はじめに
「チャットボットに質問する」から「記憶を持ち、複雑なデータ構造を読み解き、他のAIと連携する自律エージェントを構築する」へ——この流れの中で、今回はエージェントを支える「インフラストラクチャ(基盤)」側にフォーカスします。
本記事では、Google Cloud Tech の動画 「Hands-on AI workshop: Graph RAG, Memory & Multimodal Agents」 の内容をもとに、高度なAIエージェントを支える 4つの設計要素 を整理します。
本記事は概要把握を目的とした個人的なメモです。
内容に興味を持たれた場合は、正確な情報について公式動画・ドキュメントをご確認ください。
本動画は、2026年3月10日に配信された 「Google Cloud Live: Hands-on AI workshop: Multimodal agents」 の続編(Phase 2)として位置づけられています。Phase 1 では画像や動画を処理するマルチモーダルエージェントの基礎構築が行われ、Phase 2 ではそのエージェントが大規模かつ複雑な問題に対処するためのインフラ構築に焦点を当てています。Google Cloud Shell を使ったセットアップから丁寧に進められるため、Phase 1 を視聴していなくても単体で学習可能です。
補足: 筆者の前回のQiita記事は別の動画(「Build a Multi-Agent System with ADK, MCP, and Gemini」)を基にしたものであり、本動画シリーズとは別のコンテンツです。ただし、ADK・MCP・A2A などの共通技術を扱っており、テーマとして補完的な関係にあります。
登場する主要技術は以下の4つです。
| 技術 | 役割 |
|---|---|
| Cloud Spanner Graph | マルチモデルデータベース。グラフ・リレーショナル・検索・AI機能を統合し、データ間の関係性をネットワーク構造で保存・検索する |
| Graph RAG | グラフ構造を活用した検索拡張生成。標準RAGより文脈に沿った高精度な検索を実現 |
| Vertex AI Memory Bank | AIエージェントに長期記憶を持たせる機能。過去の文脈を踏まえた継続的なやり取りを実現 |
| ADK (Agent Development Kit) | マルチエージェントのオーケストレーション。複数エージェントを連携させて複雑なタスクを処理 |
それでは、全体像から見ていきましょう。
1. Cloud Spanner Graph による関係性のマッピング
最初の設計要素は「データ間のつながりをどう表現するか」です。
なぜグラフデータベースなのか?
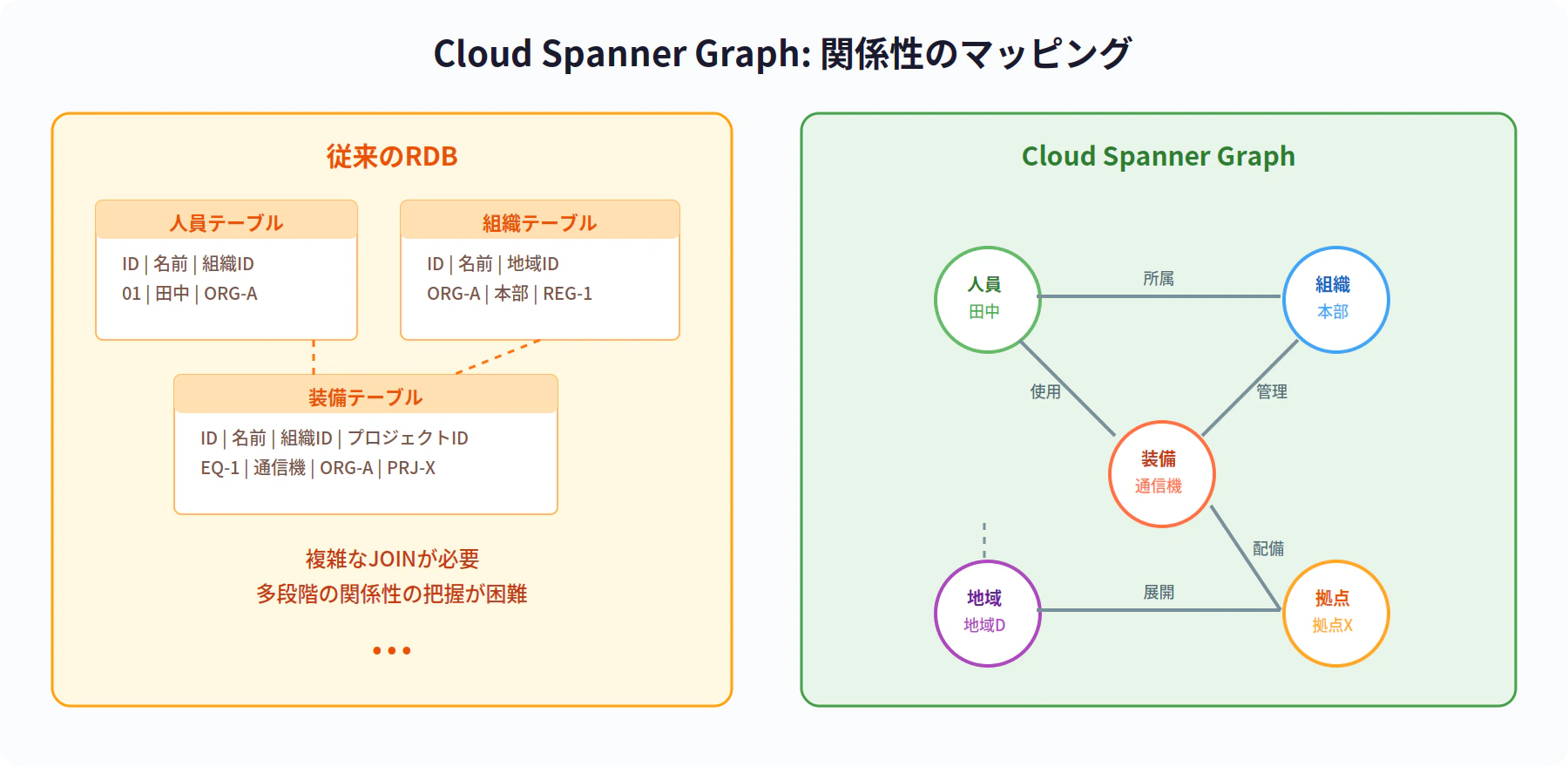
従来のリレーショナルデータベース(RDB)は、行と列のテーブル構造でデータを管理します。しかし、「人物Aは組織Bに所属し、組織Bはプロジェクトcに関与し、プロジェクトCは地域Dで展開されている」といった多段階の関係性を扱うには、複雑なJOINが必要になり、パフォーマンスも低下しがちです。
グラフデータベースでは、データを「ノード(点)とエッジ(線)」で表現します。関係性そのものがデータ構造の一部となるため、複雑なネットワーク状のつながりを直感的かつ高速に検索できます。
Cloud Spanner Graphの特徴
Cloud Spanner は Google Cloud が提供するフルマネージドな分散データベースですが、そのグラフ拡張機能である Cloud Spanner Graph を使うことで、以下のメリットが得られます。
- スケーラビリティ: Spanner の水平スケーリングをそのまま活用可能
- SQLとの互換性: GQL(Graph Query Language)に加え、既存のSQLも併用できる
- マルチモデル統合: グラフ・リレーショナル・全文検索・ベクトル検索を1つのデータベースで扱える
補足: Cloud Spanner Graph は「マルチモデル(multi-model)データベース」であり、「マルチモーダル(multimodal)」とは異なります。「マルチモデル」はグラフ・リレーショナル・検索など複数のデータモデルを統合する意味です。動画のワークショップにおいて、画像や動画といったマルチモーダルデータの処理は Gemini(Vertex AI) が担当しており、Gemini が解析・抽出した構造化データ(エンティティや関係性)を Cloud Spanner Graph に格納するという役割分担になっています。
動画では、レスキューネットワークのユースケースとして、人員・装備・拠点間の関係性をグラフで表現する例が示されています。
2. Graph RAG によるハイブリッド検索
データ構造が整ったら、次は「いかに正確な情報を取得するか」です。
標準RAGの限界
RAG(Retrieval-Augmented Generation)は、LLMのハルシネーションを防ぐためにベクトル検索で外部知識を参照する手法として広く知られています。しかし、標準的なRAGにはいくつかの制約があります。
- ベクトル検索のみに依存するため、意味的に類似していても文脈的に無関係な情報を拾いやすい
- データ間の構造的な関係性(AはBの上位組織、BはCを管轄など)を考慮できない
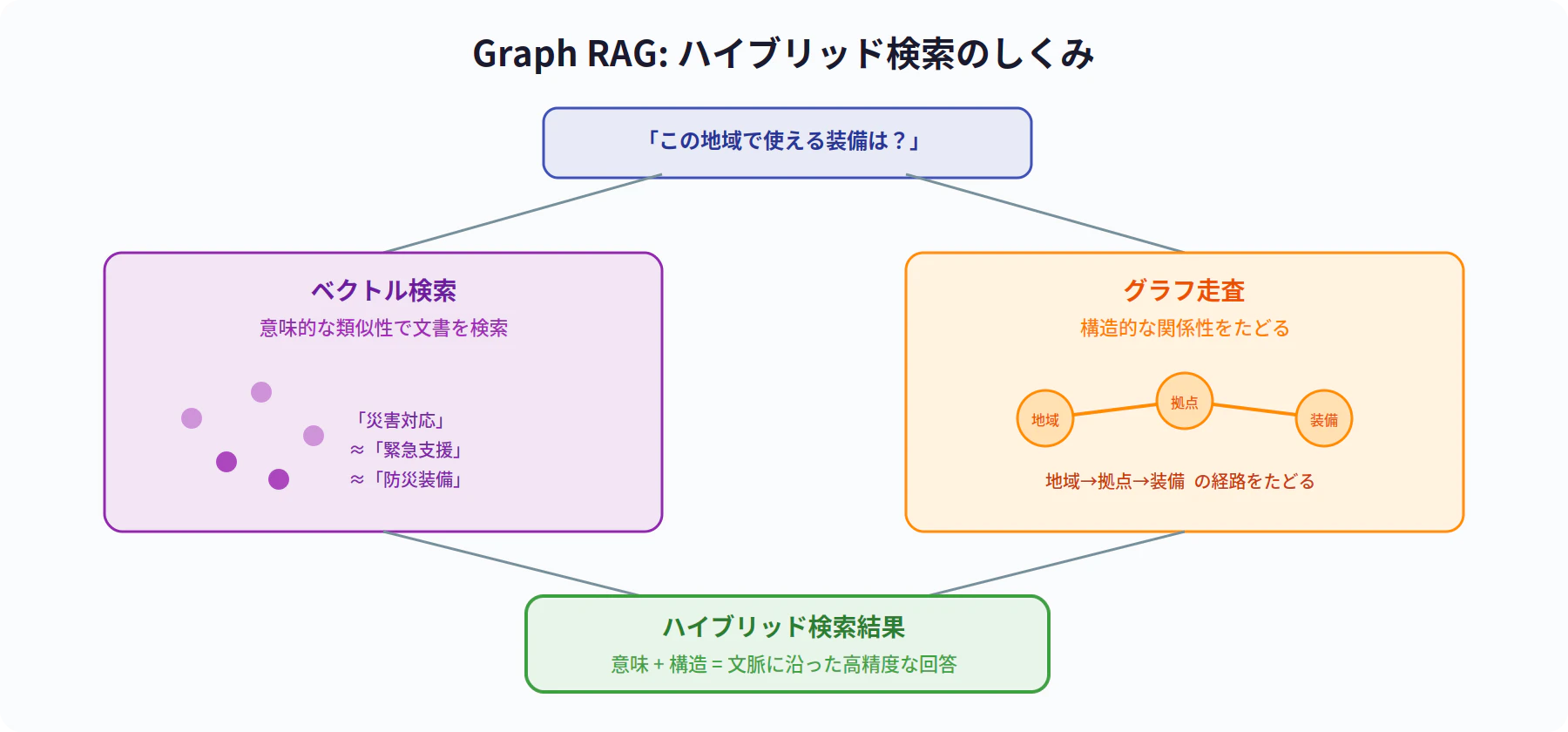
Graph RAGのアプローチ
Graph RAG は、ベクトル検索にグラフ構造の走査を組み合わせたハイブリッド検索です。
| 検索手法 | 得意な点 | 苦手な点 |
|---|---|---|
| ベクトル検索 | 意味的な類似性(「災害対応」≈「緊急支援」) | 構造的な関係性の把握 |
| グラフ走査 | 多段階の関係性(A→B→C→D) | 曖昧な自然言語からの検索 |
| Graph RAG(ハイブリッド) | 両方の強みを統合 | — |
具体的には、「この地域の災害対応に使える装備は?」という質問に対して、ベクトル検索で関連ドキュメントを見つけつつ、グラフ走査で「地域→拠点→装備」の関係性をたどることで、文脈に沿った正確な回答を生成できます。
3. Vertex AI Memory Bank による長期記憶
検索の精度が上がっても、「前回の会話を覚えていない」のでは実用性に限界があります。3つ目の設計要素は「記憶」です。
なぜ記憶が必要か?
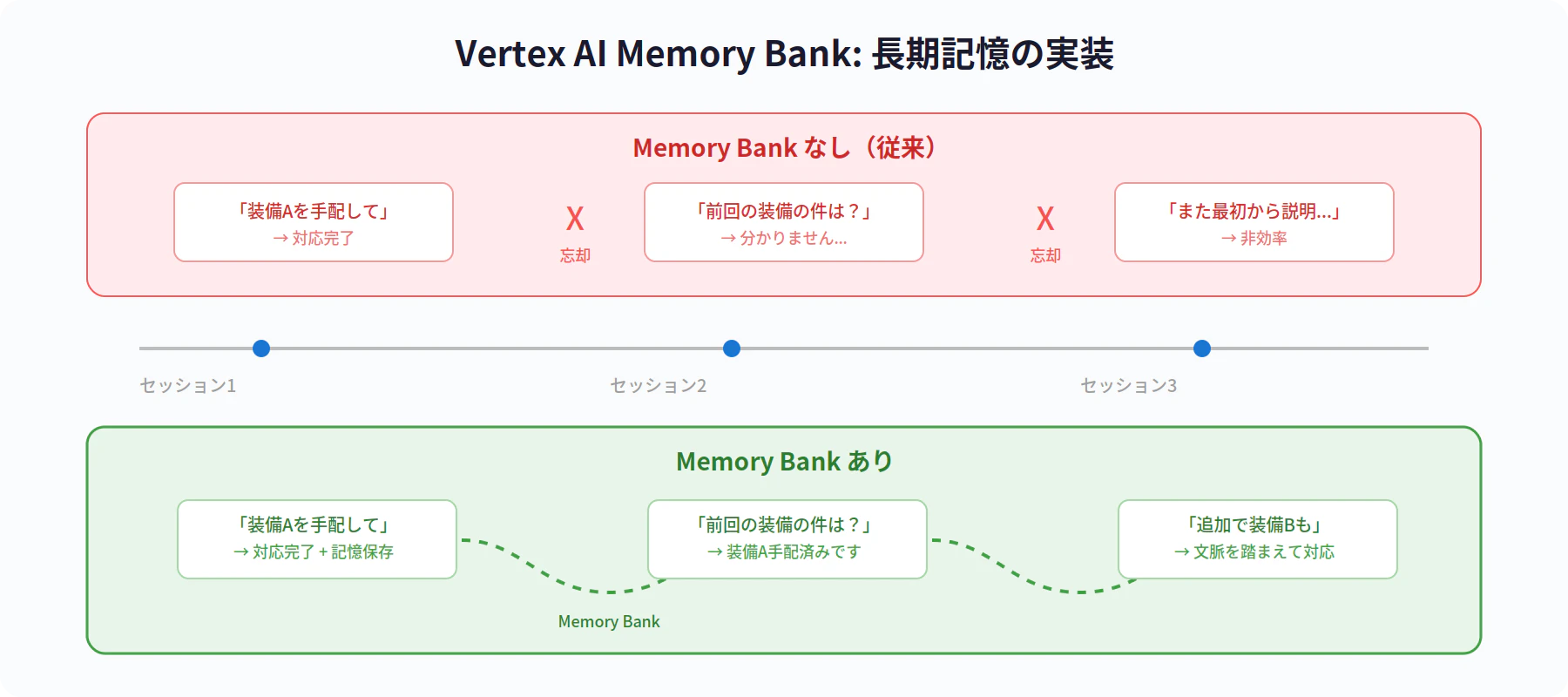
一般的なAIチャットボットは、セッションが終了すると以前のやり取りをすべて忘れます。これでは以下のような場面で不便です。
- 同じ情報を毎回説明し直す必要がある
- 過去の判断の経緯を踏まえた意思決定ができない
- ユーザーごとの好みや文脈に応じたパーソナライズが不可能
Memory Bank の仕組み
Vertex AI の Memory Bank は、エージェントに長期記憶を持たせるための機能です。
補足: Memory Bank は Vertex AI の機能として提供されるもので、単なるチャット履歴の保存とは異なります。会話(セッション)から重要な情報(ファクト)を抽出し、既存の記憶と統合(Memory Consolidation)したうえで、将来の対話で自動的に参照できるようにする仕組みです。
これにより、エージェントは以下のような振る舞いが可能になります。
- 文脈の継続: 「前回の会話で確認したあの条件」を踏まえた応答
- パーソナライゼーション: ユーザーの過去の選好や行動パターンに基づく提案
- ワークフローの連続性: 中断したタスクの再開、進捗の引き継ぎ
ADK のオーケストレーターが持つ「直前にどのエージェントを呼んだか」という短期的な状態が作業記憶だとすれば、Memory Bank は長期記憶に相当します。人間でいえば、作業記憶が「今日のタスクリスト」で、長期記憶が「このクライアントとの過去半年の取引履歴」にあたるイメージです。
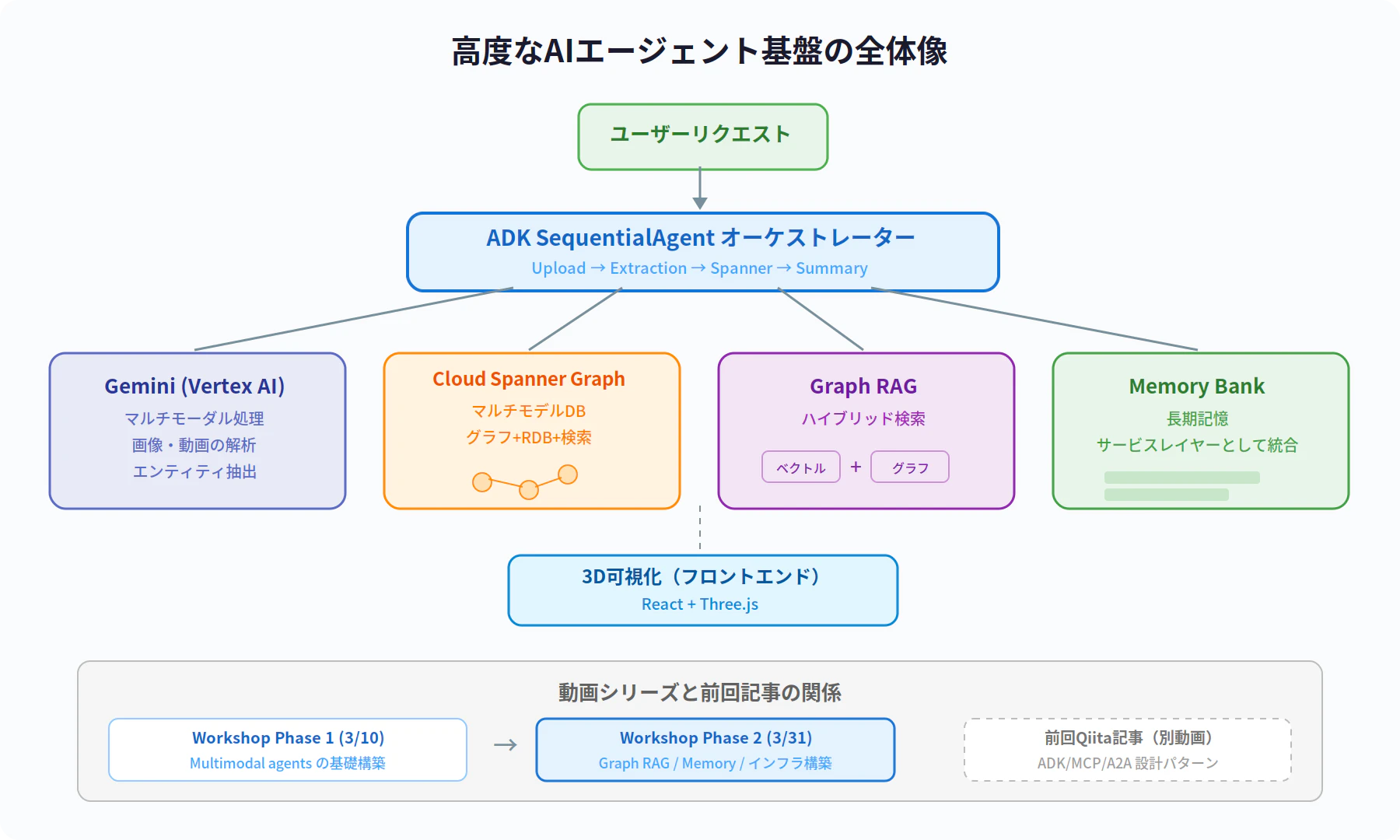
4. ADK によるマルチエージェントオーケストレーション
最後のピースは、これまでの要素を統合して「チームとして動かす」仕組みです。
実際のエージェント構成
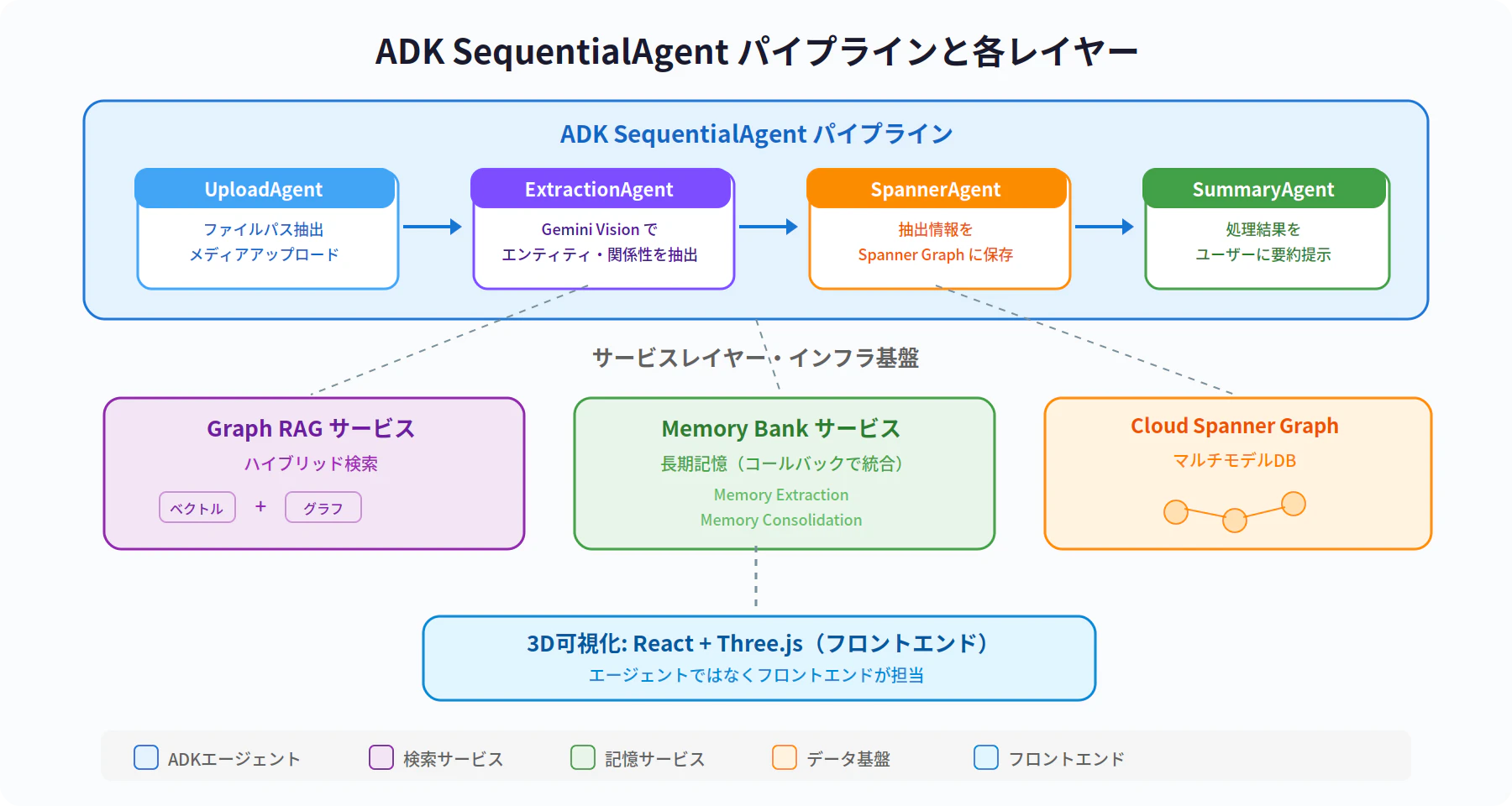
動画および公式 Codelab では、ADK の SequentialAgent を使って以下の4つの専門エージェントを順次実行するパイプラインが実装されています。
| エージェント | 役割 |
|---|---|
| UploadAgent | ユーザーのメッセージからファイルパスを抽出し、メディアをアップロード |
| ExtractionAgent | Gemini Vision を使ってメディアからエンティティと関係性を抽出 |
| SpannerAgent | 抽出した情報を Cloud Spanner Graph に保存 |
| SummaryAgent | 処理結果をユーザーにわかりやすく要約して提示 |
このパイプラインに加えて、Graph RAG サービスがハイブリッド検索を提供し、Memory Bank がサービスレイヤーおよびコールバックとしてエージェントに統合されています。
補足: Memory Bank は独立した「記憶エージェント」として実装されているのではなく、サービスレイヤーとコールバックの仕組みでエージェント群に統合されています。また、3D可視化はエージェントではなくフロントエンド(React + Three.js)が担当しています。
全体のアーキテクチャ
動画のレスキューネットワークのユースケースにおいて、各要素の役割分担は以下のようになっています。
| レイヤー | 担当 | 技術 |
|---|---|---|
| マルチモーダル処理 | メディアの解析・情報抽出 | Gemini(Vertex AI) |
| データ基盤 | 関係性の保存・グラフ検索 | Cloud Spanner Graph |
| 検索 | ハイブリッド検索(ベクトル+グラフ) | Graph RAG |
| 記憶 | 長期記憶の保持・参照 | Vertex AI Memory Bank |
| オーケストレーション | エージェント群の順次実行 | ADK(SequentialAgent) |
| 可視化 | 3Dネットワーク描画 | React + Three.js(フロントエンド) |
まとめ
本記事で紹介した4つの設計要素を改めて整理します。
| # | 設計要素 | 関連技術 | ポイント |
|---|---|---|---|
| 1 | 関係性のマッピング | Cloud Spanner Graph | ノードとエッジで多段階の関係性を表現。マルチモデルDB(グラフ+RDB+検索)を統合 |
| 2 | ハイブリッド検索 | Graph RAG | ベクトル検索 × グラフ走査で文脈に沿った高精度な情報取得 |
| 3 | 長期記憶 | Vertex AI Memory Bank | セッションを超えた文脈の保持とパーソナライゼーション |
| 4 | オーケストレーション | ADK | SequentialAgent による Upload→Extraction→Spanner→Summary のパイプライン |
エージェントの設計パターン(Sequential / Parallel / Loop、MCP によるツール分離、A2A によるサービス化など)については、筆者の前回の記事で別の動画をもとに整理しています。設計パターンとインフラ基盤は補完的な関係にあり、両方が揃ってはじめて実用的なマルチエージェントシステムが成立します。
動画内で提供されている Codelab のリンクを参照しながら、実際に手を動かして体験することをおすすめします。