最初に
最近、HadoopやOracleでのデータ入出力の仕事をしています。
その際に問題になる大量データのロード・アンロードについてのまとめを記載します。
アジェンダ
1.SQL*Loader
2.Sqoop
3.外部表(GreenplumDB)
4.外部表(Oracle)
1.SQL*Loader
SQL*LoaderはOracleへのデータ投入時に使用します。
CSV形式などのテキストファイルからデータベース内にデータを取り込むためのツールです。
SQL*Loaderのインプットとして、入力ファイルと制御ファイルが必要です。
イメージ図
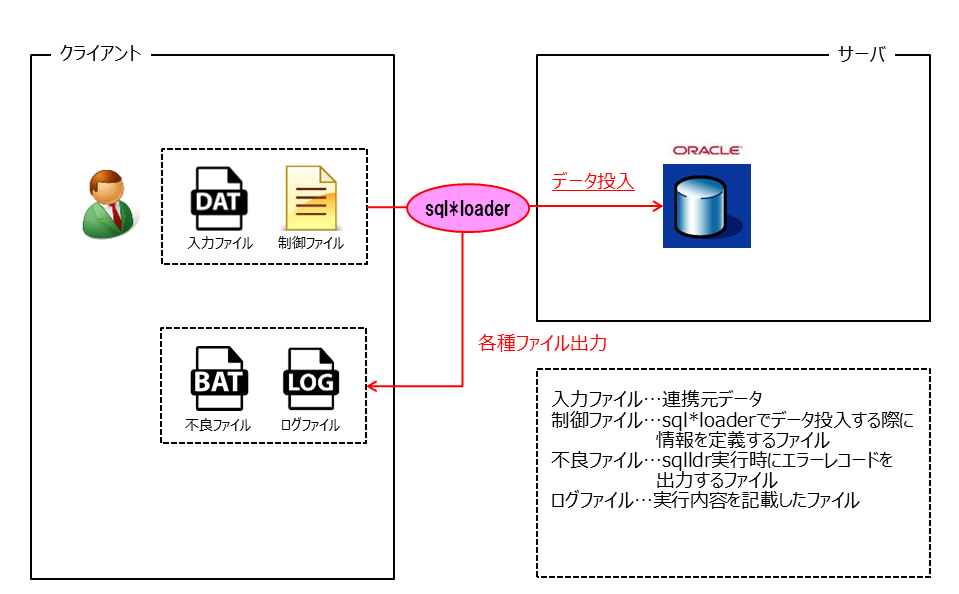
制御ファイルは取り込み対象のCSVファイル名や取り込みデータの編集仕様を記載します。
また、BATファイル名やLOGファイル名も指定可能です。
LOAD DATA
INFILE 'TEST1.DAT' "fix 10"
BADFILE 'TEST.BAD'
DISCARDFILE 'TEST1.DSC'
APPEND INTO TABLE TEST1
(
TESTCD POSITION(1:4) CHAR
, TESTNM POSITION(5:10) CHAR
)
SQL*Loaderを使用するときの注意点としては下記2つです
1.入力ファイルのフォーマットを押さえておく(データ投入ならば当たり前か…)
2.クライアント側にOracle Clientをインストールしておく必要がある。
私が最初に始めたときは2の対処法にハマりました。
環境不備の場合は場合は下記に従いOracle Clientをインストールしましょう。
http://hatsune.wankuma.com/Oracle/oic/install.html
しかし、インストールする時間がない場合はどうしたらよいでしょうか?
その場合はOracle Clientが入っているサーバを探してリモートで接続することも可能です。
環境が揃えば下記のコマンドでデータ投入完了です。
sqlldr user/pass@host:port/<SID> control='TEST.CTL' log='TEST1.log'
取込時間は20万件でも5分以内に終わっているので、なかなか速いです。
しかし、レコードが少ないならばメンテマクロ作成した方が良いです。
2.Sqoop
SqoopはHadoopとDBでのデータやりとりに使用します。
CSV形式などのテキストファイルをデータベースに取り込んだり(エクスポート)
データベースからテキストファイルに出力したり(インポート)できます。
イメージ図
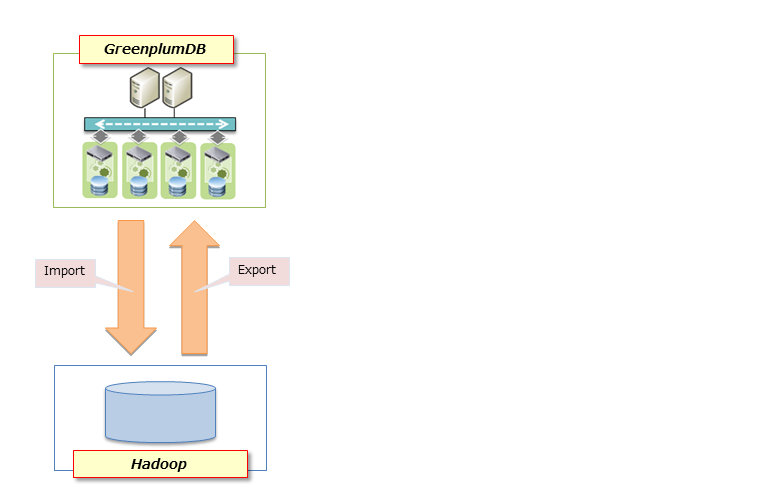
※DBはGreenplumDBとしています。
インプットは入力ファイルのみです。
Sqoopはコマンド実行時DBにアクセスをした際に、カラム情報等を取得してJavaファイルを作成します。
そのため、SQL*Loaderのような制御ファイルが不要となります。
下記のコマンドを実行して、データ投入を行います。
sqoop export \
--connect jdbc:oracle:thin:@host:port/<SID> \
--table TEST_SQOOP \
--username <user_name> \
--password <password>
--export-dir /user/work/sqoop/aaa \
--outdir /home/work/test/bin
--bindir /home/work/test/bin
--fields-terminated-by ','
--escaped-by '\\'
--input-null-string ''
--input-null-non-string ''
--optionally-enclosed-by '\"'
データ出力コマンドは下記です。
sqoop import \
-Dorg.apache.sqoop.credentials.loader.class=org.apache.sqoop.util.password.CryptoFileLoader \
-Dorg.apache.sqoop.credentials.loader.crypto.passphrase=sqoop \
--connect jdbc:oracle:thin:@host:port/<SID> \
--table TEST_SQOOP \
--target-dir /user/word/XX/aaa \
--username <user_name> \
--password-file <pass.txt> \
-m 1 \
--delete-target-dir
DB接続や読み込むCSVファイルをオプションとして指定します。
したがって、sqoopコマンド実行時は非常に長いコマンドを打つ必要があります。
Javaファイルが残ったり、エラー時の裏側のJOBの挙動に関して手動でデータ投入する分には問題ないのですが、
システムに組み込む場合は、考慮する必要があります。
3.外部表(GreenplumDB)
GreenPlumDBとOracleの外部表に関してまとめます。
Greenplumn自体の説明は下記をご参考にして下さい。
http://cn.teldevice.co.jp/product/detail/greenplum_database/feature
GreenPlumDBでは、外部表というものを経由してデータをアンロード・ロードすることが出来ます。
外部表には以下の2種類があります。
- 読込外部表:ロード
- 書込外部表:アンロード
見た目は、Create文と似ていますが、テキストファイルを読込む(書込む)LOCATIONというものが存在します。
読込外部表
create external table ei_test(
a char(1)
,b numeric(2,0)
)
LOCATION
(
'gpfdist://smdw:XXXX/test.csv.gz'
)
;
書込外部表
create writable external table eo_test(
a char(1)
,b numeric(2,0)
)
LOCATION
(
'gpfdist://smdw:XXXX/test.csv'
)
;
読込外部表を用いればDBとマウントしているNASに置いてあるCSVファイルをSELECT出来ます。
select * from ei_test;
書込外部表を用いれば
SELECT-INSERTしてDBとマウントしているNASにCSVファイルが作成されます。
insert into eo_test select * from test;
4.外部表(Oracle)
Oracleも同様に、読込外部表が存在します。
CREATE TABLE TEST(
A NUMBER(1,0)
,B CHAR(4 CHAR)
)
ORGANIZATION EXTERNAL (
TYPE ORACLE_LOADER --オラクルローダー指定
DEFAULT DIRECTORY XXX --ディレクトリオブジェクトを指定
ACCESS PARAMETERS (
RECORDS DELIMITED BY NEWLINE --改行を行区切りと認識
NOBADFILE --badファイル生成しない
NODISCARDFILE --discardファイル生成しない
NOLOGFILE --logファイル生成しない
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
MISSING FIELD VALUES ARE NULL
)
LOCATION(
'test_1.csv'
)
)
REJECT LIMIT 0
;
読込外部表を用いればDBとマウントしているNASに置いてあるCSVファイルをSELECT出来ます。
GreenplumDBと同様のクエリです。
select * from TEST;
GreenplumDBの外部表と異なる点のまとめです
- GreenplumDB:gpfdist指定
- Oracle:ディレクトリオブジェクト指定
まとめ
SQL*LoaderとOracle外部表を比べると作業工程はどちらもあまり変わらない印象です。
環境によって、どちらの手法で取り込むかを考える必要があります。
また、Sqoopを使用してみたときの処理速度は、1件でも10万件でも取り込む速度はほぼ変わりませんでした。
1件でも数分かかったので、件数が少ないものに関してはSqoopは向いていないと思われます。
ビックデータが流行ってきているなか、Sqoopはまだまだ使用ケースが少ないですが(ネットに日本語版が転がっていないのですが)今後は使われてくるのではないかと個人的に思っています。