https://github.com/zihangdai/xlnet
XLNetの動作テスト
参考資料
https://mc.ai/bert%E3%82%92%E8%B6%85%E3%81%88%E3%81%9Fxlnet%E3%81%AE%E7%B4%B9%E4%BB%8B/
BERTを超えたXLNetの紹介
環境
rocm version rocm2.6
GPU RadeonⅦ
OS ubuntu16.04.6
linuxカーネル 4.15.0-55-generic
要約
rocmにおいて公式で動作確認されているTF1.13.1を使うと動かず、TF1.14.1を使わないとおかしいことになりますと言う話です。
Pre-trained models編
これには
XLNet-Large, Cased: 24-layer, 1024-hidden, 16-heads
XLNet-Base, Cased: 12-layer, 768-hidden, 12-heads. This model is trained on full data (different from the one in the paper).
の2つの学習済みモデルがあるのダウンロードして解凍します。
XLNet-LargeとXLNet-Baseの解凍先を以下のような感じで.bashrcにパスを通します
$HOMEでmkdir gpu_xlnetと言うディレクトリを作ってから
またglueデーターセットについては
https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e
上記のスクリプトでダウンロードできます。
export GLUE_DIR=/home/hoge/gpu_xlnet/xlnet/glue_data
export BASE_DIR=/home/hoge/gpu_xlnet/xlnet_cased_L-12_H-768_A-12
export LARGE_DIR=/home/hoge/gpu_xlnet/xlnet_cased_L-24_H-1024_A-16
こんな感じでパスを通すとチュートリアルのままで動かすことができます。
hogeには任意のユーザーネームが入ります
minicondaで``conda create -n py27 python=2.7```でpython2.7環境を作ってから
pip install tensorflow-rocm==1.13.1
で試しに動かしてみました。
GPUの枚数は1枚だったのでbashrcにCUDA_VISIBLE_DEVICES = 0 を追記しておきました。
python run_classifier.py \
--do_train=True \
--do_eval=False \
--task_name=sts-b \
--data_dir=${GLUE_DIR}/STS-B \
--output_dir=proc_data/sts-b \
--model_dir=exp/sts-b \
--uncased=False \
--spiece_model_file=${LARGE_DIR}/spiece.model \
--model_config_path=${LARGE_DIR}/xlnet_config.json \
--init_checkpoint=${LARGE_DIR}/xlnet_model.ckpt \
--max_seq_length=128 \
--train_batch_size=8 \
--num_hosts=1 \
--num_core_per_host=4 \
--learning_rate=5e-5 \
--train_steps=1200 \
--warmup_steps=120 \
--save_steps=600 \
--is_regression=True
で実行しましたが
Traceback (most recent call last):
File "run_classifier.py", line 20, in <module>
import tensorflow as tf
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/__init__.py", line 24, in <module>
from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/__init__.py", line 49, in <module>
from tensorflow.python import pywrap_tensorflow
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 74, in <module>
raise ImportError(msg)
ImportError: Traceback (most recent call last):
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 58, in <module>
from tensorflow.python.pywrap_tensorflow_internal import *
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 28, in <module>
_pywrap_tensorflow_internal = swig_import_helper()
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description)
ImportError: /home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so: undefined symbol: _ZN8hip_impl22hipLaunchKernelGGLImplEmRK4dim3S2_jP12ihipStream_tPPv
Failed to load the native TensorFlow runtime.
なぞのシンボルエラーが出て実行できませんでした、Python3.6でも試してみましたが同様のエラーが吐かれました。
ちなみにpip instal tensorflow=1.13.1でCPUで動かしてみましたがこの場合はエラーなく動作を開始できました。
なのでtensorflow-rocmの問題だと思います。
そこでtensorflow-rocm==1.14.1で動かした所無事に動いたので推奨されているTF-rのバージョンを1.13.1にするのではなく最新版にするのが吉であるとわかります。
ただ動くには動いたのですがGPUの使用率は一向に上がらず
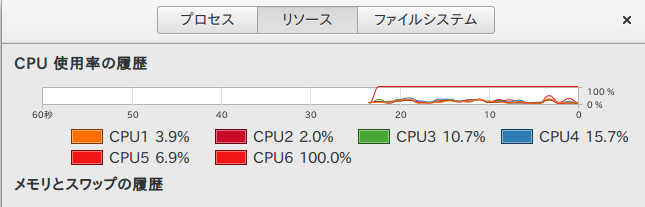
CPUの1Coreだけ使用率が100%に張り付いていたのでGPUを使ってくれてないな・・・と言った感じがしました、
途中のログを見ていると
2019-08-01 06:38:30.049864: W tensorflow/core/common_runtime/colocation_graph.cc:1016] Failed to place the graph without changing the devices of some resources. Some of the operations (that had to be colocated with resource generating operations) are not supported on the resources' devices. Current candidate devices are [
/job:localhost/replica:0/task:0/device:GPU:0
/job:localhost/replica:0/task:0/device:CPU:0
/job:localhost/replica:0/task:0/device:XLA_CPU:0
/job:localhost/replica:0/task:0/device:XLA_GPU:0].
See below for details of this colocation group:
どうやらなんかのグラフ作成に失敗しているようです。
ROCmで使うのであれば要検討な部分が多いと思われます。
学習編
学習済みモデルがダメだったぽいので次はモデルを学習させてみます。
save_dirを作って、pathを通してあげます
$ mkdir ./save
$ pip install sentencepiece
export SAVE_DIR=/home/hoge/xlnet/save
こんな感じで追加しておきました。
試しにCPUのtensorflowで前処理を行ってみます
python data_utils.py \
--bsz_per_host = 32 \
--num_core_per_host = 16 \
--seq_len = 512 \
--reuse_len = 256 \
--input_glob = * .txt \
--save_dir = $ {SAVE_DIR} \
--num_passes = 20 \
--bi_data = True \
--sp_path = spiece.model \
--mask_alpha = 6 \
--mask_beta = 1 \
--num_predict = 85
結果はabsl.flags._exceptions.IllegalFlagValueError: flag --bsz_per_host==: invalid literal for int() with base 10: '='と明らかにダメな感じだったので多分中のコードを弄る必要がありそうです
tensorflow-rocmではImportError: /home/rocm/miniconda3/envs/xlnet/lib/python3.6/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so: undefined symbol: _ZN8hip_impl22hipLaunchKernelGGLImplEmRK4dim3S2_jP12ihipStream_tPPv
tensorflow-rocmでも動きませんでした。
頻発するundefined symbol: _ZN8hip_impl22hipLaunchKernelGGLImplEmRK4dim3S2_jP12ihipStream_tPPvとはなんなのか
検索を掛けると以下のクローズド済みのイシューが見つかりました。
https://github.com/RadeonOpenCompute/ROCm/issues/764
Solved, as I am running a jupyter notebook server off another lower privilege user account,
somehow it has an older version installed and then the jupyter notebook was trying to load that (1.13.1),
but apparently when upgrading ROCm the system wide one was updated to 1.13.2.
Now removing both, and then I just installed the system wide one with sudo, it can import tensorflow without any issues.
ひとまず解決策としてxlnetの推奨tensorflowバージョンである13.1.1を使うのをやめることにしました。
tensorboard-1.14.0 tensorflow-estimator-1.14.0 tensorflow-rocm-1.14.0のバージョンを変更して実行してみます。
その結果エラーの内容が変わった、
ImportError: librccl.so: cannot open shared object file: No such file or directory
どうやらrcclのバイナリが見つからなないらしい、ただマルチGPUをするつもりはないので要らないはず・・
sudo apt-get update && sudo apt-get install -y --allow-unauthenticated rocm-dkms rocm-dev rocm-libs rccl rocm-device-libs hsa-ext-rocr-dev hsakmt-roct-dev hsa-rocr-dev rocm-opencl rocm-opencl-dev rocm-utils rocm-profiler cxlactivitylogger miopen-hip miopengemm
ひとまずこれをしたら出なくなりました。
次出たのがこのエラーで
absl.flags._exceptions.IllegalFlagValueError: flag --bsz_per_host==: invalid literal for int() with base 10: '='
ここによると
Hey, I think I fixed this by changing this line in main.py from:
flags.DEFINE_integer("train_size", np.inf, "The size of train images [np.inf]")
to:
flags.DEFINE_float("train_size", np.inf, "The size of train images [np.inf]")
It doesn't give me errors anymore and I'm able to train with the celebA dataset.
I'm using tensorflow-gpu 1.5.0 (last version), CUDA Toolkit 9.0, and cuDNN v7.
flags.DEFINE_integerをflags.DEFINE_floatに直すと良さそうと言うことなのでdata_utils.pyの873行目
flags.DEFINE_integer("bsz_per_host", 32, help="batch size per host.")をコメントアウトとしてflags.DEFINE_float("bsz_per_host", 32, help="batch size per host.")に書き直します。
そうすると
$ python data_utils.py --bsz_per_host=32 --num_core_per_host=16 --seq_len=512 --reuse_len=256 --input_glob=*.txt --save_dir=${SAVE_DIR} --num_passes=20 --bi_data=True --sp_path=spiece.model --mask_alpha=6 --mask_beta=1 --num_predict=85
WARNING: Logging before flag parsing goes to stderr.
W0801 06:25:15.442666 140464383280896 deprecation_wrapper.py:119] From data_utils.py:915: The name tf.logging.set_verbosity is deprecated. Please use tf.compat.v1.logging.set_verbosity instead.
W0801 06:25:15.442962 140464383280896 deprecation_wrapper.py:119] From data_utils.py:915: The name tf.logging.INFO is deprecated. Please use tf.compat.v1.logging.INFO instead.
W0801 06:25:15.443121 140464383280896 deprecation_wrapper.py:119] From data_utils.py:916: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.
W0801 06:25:15.443833 140464383280896 deprecation_wrapper.py:119] From data_utils.py:181: The name tf.gfile.Exists is deprecated. Please use tf.io.gfile.exists instead.
W0801 06:25:15.444554 140464383280896 deprecation_wrapper.py:119] From data_utils.py:206: The name tf.gfile.Open is deprecated. Please use tf.io.gfile.GFile instead.
W0801 06:25:15.445195 140464383280896 deprecation_wrapper.py:119] From data_utils.py:210: The name tf.gfile.Glob is deprecated. Please use tf.io.gfile.glob instead.
W0801 06:25:15.475003 140464383280896 deprecation_wrapper.py:119] From data_utils.py:211: The name tf.logging.info is deprecated. Please use tf.compat.v1.logging.info instead.
I0801 06:25:15.475229 140464383280896 data_utils.py:211] Use glob: *.txt
I0801 06:25:15.475733 140464383280896 data_utils.py:212] Find 0 files: []
I0801 06:25:15.475889 140464383280896 data_utils.py:216] Exit: task 0 has no file to process.
該当する学習データーがないと怒られます。
ひとまずhoge.txtと言う名前でサンプルにあった以下の文章を./xlnetに保存しました。
This is the first sentence.
This is the second sentence and also the end of the paragraph.<eop>
Another paragraph.
Another document starts here.
そうすると前処理を一応開始します
しかし
2019-08-01 06:55:54.651119: W tensorflow/core/common_runtime/bfc_allocator.cc:319] ****************************************************************************************************
Traceback (most recent call last):
File "run_classifier.py", line 855, in <module>
tf.app.run()
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/platform/app.py", line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/absl/app.py", line 300, in run
_run_main(main, args)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/absl/app.py", line 251, in _run_main
sys.exit(main(argv))
File "run_classifier.py", line 719, in main
estimator.train(input_fn=train_input_fn, max_steps=FLAGS.train_steps)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow_estimator/python/estimator/estimator.py", line 367, in train
loss = self._train_model(input_fn, hooks, saving_listeners)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow_estimator/python/estimator/estimator.py", line 1156, in _train_model
return self._train_model_distributed(input_fn, hooks, saving_listeners)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow_estimator/python/estimator/estimator.py", line 1219, in _train_model_distributed
self._config._train_distribute, input_fn, hooks, saving_listeners)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow_estimator/python/estimator/estimator.py", line 1329, in _actual_train_model_distributed
saving_listeners)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow_estimator/python/estimator/estimator.py", line 1480, in _train_with_estimator_spec
log_step_count_steps=log_step_count_steps) as mon_sess:
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 584, in MonitoredTrainingSession
stop_grace_period_secs=stop_grace_period_secs)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 1007, in __init__
stop_grace_period_secs=stop_grace_period_secs)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 725, in __init__
self._sess = _RecoverableSession(self._coordinated_creator)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 1200, in __init__
_WrappedSession.__init__(self, self._create_session())
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 1205, in _create_session
return self._sess_creator.create_session()
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 871, in create_session
self.tf_sess = self._session_creator.create_session()
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/monitored_session.py", line 647, in create_session
init_fn=self._scaffold.init_fn)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/session_manager.py", line 290, in prepare_session
config=config)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/session_manager.py", line 220, in _restore_checkpoint
saver.restore(sess, ckpt.model_checkpoint_path)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/training/saver.py", line 1286, in restore
{self.saver_def.filename_tensor_name: save_path})
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 950, in run
run_metadata_ptr)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 1173, in _run
feed_dict_tensor, options, run_metadata)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 1350, in _do_run
run_metadata)
File "/home/rocm/miniconda3/envs/py27/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 1370, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InternalError: 2 root error(s) found.
(0) Internal: Dst tensor is not initialized.
[[node save/RestoreV2 (defined at run_classifier.py:719) ]]
[[GroupCrossDeviceControlEdges_0/save/restore_all/_1934]]
(1) Internal: Dst tensor is not initialized.
[[node save/RestoreV2 (defined at run_classifier.py:719) ]]
0 successful operations.
0 derived errors ignored.
tensorflow.python.framework.errors_impl.InternalError: 2 root error(s) found.
ここの部分についてはあまりあてになりそうな情報がなくわからないのですが多分メモリ不足などに陥っている感じがします。