はじめに
お金がなさすぎてClaude Codeすら契約できない貧弱プログラマーですが、最近公開されたQwen3-Coderとやらはオープンソースなのでローカルで実装すれば最新モデルでローカルバイブコーディングができるような気がしたので試そうとした過程をまとめました。
注意
実装できないことがわかる記事です。
素人エンジニアが触ってみた、程度の記事なので大いに間違いを含んでいる可能性があります。おかしいところがあればぜひご指摘お願いします。
実行環境
以下の環境で実行してます しようとしていました。
| 項目 | 内容 |
|---|---|
| CPU | Intel Core i9-14900K |
| メモリ | DDR4 64GB |
| GPU | NVIDIA GeForce RTX 3090 (VRAM24GB) |
| OS | Windows 11 |
そもそもQwen3-Coderとはなんぞや
Xで流れてきた公式のポストは見ていて、「なんかまたすごそうなCLI型のLLM出たんかー」ぐらいの認識だったのですが、なんかこのロゴ(Qwen)見たことあるなと思って引っかかってました。それもそのはず、動画生成モデルで有名なWan2.1もこのロゴなんですよね。個人的にWan2.1を使ってローカルで動画生成して遊んでいた時期があったので、ここで「これつまりローカルLLMできてバイブコーディングできるってこと?」と脳裏によぎったわけです。
Qwen3-Coderの概要についてはこちらでまとめらていました。
Qwen3とQwen3-Coderの違い
さっそく、もう誰かローカルでQwen3-Coder実装してないかなと記事を探していたら、こちらを見つけてました。なんだもう実装してるのか、はやぇよ時代(コムドット)。
しかしこの記事が投稿されたのが2ヶ月前で、さっきのQwen公式の告知が数日前とかだったのにどいういうこと???とここで疑問に。
そう、これはQwen3であって、Qwen3-Coderではない。
まあ、軽く調べたかんじOllamaのQwen3-Coderのモデルあるし、さっきのQwen3ローカル実装の記事参考にすればいけそうじゃね?(筆者は今までOllama使ったことがありません)
このOllamaのモデルはたまたま名前が一致している別のモデルになるので本来のQwen3-Coderは使えません。
Qwen3-Corderのモデル探し
Qwen3-Corderはオープンソースということで、ローカルで使えないかと飛びついたわけですがここで疑問が。
そもそもClaude Codeを皆が大金払って利用するぐらいなのに、それと同じぐらい高性能なQwen3-Coderを一般家庭のローカル環境で動かせるわけなくない...???
気づくのが遅すぎてもはや笑えてきますが、はいそうです。計算リソースが足りないということです。
とはいえ、できなさそうだからやーめた。ではなく、これこれこうだから無理なのかあ。とちゃんと理由を知ることが大事だと個人的に思っているので、まずHugging Faceのページに行きます。
がっつりHugging Faceに詳しいわけではないのですが、たいていページ右欄にモデルのリンクが載っているので、Quantizations、つまり量子化されているモデルを選択します。
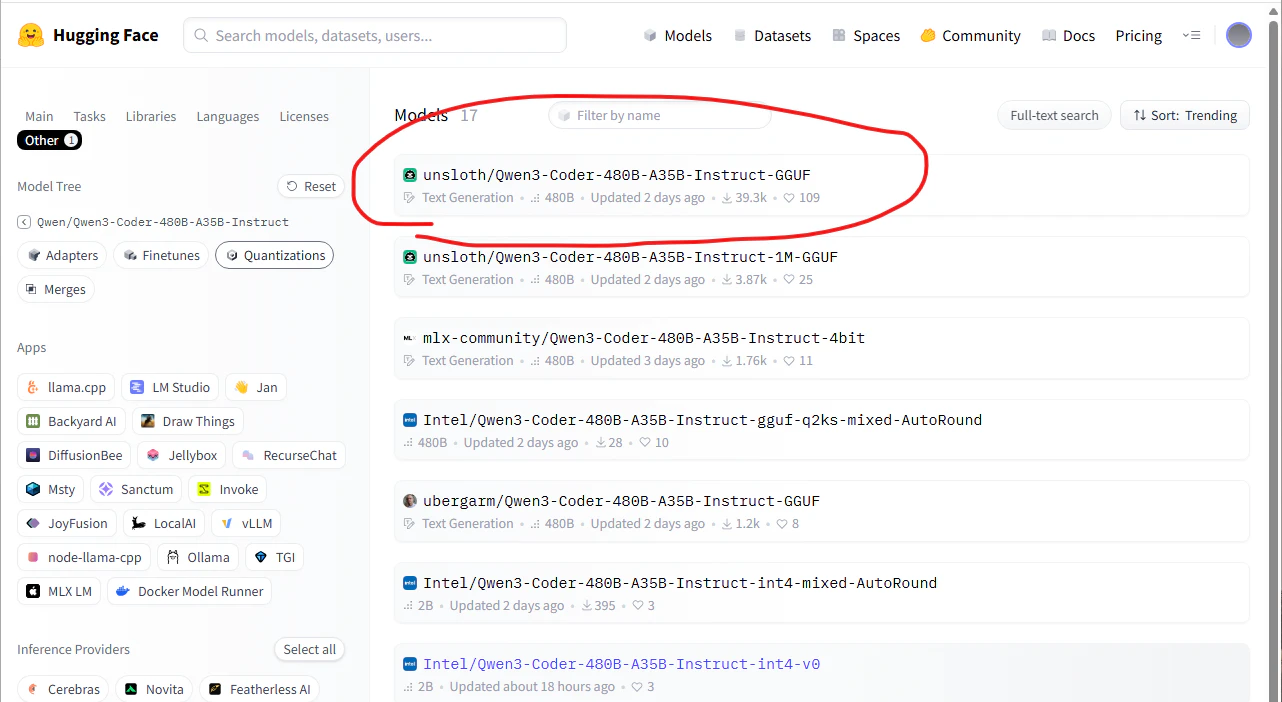
なにやらたくさん候補がありますが、とりあえず一番ダウンロードされているunslothのモデルを選択。
unslothとは、LLMのファインチューニングを高速かつ効率的に行うためのオープンソース・ライブラリです。by ChatGPT
Documentationを開くとローカルで動かす方法というページがあったので勝利を確信したのもつかの間、GGUFの欄を見てびっくり。
GGUF は、大規模言語モデル(LLM)を「軽量・高速」に扱うために作られた、最新のモデルファイル形式です。

RTX 3090 (VRA24GB) 程度のAIガチ界隈から見たらおもちゃのようなGPUで動かせるモデルは存在しないということがわかりました。
最軽量でも150GBかぁ。しかもこれもちろんGPUのVRAMだよね。そりゃみんな月額契約してバイブコーディングするわな。

納得したのでこれにて解散。
今後
無知の知のようにできないことがわかったわけですが、ここで終わるのもなんだか悔しいです。
Qwen3-Coderのもっと軽量のモデルが出るのを待つか、Qwen3-Coderとまでいかなくても、一般ご家庭のGPUで動かせるようなモデルでバイブコーディングできる環境を整えていきたいと思っています。