はじめに
こんにちは!
AWSをなんとなく触ったことはありますが、自分の中で整理された知識があるかというと微妙だな…と思い、それでは本を読みながらアウトプットしていこう! ということでこうして記事を書いています。
↓こちらの書籍を参考にさせて頂きながら記事を作成しておりますm(_ _)m
何回かに分けて各章を自分の解釈や考えなどを交えつつ、まとめていく予定です。
AWS認定資格試験テキスト AWS認定SysOpsアドミニストレーター – アソシエイト
AWSのモニタリングおよびロギングサービスの概要
この記事の前半では主に、AWSのモニタリング・ログ管理サービスを利用してシステムにメトリクスとアラームを作成し、管理する方法を見ていきます。
まずは頻出用語としてメトリクス と アラーム がありますので、そちらについて。
| 用語 | 説明 | 例 |
|---|---|---|
| メトリクス | システムの様子を数字で見えるようにしたもの。健康診断の数値のように、状態を客観的に把握するための指標 | EC2インスタンスのCPU使用率、ELBが受け取ったリクエスト数 |
| アラーム | メトリクスの数字が「ここを超えたら危ない」というライン(しきい値)に達したときに、自動でお知らせや処理を動かす見張り役 | CPU使用率が80%を超えたらメール通知、料金が一定額を超えたら通知 |
次に、この記事で扱うサービスについてざっとご紹介します。
| モニタリング/ロギングの対象 | サービス名 |
|---|---|
| AWSリソースやアプリケーションのメトリクス・ログを収集し、状態を監視する | CloudWatch |
| AWSアカウント内で行われたAPI操作やユーザー・サービスの活動履歴を記録する | CloudTrail |
| AWSリソースの構成(設定)の変更履歴を記録し、コンプライアンス評価を行う | AWS Config |
| 利用中のAWSサービスの障害情報や、自分のアカウントに影響するメンテナンス予定を通知する | AWS Health Dashboard |
この中で最も重要なサービスはCloudWatchです。
AWSリソースが作られると、自動的にCloudWatchにメトリクスを送信(Push)するようになっています。
また、Webサイトのページビュー数・商品の購入金額といったアプリケーション独自のメトリクスも、APIを使ってCloudWatchに送信することで、アラームで利用などができます。これをカスタムメトリクスといいます。
収集されたメトリクスの統計をもとにアラームを設定し、メール通知や、Lambda関数を発動させる(トリガーする)こともできます。
Amazon CloudWatch
改めてCloudWatchについてです。
このサービスが収集・可視化・障害検知を行う対象データは
メトリクス・ログ・イベント
の3つに分類されます。
メトリクスの監視
最初でも触れたメトリクスの、監視を行うときに大事な要素を見ていきます。
監視には「CloudWatchアラームを設定し、Amazon SNS(Simple Notification Service)経由で通知する」という仕組みがよく使われます。
たとえば、「CPU使用率が80%を超えたら通知」というルールで運用したい場合、CloudWatchアラームの設定を行うには次の3つを理解して設定する必要があります。
| 項目 | 説明 |
|---|---|
| 統計 | バラバラに集まった数字を、決めた時間ごとに「ひとまとめ」にした値。平均・最大・合計などの計算方法から選べる |
| 期間 | どれくらいの時間でひとまとめにするかの長さ(例:5分なら、5分ごとに1つの値として扱う) |
| アラームを実行するデータポイント | しきい値を超えたデータポイントの個数を、何個中いくつまで許容するかで指定する(例: 5個中3個でアラーム発動) |
期間に関しては、グラフで言うと 横軸の細かさ みたいなイメージになるな、と思い当たりました。
- 期間=1分 → 横軸が1分刻みで、1分ごとに点が打たれる(細かい・ギザギザのグラフ)
- 期間=5分 → 横軸が5分刻みで、5分ごとに点が打たれる(なめらかで安定したグラフ)
となると統計は…というと、 縦軸の値の決め方 になっていますね。どう集計した値を点にするか。
わかりやすくAIに図示してもらいました!
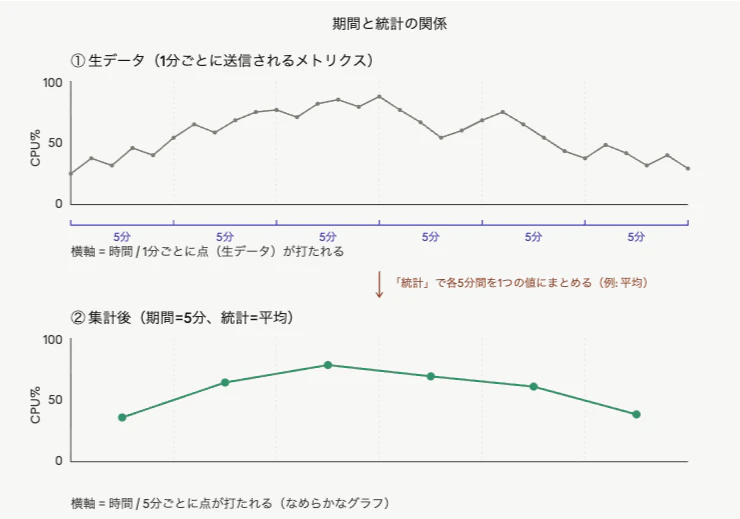
「直近5データポイント中5つすべてでCPU使用率が80%を超えたら通知」のようなときは、例えば表でまとめてみると次のような形の設定になると思います。
| 項目 | 設定値 |
|---|---|
| 名前空間 | AWS/EC2 |
| メトリクス名 | CPUUtilization |
| しきい値 | CPUUtilization > 80 |
| 統計 | 平均値 |
| 期間 | 1分 |
| アラームを実行するデータポイント | 5/5 |
ちなみに「5/5」というのは、直近5データポイント中5つ全部がしきい値を超えた、という意味になります。
ログの監視
ログの監視にはCloudWatch Logsを利用します。ログの一元管理・検索・フィルター処理を行うことができます。
AWS LambdaなどのAWSマネージド・サービスは、標準でCloudWatch Logsにログを収集する機能があります。
収集したログは、メトリクスフィルターという機能でログのパターンマッチングを行って、マッチした回数をカウントしたり、ログから取り出した数値をメトリクスの値として記録したりすることができます。
例えば、Laravelのログ用ライブラリMonologを使っている場合、デフォルトのログのフォーマットが
Log::error("msg");
// 出力例: [2024-01-01 12:34:56] local.ERROR: msg
となっています。
このように**チャンネル名.レベル名(大文字)**の形式で必ず含まれるため、メトリクスフィルターでERRORパターンを指定すれば自然に拾える、という使い方があります。
Pythonのlogger.errorなどもそのようですね。
その他、メトリクスフィルターの設定例です。
- アクセスログに記載された応答時間(ms)が5000(=5秒)以上のとき(数値比較)
- 例:
{ $.response_time >= 5000 }
- 例:
- アクセスログに記載されたステータスコードが「404」かつリクエスト先が「*.html」のとき(AND条件、ワイルドカード)
- 例:
{ ($.status = 404) && ($.request = "*.html") }
- 例:
AWS CloudTrail
AWS CloudTrailは、AWSのAPI利用状況についてのログを記録することができるサービスです。
…という文章を読んでも私は最初ピンと来なかったのですが、要は監査用途のサービスだと思えばしっくり来ました。
記録=証跡(Trail)を分析することで、「いつ・誰が・どこから・何のリソースに・どんな操作をしたか」を残しておきましょう、ということですね。
もう少し普段使いの例を挙げると…
- トラブルシューティング:「昨日急に動かなくなったけど、その時間に何の操作があった?」を調べる
- セキュリティ検知:CloudTrailのログをCloudWatch Logsに流して、不審なAPI呼び出し(例:ルートアカウント利用、IAMキー作成)を検知する
イベント履歴機能というものがあり、証跡ログの検索をしてログを分析しますが、S3やCloudWatchなど他のサービスに連携することで、ログの一元管理や監視などが楽に行えます。
- S3バケットに証跡ログを保存しておき、複数のリージョンの証跡を一元管理
- CloudWatch Logsに証跡ログを送信し、メトリクスフィルターでログイベントを監視する。
AWS Config
AWS Configは、AWSリソースの設定を記録して評価するサービスです。
CloudWatchは運用・パフォーマンス監視、CloudTrailはセキュリティ・監査が関心事でしたが、AWS Configは構成変更管理になります。
設定変更履歴自体はCloudTrailでの証跡からも調査できますが、大量のログを分析する必要が出てきます。
それに対して、Configなら時系列順にすばやく変更を確認できます。
AWS Configルール
AWSリソースの設定内容を評価するために、AWS Configルールを作成して、適切な設定内容を定義できます。AWSによって事前定義されたマネージドルールというものもあります。
…といっても多すぎるので、一部だけ抜粋してご紹介します!
| ルール名 | チェック内容 | カテゴリ |
|---|---|---|
s3-bucket-public-write-prohibited |
S3バケットがパブリック書き込みを許可していないか | セキュリティ |
s3-bucket-server-side-encryption-enabled |
S3バケットでサーバー側暗号化が有効になっているか | 暗号化 |
encrypted-volumes |
EBSボリュームが暗号化されているか | 暗号化 |
rds-storage-encrypted |
RDSのストレージが暗号化されているか | 暗号化 |
restricted-ssh |
セキュリティグループでSSH(22番)が 0.0.0.0/0(全IPアドレス受け入れ) に開放されていないか |
ネットワーク |
iam-password-policy |
IAMのパスワードポリシーが基準(長さ・複雑さ等)を満たしているか | IAM |
cloudtrail-enabled |
CloudTrailが有効になっているか | 監査・ロギング |
これらのルールは、AWSが運用・メンテナンスしてくれますので、可能な範囲で設定できると健全なリソースの状態を保てそうですね。
独自の評価を行うカスタムルールも作成できます。
| 想定シナリオ | チェック内容 |
|---|---|
| 命名規則の徹底 | EC2インスタンス名が prj-<env>-<role>-NN の形式になっているか |
| コスト管理ルール | 本番環境以外で t3.large 以上のインスタンスタイプが使われていないか |
このルールについてはLambda関数で専用のロジックを実装するかもしくは、AWS CloudFormation Guard という DSL で、Lambda関数を書かずに直接ルールを記述できるとのことです(2022年から利用可能)。
基本的にはマネージドルールで良さそう。
AWS Health Dashboard(旧 Personal Health Dashboard)
AWS Health Dashboardには、AWS利用者の環境に影響するAWSイベントの通知や、メンテナンスへの対処方法が表示されます。
(※もともとは Personal Health Dashboard という名前で提供されていたのですが、2022年に Service Health Dashboard と統合されて、現在は AWS Health Dashboard という1つのサービスになっています。統合後は次の2つのビューに分かれています。)
| ビュー | URL | 内容 | 認証 |
|---|---|---|---|
| Your account health | コンソールから | 自分のアカウントに関係するイベント | ログイン必要 |
| Service health | health.aws.amazon.com/health/status | 全AWS利用者向けの障害情報 | 不要(公開ページ) |
「Your account health」ビューは、「自分のアカウントが実際に使っているサービス・リージョン」に絞った情報だけが届くのが特徴です。
例えば
- 来週、自分が使っているEC2インスタンスが再起動される予定
- 証明書の有効期限が近い
といった、自分に直接関係のあるイベントだけをピンポイントで確認できます。
おわりに
ここまで読んでくださりありがとうございました!
今回のテーマはAWSにおけるモニタリング・ロギングについてでした。
次の記事では、「信頼性を高めるための各種AWSサービス(AWS Auto Scalingなど)」について見ていきたいと思います。