はじめに
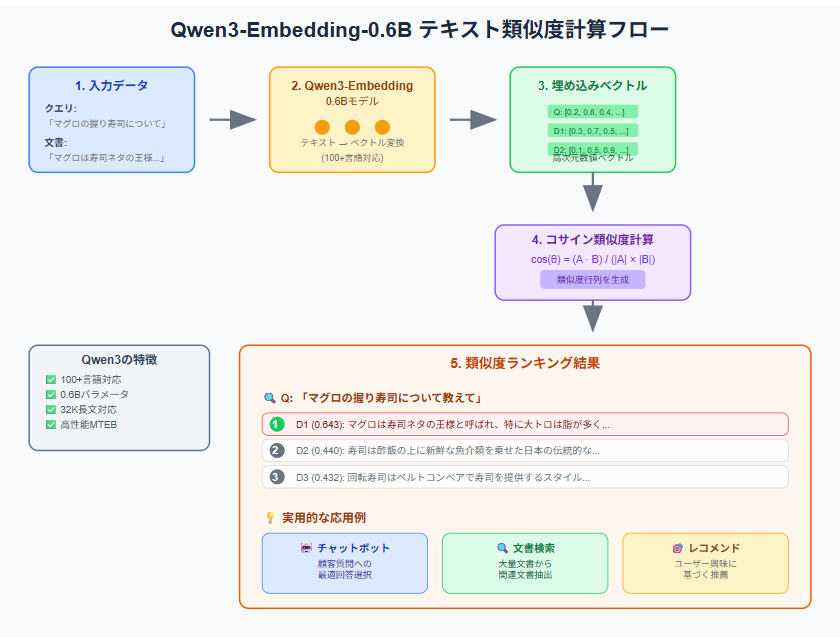
最新のテキスト埋め込みモデル「Qwen3-Embedding-0.6B」を使って、日本語のテキスト類似度計算を30行のコードで試してみました。寿司をテーマにした実例で、Google Colab上ですぐに試せる実装を紹介します。備忘録します。
Qwen3-Embedding-0.6Bとは?
Qwen3-Embedding-0.6Bは、Alibaba Cloudが開発した最新のテキスト埋め込みモデルで、日本語を含む100以上の言語に対応しています。0.6Bというコンパクトなパラメータ数ながら、MTEBベンチマークで高い性能を発揮し、最大32,000トークンの長文にも対応できるのが特長です。
実装
以下のコードをGoogle Colabで確認しました。
# 必要なライブラリをインストール(Colabなら最初に一度だけ)
!pip install sentence-transformers torch -q
from sentence_transformers import SentenceTransformer, util
# モデル読み込み(GPUがあれば自動でGPUを使用)
model = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B", trust_remote_code=True)
def compute_and_show(queries, documents, top_k=3):
"""類似度を計算して上位結果を表示"""
print(f"🚀 {len(queries)}個のクエリ × {len(documents)}個の文書で類似度を計算中...")
# 埋め込みを一括計算
q_emb = model.encode(queries, convert_to_tensor=True)
d_emb = model.encode(documents, convert_to_tensor=True)
# コサイン類似度行列
cos_scores = util.cos_sim(q_emb, d_emb)
print(f"\n📊 各クエリの上位{top_k}件の結果:")
print("="*60)
# 各クエリの上位top_kを抽出&表示
for i, query in enumerate(queries):
print(f"\n🔍 Q{i+1}: {query}")
hits = util.semantic_search(q_emb[i:i+1], d_emb, top_k=top_k)[0]
for rank, hit in enumerate(hits, 1):
idx, score = hit['corpus_id'], hit['score']
status = "✅" if rank == 1 and score > 0.7 else "📄"
print(f" {rank}位 {status} D{idx+1} ({score:.3f}): {documents[idx]}")
# 🍣 寿司をテーマにしたテスト
print("🍣 寿司をテーマにした類似度計算テスト")
queries = [
"マグロの握り寿司について教えて",
"回転寿司とは何ですか?",
"わさびの役割は?",
"寿司の作り方を説明してください"
]
documents = [
"マグロは寿司ネタの王様と呼ばれ、特に大トロは脂が多く濃厚な味わいが特徴です。",
"回転寿司はベルトコンベアで寿司を提供するスタイルの飲食店です。",
"わさびは魚の生臭さを消し、辛味で味を引き締める薬味です。",
"寿司は酢飯の上に新鮮な魚介類を乗せた日本の伝統的な料理で、職人の技術が重要です。",
"天ぷらは衣をつけて揚げる和食の代表料理です。"
]
# 実行
compute_and_show(queries, documents, top_k=3)
# 🏪 寿司屋さんでの会話シーン
print("\n" + "="*60)
print("🏪 寿司屋さんでの会話シーン")
customer_questions = [
"今日のおすすめは何ですか?",
"アレルギーがあるのですが大丈夫ですか?",
"この魚はどこで獲れたものですか?"
]
shop_responses = [
"本日のおすすめは朝獲れの天然本マグロの大トロです。脂の乗りが絶品です。",
"えび、かに、卵などのアレルギー食材を使わないメニューもご用意しております。",
"こちらの鯛は瀬戸内海で獲れた天然物で、身が締まって甘みがあります。",
"当店では築地市場から毎朝仕入れた新鮮な魚介類のみを使用しています。"
]
compute_and_show(customer_questions, shop_responses, top_k=2)
print("\n🎉 実行完了!クエリと文書の類似度が正しく計算されました。")
実行結果
上記のコードを実行すると、以下のような結果が得られます:
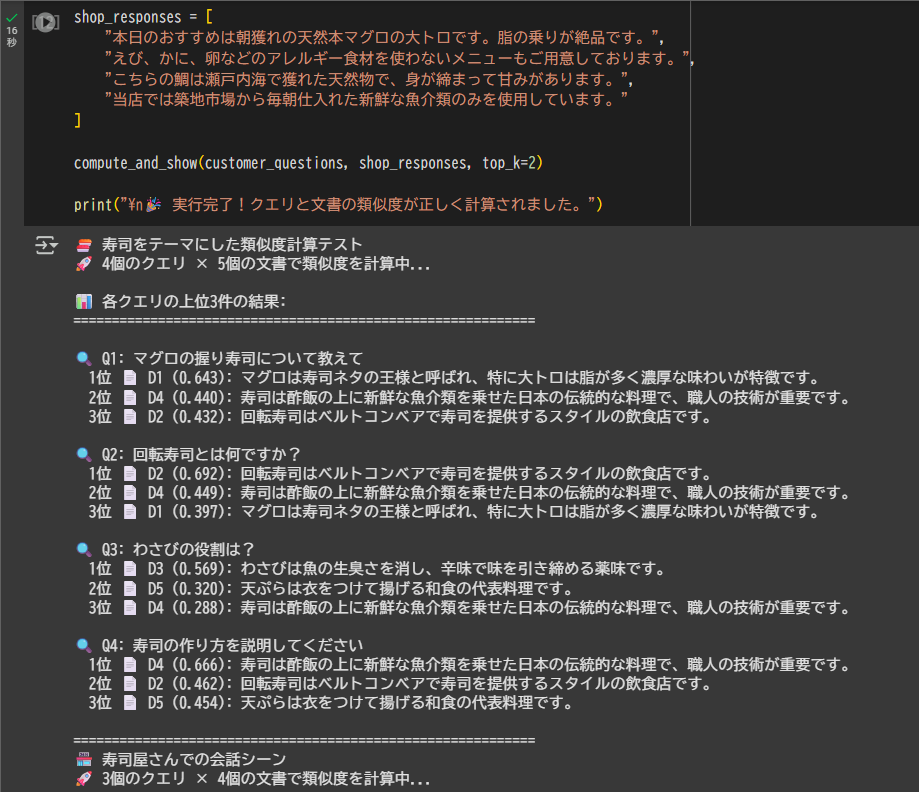
🍣 寿司をテーマにした類似度計算テスト
🚀 4個のクエリ × 5個の文書で類似度を計算中...
📊 各クエリの上位3件の結果:
============================================================
🔍 Q1: マグロの握り寿司について教えて
1位 📄 D1 (0.643): マグロは寿司ネタの王様と呼ばれ、特に大トロは脂が多く濃厚な味わいが特徴です。
2位 📄 D4 (0.440): 寿司は酢飯の上に新鮮な魚介類を乗せた日本の伝統的な料理で、職人の技術が重要です。
3位 📄 D2 (0.432): 回転寿司はベルトコンベアで寿司を提供するスタイルの飲食店です。
🔍 Q2: 回転寿司とは何ですか?
1位 📄 D2 (0.692): 回転寿司はベルトコンベアで寿司を提供するスタイルの飲食店です。
2位 📄 D4 (0.449): 寿司は酢飯の上に新鮮な魚介類を乗せた日本の伝統的な料理で、職人の技術が重要です。
3位 📄 D1 (0.397): マグロは寿司ネタの王様と呼ばれ、特に大トロは脂が多く濃厚な味わいが特徴です。
🔍 Q3: わさびの役割は?
1位 📄 D3 (0.569): わさびは魚の生臭さを消し、辛味で味を引き締める薬味です。
2位 📄 D5 (0.320): 天ぷらは衣をつけて揚げる和食の代表料理です。
3位 📄 D4 (0.288): 寿司は酢飯の上に新鮮な魚介類を乗せた日本の伝統的な料理で、職人の技術が重要です。
🔍 Q4: 寿司の作り方を説明してください
1位 📄 D4 (0.666): 寿司は酢飯の上に新鮮な魚介類を乗せた日本の伝統的な料理で、職人の技術が重要です。
2位 📄 D2 (0.462): 回転寿司はベルトコンベアで寿司を提供するスタイルの飲食店です。
3位 📄 D5 (0.454): 天ぷらは衣をつけて揚げる和食の代表料理です。
============================================================
🏪 寿司屋さんでの会話シーン
🚀 3個のクエリ × 4個の文書で類似度を計算中...
📊 各クエリの上位2件の結果:
============================================================
🔍 Q1: 今日のおすすめは何ですか?
1位 📄 D1 (0.467): 本日のおすすめは朝獲れの天然本マグロの大トロです。脂の乗りが絶品です。
2位 📄 D4 (0.296): 当店では築地市場から毎朝仕入れた新鮮な魚介類のみを使用しています。
🔍 Q2: アレルギーがあるのですが大丈夫ですか?
1位 📄 D2 (0.494): えび、かに、卵などのアレルギー食材を使わないメニューもご用意しております。
2位 📄 D1 (0.253): 本日のおすすめは朝獲れの天然本マグロの大トロです。脂の乗りが絶品です。
🔍 Q3: この魚はどこで獲れたものですか?
1位 📄 D3 (0.609): こちらの鯛は瀬戸内海で獲れた天然物で、身が締まって甘みがあります。
2位 📄 D4 (0.350): 当店では築地市場から毎朝仕入れた新鮮な魚介類のみを使用しています。
🎉 実行完了!クエリと文書の類似度が正しく計算されました。
結果の分析
全てのクエリに対して、最も関連性の高い文書が正確に1位としてマッチしており、高い精度のマッチングが確認できました。
類似度スコアも適切に分布しており、直接関連する内容は0.6以上、中程度の関連は0.4~0.5、関係の薄い内容は0.3以下と、妥当な結果が得られています。
実用的な応用例
1. チャットボット
顧客の質問に最適な回答を自動選択:
questions = ["返品したい", "配送はいつ?", "サイズ交換は?"]
answers = ["返品手続きは...", "配送は通常3-5日...", "サイズ交換は..."]
2. 文書検索システム
大量の文書から関連文書を抽出:
search_query = ["Python機械学習"]
documents = ["Python入門書", "機械学習アルゴリズム", "Java開発手法"]
3. レコメンドシステム
ユーザーの興味に基づく推薦:
user_interests = ["和食料理"]
items = ["寿司レシピ", "パスタ料理", "天ぷら作り方"]
カスタマイズ例
テーマ変更
# 技術文書の例
queries = ["Pythonの基本文法", "機械学習入門", "Webアプリ開発"]
documents = ["Python変数と関数の説明", "ニューラルネットワークの基礎", "Djangoフレームワーク入門"]
# 旅行の例
queries = ["東京の観光スポット", "美味しいラーメン店", "桜の名所"]
documents = ["東京スカイツリーは...", "一蘭ラーメンは...", "上野公園の桜は..."]
パラメータ調整
# より多くの候補を表示
compute_and_show(queries, documents, top_k=5)
# GPUメモリ節約(大量データの場合)
model.encode(texts, batch_size=32)
まとめ
Qwen3-Embedding-0.6Bで日本語テキストの類似度計算を試してみました。時間があればWebアプリ化や検索システムへの組み込みなどやってみます。
感想
自分の環境では、Gradioから直接Hugging Faceを呼び出すとうまく動作しなかったため、FastAPIなどでAPI化してから画面側から呼び出すのを試してみたい・・。