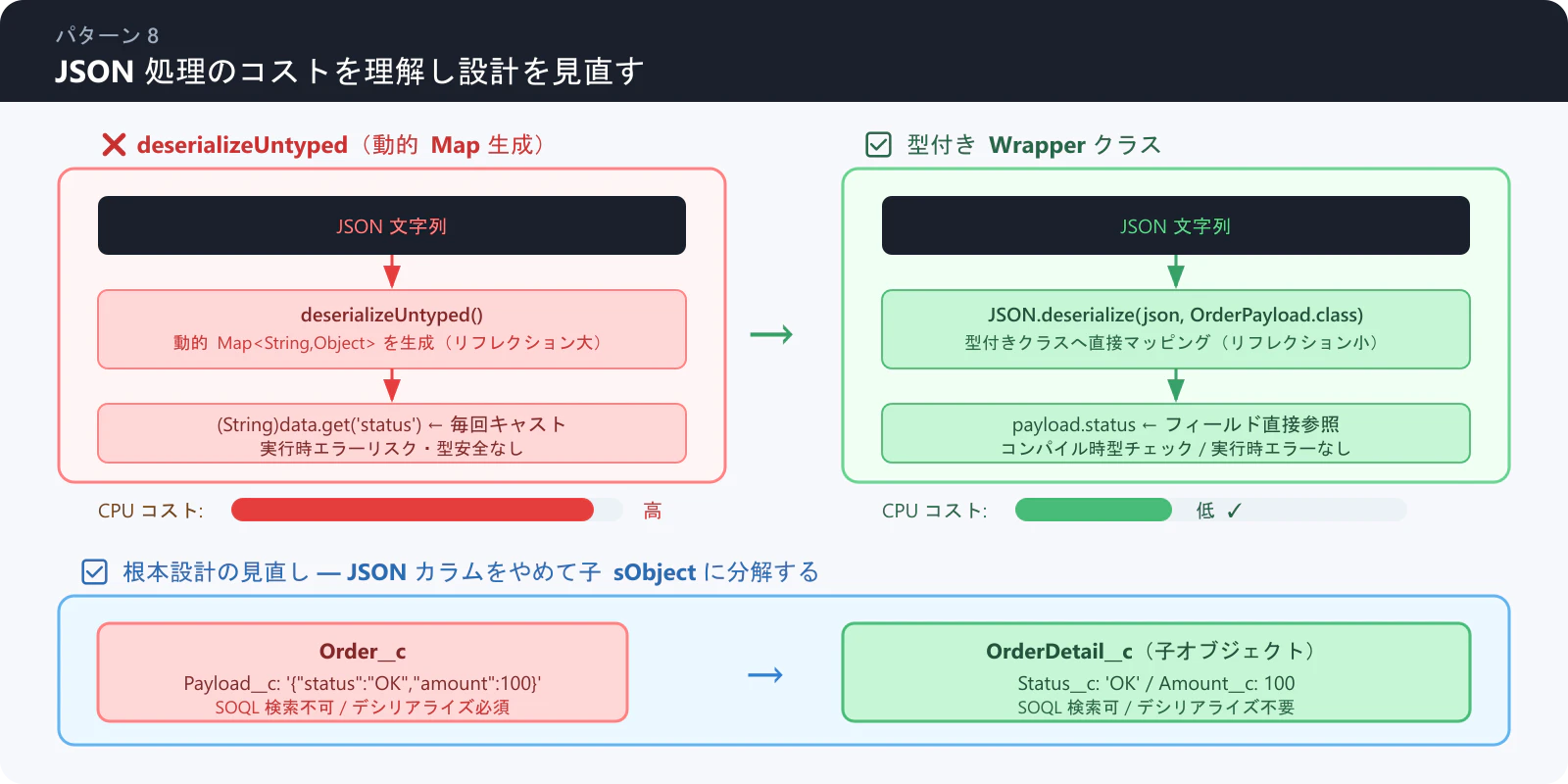
JSON.serialize() / JSON.deserialize() は CPU を比較的多く消費します。特に deserializeUntyped は動的な Map 生成を伴うため、型付きクラスによる直接マッピングより一般的にコストが高くなります。
ただし、ループ内での JSON デシリアライズ自体は、レコードごとに異なる Payload を持つ構造では避けられない場合があります。 重要なのは「どの方法を使うか」と「そもそも JSON で持つ必要があるか」を見直すことです。
❌ アンチパターン: deserializeUntyped をループ内で使う
for (Order__c o : orders) {
// deserializeUntyped は動的 Map を生成するため型付きより低速
Map<String, Object> data = (Map<String, Object>) JSON.deserializeUntyped(o.Payload__c);
String status = (String) data.get('status');
Decimal amount = (Decimal) data.get('amount');
// 処理
}
✅ 改善案 1: 型付き Wrapper クラスを使う
public class OrderPayload {
public String status;
public Decimal amount;
}
for (Order__c o : orders) {
// 型付きクラスは内部でリフレクションコストが抑えられ、コードも安全
OrderPayload payload = (OrderPayload) JSON.deserialize(o.Payload__c, OrderPayload.class);
// payload.status, payload.amount を直接利用
}
✅ 改善案 2: そもそも JSON カラムを使わない設計を検討する
JSON を 1 カラムに詰め込む設計は CPU コストだけでなく、SOQL での検索不可・スキーマ管理の困難さも招きます。データ構造が固定であれば 専用の子オブジェクトや個別項目に分解することが根本的な解決策です。
❌ Order__c.Payload__c (JSON文字列) → ✅ OrderDetail__c (子オブジェクト) に分解
まとめ: JSON 処理が必要な場合は
deserializeUntypedを避けて型付きクラスを使い、設計段階では JSON カラムに頼らない構造も検討しましょう。
まとめ: チェックリスト

設計・レビュー時にこの観点で確認しましょう。
- ループの中に SOQL・DML がないか
- ネストループを Map で置き換えられないか
- 繰り返し計算している値を変数にキャッシュしているか
-
文字列連結に
+=を使っていないか(String.join()を使う) - 大量データは Batch Apex で分割しているか
- 重い処理は Queueable / Future で非同期化しているか
-
Limits.getCpuTime()でリミット監視を入れているか -
固定スキーマの JSON に
deserializeUntypedを使っていないか(型付き Wrapper クラスを使う) - JSON カラムを子オブジェクト・個別項目に分解できないか検討したか
おわりに
CPU タイムリミットの問題は、単発のテストデータでは気づきにくく、本番の大量データで突然発生することが多いです。「最初から Bulkify を意識した設計」と「Limits クラスによる監視」を組み合わせることで、スケーラブルな Apex コードが書けるようになります。
参考リンク
本記事を執筆するにあたり、以下の公式ドキュメント・学習リソースを参照しました。
設計パターンをより深く理解したい方はあわせてご覧ください。
| # | タイトル | 内容 |
|---|---|---|
| 1 | Execution Governors and Limits — Apex Developer Guide | CPU タイム・ヒープ・SOQL・DML など全 Governor Limits の公式一覧。本記事で引用したすべての数値の一次ソース |
| 2 | Batch Apex — Trailhead |
Database.Batchable の構文・スコープサイズ・Database.Stateful によるステート管理・テスト手法を網羅したハンズオン教材 |
| 3 | Queueable Apex — Apex Developer Guide |
System.enqueueJob のチェーン制限・スタック深度制御(AsyncOptions)など、パターン 6・7 の根拠となる仕様の公式ドキュメント |