はじめに
Gemini Embedding 2 でマルチモーダル(画像+テキスト)のEmbeddingを試していました。
画像の類似度などを確認する中で、「マルチモーダルで使えるのは便利だな」と感じつつも、
それ以上に気になった点がありました。
それは、テキストEmbeddingのインターフェース(IF)やパラメータの設計が、これまでのEmbeddingモデルと少し違うという点です。
そこで本記事では、精度比較ではなく、
「テキストEmbeddingのIFとパラメータ設計に注目して整理」してみます。
※本記事は執筆時点の仕様ベースで整理しています。最終的な仕様は公式ドキュメントをご確認ください。
比較対象
-
Gemini
gemini-embedding-001
-
OpenAI
text-embedding-3-smalltext-embedding-3-large
まず結論

- Gemini:用途に応じてEmbeddingの挙動を制御できる設計
- OpenAI:シンプルで扱いやすい設計
特に差が出るのは以下です。
- 用途指定(task_type)の有無
- インターフェース設計の思想
① 出力次元の指定について

Gemini
config=types.EmbedContentConfig(
output_dimensionality=768
)
OpenAI
client.embeddings.create(
model="text-embedding-3-small",
input="テキスト",
dimensions=768
)
整理
- 両者とも出力次元の指定は可能
- そのため、ここは大きな差別化ポイントではない
② 用途指定(task_type)の違い

Gemini
config=types.EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT"
)
主な task_type:
- RETRIEVAL_QUERY(検索クエリ)
- RETRIEVAL_DOCUMENT(検索対象)
- SEMANTIC_SIMILARITY
- CLASSIFICATION
- CLUSTERING
上記以外にも QUESTION_ANSWERING、FACT_VERIFICATION などが用意されています。
詳細は 公式ドキュメント を参照してください。
OpenAI
- 用途を明示的に指定するパラメータはない
- 同じEmbeddingを用途に応じて使い分ける
所感
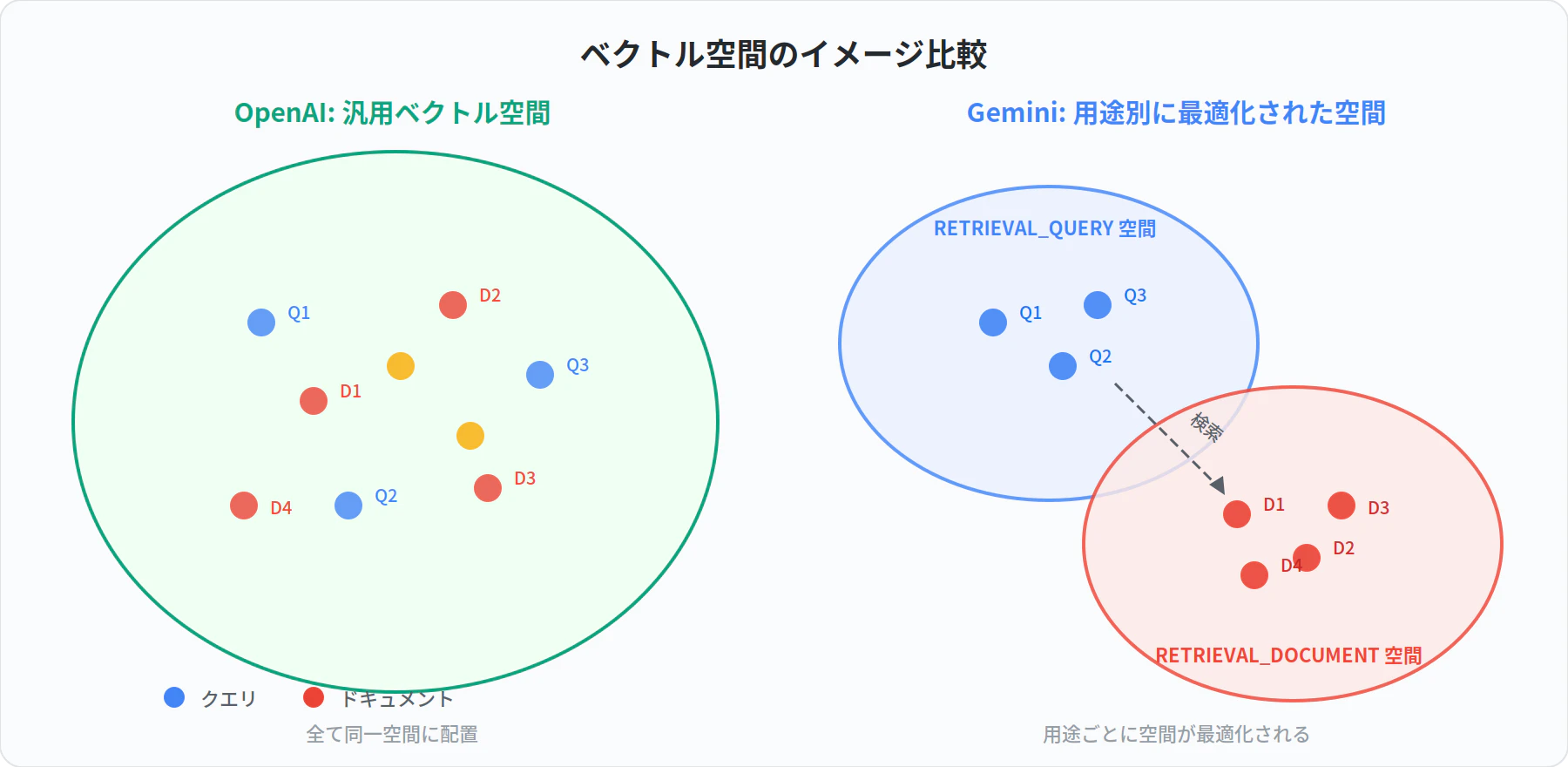
- Gemini:用途ごとに最適化されたEmbeddingを生成できる
- OpenAI:汎用Embeddingを用途側で使い分ける
たとえば RAG で task_type を使い分ける場合、
インデックス登録時は RETRIEVAL_DOCUMENT、検索時は RETRIEVAL_QUERY を指定することで、
クエリとドキュメントそれぞれに適したベクトル空間上の配置が期待できます。
これにより、汎用Embeddingをそのまま使う場合と比べて、
検索用途に最適化された表現になることが期待されます。
③ 入力インターフェース(IF)の違い

Gemini
contents = [
types.Content(
parts=[types.Part(text="テキスト")]
)
]
OpenAI
input="テキスト"
補足
この違いはEmbedding固有というより、
- Gemini API全体の設計(GenerativeLanguage API)
- マルチモーダル統一構造
に由来するものと考えられます。
所感
- Gemini:構造化された入力(拡張前提)
- OpenAI:シンプルで理解しやすい
④ 設計思想の違い

Gemini は
- モデルの用途(検索・類似度など)を明示的に指定する
- 入力を構造として扱う
という点から、
Embeddingも「制御・最適化する対象」
として設計されているように見えます。
一方 OpenAI は
- シンプルなAPI
- モデル選択中心
であり、
すぐに使えることを重視した設計
という印象です。
⑤ 実務での使い分け(具体例)
OpenAIが向いていそうなケース
-
シンプルなRAG構成
- 例:FAQ検索、社内ドキュメント検索
-
小規模〜中規模のベクトル検索
-
チームで扱うために学習コストを下げたい場合
Geminiが向いていそうなケース
-
検索クエリとドキュメントを分けて最適化したい
- 例:検索精度を上げたいRAG(task_typeでクエリ側・ドキュメント側を分離)
-
マルチモーダル検索を見据えている
-
将来的にEmbedding設計を調整したい場合
まとめ

Gemini Embedding は、
- マルチモーダル対応という点だけでなく
- テキストEmbeddingの時点で制御可能な設計になっている
点が特徴的でした。
特に
- task_type による用途指定
- 構造化された入力
といった点は、従来のEmbeddingと異なる設計思想を感じます。
Embeddingも「とりあえず使う」から
「設計・最適化する対象」へ変わってきているのかもしれません。
おわりに
今回はIF(インターフェース)やパラメータの観点で整理してみました。
2年ほど前に、Dify や Open WebUI、ollama + Continue などで RAG を試していた頃と比べると、
次元数や指定できるパラメータなどに変化が出てきていると感じています。
そのような変化に気づいたため、今回あらためて整理してみました。
今後も、IFやチャンクの切り方、前提となる考え方や概念などは変わっていく可能性があり、
そのあたりも含めて引き続き見ていきたいと思います。
参考