はじめに
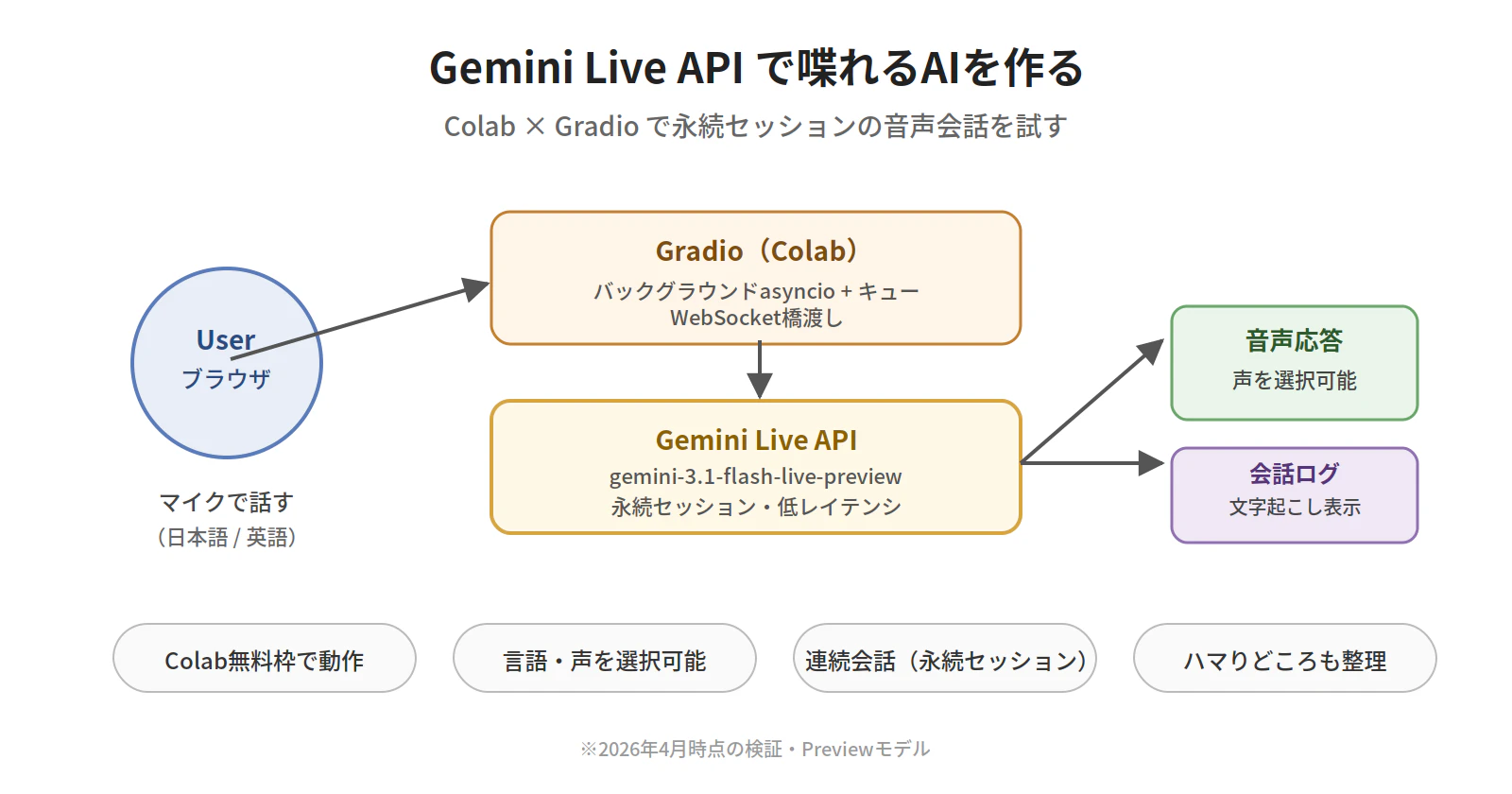
Gemini Live API(Preview)を使って、Colab上で音声会話できるAIを動かしてみた備忘録です。
音声ファイルをアップロードするのではなく、ブラウザのマイクから話しかけて、Geminiの音声で返答してもらう — そんな「喋れるAI」を、Google Colabの無料枠とGradioで試せる範囲でまとめました。
途中でいくつかハマりどころがあったので、同じように試したい方の参考になれば幸いです。
この記事のスコープ
- 対象読者: PythonとColabに触れたことがある方
-
使用モデル:
gemini-3.1-flash-live-preview(Preview・2026年4月時点) - 前提: Google AI StudioのAPIキー(無料枠で動作確認済み)
- 注意: Previewモデルのため、仕様や制限は今後変更される可能性があります。本番運用向けの堅牢性は考慮していません
※本記事は2026年4月時点の個人の整理メモです。
Gemini Live APIとは
従来の音声AIは、STT(音声→テキスト)→ LLM(応答生成)→ TTS(テキスト→音声) の3段階を直列で繋ぐ構成でした。各段階でレイテンシが積み重なり、声色や感情といったニュアンス情報もテキスト化の段階で失われやすくなります。
Gemini Live APIは、Native Audioモデルで音声入出力を1モデルで完結させるアプローチです。WebSocketを使った双方向ストリーミングで、低レイテンシ・割り込み可能(barge-in)・ニュアンス保持といった特性があります。
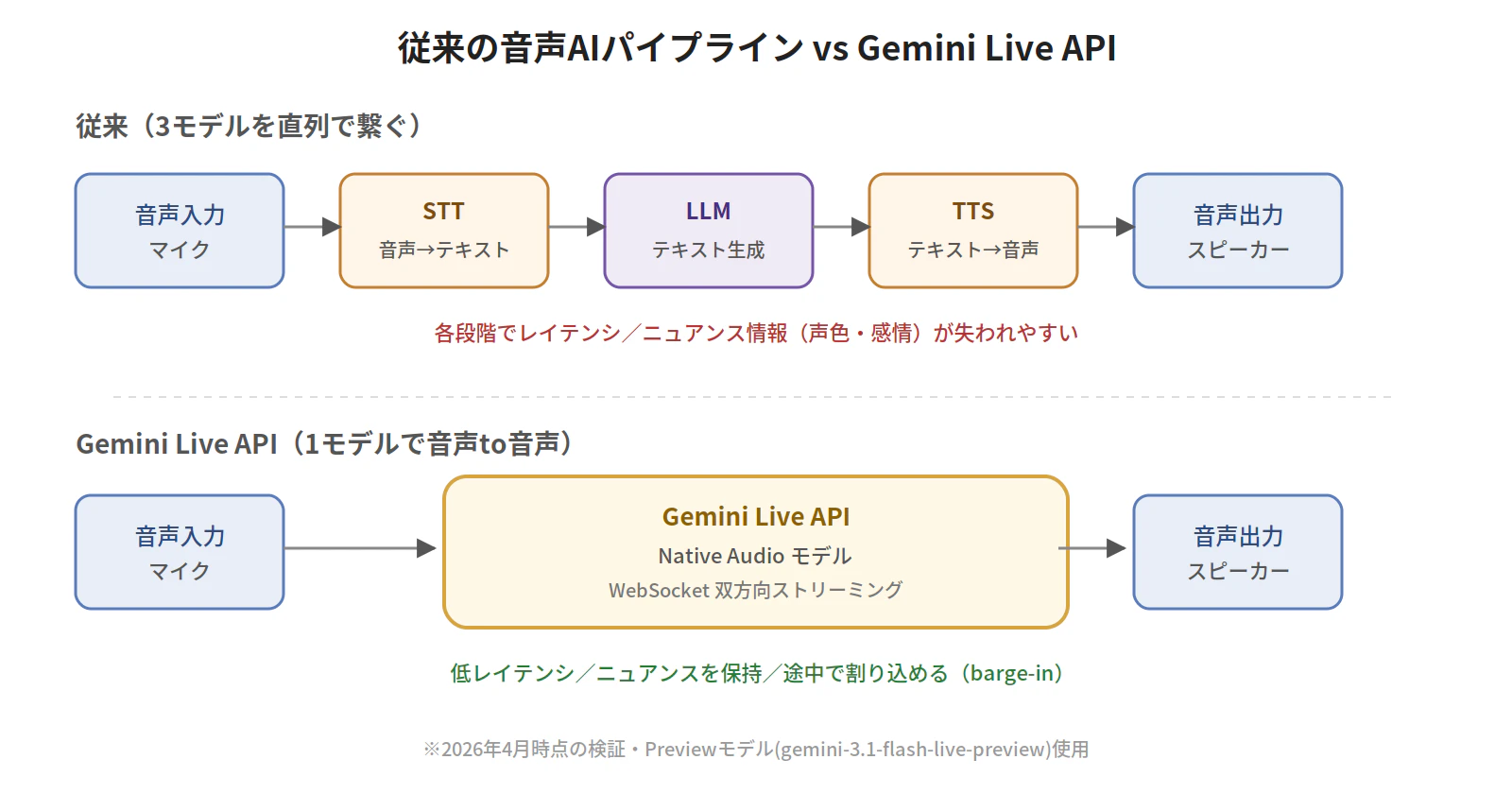
👉 「音声→音声」を1つのモデルで扱うため、会話のテンポが自然になる、と整理しやすいです。
全体アーキテクチャ
Colab × Gradio × Live API の組み合わせでは、以下の3つの層が協調します。
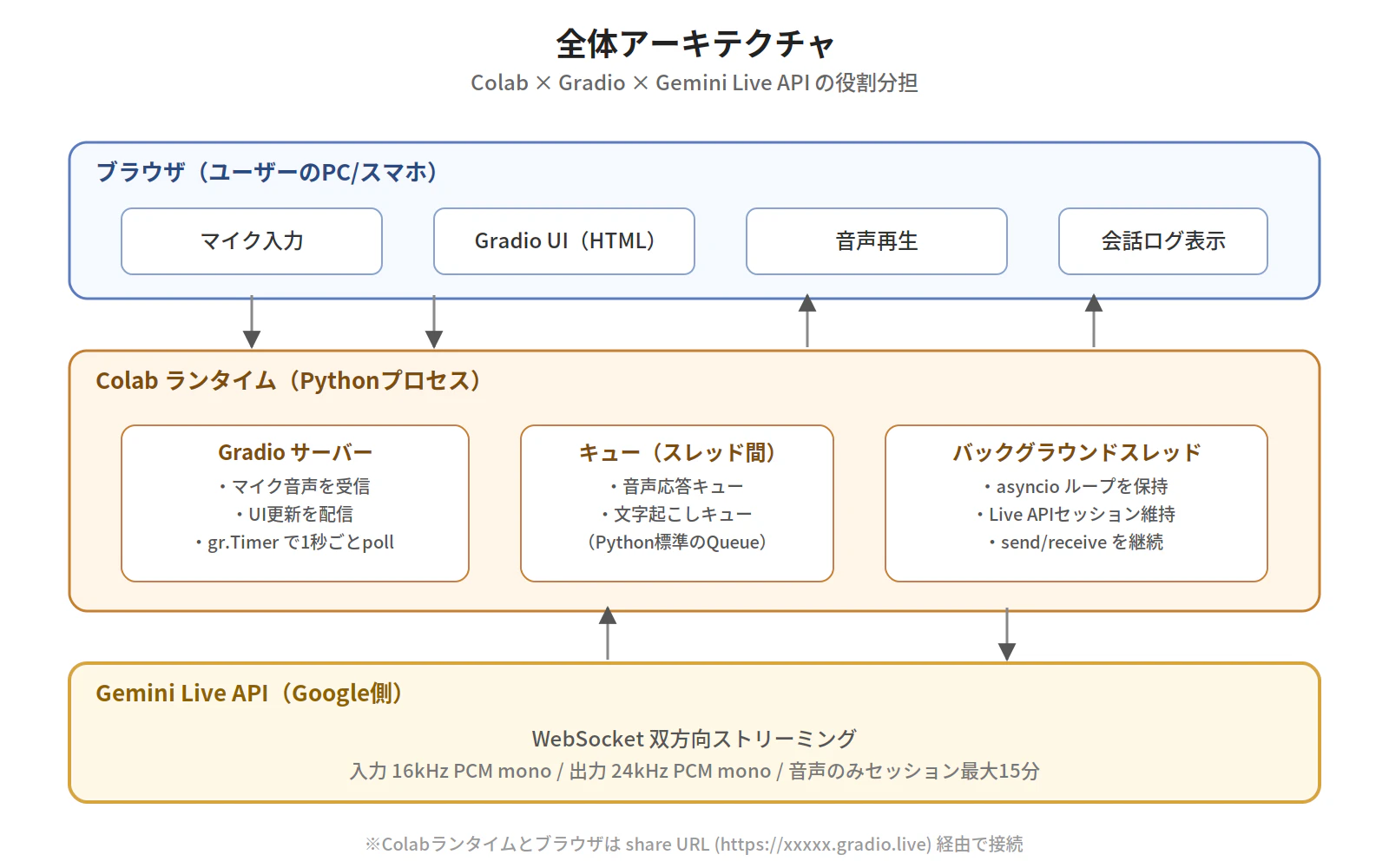
- ブラウザ層: マイク入力・音声再生・UI表示。Gradioが生成したHTMLが動く
- Colabランタイム層: Gradioサーバー + バックグラウンドのasyncioループ + スレッド間キュー
- Live API層(Google側): WebSocket経由で音声ストリームを受けて応答を返す
ポイントは、Gradio(同期)とLive API(非同期のWebSocket)の橋渡しに、別スレッドとキューを使うことです。これがないと、「Gradioのハンドラが終わるとasyncioも終わってしまう」状態になります。
環境準備
APIキー
Google AI Studio でAPIキーを取得し、Colabの左サイドバー「🔑 シークレット」に GOOGLE_API_KEY として登録します。
import os
try:
from google.colab import userdata
os.environ["GOOGLE_API_KEY"] = userdata.get("GOOGLE_API_KEY")
print("APIキーをColab userdataから取得しました")
except ImportError:
if not os.environ.get("GOOGLE_API_KEY"):
raise RuntimeError("GOOGLE_API_KEY が設定されていません")
genai.Client() は環境変数 GOOGLE_API_KEY を自動で読むので、この形が素直です。
ライブラリ
!pip install -q "gradio>=5.0" google-genai numpy scipy
gr.Timer を使うため Gradio 5.x 以上を推奨します。
実装:永続セッション版
最小構成として「録音→送信→音声応答再生」を1ターンだけ動かす版も書けますが、同じ話題を続けて聞けない制約があります。ここからは、セッションを張りっぱなしにして連続会話できる構成を作っていきます。
設計方針
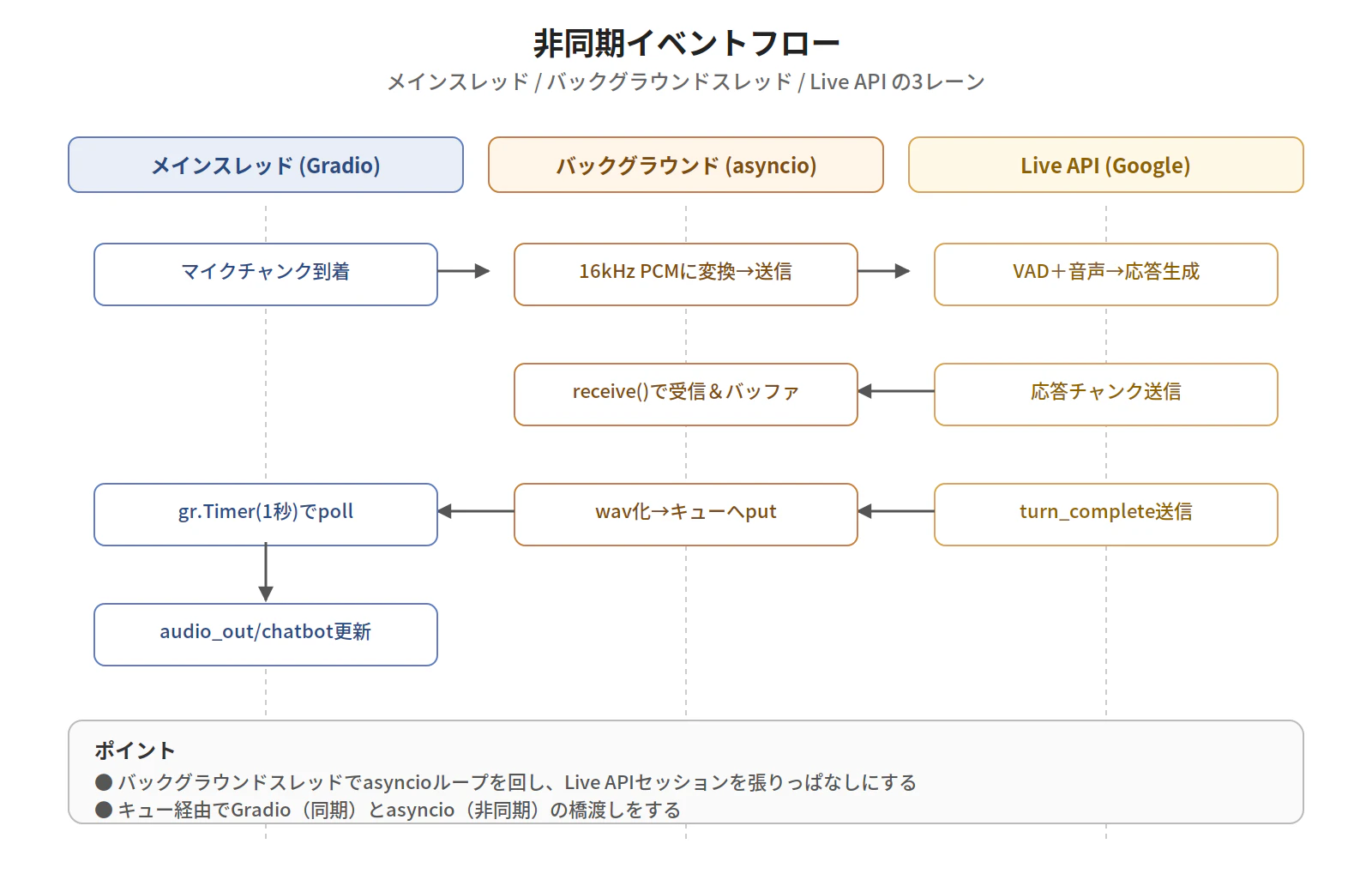
- バックグラウンドスレッドで
asyncioループを起動し、Live APIセッションを維持 - メインスレッド(Gradioハンドラ)からは キュー経由 で音声データを送り込む
- 応答音声と文字起こしも キュー経由 でGradioに戻す
-
gr.Timerで1秒ごとにキューをpollしてUIを更新
ハマりどころ①:receive() は1ターン分のイテレータ
最初、素直に以下のように書いたところ、1ターンだけ応答して、その後沈黙する現象に遭遇しました。
async def _receive_loop(self):
async for response in self.session.receive():
# 処理...
ログを仕込んで追ったところ、turn_complete が返ってきた瞬間に async for が抜けて、with 文ごとセッションが閉じていました。
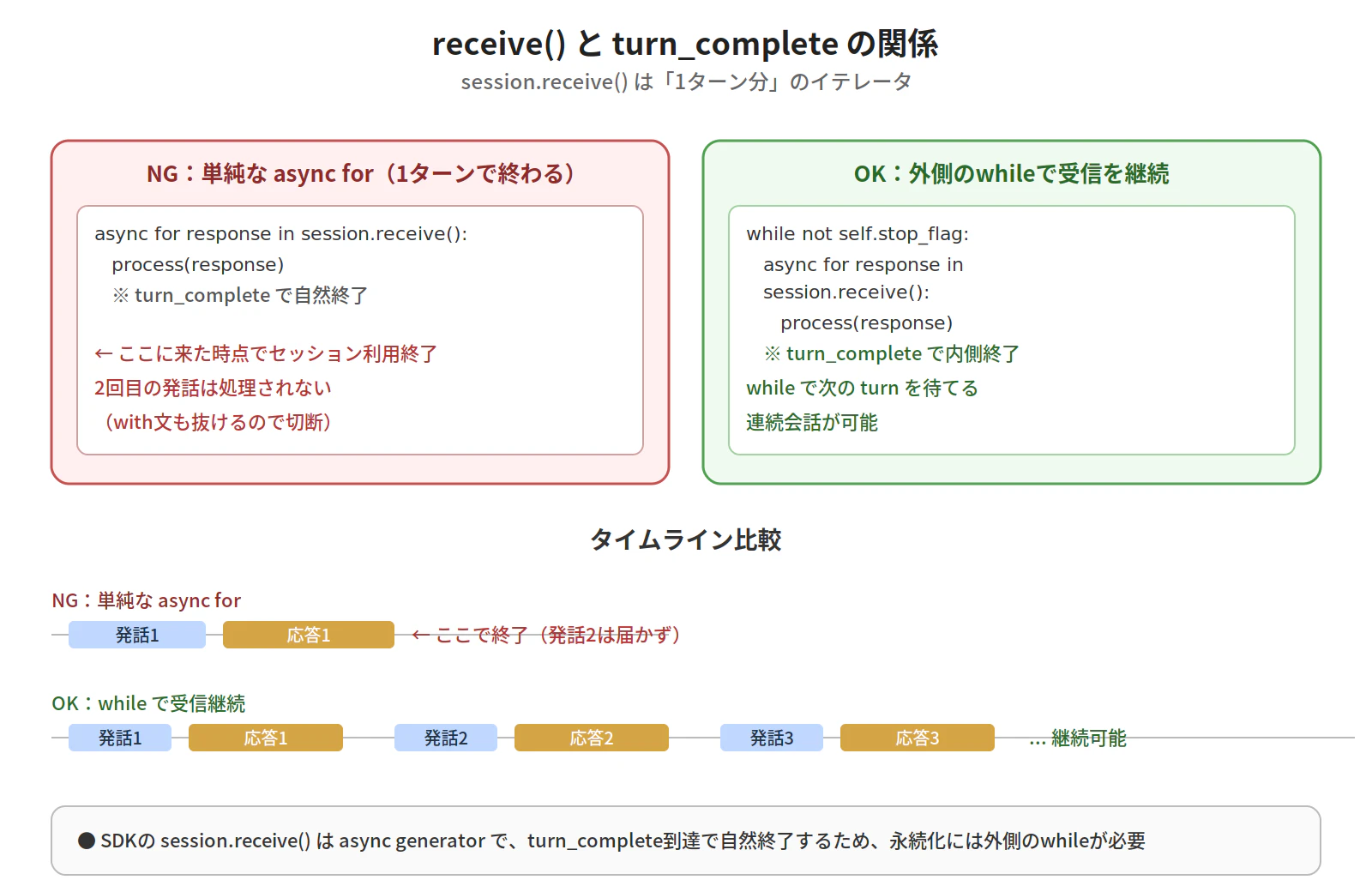
SDKの session.receive() は 1ターン分のasync generator なので、ターンをまたいで使うには外側の while で囲う必要があります。
👉 WebSocket接続自体は張りっぱなしなので「ストリームが継続する」と思いがちですが、receive() の粒度は1ターン単位、と捉えると整理しやすいです。
async def _receive_loop(self):
while not self.stop_flag:
async for response in self.session.receive():
# 処理...
# async forを抜けたら、次のturnを待つためにwhileの先頭へ戻る
👉 このパターンは公式ドキュメントでも触れられていますが、初見だと気付きにくい落とし穴でした。
ハマりどころ②:音声再生が毎秒リセットされる
gr.Timer で1秒ごとに audio_out を更新する構成にしたところ、応答音声が1秒だけ再生されて止まる現象に遭遇しました。
原因は、キューが空のときに None を返していたことです。Gradioは None を「クリア指示」と解釈し、再生中のオーディオを毎秒リセットしていました。
対策として、キューに新規音声があるときだけ更新、それ以外は gr.skip() で触らないようにします。
def poll_updates(chat_history):
# ... 文字起こし処理 ...
new_audio = None
try:
while True:
new_audio = manager.response_audio_queue.get_nowait()
except Empty:
pass
if new_audio is not None:
audio_path = wav_bytes_to_tempfile(new_audio)
return chat_history, audio_path, stats
else:
return chat_history, gr.skip(), stats # ここで再生を守る
ハマりどころ③:Colabでマイクが認識されない
ブラウザ(Chrome)ではマイクデバイスは認識されているのに、Gradioに届く波形が平坦(無音)になることがありました。
切り分けとして、https://mictests.com/ などでマイク自体の動作を確認したうえで、Chromeの🔒アイコン → サイトの設定 → マイクでデバイスを明示的に選択し直すと解消しました。複数マイク環境では、Chromeが意図しないデバイスを掴んでいることが原因でした。
言語と声の選択
Native Audio モデル(gemini-3.1-flash-live-preview)では、language_code による明示的な言語指定はサポートされていません。System Instructionで言語を指定するのが公式推奨です。
LANGUAGE_PRESETS = {
"日本語": {
"instruction": (
"あなたは親しみやすいアシスタントです。簡潔に答えてください。"
"RESPOND IN JAPANESE. YOU MUST RESPOND UNMISTAKABLY IN JAPANESE."
),
},
"English": {
"instruction": (
"You are a friendly assistant. Keep your answers concise. "
"RESPOND IN ENGLISH. YOU MUST RESPOND UNMISTAKABLY IN ENGLISH."
),
},
}
声(voice_name)は speech_config で指定できます。Live APIには30種の声が用意されていて、今回は Puck / Charon / Kore / Aoede から選べるようにしました。
config = types.LiveConnectConfig(
response_modalities=["AUDIO"],
system_instruction=preset["instruction"],
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name=voice_name,
)
),
),
)
コード全体
クリックで展開(約300行)
import asyncio
import io
import tempfile
import threading
import time
import traceback
import wave
from math import gcd
from queue import Empty, Queue
import gradio as gr
import numpy as np
from google import genai
from google.genai import types
from scipy.signal import resample_poly
MODEL = "gemini-3.1-flash-live-preview"
SEND_SAMPLE_RATE = 16000
RECEIVE_SAMPLE_RATE = 24000
LANGUAGE_PRESETS = {
"日本語": {
"instruction": (
"あなたは親しみやすいアシスタントです。簡潔に答えてください。"
"RESPOND IN JAPANESE. YOU MUST RESPOND UNMISTAKABLY IN JAPANESE."
),
},
"English": {
"instruction": (
"You are a friendly assistant. Keep your answers concise. "
"RESPOND IN ENGLISH. YOU MUST RESPOND UNMISTAKABLY IN ENGLISH."
),
},
}
VOICE_PRESETS = ["Puck", "Charon", "Kore", "Aoede"]
def build_config(language_key: str, voice_name: str) -> types.LiveConnectConfig:
preset = LANGUAGE_PRESETS[language_key]
return types.LiveConnectConfig(
response_modalities=["AUDIO"],
system_instruction=preset["instruction"],
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(
voice_name=voice_name,
)
),
),
)
class LiveSessionManager:
def __init__(self):
self.client = genai.Client()
self.loop = None
self.session = None
self.thread = None
self.ready_event = threading.Event()
self.stop_flag = False
self.current_config = None
self.response_audio_queue = Queue()
self.transcript_queue = Queue()
self._current_turn_audio = bytearray()
self.state = "disconnected"
self.last_error = None
def start(self, config: types.LiveConnectConfig):
if self.thread and self.thread.is_alive():
self.stop_flag = True
try:
if self.session and self.loop and not self.loop.is_closed():
asyncio.run_coroutine_threadsafe(self._close_session(), self.loop)
except Exception:
pass
self.thread.join(timeout=5)
self.ready_event.clear()
self.stop_flag = False
self.current_config = config
self.session = None
self._current_turn_audio = bytearray()
self.state = "connecting"
self.last_error = None
self.thread = threading.Thread(target=self._run_loop, daemon=True)
self.thread.start()
self.ready_event.wait(timeout=30)
async def _close_session(self):
try:
if self.session:
await self.session.close()
except Exception:
pass
def _run_loop(self):
self.loop = asyncio.new_event_loop()
asyncio.set_event_loop(self.loop)
try:
self.loop.run_until_complete(self._session_main())
except Exception as e:
self.state = "error"
self.last_error = str(e)
async def _session_main(self):
try:
async with self.client.aio.live.connect(
model=MODEL, config=self.current_config
) as session:
self.session = session
self.state = "connected"
self.ready_event.set()
await self._receive_loop()
except Exception as e:
self.state = "error"
self.last_error = str(e)
self.ready_event.set()
finally:
if self.state != "error":
self.state = "disconnected"
async def _receive_loop(self):
try:
while not self.stop_flag:
try:
async for response in self.session.receive():
if self.stop_flag:
return
if response.data:
self._current_turn_audio.extend(response.data)
sc = response.server_content
if sc:
if sc.input_transcription and sc.input_transcription.text:
self.transcript_queue.put(("user", sc.input_transcription.text))
if sc.output_transcription and sc.output_transcription.text:
self.transcript_queue.put(("gemini", sc.output_transcription.text))
if sc.turn_complete and self._current_turn_audio:
wav_bytes = pcm_bytes_to_wav(
bytes(self._current_turn_audio), RECEIVE_SAMPLE_RATE
)
self.response_audio_queue.put(wav_bytes)
self._current_turn_audio = bytearray()
if sc.interrupted:
self._current_turn_audio = bytearray()
except Exception as inner:
# エラー時は無限ループ回避のため即return
self.state = "error"
self.last_error = str(inner)
return
finally:
pass
def send_audio(self, pcm_bytes: bytes):
if not self.session or not self.loop or self.state != "connected":
return
asyncio.run_coroutine_threadsafe(
self._send_audio_async(pcm_bytes), self.loop
)
async def _send_audio_async(self, pcm_bytes: bytes):
try:
await self.session.send_realtime_input(
audio=types.Blob(
data=pcm_bytes,
mime_type=f"audio/pcm;rate={SEND_SAMPLE_RATE}",
)
)
except Exception:
pass
def numpy_to_pcm16_bytes(audio_np: np.ndarray, src_sr: int) -> bytes:
if audio_np.ndim == 2:
audio_np = audio_np.mean(axis=1)
if audio_np.dtype == np.int16:
audio_float = audio_np.astype(np.float32) / 32768.0
elif audio_np.dtype == np.int32:
audio_float = audio_np.astype(np.float32) / 2147483648.0
else:
audio_float = audio_np.astype(np.float32)
peak = np.abs(audio_float).max()
if peak > 1.0:
audio_float = audio_float / peak
if src_sr != SEND_SAMPLE_RATE:
g = gcd(src_sr, SEND_SAMPLE_RATE)
audio_float = resample_poly(audio_float, SEND_SAMPLE_RATE // g, src_sr // g)
audio_int16 = np.clip(audio_float * 32767, -32768, 32767).astype(np.int16)
return audio_int16.tobytes()
def pcm_bytes_to_wav(pcm_bytes: bytes, sample_rate: int) -> bytes:
buf = io.BytesIO()
with wave.open(buf, "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(sample_rate)
wf.writeframes(pcm_bytes)
return buf.getvalue()
def wav_bytes_to_tempfile(wav_bytes: bytes) -> str:
tmp = tempfile.NamedTemporaryFile(suffix=".wav", delete=False)
tmp.write(wav_bytes)
tmp.close()
return tmp.name
manager = LiveSessionManager()
def start_session(language_key: str, voice_name: str):
config = build_config(language_key, voice_name)
manager.start(config)
if manager.state == "connected":
return f"🟢 接続: {language_key} / 声: {voice_name}"
else:
return f"🔴 接続失敗: {manager.last_error or '不明'}"
def on_mic_stream(audio_chunk):
if audio_chunk is None:
return
sr, audio_np = audio_chunk
if audio_np is None or len(audio_np) == 0:
return
pcm = numpy_to_pcm16_bytes(audio_np, sr)
manager.send_audio(pcm)
def poll_updates(chat_history):
while True:
try:
role, text = manager.transcript_queue.get_nowait()
except Empty:
break
if role == "user":
if chat_history and chat_history[-1][0] is not None and chat_history[-1][1] is None:
chat_history[-1] = (chat_history[-1][0] + text, None)
else:
chat_history.append((text, None))
else:
if chat_history and chat_history[-1][1] is not None:
chat_history[-1] = (chat_history[-1][0], chat_history[-1][1] + text)
else:
last_user = chat_history[-1][0] if chat_history else ""
if chat_history and chat_history[-1][1] is None:
chat_history[-1] = (last_user, text)
else:
chat_history.append((None, text))
new_audio = None
try:
while True:
new_audio = manager.response_audio_queue.get_nowait()
except Empty:
pass
state_icon = {"connected": "🟢", "disconnected": "⚪", "error": "🔴", "connecting": "🟡"}.get(manager.state, "⚪")
status_text = f"{state_icon} {manager.state}"
if manager.state == "error" and manager.last_error:
status_text += f" - {manager.last_error[:80]}"
if new_audio is not None:
audio_path = wav_bytes_to_tempfile(new_audio)
return chat_history, audio_path, status_text
else:
return chat_history, gr.skip(), status_text
with gr.Blocks(title="Gemini Live API Demo") as demo:
gr.Markdown("## Gemini Live API 永続セッション")
gr.Markdown("言語と声を選んで「接続」を押してください。")
with gr.Row():
language_radio = gr.Radio(choices=list(LANGUAGE_PRESETS.keys()), value="日本語", label="言語")
voice_dropdown = gr.Dropdown(choices=VOICE_PRESETS, value="Puck", label="声")
start_btn = gr.Button("接続 / 再接続", variant="primary")
status = gr.Textbox(label="ステータス", value="未接続", interactive=False)
with gr.Row():
with gr.Column():
mic = gr.Audio(sources=["microphone"], streaming=True, type="numpy", label="マイク(常時入力)")
with gr.Column():
chatbot = gr.Chatbot(label="会話ログ", height=400)
audio_out = gr.Audio(label="Geminiの応答", autoplay=True, streaming=False)
start_btn.click(fn=start_session, inputs=[language_radio, voice_dropdown], outputs=status)
mic.stream(fn=on_mic_stream, inputs=mic, outputs=None)
timer = gr.Timer(1.0)
timer.tick(fn=poll_updates, inputs=chatbot, outputs=[chatbot, audio_out, status])
demo.launch(share=True, debug=True)
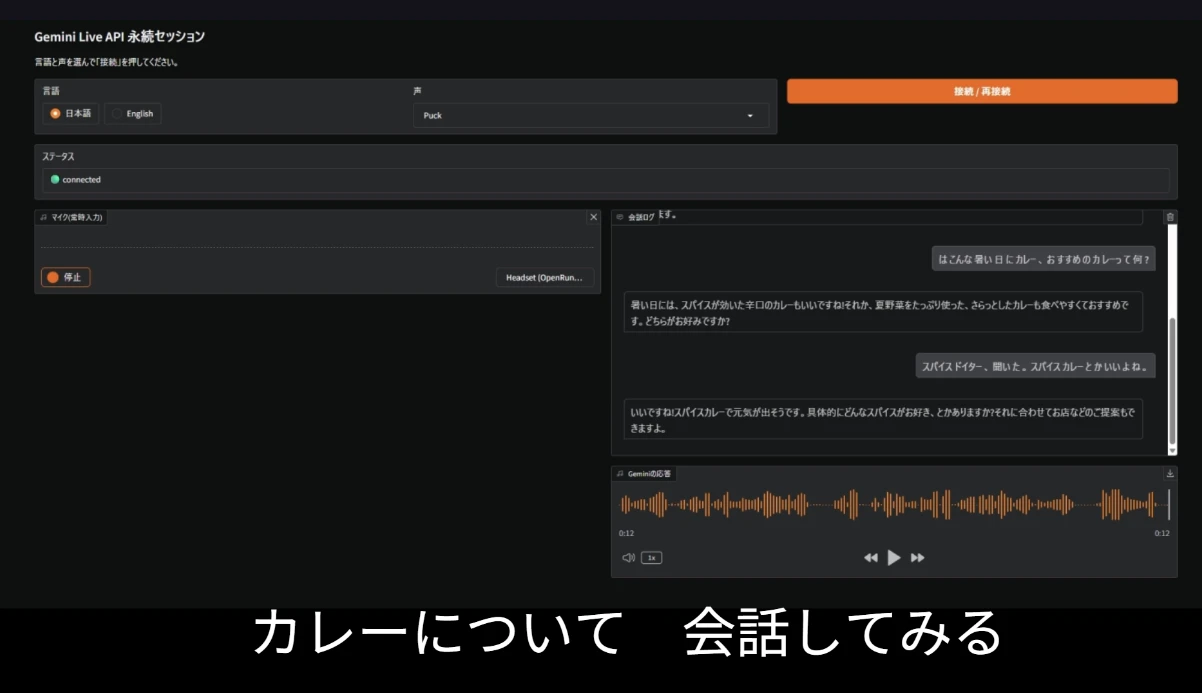
動かしてみた
Colab上で上記コードを実行すると、https://xxxxx.gradio.live の公開URLが発行されます。必ずこのshare URLを新しいタブで開くようにしてください(Colab内の埋め込みプレビューだと、iframe経由でマイク権限が降りにくいことがあります)。
「接続」を押して、マイクに向かって話しかけると、Geminiが音声で返してくれます。声を Charon に変えると低めの落ち着いた声、Aoede にすると明るめの声、といった具合にキャラクターが変わって面白いです。
補足:運用上の注意
セッションと接続の時間制限
Live APIには セッション と 接続(WebSocket connection) という2つの時間制限があります。混同しやすいので整理しておきます。
-
セッションの時間制限(圧縮なしの場合)
- 音声のみ: 最大15分
- 音声+映像: 最大2分
- WebSocket接続の寿命: 約10分(これを超えるとサーバー側から切断される)
-
延長方法:
- Context Window Compression: セッションを実質無制限に延長できる
- Session Resumption: 接続が切れても同じセッションを別の接続で引き継げる
今回の実装は短時間の動作確認が目的なので、これらの延長機能は入れていません。本格的に使う場合は、GoAway メッセージの検知と session resumption の実装を検討する必要があります。
Previewモデルの稀なエラー
1011 The service is currently unavailable が返ることがあります。コード上はエラー時にセッションを終了するようにしてあるので、ステータスが🔴になったら「接続 / 再接続」を押してください。
無料枠の範囲
本記事は Google AI Studio の無料枠で動作確認しています。本格的に使うなら公式の料金体系とレート制限を確認してください。
発展の方向
今回は音声会話の基本形だけをまとめましたが、Live APIはもっと広い使い方ができます。
-
Function Calling: ユーザーの発話に応じて関数を呼び出す。レストランメニューを喋るとUIにメニュー表示、のような連動が組める(※
gemini-3.1-flash-live-previewでは同期Function Callingのみサポート、非同期は未対応) -
カメラ映像入力:
send_realtime_input(video=...)で画像フレームも送れる。マルチモーダルに拡張可能 -
長時間セッション対応:
ContextWindowCompressionConfigで時間制限を延長、SessionResumptionConfigで接続切断からの復帰を実装する
まとめ

- Gemini Live API は音声入出力を1モデルで扱う低レイテンシAPI
- Colab × Gradio で手軽に試せるが、非同期とWebSocketの橋渡しに工夫がいる
- ハマりどころは receive()の二重ループ と gr.skip()による再生保護 の2つが中心
- Previewモデルのため、長期的な仕様変更には注意が必要
Colabの無料枠+Gradioの組み合わせで、喋れるAIをここまで動かせるのは試す価値があると感じました。デモ用の叩き台としても十分使える手応えです。同じように試す方の参考になればと思います。